
查询会话中带时间因子的隐式负反馈研究
2016-05-04 03:10:24陈振宏俞晓明程学旗
中文信息学报 2016年2期
陈振宏,俞晓明,刘 悦,程学旗
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院大学,北京,100190)
查询会话中带时间因子的隐式负反馈研究
陈振宏1,2,俞晓明1,刘 悦1,程学旗1
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院大学,北京,100190)
隐式相关反馈常被用于提升检索系统的性能,目前大部分工作集中在研究隐式正反馈。该文同时考虑隐式正负反馈,将查询会话中被点击网页前的未被点击网页作为隐式负反馈信息,通过引入时间因子,估计用户在未被点击网页的标题和摘要上的停留时间,推断隐式负反馈与用户兴趣和行为的关系,达到优化检索结果的目的。在TRECSession2011和2012数据集上的实验,验证了该文提出的带时间因子的隐式正负反馈算法TIPNF的有效性。
查询会话;隐式负反馈;时间因子;排序
1 引言
相关反馈技术是优化检索系统排序结果的重要方法之一,包括显式相关反馈、隐式相关反馈和伪相关反馈三类。其中,隐式相关反馈利用用户与检索系统的交互信息推断用户偏好,达到优化检索效果的目的,交互信息包括用户历史查询、点击的结果网页、在网页上的停留时间等,这些信息往往容易获取,而且信息量非常大。
当前对隐式反馈的研究主要集中在隐式正反馈上,通过用户点击的网页、用户在网页上的停留时间等信息,推断用户的兴趣。例如,如果用户点击了某篇网页,则认为该网页与用户的查询更相关,用户在网页上的浏览时间越长,说明该网页的内容更有价值。相对隐式正反馈,隐式负反馈不管在信息的获取上还是使用上,都存在较大困难。目前对隐式负反馈的研究,一般是将其与正反馈一起构造偏序关系作为排序学习等模型的输入,通过训练得到的模型对检索结果进行优化。而直接同时使用隐式正负反馈进行检索结果优化的工作很少,因为隐式反馈信息中存在较多的噪音,被当作负反馈信息的内容并不总是与查询不相关的,如果直接将隐式负反馈信息作用到排序模型,可能导致检索质量与仅使用隐式正反馈相比反而下降的情况。在这个背景下,本文探究如何有效地使用隐式负反馈进行检索结果优化,我们采用保守的方式获取隐式负反馈信息,仅将被点击网页前的未被点击网页当作负反馈信息,并通过隐式正反馈信息估计用户在未被点击网页上的浏览时间,提出带时间因子的隐式正负反馈排序算法,探讨隐式负反馈的使用以及时间因子对负反馈信息使用的影响。
本文主要研究利用同一查询会话中的隐式反馈信息对查询会话下一个查询的结果进行优化,查询会话定义为用户为满足某个信息需求与检索系统进行的一系列交互过程。本文利用的隐式正负反馈信息特指查询会话中被点击的网页和位于被点击网页前的未被点击网页。此外,我们还使用了用户在被点击网页上的浏览时间以及用户在未被点击网页上的可能停留时间。考虑到隐式反馈信息自身存在的噪声,并且基于检索系统返回结果中位置越靠后的网页越不相关的假设,我们仅使用被点击网页前的未被点击网页作为隐式负反馈信息;同时,根据用户提交查询的时刻、用户点击网页的时刻和用户离开网页的时刻来估计用户在未被点击网页上的浏览时间,提出统一的带时间因子的隐式正负反馈排序算法。
本文的贡献在于挖掘隐式负反馈信息,提出隐式负反馈信息的时间因子的计算方法,探究隐式负反馈信息的使用以及时间因子对负反馈信息的影响,并提出带时间因子的隐式正负反馈排序算法。在TREC Session数据集上的实验结果验证了本文所提算法的有效性,带时间因子的隐式正负反馈排序算法相对原始查询结果约有80%的提升,相对只考虑隐式正反馈信息的排序算法约有10%的提升。
本文余下章节组织如下,第二节介绍相关工作;第三节探究隐式正负反馈信息的提取以及其上时间因子的计算;第四节提出带时间因子的隐式反馈排序算法;第五节介绍实验数据集、评价指标选择,并验证本文所提算法的有效性;第六节是对本文的总结及下一步研究的方向。
2 相关工作
常用的隐式反馈信息包括历史查询和点击流数据,其中,点击流数据已被多数研究人员使用并证实能够很好的提升检索结果的相关度。文献[1]对用户浏览行为进行眼球运动追踪,研究并分析用户行为,得出点击行为与网页相关度有很强相关性等结论。文献[2]验证点击流数据作为隐式反馈信息能够达到与显式反馈信息相当甚至更好的结果,它根据点击流数据采用一定策略产生pairwise排序学习模型需要的网页对,与直接使用人工标注的网页相关度学习得到的模型进行对比,发现两者效果相当。
用户在被点击网页上的浏览时间也被广泛研究,然而对于浏览时间与网页相关度的相关性却颇有争议。Kelly[3]指出网页浏览(展示)时间与网页相关度之间没有普遍的直接关系,在他们的工作中,浏览时间表示为在同一话题下用户的平均浏览时间。而Halabi[4]则指出对给定的用户在某一查询会话中,浏览时间反映着用户对网页的兴趣,用户在网页上停留的时间越长,说明该网页与用户的需求可能更相关。鉴于他们对浏览时间的度量方式不同,我们并不认为他们的结论存在冲突。由于我们的实验设置与Halabi的类似,都是研究给定用户在查询会话中的隐式反馈信息,因此我们假设用户在网页上停留的时间越长,该网页更相关。
在TREC Session 2011任务中,文献[5]使用被点击网页的浏览时间以及待排序网页与被点击网页的相似度预测用户在待排序网页上的浏览时间,进而根据该时间进行排序的算法取得了第一的好成绩,其引用的方法来自SongHuaXu等在文献[6]中提出的基于用户浏览时间的网页排序算法。然而文献[5]和文献[6]只使用了被点击网页的信息,本文在他们工作的基础上进一步考虑未被点击网页的信息,并估计其浏览时间,提出统一的带时间因子的隐式正负反馈排序算法,更好的提升检索结果的相关度。
另外,文献[7]通过建模隐式反馈信息,得到一个决策树模型用于判断网页的有效性,并将同一查询会话中预测为有效网页中词频最高的前15个词和预测为无效网页中词频最高的前十个词作为查询扩展,添加到查询会话的倒数第二个查询。然而,他们的实验结果显示添加了无效网页信息的算法比单纯使用有效网页的算法效果更差。虽然对隐式负反馈信息的使用方法不同,本文在未考虑时间因子的情况下,单纯使用隐式正负反馈信息的效果远差于只使用隐式正反馈信息的效果。但通过引入时间因子,检索效果得到了显著提升,在TREC Session 2011和2012数据集上的结果都验证了时间因子对排序结果的影响。
3 时间因子定义
本文利用同一查询会话中的隐式正负反馈信息,即被点击网页与位于被点击网页前的未被点击网页,同时考虑用户浏览时间,挖掘用户在未被点击网页上的浏览时间,对查询会话下一个查询的结果进行优化。下面先简要介绍查询会话包括的信息以及本文使用的隐式正负反馈信息,然后探讨时间因子的表示与计算。
3.1 查询会话构成
查询会话,定义为用户为满足某个信息需求与检索系统进行的一系列交互,每个交互包括用户查询、该查询提交的时刻、检索系统返回的网页集、用户点击的网页、用户进入被点击网页以及离开被点击网页的时刻等信息。
3.2 隐式正负反馈信息
隐式反馈技术利用用户行为来理解用户的兴趣和偏好,本文研究的用户行为包括用户点击了哪些网页以及在网页上的停留时间。我们假设用户点击的网页比未被点击的网页更相关,即用户在浏览检索结果时,趋向于点击他们感兴趣的网页,也就是与他们的信息需求相关的网页。本文研究的隐式正反馈信息就是指用户点击的网页。
我们假设用户浏览结果网页集时遵循自上而下的行为,于是,如果用户点击了第i+1个网页却没有点击第i个网页,我们有理由相信第i个网页的内容很可能与用户需求不符。基于这个观察,我们使用被点击网页前的未被点击网页作为隐式负相关反馈,与正反馈信息一起参与到排序计分。
当然,选择隐式负反馈信息的策略还有很多,例如选择与被点击网页相似度小的未被点击网页,使用最后一个被点击网页前的所有网页等。考虑到隐式负反馈信息使用的难度(来自自身的噪声)及其对检索结果影响的不稳定性,本文采用较为保守的策略,仅使用被点击网页前的一个未被点击网页作为隐式负反馈信息。例如,用户点击了第五和第八个网页,此时我们选择第四和第七个网页作为负反馈信息;如果用户点击了第三和第四这两个网页,我们选择第二个网页作为负反馈信息。
3.3 时间因子计算
用户点击网页后在其上的浏览时间,一定程度上反映了网页内容对用户的吸引程度,于是,我们假设用户在网页上的浏览时间越长,该网页可能更相关。用户在点击网页上的浏览时间一般比较容易得到,而在未被点击网页上的浏览时间很难显示得到。本文提出估计用户在未被点击网页上浏览时间的方法,挖掘隐式负反馈信息对用户偏好的作用,统一了隐式正负反馈信息在检索结果排序中的使用。
被点击网页的浏览时间从查询会话的数据可以直接计算得到,式(1)使用用户离开网页的时刻与进入网页的时刻之差计算用户在网页上的停留时间,Cki表示第k次交互中被点击的检索结果排序为i的网页。
(1)
采用3.2节中隐式负反馈信息的提取策略,能够很方便的估计用户在未被点击网页上的浏览时间,这里估计的时间不是在网页内容页面上的停留时间,而是在检索系统展示的网页的标题跟摘要上的浏览时间,计算方法如式(2)所示,其中,Ik表示查询会话中的第k个交互,Uki为第k个交互中检索结果位置为i的未被点击网页。
(2)
另外,考虑网页在检索结果中的排序以及用户浏览行为,位置越靠前的网页与查询在某些性质上可能更相关,用户也比较倾向于浏览位置靠前的网页。于是,在用户浏览时间的基础上考虑网页在结果集中位置的因素,得到最终的网页时间因子计算如式(3)所示。
(3)
其中,γ、β、τ为参数,γ和β用来控制用户浏览时间在时间因子上的比例,γ取正实数,β取负实数用于表示隐式正负反馈信息的不同作用。参数τ用于控制网页序的影响。
4 带时间因子的隐式反馈排序算法
本节研究如何利用第三节得到的隐式正负反馈信息和时间因子达到提高检索结果质量的目的。隐式反馈信息的使用一般有两种,将隐式反馈信息独立作用于检索结果进行重新排序,或者将隐式反馈信息直接集成到排序算法中。本文采用前一种方法,利用隐式反馈信息对查询会话下一个查询的结果进行重排序。
4.1 带时间因子的隐式正反馈算法
仅考虑隐式正反馈信息,使用与文献[5-6]类似的排序算法,得到带时间因子的隐式正反馈算法TIPF(TimedImplicitPositiveFeedback),对查询会话最后一个查询的结果使用式(5)进行重新排序。
(4)
(5)
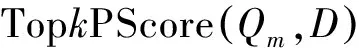
4.2 带时间因子的隐式正负反馈算法
在TIPF的基础上,进一步考虑隐式负反馈信息,得到TIPNF(TimedImplicitPositiveandNegativeFeedback)算法,最后按式(7)计算的分数对初始结果进行重新排序。其中TopkNScore(Qm,D)由集合NegativeScore(Qm,D)中数值最大的N个元素组成。
(6)
(7)
通过估计隐式负反馈信息上的时间因子,式(7)将正负反馈信息很好的统一了起来,TIPNF显示了隐式负反馈信息使用的新方法。
通过取TopN篇网页的和能从一定程度上降低数据噪声对模型稳定性的影响。例如,如果用户在浏览某篇网页时由于各种原因可能临时离开,于是最后获取到的浏览时间远大于实际值,导致取Top1进行计算排序时可能把不相关的网页排到很靠前的位置。实验结果也证实,取TopN时的效果比Top1好很多。
5 实验分析
我们使用TREC Session的数据,通过多组对比实验验证TIPNF算法的有效性,实验结果评价指标用的是ERR[8](Expected Reciprocal Rank),5.2节中我们将详细讨论选择ERR作为最终评价指标的原因。实验结果显示TIPNF能有效地提高检索结果的质量。
5.1 测试数据集
TREC Session原始语料为clueweb09数据,我们使用其中的英语语料,共2TB的压缩数据,10亿篇网页。我们分别在TRECSession 2011和TREC Session 2012年的数据上验证TIPNF算法的有效性。TREC Session 2011提供了76个会话信息,其中有12个会话没有点击信息,17个会话的被点击网页没有对应的未被点击网页,所以,最终用于实验的会话一共有47个。TREC Session 2012共有98个会话信息,其中有26个会话没有点击信息,26个会话的被点击网页没有对应的未被点击网页,最终用于实验的会话共有46个。
每个查询会话有一个特定的任务,用户根据该任务构造查询与检索系统进行一系列交互。TREC Session提供了每个交互中用户提交查询的时刻、检索系统返回的网页集、用户进入和离开网页的时刻等信息。检索结果采用五级相关度进行评判,分别是-2,0,1,2,3,-2表示垃圾网页,0表示不相关,1表示相关,2表示高度相关,3表示精确命中。
5.2 评价指标
检索系统常用的评价指标有Precision、Recall、F-score、MAP、DCG[9]、ERR等,DCG和ERR常用于评价多级标注结果。此次实验中我们采用ERR(Expected Reciprocal Rank)作为最终的评价指标,下面先简单介绍ERR和DCG的区别,然后解释选择ERR的原因。
DCG(Discounted Cumulative Gain)的计算如式(8)所示,其中gi为第i个网页的相关度。从式(8)可以看到,DCG对每个结果网页采用叠加的方式计算最终检索的质量,这使得每个网页对最终检索质量的贡献仅与网页本身的相关度以及网页在检索结果中的位置有关,而与位于该网页之前的其他网页的相关度无关。
(8)
然而,用户实际浏览检索结果时,如果第i-1个位置的网页很相关,那么用户的信息需求可能得到满足,从而不会去查看第i个网页。例如,在5.1节中描述的五级相关度下评价两个检索结果,第一个检索结果为相关度均为1的20个网页,第二个检索结果中第一个网页的相关度为3,剩余19个网页的相关度均为-2,此时,DCG计算的结果认为第一个检索结果质量更高。但是,第二个检索结果中的第一个网页已经完全满足了用户的信息需求,用户可能不会继续往下浏览;而如果浏览第一个检索结果,用户可能需要在看完全部20个网页后才能找到其需要的全部信息。
ERR则建模用户的这种浏览行为,弥补了DCG的不足。ERR采用级联浏览模型来描述用户行为,用户自上而下浏览检索结果时,在第i篇网页以概率R(i)得到满足,以1-R(i)的概率继续浏览下一篇网页。其计算公式如式(11)所示。
(9)
(10)
(11)
其中,gi为检索结果中第i个网页的相关度,g为网页的相关度,实验中使用TREC官方对检索结果的多级标注,分别是-2,0,1,2,3,式(9)中的gmax为多级标注中的最大值,在本实验中,gmax取值为3。
本文提出的TIPNF算法使用的假设与ERR类似,TIPNF假设用户自上而下浏览网页,认为被点击网页前的未被点击网页与查询不相关,与用户看了未被点击网页信息需求没得到满足继续往下浏览的行为一致。基于上述原因,我们在实验中主要采用ERR评价所提出算法的有效性,当然,我们也给出了nDGC@10的评价结果。
5.3 时间因子统计
本节我们以TRECSession2011为例分析用户在点击网页上的浏览时间、在未点击网页上估计的浏览时间以及对应的时间因子。
图1是隐式正反馈信息即用户在被点击网页上的浏览时间和按式(3)得到的时间因子的分布,被点击网页共151个。从图1可以看到,大部分浏览时间在100秒以内,少部分需要100到200秒,与我们实际使用搜索引擎时的浏览时间接近,其中只有少数几个网页的浏览时间超过300秒,我们仔细查看了这些网页,发现这些网页内容的长度与其他网页差不多,据此判断为噪声点,原因可能是前文提到的用户临时有事离开导致时间记录有偏差。由于只有极少数网页的时间可能有偏差,实验中我们并不对其做特殊处理。实验时式(3)中的γ和τ分别取值0.1和0.2,由于隐式正反馈时间因子中网页序部分只用来对时间因子进行细微的调整,所以图中被点击网页时间因子的分布和实际浏览时间的分布基本一致。
同样的,我们在图2中展示了隐式负反馈信息即未被点击网页的估计浏览时间和时间因子分布。满足我们的隐式负反馈信息设定条件的网页共90个,通过统计得到估计的浏览时间大部分集中在七秒左右,部分高达十几秒,这相对用户实际查看网页结果的标题和摘要的时间偏高。可能原因有两方面,一是用来计算的起止时间包含系统响应时间和页面加载时间;另外一个是因为用户出于实验数据采集的目的特别仔细的浏览了每个结果网页的标题和摘要,同时思考需不需要点击等,导致浏览时间整体偏高。我们通过对式(3)使用较小的β值来降低估计时间偏高的影响,TRECSession2011数据上β和τ分别取值-0.001和0.2。
5.4TIPNF算法效果

图1 TREC Session 2011隐式正反馈时间分析
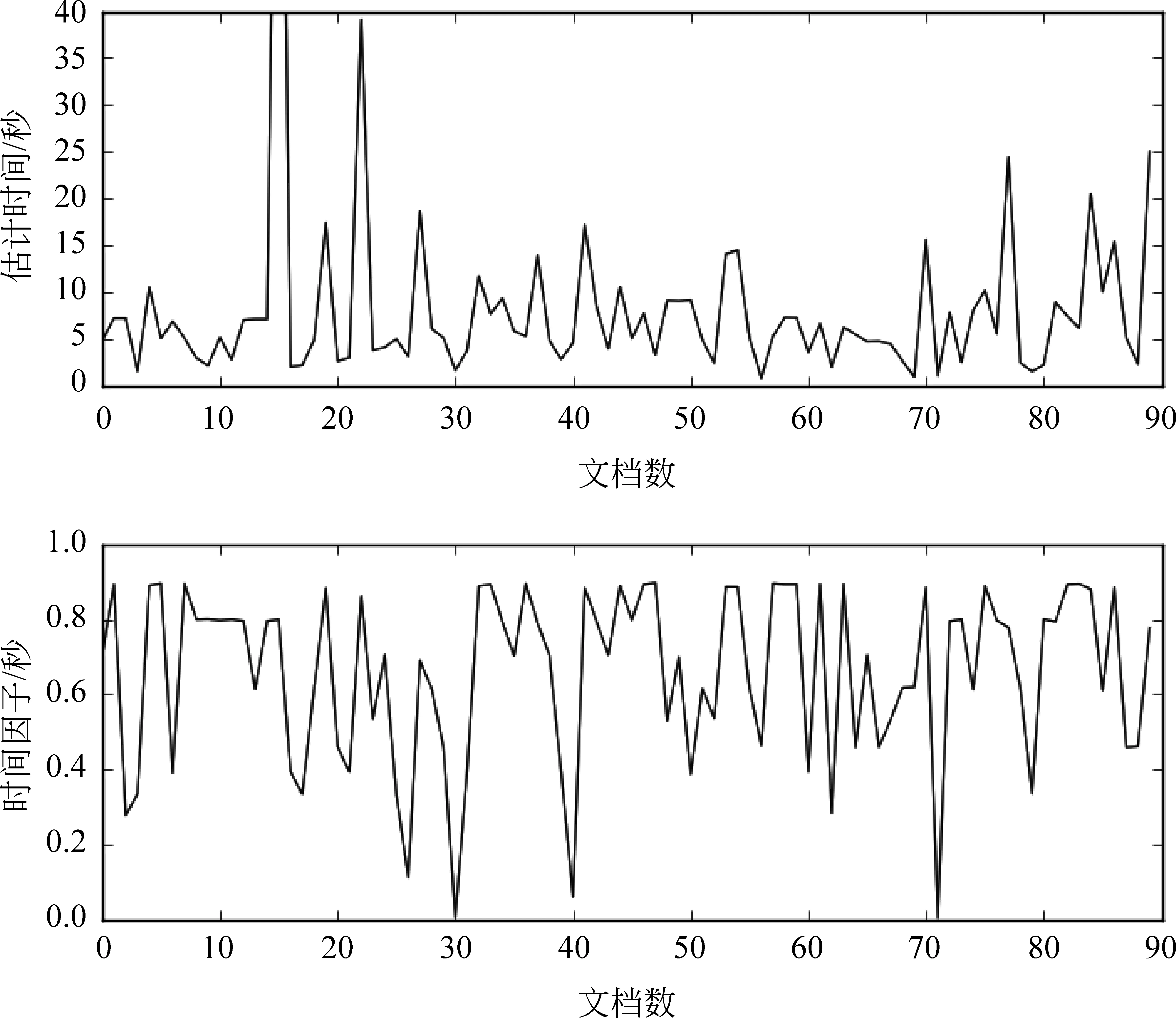
图2 TREC Session 2011隐式负反馈时间分析
我们用查询会话的下一个查询与网页的BM25得分作为基准参照,同时比较隐式正负反馈算法在是否考虑时间因子条件下对检索性能的影响,验证所提出算法的有效性。其中,TIPF算法是文献[5]算法的改进,文献[5]使用的算法在TRECSession2011中取得了第一的成绩。
只考虑隐式正反馈信息,针对式(3),对是否使用时间因子,可以得到IPF(ImplicitPositive-Feedback)和TIPF(TimedImplicitPositiveFeedback)。同样的,考虑隐式正负反馈信息时,可以得到IPNF(ImplicitPositiveandNegativeFeedback)和TIPNF(TimedImplicitPositiveandNegativeFeedback)。上述不同组合得到的算法在TRECSession2011和TRECSession2012数据集上检索结果的ERR值如表1、表2所示。其中,BM25参数k1和b取值分别为0.8、0.25,本文算法参数γ、τ和N取值为0.1、0.2、5,TRECSession2011上参数β取值为-0.001,TRECSession2012上参数β取值为-0.28。
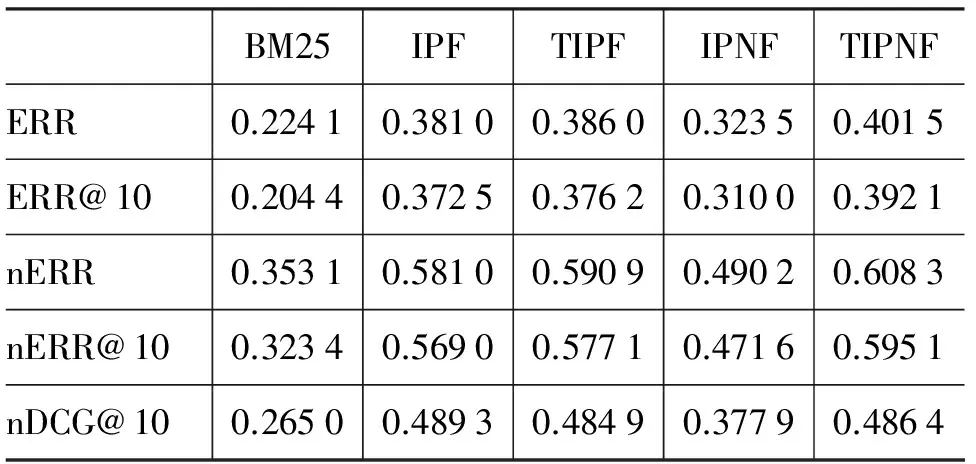
表1 TREC Session 2011数据测试结果

表2 TREC Session 2012数据测试结果
可以看到,隐式正反馈信息能很好的提升检索的性能,这与大多数研究结果一致。比较IPF和TIPF,发现时间因子对隐式正反馈信息提升的效果不是很明显,但它们在不同指标上的表现都很稳定。比较IPF和IPNF算法,不考虑时间因子的情况下,IPNF虽然相对BM25有显著的提高,却比IPF低了不少,原因可能在于IPNF对隐式负反馈信息的使用比较粗糙,没能很好利用隐式负反馈信息。对比TIPNF和其他算法,TIPNF在各个ERR指标上都达到最大值,在评价指标ERR上,TIPNF相对BM25提高了约80%,在TREC Session 2012数据集上相对TIPF提高了高达10%的性能。这验证了本文提出的带时间因子的隐式正负反馈算法的有效性。
6 总结
本文研究了隐式负反馈信息在提高信息检索结果质量上的应用,将查询会话中被点击网页前的未被点击网页作为隐式负反馈信息,通过引入时间因子,估计用户在未被点击网页的标题和摘要上的浏览时间,推断隐式负反馈信息与用户兴趣和行为的关系,从而优化检索结果的质量。在TREC Session 2011和TREC Session 2012数据集上,我们验证了本文提出的带时间因子的隐式正负反馈算法TIPNF的有效性。
本文度量网页相似度时只尝试了余弦相似度,而SongHuaXu等在文献[6]中指出,在他们的工作中网页相似度度量方式的选择对结果有关键的影响,因此,在今后的工作中,我们会尝试不同的网页相似度度量方式,讨论TIPNF算法的鲁棒性。另外,我们将研究如何将隐式反馈信息融入到检索排序模型中,而不是本文使用的直接对检索结果进行重新排序。最后,时间因子的估计和使用方式也是一个有待继续探索的问题。
[1] Kanoulas E, Carterette B, Hall M, et al. Session track 2011 overview[C]//Proceedings of the 20th Text REtrieval Conference Notebook Proceedings (TREC 2011). 2011.
[2] Liu T, Zhang C, Gao Y, et al. BUPT_WILDCAT at TREC 2011 Session Track[R].
[3] Dou Z, Song R, Yuan X, et al. Are click-through data adequate for learning web search rankings?[C]//Proceedings of the 17th ACM conference on Information and knowledge management, 2008: 73-82.
[4] Xu S, Zhu Y, Jiang H, et al. A user-oriented webpage ranking algorithm based on user attention time[C]//Proceedings of the AAAI, 2008: 1255-1260.
[5] Joachims T, Granka L, Pan B, et al. Accurately interpreting clickthrough data as implicit feedback[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval, 2005: 154-161.
[6] Kubat M, Tapia M. Time spent on a web page is sufficient to infer a user’s interest[C]//Proceedings of the IASTED EuropeanConference on Proceedings of the IASTED European Conference: internet and multimedia systems and applications, 2007: 41-46.
[7] Liu C, Belkin N J, Cole M J. Personalization of search results using interaction behaviors in search sessions[C]//Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval, 2012: 205-214.
[8] Kelly D, Belkin N J. Display time as implicit feedback: understanding task effects[C]//Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval, 2004: 377-384.
[9] Chapelle O, Metlzer D, Zhang Y, et al. Expected reciprocal rank for graded relevance[C]//Proceedings of the 18th ACM conference on Information and knowledge management, 2009: 621-630.
[10] Järvelin K, Kekäläinen J. IR evaluation methods for retrieving highly relevant documents[C]//Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval, ACM, 2000: 41-48.
[11] Zhang B, Guan Y, Sun H, et al. Survey of user behaviors as implicit feedback[C]//Proceedings of the Computer, Mechatronics, Control and Electronic Engineering (CMCE), 2010 International Conference on IEEE, 2010: 345-348.
[12] 王斌.信息检索导论[M],北京:人民邮电出版社,2010: 1-2.
Exploration of Implicit Negative Feedback with Time Factorin Search Session
CHEN Zhenhong1,2, YU Xiaoming1, LIU Yue1, CHENG Xueqi1
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100190, China)
Implicit relevance feedback has been used to improve the performance of the retrieve system. In Contrast to the recent, most of the related work focusing on implicit positive feedback, this paperinvestigated the usefulness of combining both implicit positive and negative feedback with time factor. The implicit negative feedback used in this paper is the unclicked document before the clicked document in the same search session. By estimating the time spent on the title and snippet of the unclicked document, the time factor is introduced to infer the relationships between user’s interest and behaviors. Thus, a unified time factor model called TIPNF is proposed to use both implicit positive and negative feedback to improve the performance of the retrieve system. Experiments on TREC Session 2011 and 2012 verify the effectiveness and stabilization of the TIPNF.
search session; implicit negative feedback; time factor; rank

陈振宏(1988—),硕士,主要研究领域为大规模机器学习、分布式系统、社交网络。E⁃mail:chenzhenhong@software.ict.ac.cn俞晓明(1977—),博士,高级工程师,主要研究领域为互联网搜索与数据挖掘。E⁃mail:yuxiaoming@software.ict.ac.cn刘悦(1971—),博士,副研究员,主要研究领域为文本挖掘、Web搜索、复杂网络分析与社会计算。E⁃mail:liuyue@ict.ac.cn
1003-0077(2016)02-0113-08
2013-06-18 定稿日期: 2013-11-15
国家重点基础研究发展计划(973)(2012CB316303,2014CB340401);国家高技术研究发展计划(863)(2014AA015204,2014AA015103);国家自然科学基金(61232010);国家杰出青年科学基金(61425016);中国科学院重点部署项目(KGZD-EW-T03-2)
TP
A
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
四川大学学报(自然科学版)(2021年1期)2021-01-26 07:39:14
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
电子制作(2019年23期)2019-02-23 13:21:36
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
电子制作(2018年10期)2018-08-04 03:24:38
儿童绘本(2018年5期)2018-04-12 16:45:32
电子制作(2017年2期)2017-05-17 03:54:56
电子测试(2015年18期)2016-01-14 01:22:58
河北软件职业技术学院学报(2015年3期)2016-01-01 07:29:50
