
一个半监督的中文事件抽取方法
2016-05-04 02:56李培峰朱巧明
中文信息学报 2016年2期
徐 霞,李培峰,朱巧明
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
一个半监督的中文事件抽取方法
徐 霞1,李培峰2,朱巧明2
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
半监督或无监督的事件抽取方法在目前依旧是一个具有挑战性的课题。针对中文本身在表述中存在的固有特点,该文提出一种基于双视图的事件抽取自举学习方法。该方法以少量种子为基础,从文档相关度与语义相似度两个视图出发,进行交互过滤筛选,不断抽取新的有效事件模板,为事件抽取服务。在ACE2005中文语料上的测试表明,和现有方法相比,该方法可以有效地提高中文信息事件抽取系统的性能。
事件抽取;自举;文档相关度;语义相似度
1 引言
互联网时代如何从海量电子文档中及时准确地找到需要的信息己经成为一个亟待解决的问题,信息抽取正是在这样的背景下产生并发展起来的。事件抽取是信息抽取领域一个重要的研究方向,事件抽取主要把人们感兴趣的,用自然语言表达的事件以结构化的形式呈现出来,如什么人,什么地方,什么时间,做了什么事等,在数据挖掘、文本摘要、自动问答以及信息检索等领域有着广泛的应用。
传统的事件模板获取方法需要人工对训练语料进行标注,然后使用有监督的机器学习方法从中学出相应的事件模板,由人工进行浏览并决定取舍。这种方法依赖于大量标注好的语料,训练数据的获取费时费力。当训练语料发生变化时,事件模板还需要重新提取,因此代价很高。
为了进一步减少人工标注,提高系统的移植性,学者们已经开始探索使用半监督的方法来获取事件模板。Yangarber[1]等人在MUC-6英文语料上实现了“管理继承”类型事件的抽取,他们在预定义种子模板(触发词-论元形式)的基础上应用了文档相关度方法,利用相关文档和特定类型事件强烈相关这一特性发现相关文档中的模板,取得了准确率80%和召回率78%的实验结果。但是,中文具有和英文不一样的特点。和英文相比,由于中文词汇表达的灵活性,事件触发词个数要远大于英文触发词。例如,在ACE 2005语料中,描述相同事件个数的中英文对比显示,中文触发词的个数要比英文多30%[2]。从这个角度来讲,触发词扩展是中文半监督事件抽取的关键所在,就像英文半监督事件抽取更加偏重于区分同一触发词的真假实例。所以,英文中的文档相关度方法不能直接应用到中文中。另一方面,文档相关度方法严重依赖种子模板,直接将该方法用在中文事件抽取中会出现很低的召回率。
很明显,与种子模板相似度高的模板描述该类型事件的可能性相对较大。所以,从语义相似度的角度发现与种子模板相似度高的模板,从而进行模板扩展是另外一种方法。但是,该方法也存在问题,那就是存在大量的无效模板,会迅速恶化抽取结果的准确率。
为此,本文提出一种利用两个视图彼此交互过滤的方法,从文档相关度与语义相似度两个视图出发,采用半监督自举(Bootstrapping)方法不断得到新的种子模板,最后抽取出特定类型的事件实例,有效地提高了中文事件抽取系统的性能。
本文的结构组织如下,第二节介绍相关工作;第三节讲述事件抽取基准系统和存在的问题;第四节基于双视图的半监督中文事件抽取方法;第五节是实验结果与分析;第六节为总结并对下一步工作进行了展望。
2 相关工作
目前,涉及半监督或无监督的事件抽取研究较少。
在半监督方法中,基于文档相关度方法是一种常用的方法。该方法把含有大量被选为特定类型模板的文档称为相关文档,其余称为不相关文档。它假设相关文档可能包含更多的相关模板,那么从这些相关文档中抽取模板是一种高效的方法。Riloff[3]首先指出语料库可分为含有特定类型事件和不含有该特定类型事件的两部分文档集,可以用出现在相关文档和不相关文档的频率来评估模板。Yangarber等人[4]用Bootstrapping方法实现了Riloff的方法,他们不需要手动文档分类或语料注释,先定义几个种子模板,用这些种子模板计算文档的相关度,然后对模板进行打分(根据其所在文档的相关度),将高分的模板加入种子集,循环此过程。Surdeanu等人[5]使用了一种混合的方法获取信息抽取模板,他们使用Co-Training方法,把文档中出现的词汇和文档中出现的模板作为两种条件独立的视角,从这两个视角出发训练出两个一致的文档分类器。当两个分类器都收敛时,模板的获取过程结束。Stevenson和Greenwood依据语义相似度为中心[6]提出一种新的模板排序替代方法,使用WordNet[7]来得到词语的相似度,然后构建模板的矢量,用余弦夹角值来度量模板之间的相似性。Liao 和Grishman[8]提出了一种过滤排名方法,在文档相关度为中心的方法中过滤语义相似度低的模板。
3 基准系统和存在的问题
3.1 基准系统
本文采用纽约大学的Exdisco[4]作为基准系统。该系统对于一个特定的事件类型T,要求用户提供几个对于T有代表性的种子模板,然后以文档相关度方法来评估模板,学习出更多的与T相关的模板,这些新的模板又被用于下一轮迭代,这样循环往复,直到收敛。Exdisco系统的事件模板自动获取过程如下。
(1) 初始化: 定义几个事件抽取模板作为种子模板;
(2) 计算文档的相关度: 系统根据当前的种子模板集来计算每个文档的相关度;
(3) 对候选抽取模板评估: 依据候选模板所在文档集的相关度,对候选抽取模板打分;
(4) 产生新的种子模板集: 依据得分对候选抽取模板进行排序,将分值高的候选抽取模板加入种子模板集;
(5) 返回步骤2,经过一定次数的迭代或者不再生成新的模板为止;
3.2 中文事件抽取存在的问题
通过对基准系统的分析,我们发现该方法在中文中没有像在英文中表现出色,究其原因是因为语言的差异。与英文相比,汉语语义结构上的复杂性与多变性以及词与词之间无自然界限、无词尾形式标志、无形态变化等这些现象的存在,给事件抽取带来了困难,具体表现在以下四个方面。
(1) 通过大量真实语料的分析发现,对一类特定事件的描述,中文文本中找到所有表达该事件的触发词个数要远大于英文文本中的触发词,难以统计完全。
(2) 与英语相比,中文句子的结构更灵活,句子元素之间的耦合度更松,在具体的上下文中,各种成分都可以被省略,限制了句法分析的应用。
(3) 在语料库里存在着一词多义的现象,有些触发词,如“来”、“去”等意义过多,对词义消歧要求比较高。
(4) 中文中存在很多词义相近的触发词,一旦由无效触发词构成的无效模板增多,越来越多的非目标事件会被抽取,事件抽取系统的准确率会快速下降。
以上问题在中文事件抽取表现在: 1)文档相关度方法可以在相关文档集中识别出大量事件,但是对种子模板的要求比较高,中文中表达特定类型事件的触发词难以全面列出;2)语义相似度方法可以不受文档的限制,跨文档发现与种子模板相似度高的事件模板,可以很好地对种子模板进行扩充,但是其存在的致命缺点是准确率低。所以,为了能够精确而全面地扩展中文事件模板,本文丰富了事件模板的特征信息,提出利用双视图相互训练扩展事件模板,结合文档相关度和语义相似度的自举方法,并且各自加入过滤器提高精度。这种双视图彼此交互过滤,迭代循环扩展事件模板的方法可以很好地抽取中文的事件实例。
4 基于半监督的中文事件抽取方法
4.1 基本思路
图1(a)描述了文档相关度方法,假设高相关度文档中包含更多相关模板,重点在每个相关文档中学习出与种子模板经常重现或同现的同类或相关类别的事件模板(例如,死亡(Die)类新闻中有大量描述人员死亡、受伤等类别事件)。该方法的缺点是无法从低相关度文档中学习那些不常见或和种子模板匹配度低的模板,其性能严重受限于种子模板的覆盖面。例如,Liao和Grishman[8]使用了34个种子模板来抽取攻击(Attack)事件,就是为了提供尽可能多的种子模板。当把该方法应用到中文事件抽取时,由于中文句子结构相对比英文复杂、结构欠严谨,导致种子模板很难具有较好的覆盖面。
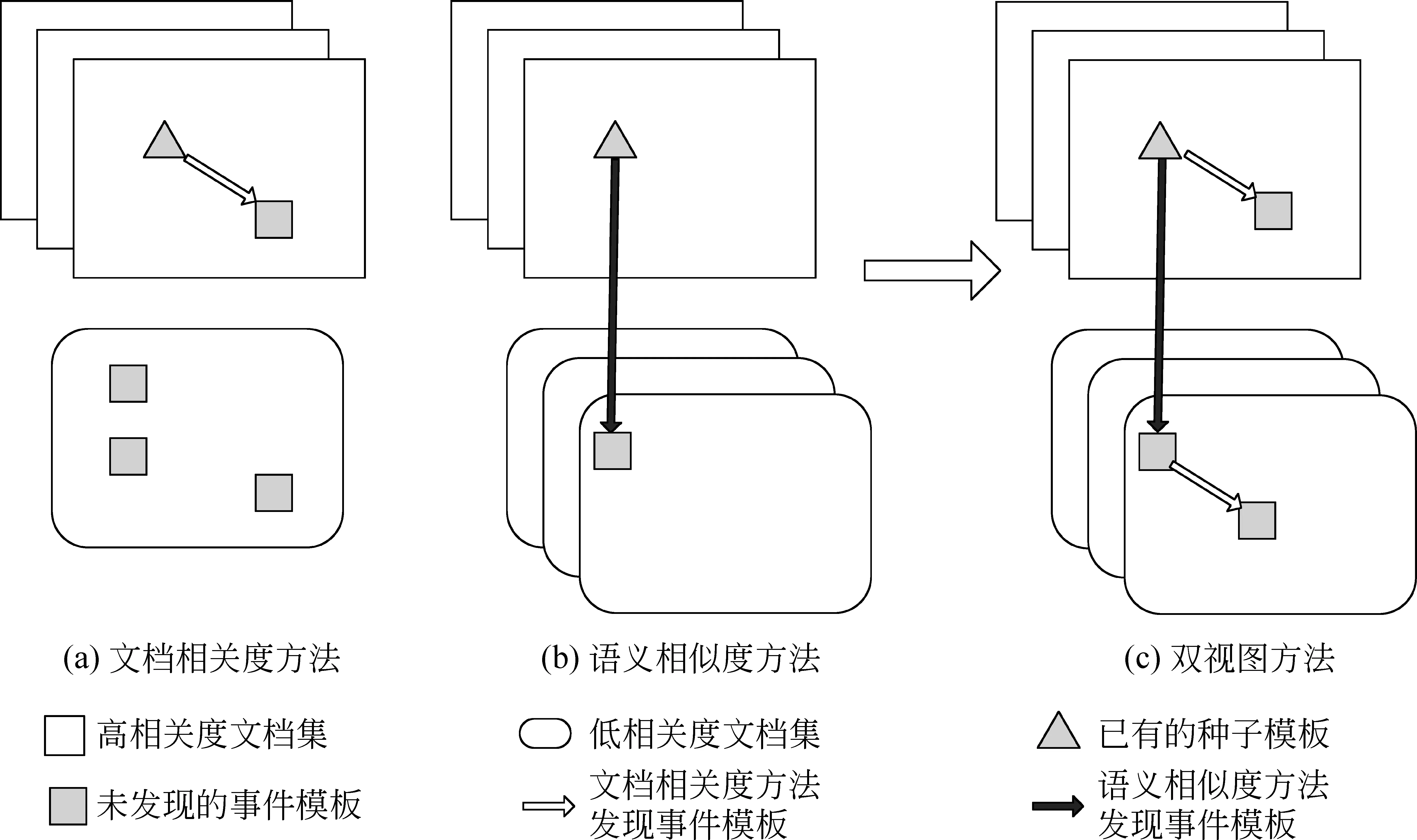
图1 方法比较
图1(b)给出语义相似度方法,假设与种子模板相似度高的模板更可能是事件模板,可以不受文档的限制,跨文档地发现表达同一事件的模板(例如,不同文档里出现的“殴打”、“抽打”、“痛打”都同属一类事件),存在的问题是同现模板不易被发现。而且,由于中文词语存在的多义性,导致语义相似度方法会带来大量的错误模板。
图1(c)是本文针对中文事件抽取提出了一种双视图的方法,结合文档相关度和语义相似度两个方法,不仅可以跨文档发现同一事件的模板,扩大相关文档的范围,而且可以在同一文档内发现一同出现的事件模板,两者相互促进,相辅相成,共同影响中文信息事件抽取系统的性能。
4.2 双视图自举方法
为了提高中文事件抽取系统的性能,必须能够精确而全面地识别出中文事件模板,本文的双视图自举方法以文档相关度与语义相似度两个视图为基础,形成彼此交互过滤的有序集,将两个有序集中最优的模板同时加入种子模板,不断循环此过程,直到不再产生新的模板为止。算法1给出了基于双视图彼此交互过滤的半监督算法的描述。

算法1:双视图自举中文事件模板和事件抽取方法 输入: 候选事件模板集Candidate 种子触发词集Seed 输出: 事件模板集Pattern,抽取的事件集Event
算法流程:
1) Pattern ← ∅,Event ← ∅
2) Pattern ← Candidate中含有Seed中触发词的事件模板集
3) Candidate = Candidate - Pattern
迭代过程
4) 计算每个文档di的相关度Rel(di)
5) 计算每个候选模板p的得分Score(p),降序形成有序集C1
6) 计算每个候选模板p与Pattern之间的每个模板的相似度均值Sim_ave(p),降序形成有序集C2
7) 过滤掉C1中触发词相似度低于阈值a的事件模板,过滤掉C2中得分低于阈值b的事件模板
8) 分别从C1、C2中选择得分和相似度均值最高的一个模板p1、p2
9) 把模板p1、p2加入事件模板Pattern,同时更新候选事件模板Candidate: Pattern = Pattern∪p1∪p2,Candidate = Candidate-{p1∪p2}
10) 不断循环过程4-9,直到不再产生新的模板为止
迭代结束
11) Event ← Pattern模板可以匹配的所有事件
本文主要实现上述基于双视图彼此交互过滤的算法,采用Bootstrapping半监督的方法不断扩展种子模板,指导中文的事件抽取。在算法1中,需要解决三个问题: 1)模板的定义;2)计算语义相似度;3)计算文档相关度。
4.3 模板的定义
事件模板用来指导从中文文本抽取事件。为了更好地计算模板之间的相似度,在触发词-论元形式上丰富了触发词与论元之间的句法特征,及论元的类别特征。本文从词法特征、类别/子类别特征、句法结构特征多角度描述模板。其中,词法特征包括候选事件中的事件触发词(Trigger)、事件触发词的词性信息(TriggerPOS)和与触发词关联的事件元素(论元Argument);类别/子类别特征包括论元的类别(Enttype)和论元的子类别(Subenttype);句法结构包括触发词与论元之间依存路径(Path)。
事件触发词、论元及其相关特征构成了事件模板的框架,本文的事件模板组成包括: 触发词、论元、词性、(子)类别、依存路径,为模板定义一个六元组Pattern=(Trigger,TriggerPOS,Arguement,Enttype,Subenttype,Path)。
4.4 计算文档相关度
文档相关度可从侧面反映候选模板成为事件模板的可能性,以文档相关度方法来评估候选模板时,首先对中文文本进行预处理,多特征角度描述候选模板,预定义种子模板。本文对Yangarber等人[4]的方法进行了优化,得到了如下的计算方法。
初始化: 种子模板的精确度为1,其它为0,种子模板所在文档的相关度为1,其它为0。
在i+1次循环中,对每个模板p计算其精确度:
(1)
其中,H(p)是模板p所在的文档集,Reli(d)是第i次循环文档d的相关度。Reli+1(d)的计算公式如式(2)所示。
(2)
其中,Kd是指文档d中已被选为种子模板的模板集,Preci+1(Kd)是模板集Kd的精确度。Preci+1(Kd)的计算公式如式(3)所示。
(3)
其中,H(Kd)是出现了文档d中被选为种子模板的文档集。
然后,我们对每一个候选模板p进行打分:
当Sup(p)=0时,Score(p)=0
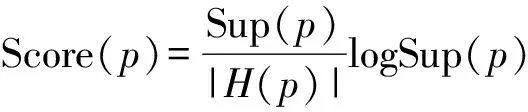

(4)
式(4)中,“Sup(p)=1”与“Sup(p)=0”都出现Score(p)=0这一情况,为区别非相关模板与所在文档集的相关度之和为1的相关模板,对相关模板设定一个对Score影响很小的系数0.1,即当Sup(p)=1时,Sup(p)=Sup(p)+0.1。
最后,将最高分值的模板加入种子模板,进入下一个循环,直到不再产生新的种子模板。
4.5 计算语义相似度
与种子模板相似度高的模板更可能成为该类型的事件模板,本文用语义相似度来反映它们之间的相似程度。每一个模板p由触发词f、论元类型t和触发词与论元之间的依存关系d组成,它们之间的语义相似性取决于这些词及特征关系之间的相似性,本文模板之间的语义相似度计算方法如式(5)所示。
Sim(p1,p2)=maxsim·S1(d1,d2)·S2(t1,t2)

(5)
maxsim指候选模板与种子触发词之间最大的词汇语义相似度:
(6)

(7)
S2(t1,t2)是指候选模板中论元类型t1与种子模板中论元类型t2之间的差异值,本文用式(8)来反映不同类别的论元之间的差异性。
(8)
(9)
这样本文可以计算出候选模板与种子模板之间的语义相似度,为了更加综合地衡量模板间的语义相似度,本文对候选模板的评估是根据它们与种子模板之间语义相似度的均值Sim_ave,式(9)更具有合理性和一般性。
5 实验与分析
5.1 实验环境
本文的实验数据是ACE 2005中文语料,该语料将事件的类别主要分为八个大类及33个子类。本实验主要通过定义的种子模板抽取出其中就有代表性的Injure、Die、Attack三类事件。对语料库中633个中文文本统计表明,Injure事件有163个,Die事件有243个,Attack事件有534个。评价指标是准确率P、召回率R和F1值。
实验中的中文文本以句子为单位,利用苏州大学自然语言处理平台集成的工具进行分词、词性标注和实体类别识别。在此基础上进行句法和依存分析,得到依存和句法分析树。将词性为动词或名词的词汇作为触发词,依次与该句中的实体形成触发词-论元式,并记录论元的类别、依存关系等特征,得到本文的候选模板。
对Injure、Die、Attack三类事件的抽取工作依赖于事件模板,中文事件的的种子模板人工很难详细给出。本文是通过种子触发词得到种子模板,将候选模板中包含种子触发词的模板选为种子模板。这就需要既能代表特定类型事件又有固定语义的词汇作为种子触发词,本文提供了最少量的触发词,具体如下:
• Injure事件: “伤”
• Die事件: “死”
• Attack事件: “攻击”、“冲突”、“打”
这样包含这五个种子触发词的候选模板就是最初的种子模板。
5.2 实验结果
本文提出的基于双视图的事件抽取自举学习方法通过Bootstrapping方式不断扩充种子模板,指导中文事件抽取工作。为了验证双视图方法扩充种子模板的可行性与有效性,分别用文档相关度方法、语义相似度方法和双视图的方法评估候选模板。算法1在具体实现时,防止双视图的方法过早地引入大量无效事件模板,需要对有序集C1过滤掉maxsim低于阈值a(a取0.7)的模板,对有序集C2过滤掉score低于阈值b(b取0.3)的模板。表1显示了三种方法用来抽取事件的结果。表1中本文提出的方法分别比文档相关度方法和语义相似度方法提高了F1值7.7%和3.4%,验证了本文方法的效率。另外,可以发现,文档相关度方法具有较高的准确率,而语义相似度方法具有较高的召回率,这和我们前面的分析相符合。而本文的方法,则在准确率和召回率方面相对比较均衡,吸收了双方的优点。
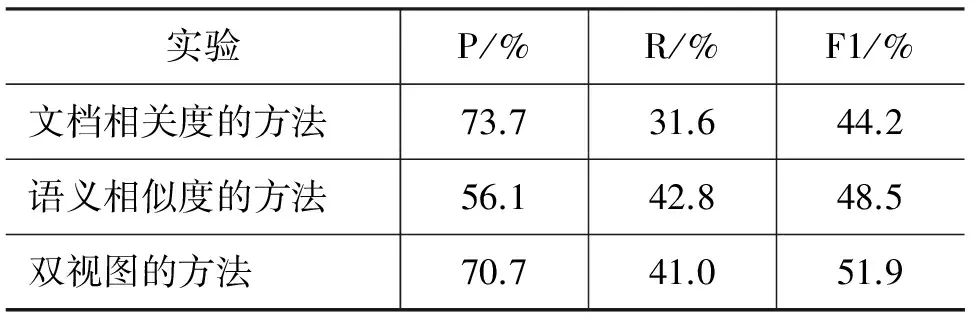
表1 中文事件抽取实验结果
为了进一步分析实验结果,本文把在语料库中事件能顺利对应的触发词称为有效触发词,否则称为无效触发词。能抽取事件实例的事件模板称为有效事件模板,否则称为无效事件模板。表2显示了各个方法新增触发词的个数和准确率,表3显示了各个方法抽取事件模板的性能。

表2 新增触发词情况
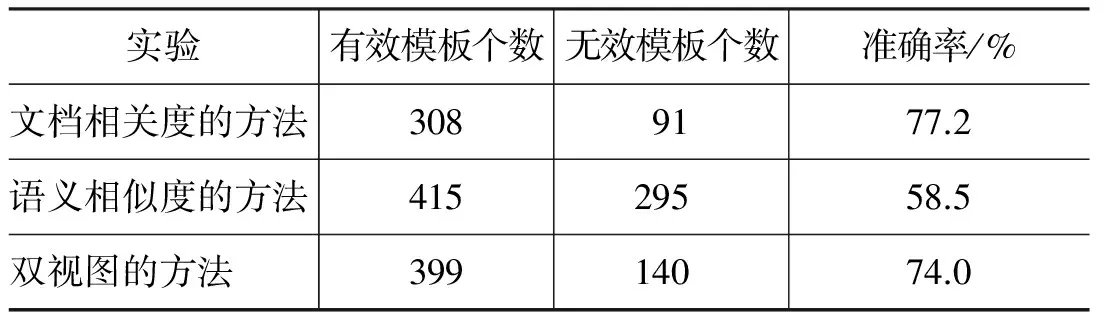
表3 事件模板情况
用文档相关度方法评估候选模板,种子模板的准确率是77.2%,同时识别事件的准确率达到73.7%,但是召回率仅为31.6%,远远低于英文中的78%。这是因为英文中表达事件的触发词数量少,人工容易给出,而中文中表达事件的触发词数量远多于英文,只能通过最初的种子模板不断累积。但是文档相关度方法只能发现与种子触发词经常一同出现的触发词(例如,“死”与“死亡”、“伤”与“受伤”)。文档相关度方法在实验中有效触发词仅仅增加了“受伤”“死亡”“丧生”这三个。
语义相似度方法可以跨文档地扩展种子模板,有效触发词的数量可以增加38个。例如,“惨死”“殴打”“抽打”“痛打”“杀”“逝世”“过世”“病逝”“进攻”“伏击”等。语义相似度方法可以很好地扩展种子模板,召回率比文档相关度方法提高了约11%,但是该方法会引入大量无效触发词(61个),而且一旦引进无效触发词,会有越来越多的无效模板被引入,其抽取的模板的准确率只有58.5%。
文档相关度方法和语义相似度方法,对中文事件抽取分别带来高准确率和高召回率的优势,本文提出的双视图互训练方法,在文档相关度与语义相似度两个视图下择优一同影响种子模板,共同发现目标事件,两者相互影响,相互促进。实验结果表明,双视图方法下事件抽取系统的F1达到了51.9%,优于现有的方法。该方法不仅能扩展种子模板而且能有效地抑制无效模板,有效模板的个数达到399个,远远高出文档相关度方法,事件模板的准确率达到74.0%,明显优于语义相似度方法。所以,本文的基于双视图的事件抽取自举学习方法对中文事件抽取的研究取得了一定的进步,但是还存在很大的发展空间。
6 小结与展望
本文具体分析了文档相关度与语义相似度方法的优缺点以及中英文之间的差异性,提出了一种基于双视图的事件抽取自举学习方法,从文档相关度与语义相似度两个视图出发,进行交互过滤筛选,不断扩展新的事件模板,指导中文事件抽取工作。实验证明,该方法在有效模板获取上性能较好。
中文语言的复杂性给事件抽取任务带来挑战,在接下来的工作中,本文将考虑到中文语言的特点,加深对特殊句式的理解,考虑句子中的句法结构与语义成分,进一步改善中文事件抽取工作。
[1] Roman Yangarber, Ralph Grishman, Pasi Tapanainen, Silja Huttunen. Unsupervised discovery of scenario-level patterns for Information Extraction[C]//Proceedings of the 6th Conference on Applied Natural Language Processing. 2000: 282-289.
[2] Peifeng Li, Guodong Zhou, Qiaoming Zhu, et al. Employing compositional semantics and discourse consistency in Chinese event extraction[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2012: 1006-1016.
[3] Ellen Riloff. Automatically Generating Extraction Patterns from Untagged Text[C]//Proceedings of the Thirteenth National Conference on Artificial Intelligence. 1996: 1044-1049.
[4] Roman Yangarber, Ralph Grishman, Pasi Tapanainen, Silja Huttunen. Automatic Acquisition of Domain Knowledge for Information Extraction[C]//Proceedings of the 18th Conference on Computational Linguistics.2000: 940-946.
[5] Mihai Surdeanu, Jordi Turmo, Alicia Ageno. A Hybrid Approach for the Acquisition of Information Extraction Patterns[C]//Proceedings of the EACL 2006 Workshop on Adaptive Text Extraction and Mining. 2006.
[6] Mark A. Greenwood, Mark Stevenson. Improving semi-supervised acquisition of relation extraction patterns[C]//Proceedings of the Workshop on Information Extraction Beyond the Document. 2006:29-35.
[7] Ted Pedersen, Siddharth Patwardhan, Jason Michelizzi. WordNet: Similarity—Measuring the Relatedness of Concepts[C]//Proceedings of the Nineteenth National Conference on Artificial Intelligence. 2004: 1024-1025.
[8] Shasha Liao, Ralph Grishman. Filtered Ranking for Bootstrapping in Event Extraction[C]//Proceedings of the 23rd International Conference on Computational Linguistics. 2010: 680-688.
[9] 刘群,李素建. 基于《知网》的词汇语义相似度计算[J]. 计算语言学及中文信息处理,2002,7: 59-76.
A Semi-supervised Chinese Event Extraction Method
XU Xia1, LI Peifeng2,ZHU Qiaoming2
(1. School of Computer Science and Technology, Soochow University, Suzhou,Jiangsu 215006,China; 2. Province Key Lab of Computer Information Processing Technology of Jiangsu, Suzhou, Jiangsu 215006, China)
Currently, semi-supervised or unsupervised event extraction remains a challenge. According to the nature of Chinese language, this paper proposes a dual-view-based bootstrapping approach to extract event patterns. According to a small set of seeds, it applies a cross filtering method to two views, document relevance and semantic similarity, and extract new patterns in each iteration. Our experimental results show our system outperforms the existed systems.
event extraction; bootstrapping; document relevance; semantic similarity

徐霞(1989-),硕士研究生,主要研究领域为自然语言处理、中文信息处理。E⁃mail:xuxia1125@163.com李培峰(1971-),博士,教授,主要研究领域为自然语言处理、中文信息处理、Web信息处理和嵌入式系统。E⁃mail:pfli@suda.edu.cn朱巧明(1963-),博士,博士生导师,教授,主要研究领域为自然语言处理、中文信息处理、Web信息处理和嵌入式系统。E⁃mail:qmzhu@suda.edu.cn
1003-0077(2016)02-0168-07
2013-11-05 定稿日期: 2014-03-28
国家自然科学基金(61272260),江苏省自然基金(BK2011282),江苏省高校自然科学重大基础研究项目(11KIJ520003)
TP
A
猜你喜欢
通信技术(2021年12期)2022-01-25
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
电脑知识与技术(2016年13期)2016-06-29
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
中文信息学报(2012年2期)2012-06-29
