
基于主位-述位结构理论的英文作文连贯性建模研究
2016-05-04 00:59王明文谢旭升李茂西万剑怡
中文信息学报 2016年1期
徐 凡,王明文,谢旭升,李茂西,万剑怡
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
基于主位-述位结构理论的英文作文连贯性建模研究
徐 凡,王明文,谢旭升,李茂西,万剑怡
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
该文在研究了有监督的基于实体和基于篇章关系网格的篇章连贯性模型的基础上,提出了一个无监督的基于主位-述位结构理论的篇章连贯性模型。该模型通过引入词语的词干、上下位、近义和复述等语义方面的信息来计算相邻句子中主位和述位的相似度,并利用此相似度值来描述篇章的连贯性。同时,该文提出了一种简单有效的基于篇章关系计数的连贯性模型,并采用线性组合方法将其与基于主位-述位结构理论的连贯性模型加以集成。上述模型在国际基准英文作文语料上进行试验,实验结果表明采用线性组合的连贯性模型后,作文连贯性检测准确率与目前基于实体和篇章关系网格的模型相比得到显著提升。
衔接性;连贯性;主位-述位结构理论;篇章关系;线性组合
1 引言
众所周知,作为主观题形式的英文写作更能考查出学生实际应用英语的能力。相比较表层的英语语法、词汇和句法等方面的错误而言,位于底层的句子间的衔接性和连贯性方式的缺乏或误用显得更为难以发现。一般来说,语篇(也称为篇章或文本)的衔接性和连贯性是句子构成篇章的两个最基本的特性。衔接性是连句成章的词汇和语法方面的手段,是语篇中表层结构上的粘着性,是语篇的有形网络;而连贯性是采用这些手段所产生的结果,是语篇中底层语义上的关联性,是语篇的无形网络[1]。由此可见,在篇章特性的刻画和建模方面,连贯性比衔接性显得更为重要。
篇章连贯性建模旨在对篇章中句子间的连贯性程度建立可计算模型,是自然语言处理的一个基础和关键问题,并逐渐成为国内外研究热点。因为它可以被广泛地应用在统计机器翻译[2]、篇章生成[3-4]、文本摘要[5-6]和学生写作自动评分[7-10]等许多与自然语言处理相关的应用中。
现有的连贯性模型主要包括基于内容的隐马尔可夫模型[4]、基于潜在语义分析的模型[11]、基于句法结构的模型[12]、基于实体的模型[13-16]、基于篇章关系的模型[17]、基于指代消解的模型[18-19]等。这些主流的篇章连贯性建模主要存在两大不足: 其一,忽略了篇章衔接性理论对连贯性建模的指导作用。实际上,根据功能语言学家韩礼德的主位-述位结构衔接性理论所述,人们认识事物一般按照从已知信息(主位)到未知信息(述位)的认知心理方式展开,主位部分对于信息传递和维护篇章的衔接性和连贯性有至关重要的作用,清晰而且合理的主位推进方式是语篇衔接性和连贯性的重要保证之一[20]。文献[21]认为很多英语学习者的作文缺乏连贯性的最主要的原因在于他们没有合理和有效地使用英语中的主位推进方式。然而,主位-述位结构理论仅在定性层面上分析了篇章的衔接性和连贯性,缺乏可计算性。为此,本文将主位-述位结构理论从定性层面拓展到定量层面,研究其可计算性问题。其二,主流的篇章连贯性模型均采用有监督的机器学习方法。它们一方面需要依赖于大规模而且高成本的人工标注语料库,另一方面与文本中抽取的平面或结构化特征具有极大的相关性,并且面临极其严峻的特征选择工程问题,即如何从这些海量特征中选择最为有效的特征集合。于是,本文着重研究无监督(不需要人工标注语料库)的篇章连贯性模型。
鉴于此,本文提出了一个无监督的基于主位-述位结构理论的篇章连贯性模型。该模型通过引入词语的词干、上下位、近义和复述等语义方面的信息来计算相邻句子中主位和述位的相似度,并利用此相似度来描述篇章的连贯性。同时,本文提出了一种简单有效的基于篇章关系计数的连贯性模型,并采用线性组合方法将其与基于主位-述位结构理论的连贯性模型加以集成。上述模型在国际基准英文作文语料上进行试验,实验表明采用线性组合的连贯性模型后,作文连贯性检测准确率与目前基于实体和篇章关系网格的模型相比得到显著提升。
本文内容组织如下: 第二节介绍篇章连贯性建模的相关工作;第三节重点阐述了本文提出的基于主位-述位结构理论的篇章连贯性模型;第四节描述了本文提出的另外一种简单并且有效的基于篇章关系计数的连贯性模型,并阐述了如何将它与基于主位-述位结构理论的连贯性模型加以集成;第五节给出了实验设置及详细的结果分析;第六节是本文的结论和将来工作部分。
2 相关工作
代表性的篇章连贯性建模工作主要分为两大类: 其一是无监督的篇章连贯性模型[4,11];其二是有监督的篇章连贯性模型[12-19]。
(1) 针对无监督的篇章连贯性模型,文献[4]基于隐马尔可夫模型(Hidden Markov Model,HMM),将篇章中的话题看作隐状态,并把句子看作观察,通过捕获篇章中话题的转换方式来指导篇章连贯性建模。Foltz等[11]利用文本中相邻两个句子的语义相关性来表示篇章的连贯性,并采用潜在语义分析(Latent Semantic Analysis,LSA)[22]计算相邻句子的相关度。然而,此模型需要依赖较多的参数和额外的资源: 其一,如何设置一个适当的初始语义空间维度并如何对高维数据进行降维;其二,如何选择合适的语料去创建有效的语义空间。
(2) 针对有监督的篇章连贯性模型,文献[12]从句法结构角度研究篇章连贯性建模,探索了文本中相邻两个句子的句法结构转换机制,并建立了基于句法树产生规则的篇章连贯性模型。文献[13-15]受中心理论[23]启发提出了基于实体的篇章连贯性模型,利用篇章中出现的实体间的延续关系对篇章连贯性进行建模。她们通过篇章实体及其实现的语法角色所构成的篇章实体矩阵来捕获文本中相邻两个句子的实体分布。文献[16]对文献[13-15]的工作进行了扩展,着重研究了训练语料中源文本和置换文本间的关系,并显示了多重排序而非成对排序对于篇章连贯性建模的有效性。文献[17]则从篇章关系角度对篇章连贯性进行建模,同时采用显式和隐式四大类型的篇章关系(时序性Temporal、可能性Contingency、对比性Comparison和扩充性Expansion)对文献[13-15]的实体模型进行扩展。文献[17]首先将基于实体模型中的语法角色替换成篇章关系,然后采用有监督的排序学习技术对篇章的连贯性进行建模。此外,文献[18]和文献[19]提出了基于名词短语指代消解的篇章连贯性模型,并分别显示了篇章中名词短语的指代消解对于篇章连贯性建模存在着重要的指导作用。
3 基于主位-述位结构理论的篇章连贯性模型
主位-述位结构理论是功能语言学上描述篇章衔接性方面的重要理论,仅从定性层面描述了篇章中句子间的衔接方式。本文将其从定性层面拓展到定量层面,研究其可计算性问题,并利用它指导篇章的连贯性建模。本节首先简要介绍系统功能语法的主位-述位结构理论,然后着重阐述基于此理论的篇章连贯性模型。
3.1 主位-述位结构理论简介
根据Halliday所述,主位是说话者表达思想的出发点,而述位是围绕主述展开的事实性内容。一般来说,主位代表的是已知信息,即说话者和听话者双方都明确的信息,而述位代表的是未知信息,它往往是指说话者知道而听话者不知道的信息。为了清晰起见,我们通过例1进行更为详细的解释(主位部分采用下划线表示,述位部分采用斜体表示)。
例1 The book you lent meisveryinteresting.
其中,例1的主位部分是双方都预先明确的已知信息。相反,述位部分是未知信息,它一般围绕主位部分而展开。如,例1中的“这本书怎么样?”等。
同时,Halliday认为主位部分在语篇的组织结构方面具有重要作用,清晰的主位推进(thematic progression)保证了语篇的衔接性,把主位推进定义为语篇中各个句子的主位部分构成的一个主位序列,并提出了多种主位推进模式。后来,很多学者都纷纷从事主位推进模式研究,他们试图概括出通用的主位推进模式。出于主位推进模式的计算机实现方面的考虑,本文采用文献[24]提出的三种主位推进模式: (a)前一句的主位部分推导出后一句的主位部分,即Ti—>Ti+1模式(这里i代表文本中句子的序号,下同);(b)前一句的述位部分推导出后一句的主位部分,即Ri—>Ti+1模式;(c)前一句的主位和述位部分联合推导出后一句的主位部分,即Ti+Ri—>Ti+1模式。为清晰起见,表1列出文献[21]中的三种主位推进模式实例。
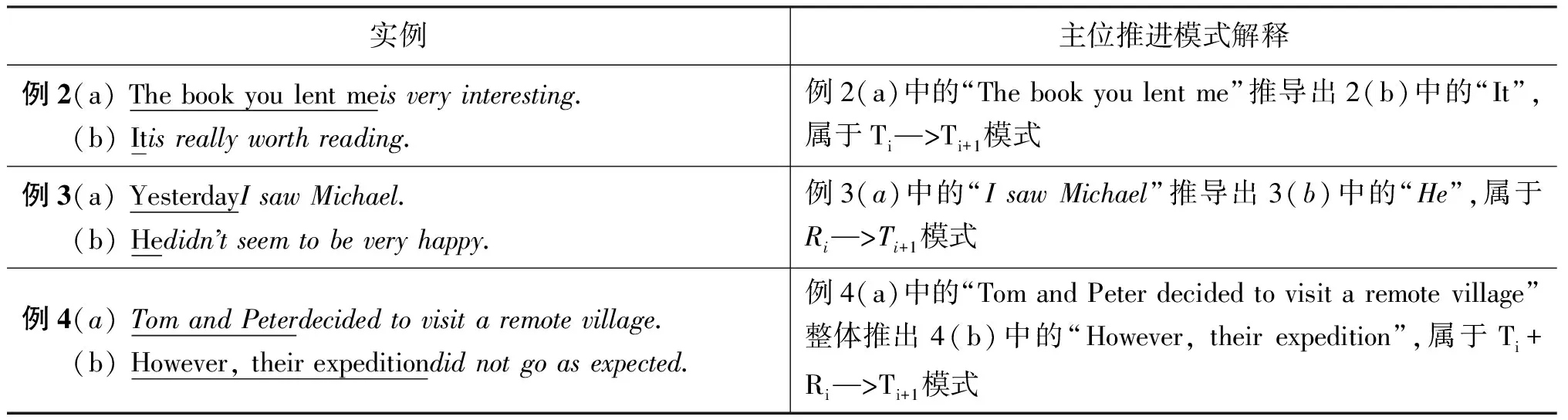
表1 主位推进模式实例
3.2 基于主位-述位结构理论的篇章连贯性建模
本文将主位-述位结构理论可计算化,把相邻两个句子的主位推进程序模式的相似度作为篇章整体连贯性得分,并将其得分作为判断篇章是否连贯的标准。篇章连贯性建模过程包括以下两个步骤。
第1步 句子中主位和述位的识别
根据Halliday所述,句子中谓语部分是标识主位和述位的临界点。基于此,本文提出了图1所示的主位和述位识别算法。
算法主要功能如下: 对于任意一篇文本,我们对文本中的每个句子进行词性标记任务,然后找出每句的首位动词,如果存在动词,则将动词前部分作为主位部分,将动词以及它的后面部分作为述位部分;否则将句子平均切分,前一部分作为主位部分,后一部分作为述位部分。
第2步 篇章连贯性得分计算
本文采用美国卡耐基梅隆大学提出的机器翻译评测指标METEOR(Metric for Evaluation of Translation with Explicit word ORdering)*http://www.cs.cmu.edu/~alavie/METEOR/计算相邻句子的主位和述位部分的相似度。原因在于: 其一,METEOR采用单精度的加权调和平均数和单字召回率方法,能够取得与人工判断的具有较高相关性的机器翻译评测结果;其二,METEOR在计算源句子和翻译句子的相似度时引入了更多的语义方面信息(例如,单词的词干、WordNet中的同义词、上下义词、复述等),本文预期这些信息对于篇章连贯性建模将具有重要作用。
具体而言,对于给定一篇文档,本文采用图1所示的主位和述位识别算法对每一句进行划分,标记出每个句子的主位和述位部分;然后,采用METEOR分别计算相邻两个句子的以上三种主位推进程序的相似度;最后将相似度得分进行求和取均值,分别作为三种主位推进程序模式下的文本连贯性得分,如式(1)所示。

图1 主位和述位识别算法
ThemeRhemeCohesionScore(Text)=
(1)
其中,N代表任意一篇作文的句子总数,MeteorSim()代表采用机器翻译评测指标METEOR计算的相似度(式(2)),Uij代表相似度的计算单元,例如,i=1,j=1代表第1句的主位部分;i=1,j=2代表第1句的述位部分;i=1,j=3代表第1句的主位+述位部分(整个句子)。

(2)
其中,P=M/T用来计算句子相似度的精确度,R=M/R用来计算句子相似度的召回率。这里,M代表所述源句和所述目标句中匹配的一元文法个数,R代表所述源句的一元文法个数,T代表所述目标句的一元文法个数,a是平衡因子,以权衡P和R值在计算相似度时的作用,满足0≤a≤1。本文选择Meteor的默认a值(0.85)。
此外,出于模型的通用性考虑,本文将Ti—>Ti+1,Ti—>Ti+1和Ti—>Ti+1三者的相似度得分先取最大者,然后将其求和取均值(模型记作SumMax),如式(3)所示。
SumMaxThemeRhemeCohesionScore(Text)=
MeteorSim(Ri->Ti+1),
(3)
其中,MeteorSim(Ti—>Ti+1),MeteorSim(Ri—>Ti+1),MeteorSim(Ti+Ri—>Ti+1)分别代表三种主位推进程序的相似度。
4 基于篇章关系计数的篇章连贯性模型及集成
本节主要阐述篇章关系在连贯性建模中的应用,并提出基于篇章关系计数的连贯性模型。同时介绍如何利用线性组合方式将其与基于主位-述位结构理论的连贯性模型加以集成。
4.1 基于篇章关系计数的篇章连贯性建模
篇章关联词是一种典型的显式篇章衔接手段,对于维护整个篇章的上下文连贯性具有重要的作用。一般来说,连贯的篇章中往往使用较多的篇章关联词。一般而言,篇章关联词是篇章关系(如: Temporal,Contingency,Comparison,Expansion等关系)的指示标志。为清晰起见,本文采用例5和例6加以说明。
例5 Selling picked up as previous buyers bailed out of their positions and aggressive short sellers- anticipating further declines-moved in. (篇章关联词“and”指示“Expansion”篇章关系)
例6 My favorite colors are blue and green.
上述例5和例6中均具有关联词“and”。其中,例5中的“and”充当篇章关联词连接两个从句“Selling picked up as previous buyers bailed out of their positions”和“aggressive short sellers-anticipating further declines-moved in.”,而例6中的“and”却不充当篇章关联词。
基于上述分析,如何识别出篇章中所有的篇章关系便成为关键问题。不同于文献[17]的工作,他们同时考虑了显式和隐式篇章关系(不存在显式的篇章关联词情形),但是隐式篇章关系识别性能仅为40%左右,而且同样需要依赖于大规模的人工标注语料。这些额外条件在一定程度上制约了文献[17]方法在大规模数据环境中的适用性。由于文献[25]已经提出了高性能的显式篇章关系识别的方案(AddDiscourse),利用篇章连接词等词汇、句法和语义等方面的特征,采用机器学习方法取得了96.26%的识别性能,因此本文直接采用文献[25]的方法进行显式篇章关系识别。本文提出的基于篇章关系计数的连贯性建模过程包括以下两个步骤。
第1步: 篇章关系识别
对任意一个文本中的每一句采用上述AddDiscourse工具识别出篇章关系。
第2步: 篇章连贯性得分计算
当识别出篇章关系后,本文采用式(4)表示一篇文本的篇章连贯性评分。

(4)
其中,#disRel代表篇章关系的个数,N代表篇章中句子总数。
4.2 篇章连贯性分析组合模型
为了验证基于主位-述位结构理论的模型和基于篇章关系计数的模型是否具有协同性,本文利用两者的线性组合方式,提出了一种组合模型,如式(5)所示。
SumMaxCompositeCoherenceScore(Text)=
α*SumMaxThemeRhemeCohesionScore(Text)+
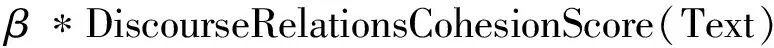
(5)
其中,α和β代表主位-述位连贯性和篇章关系连贯性在学生作文连贯性评估中所占的比例,满足α+β=1,α≥0和β≥0。
5 实验设置和结果分析
为了验证本文提出的篇章连贯性模型的有效性,我们采用国际基准英文作文语料分别设计了三组篇章连贯性检测实验。第一组实验用于验证基于主位-述位结构理论的连贯性模型检测性能;第二组实验用于验证基于篇章关系计数的连贯性模型检测性能;第三组实验用于验证两者线性组合下的连贯性模型检测性能。本节首先简要介绍实验设置,然后给出详细的实验结果和分析。
5.1 实验设置
本文采用文献[8]发布的ESOL(EnglishasaSecondorOtherLanguage)学生作文语料作为实验数据集。它是目前唯一可公开获取的国际基准英文作文语料。为清晰起见,图2描述了一个ESOL学生作文测试语料实例。

图2 ESOL学生作文测试语料实例
需要说明的是语料库对整篇作文进行了评分,包括了反应作文质量的多个方面,例如,措词、连贯性、合乎语法性等。但是,一般来说,一篇作文的评分越高,它的连贯性程度也越高。相应地,如果一篇作文的评分高于所有作文评分均值(人工评分或模型评分),本文认为它是连贯性文本,否则将其作为非连贯性文本。为此,本文选用了语料ESOL下2000年的1 141篇学生作文作为训练语料,计算出来的得分平均值作为2001年1~6月份的97篇测试语料的门限值。之所以选择此语料的2001年的97份文本作为测试数据,原因在于语料发布人员仅发布了这97篇作文对应的两位标注人员的人工评分值。于是,本文可以利用这些人工评分值与这97篇作文的人工平均分进行对比,将大于人工平均分的作文作为连贯的作文,小于人工平均分的作文作为不连贯的作文,从而可以计算出作文的人工连贯性程度,作为篇章连贯性检测性能上限。
此外,本文采用Brown大学所开发的通用篇章连贯性检测工具Melsner*https://bitbucket.org/melsner/browncoherence/downloads生成基于实体的篇章连贯性得分,采用SENNA*http://ml.nec-labs.com/senna/工具对作文进行词性标记,采用Berkleyparser*http://code.google.com/p/berkeleyparser/对作文进行短语句法分析。由于作文语法修订工具的不可获取性,我们直接采用作文中原始句子作为训练和测试语料,并采用准确率(Accuracy)作为模型的性能评测指标,即模型能检测出的正确和不正确的连贯性作文篇数占总作文篇数的比例。
5.2 实验结果分析
由于本文采用主位-述位结构理论指导篇章连贯性建模,于是主位和述位的识别性能将至关重要。表2列出了主位和述位的算法识别性能和人工标注性能。其中人工标注过程为: 从文献[13]发布的Earthquake和Accident语料中随机选择了100篇文本,首先请两位高年级的研究生手工标注出这100篇文本中每一个句子的主位和述位部分,然后将他们标注一致的部分作为标准答案,并与图1所示算法识别出的主位和述位部分进行对比。根据表2的实验数据,我们可以明确: 与人工标注性能相比,本文提出的基于规则的主位和述位识别算法具有可行性。同时,需要强调的是本文提出的主位和述位识别算法是以最先出现的动词作为主位和述位切分的标准,另外我们也利用了Stanford句法分析器*http://nlp.stanford.edu/software/lex-parser.shtml对每个句子进行依存句法分析,然后抽取出句子的主要谓词(mainpredicate),并将其作为切分主位和述位的依据,但并没有带来主位和述位识别性能的提升(对应的主位和述位识别性能为81.90%)。这也从侧面说明了本文提出的主位和述位识别算法的简单有效性。
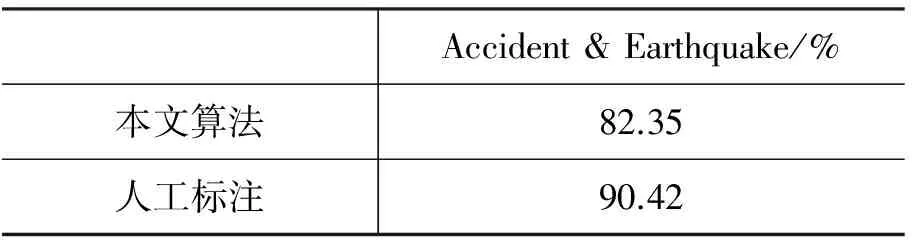
表2 主位-述位识别性能
表3列出了本文提出的单个模型和组合模型下的性能,并与代表性的篇章连贯性模型进行了对比。同时,为了验证相似度计算单元的影响,我们也给出了将相邻的整个句子作为篇章连贯性的计算单元下的实验性能。由于Lin模型[17]仅报告了通用领域(新闻领域)下的篇章连贯性检测性能,于是本文针对有噪音的ESOL语料重现了基于篇章关系网格的模型[17],并且采用文献[17]和文献[13]同样的评价方法(accuracy)进行作文连贯性评估,构造ESOL中训练语料中成对的(连贯性强作文,连贯性弱作文)训练和测试数据,采用五倍交叉验证进行试验。实验结果表明:
(1) 直接采用完整句子作为相似度计算的单元明显低于随机方式50.00%的Accuracy,同时低于三种主位推进程序模式所取得的检测性能。它一方面说明了直接把整个句子作为处理单元时粒度太粗,从而导致区分度不高,另一方面也说明了主位-述位结构理论对于学生作文连贯性评估的可行性,即将句子切分成主位和述位部分,然后再计算相似度这种形式更加有效。本文认为原因在于学生作文的水平高低不等,有些作文存在大量的噪音(例如,错词、错误的表达等),从而导致了整个句子的相似度比较低。同时,基于实体或篇章关系网格的模型所取得的性能略高于随机方法。本文认为原因在于基于实体或篇章关系网格的模型比较适合通用文体(新闻领域),因为这些新闻文本具有明显的表示时序(Temporal)、可能性(Contingency)、对比(Comparison)和扩充(Expansion)逻辑关系,但对于有噪音的学生作文语料却不太适用。
(2) 在这三种不同的主位推进程序中,Ti—>Ti+1模式取得了最好56.70%的Accuracy,其高于随机方法所取得的性能。我们认为原因在于作者往往采用主位扩展主位或主位扩展主位的写作方式或习惯来展开全文。 同时,本文提出的SumMax模型也取得了55.67%的Accuracy,这充分验证了SumMax具有通用性,这为模型合成提供了实验数据基础。
(3) 本文提出的基于篇章连贯性的学生作文连贯性SumMax模型和基于篇章关系计数的模型均具有重要的作用,而且这两种模型可以采用较为简单的线性组合方式加以集成(取得了64.43%的检测性能)。造成集成模型与单个模型性能存在较大差异的原因在于基于主位结构的模型生成的作文连贯性分数较低(平均分为0.031 06),相反基于篇章关系的模型生成的作文连贯性分数较高(平均分为0.273 9),为了提升基于主位结构的模型的分数,本文在计算平均分数时增大了它的权重(α*主位结构的平均分+α*篇章关系的平均分)),相应地将集成后的分数(α*主位结构的平均分+β*篇章关系的平均分)与平均分进行比较,从而提升了集成后系统的性能。相比人工连贯性,完整或切分句子方法下的学生作文连贯性评估任务性能都不太高,这也从侧面说明了学生作文连贯性评估任务的挑战性,因为学生在写作时通常会采用多种复杂的形式,例如,缺省和指代(尤其是零指代现象)等。

表3 ESOL语料上实验结果及对比
此外,为了验证主位和述位识别精度对本文方法的性能影响如何,我们进一步对有噪音的ESOL语料进行了主位和述位识别实验,经过我们对ESOL语料的统计,有近30%左右的动词存在形式错误,导致词性标记的时候不能正确识别出它们的“VB”词性,同时我们选择了ESOL的200句由两位标注者进行标注,由于这些错误的动词导致计算出来的标注kappa值约为0.40,具有比较弱的一致性。我们将两位标注者认为一致的约80句对应的三篇作文进行了连贯性实验,一方面利用本文算法识别出来的主位和述位计算作文的连贯性得分(平均分0.031),另一方面利用人工切分的主位和述位计算作文的连贯性得分(平均分0.029),由于这两者的连贯性得分非常相近,导致主位和述位识别算法对最终的连贯性评估性能没有影响。所以,我们认为本文的主要出发点还是在于探索了完整句和切分句后对于文本连贯性检测的性能影响,其中完整句的连贯性识别性能为49.50%,切分后的连贯性识别性能为56.70%,对于切分之后的几个单词边界带来的错误对于系统的最终连贯性得分影响极小。
6 结论和将来工作
不同于有监督的基于实体和篇章关系网格的篇章连贯性模型,本文探索了功能语言学家Halliday提出的系统功能语法中主位-述位结构理论驱动下的新型无监督的篇章连贯性模型。该模型通过引入词语的词干、上下位、近义和复述等世界知识方面的信息来计算句子中主位和述位的相似度,并利用此相似度值来描述篇章的连贯性。同时,本文提出了一种简单有效的基于篇章关系计数的连贯性模型,并采用线性组合方法将其与基于主位-述位结构理论的连贯性模型加以集成。通过国际基准英文作文语料上的实验结果表明主位-述位结构理论和篇章关系信息能使篇章连贯性检测准确率得到显著提升。
作为将来工作,我们一方面将此模型应用于汉语作文环境,并针对汉语本身所具有特点进行模型的修改和扩充;另一方面,我们将基于此模型构建一个完整学生作文自动评分平台。
[1] 黄国文. 语篇分析概要[M]. 长沙:湖南教育出版社,1987:1-221.
[2] Fox H J. Phrasal cohesion and statistical machine translation[C]//Proceedings of the Empirical Methods in Natural Language Processing (EMNLP). Philadelphia, U.S.A., Association for Computational Linguistics Press: 2002: 304-311.
[3] Soricut R, Marcu D. Discourse generation using utility-trained coherence models[C]//Proceedings of the Joint Conference of 44th Annual Meeting of the Association for Computational Linguistics and 21st International Conference on Computational Linguistics (ACL-COLING). Sydney, Australia, Association for Computational Linguistics Press: 2006: 803-810.
[4] Barzilay R, Lee L. Catching the drift: probabilistic content models, with applications to generation and summarization[C]//Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (HLT-NAACL). Boston, Massachusetts, U.S.A., Association for Computational Linguistics Press: 2004:113-120.
[5] Lin Z H, Liu C, Ng H W, et al. Combining coherence models and machine translation evaluation metrics for summarization evaluation[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (ACL). Jeju Island, Korea, Association for Computational Linguistics Press: 2012:1006-1014.
[6] Bollegala D, Okazaki N, Ishizuka M. A bottom-up approach to sentence ordering for multi-document summarization[C]//Proceedings of the Joint Conference of 44th Annual Meeting of the Association for Computational Linguistics and 21st International Conference on Computational Linguistics (ACL-COLING). Sydney, Australia, Association for Computational Linguistics Press: 2006: 385-392.
[7] Yannakoudakis H, Briscoe T. Modeling coherence in ESOL learner texts[C]//Proceedings of the 7th Workshop on the Innovative Use of NLP for Building Educational Applications. Montreal, Canada, Association for Computational Linguistics Press: 2012:33-43.
[8] Yannakoudakis H, Briscoe T, Medlock B. A new dataset and method for automatically grading ESOL texts[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL). Portland, Oregon, Association for Computational Linguistics Press: 2011:180-189.
[9] Burstein J, Tetreault J, Andreyev S. Using entity-based features to model coherence in student essays[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL). Uppsala, Sweden, Association for Computational Linguistics Press: 2010: 681-684.
[10] Higgins D, Burstin J, Marcu D, et al. Evaluating multiple aspects of coherence in student essays[C]//Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics. (HLT-NAACL). Boston, Massachusetts, U.S.A., Association for Computational Linguistics Press: 2004: 185-192.
[11] Foltz P W, Walter K, Thomas K L. The measurement of textual coherence with latent semantic analysis[J]. Discourse Processes,1998,25(2&3):285-307.
[12] Louis A, Nenkova A. A coherence model based on syntactic patterns[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CNLL). Jeju Island, Korea, Association for Computational Linguistics Press: 2012: 1157-1168.
[13] Barzilay R, Lapata M. Modeling local coherence: an entity-based approach[J]. Computational Linguistics,2008,34(1):1-34.
[14] Barzilay R, Lapata M. Modeling local coherence: an entity-based approach[C]//Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL). Ann Arbor, Association for Computational Linguistics Press: 2005: 141-148.
[15] Lapata M, Barzilay R. Automatic evaluation of text coherence: models and representations[C]//Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI). Edinburgh, Scotland, U.K.: 2005: 1085-1090.
[16] Feng V W, Hirst G. Extending the entity-based coherence model with multiple ranks[C]//Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics (EACL). Avignon, France, Association for Computational Linguistics Press: 2012: 315-324.
[17] Lin Z H, Ng H T, Kan M Y. Automatically evaluating text coherence using discourse relations[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL). Portland, Oregon, Association for Computational Linguistics Press: 2011: 997-1006.
[18] Iida R, Tokunaga T. A metric for evaluating discourse coherence based on coreference resolution[C]//Proceedings of the 24th International Conference on Computational Linguistics (COLING). IIT Bombay, Mumbai, India: 2012:483-494.
[19] Elsner M, Charniak E. Coreference-inspired coherence modeling[C]//Proceedings of the Human Language Technology Conference of the 46th Association for Computational Linguistics (ACL: HLT). Columbus, Ohio, USA, Association for Computational Linguistics Press: 2008: 41-44.
[20] Halliday M A K. An Introduction to Functional Grammar[M]. New York: Oxford University Press Inc., 2004:1-700.
[21] 程晓堂. 从主位结构看英语作文的衔接与连贯[J]. 山东师范大学学报,2002,(2):94-98.
[22] Landauer T K, Dumais S T. A solution to plato’s problem: the latent semantic analysis theory of acquisition, induction and representation of knowledge[J]. Psychological Review, 1997,104(2):211-240.
[23] Grosz B J, Weinstein S, Joshi A K. Centering: a framework for modeling the local coherence of discourse[J]. Computational Linguistics, 1995,21(2):203-225.
[24] 胡壮麟. 语篇的衔接与连贯[M]. 上海:上海外语教育出版社,1994:1-235.
[25] Pitler E, Nenkova A. Using Syntax to Disambiguate Explicit Discourse Relations in Text[C]//Proceedings of the the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP (ACL-IJCNLP).Suntec, Singapore, Association for Computational Linguistics Press: 2009: 13-16.
Coherence Modeling for English Student Essay Based on Theme-rheme Structure Theory
XU Fan, WANG Mingwen, XIE Xusheng, LI Maoxi, WAN Jianyi
(School of Computer Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China)
This paper presents an unsupervised theme-rheme structure theory based discourse coherence model, in contrast to the current supervised entity based model and the discourse relation grid based model. Our model describes discourse coherence via calculating the similarity between theme or rheme of adjacent sentences through incorporating more semantic knowledge like word stem, hypernym, hyponym, synonym and paraphrase etc. Meanwhile, this paper also presents a simple and effective coherence model based on counting the number of discourse relations within a discourse, and integrates the theme-rheme-based model using linear combination method. Evaluation on benchmark English student essay dataset reveals the effectiveness of our linear combination discourse coherence model, significantly outperforming baselines the literature.
cohesion; coherence; theme-rheme structure theory; discourse relation; linear combination

徐凡(1979-),博士,讲师,主要研究领域为自然语言处理和中文信息处理。E⁃mail:xufan@jxnu.edu.cn王明文(1964-),博士,教授,主要研究领域为信息检索、数据挖掘、自然语言处理。E⁃mail:mwwang@jxnu.edu.cn谢旭升(1963-),教授,主要研究领域为数据库技术及应用、软件设计及应用。E⁃mail:xiexusheng@sina.com
1003-0077(2016)01-0115-09
2013-06-25 定稿日期: 2014-05-09
国家自然科学基金(61402208, 61462045,61562042),江西省教育厅项目(GJJ150351)
TP
A
猜你喜欢
中国药学药品知识仓库(2022年7期)2022-05-10
通信技术(2021年12期)2022-01-25
天津外国语大学学报(2021年3期)2021-08-13
疯狂英语·新悦读(2021年1期)2021-01-27
新生代(2018年23期)2018-10-22
智富时代(2018年6期)2018-08-06
智富时代(2018年6期)2018-08-06
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
