
搜索引擎的一种在线中文查询纠错方法
2016-05-04 00:59刘云峰杨海松张小鹏段建勇乔建秀
中文信息学报 2016年1期
胡 熠,刘云峰,杨海松,张小鹏, 段建勇, 张 梅, 乔建秀
(1. 阿里巴巴(中国)网络技术有限公司, 浙江 杭州 310052; 2. 腾讯公司, 广东 深圳 518057; 3. 北方工业大学 信息工程学院, 北京 100144)
搜索引擎的一种在线中文查询纠错方法
胡 熠1,刘云峰2,杨海松2,张小鹏2, 段建勇3, 张 梅3, 乔建秀2
(1. 阿里巴巴(中国)网络技术有限公司, 浙江 杭州 310052; 2. 腾讯公司, 广东 深圳 518057; 3. 北方工业大学 信息工程学院, 北京 100144)
该文主要解决中文搜索引擎的查询纠错问题。错误的查询,已经偏离用户真实的搜索意图时,搜索质量很差,甚至导致搜索结果数为零。为此该文提出了一种服务于实际搜索引擎,较为完整的查询纠错方案。该文重点描述了纠错查询候选生成、纠错查询候选评价、以及基于核函数,挑选最优纠错查询候选等内容。通过在开放测试集上的准确率/召回率验证,以及在搜索引擎中实际的DCG评测,该文的方案都取得了较好的效果。
中文查询纠错; 多特征; 核函数排序
1 前言
网页搜索引擎输入的中文查询中,有一部分带有输入错误的查询,往往得不到好的搜索结果:返回的网页或者数量很少,或者和用户的期待相差很远,严重影响了用户的使用体验。例如,对查询“火箭对振勇士直拨”,搜索引擎找不到用户满意的网页。如果能纠错成符合用户意图的正确的查询“火箭对阵勇士直播”,并用后者的结果代替前者,可以极大增加用户对搜索引擎智能性的良好体验。英文查询有拼写错误的占到总查询的10%到15%[1]。我们从检索日志统计中看到,有输入错误的中文查询也要占到所有查询的10%以上。中文查询出错的原因很多,形式多种多样。归纳起来,错误主要形式如表1中所列。

表1 中文查询的七种主要错误形式

续表
表1概括了我们遇见的大部分中文错误类型。由于当前主流中文输入法是拼音输入法,所以1~3是主要的错误形式,占错误查询的较大比例,而4~7比例则较小。事实上,1~3都可以归结到“拼音纠错”模式,而4需要对基于键盘分布导致按键出错的行为进行建模,5~7需要对中文表达合理性进行建模。
本文通过离线挖掘的方式得到
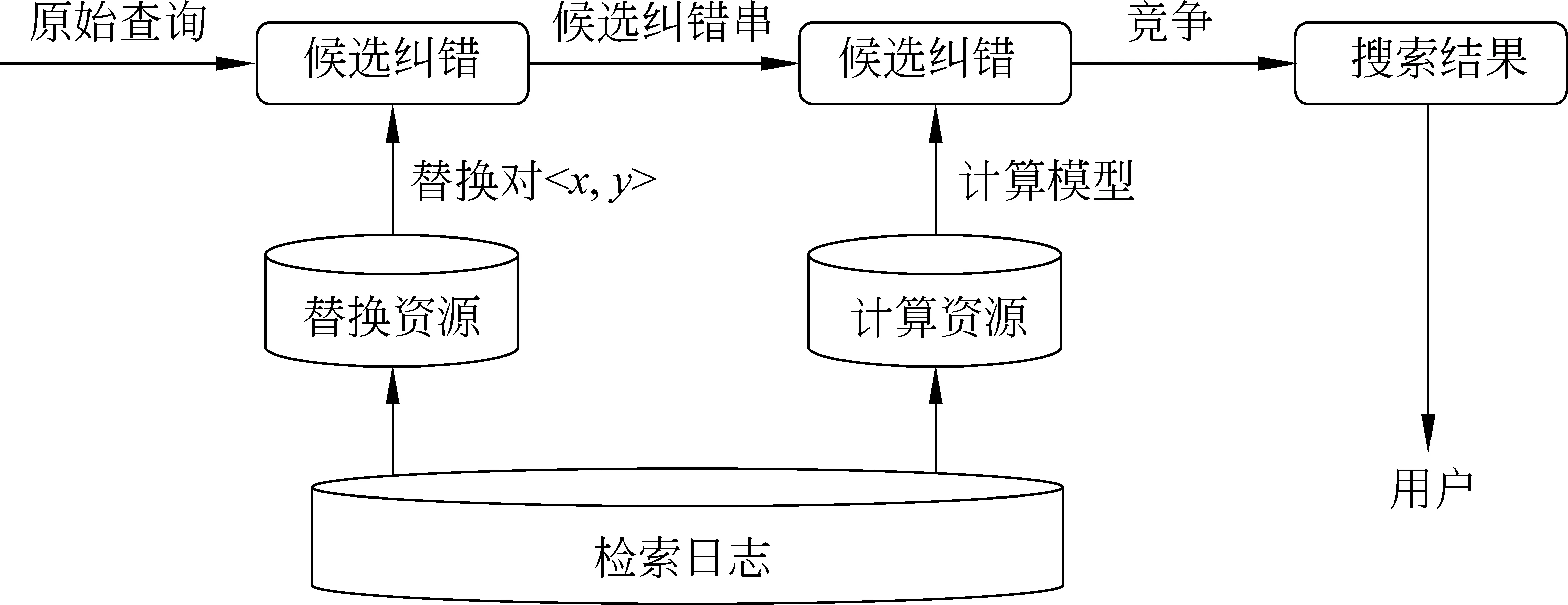
图1 查询纠错流程
本文的纠错方案是:先替换原查询中疑似需要修改的局部,再根据多种判断依据,排序所有的候选纠错查询,找到最合适的纠错。
2 相关研究
以往大量的研究工作集中在英文的查询纠错,而英文查询的错误在于词的拼写错误和真实词的使用错误。基于这样的任务设定,英文查询纠错很自然地分成两条主要的研究路线,分别针对不同的纠错类型。
有拼写错误的词是那些不存在于词表中的“词”,查询中出现拼写错误的词,其纠错的目标就是用词表中正确的对应词替代它。此时工作重点在于为查询中不存在于词表的词生成一个候选词表,并为每一个候选词表按某个指标排序。侯选词的排序可以基于人工设定的分数,给不同的编辑距离赋予不同的得分;或参考侯选词在语料库中的频次,出现的频率较高的,排序越靠前[2]。很明显,这种纠错方式不够灵活,相同的错误词纠错结果是一样的。近些年来, 噪声信道模型被广泛应用于查询纠错[3-8], Brill and Moore[6]提出一种改进的基于噪声信道模型的纠错方法, 允许对一般性的串到串的编辑操作进行建模。而Toutanova and Moore[7]引入对英文单词“发音”信息的显式建模, 进一步改进了基于噪声信道模型的纠错。 Ahmad and Kondrak[8]则从用户查询日志来学习这个模型,证明用户查询日志可用。Li et al 在文献[3]中从query log中通过分布相似性发现错误单词及其对应的正确单词,挑选所有和原查询在一定编辑距离内的候选串作为纠错结果。Chen et al[4]的工作是Li et al.的延续,进一步用搜索结果来决定质量较高的纠错. Gao et al[5]把噪声信道模型融合在一个更通用的排序方案中,允许比较灵活地加入排序特征。
真实词纠错也可以看作是上下文相关的词纠错。它试图检测当前特定上下文环境下,一个词表中存在词的不恰当的使用,也就是说待纠错的词本身是一个真正的词,但是在当前上下文中使用不当。针对这个任务的常规做法是使用一个预先定义好的混淆集(Confusion Set)[9-10]。对于真实词是否适用的判断,需要更多的上下文信息。
Duan等人[11]研究了在线query输入过程中的实时纠错问题。他们为此提出一个生成模型,通过无监督的方式训练了一个马尔科夫转换模型用来捕捉用户的输入行为,取得了一定的效果。
3 查询纠错系统
中文的查询纠错,和英文真实词纠错在原理上有类似之处,因为都无法通过词典中没有的字或词触发,所以需要对每个查询尝试纠错。本文中文纠错的解决方案,在离线和在线阶段由四个主要步骤实现。
Step 1. 从带标记的<错误查询,正确查询>的对齐语料和日志中挖掘可以用于替换的<错误片段, 正确片段>,包括中文形式和拼音形式;
Step 2. 在查询中发现了替换资源的错误片段时,尝试把疑似错误片段替换为相应的正确片段,遍历所有可能的替换之后,可形成多个纠错查询候选;
Step 3. 假如有N个候选纠错查询,这N个候选纠错查询按相对于原串质量的高低排序,得分最高的并且质量高于原查询的候选纠错查询,认为是原查询的纠错;
Step 4. 最佳纠错查询和原来的查询一起去检索,如果发现原串的检索结果质量相比候选串的检索结果质量更高,那么不采用候选纠错查询的结果。我们称之为“结果竞争”机制。
正如图 1所描述的,本文纠错系统的替换资源和计算资源都是从检索日志中得到。离线资源之上是系统的在线纠错流程。可以用表2中的算法描述。

表2 在线查询纠错算法
由于篇幅限制,替换资源的挖掘(1)、结果竞争(4)在本文不做详细介绍,会另撰文阐述。而算法描述的在线纠错系统的执行流程的其他环节的详细内容将在3.1~3.4节中阐述。
3.1 候选纠错查询生成
一个错误片段,对应着多个可能的正确片段。查询经历局部替换的过程中,每一次替换,增加若干候选纠错查询。我们仍然用前文的例子说明:“火箭对振勇士直拨” 其中 “对振”可以替换成“对阵”, “直拨”可以替换成“直播”。如图2所示,其中每个节点是一个词切分单元。

图2 候选纠错查询生成示意图
从“开始S”到“结束E”总共有四条路径,分别对应四个查询(包括原串)
(1) 火箭对振勇士直拨 (原串)
(2) 火箭对阵勇士直拨
(3) 火箭对振勇士直播
(4) 火箭对阵勇士直播
从常识来看,(4)才是最优的查询。显然,如果“对振”不仅仅可以替换为“对阵”,或者“直拨”不仅仅可以替换为 “直播”,那么可生成的候选纠错查询将会更多。
3.2 寻找最优的候选纠错查询
因为存在多种替换的可能,所以寻找最优候选纠错查询,本质上是一个排序问题。以候选纠错查询相对于原查询的质量高低来选择最优解,如公式(1)所示。
(1)
在这里,q是原始查询,q′是某一个候选纠错查询,r(x)是一个评分函数, 而整个函数的意义就是挑选得分最高的候选纠错查询q*。 任意一个q′,相对于q,生成用于排序的特征, 这些特征的集合用向量x表示x=(f1,f2,...fn)T,组成x的特征f在后面详细介绍。本文要得到一个区分“Good Correction”和“Bad Correction” 二元分类的分类界面,可以在支持向量的理论框架下来得到分类界面[12]。本文用来判断
3.3 候选纠错查询的质量评估
在本文查询纠错的任务中,可用于给候选纠错查询打分的信息考虑了多样性:候选纠错查询本身的质量如何,可以用历史上这个候选串在搜索引擎中的点击通过率(Click Through Rate,后文简称ctr)来刻画;也可以用这个候选纠错查询在多大程度上符合人的“语言习惯”来说明它的质量(Language Model, LM);从全局角度,替换的部分是否和环境中其他词更搭配(Pointwise Mutual Information, PMI);其他的判断依据还包括拼音是否相似(主要针对字符纠错而言);所用到的替换在历史上是否是一个好的经验替换;替换前后词切分个数的变化等。
3.3.1 点击通过率特征
在搜索历史上,一个候选纠错查询q′如果被不同用户提交次数越多,提交后用户点击了搜索引擎返回结果的比例越高,则越可能说明这个候选纠错查询的质量越高,如式(2)所示。
(2)
其中ctr(q′)表示候选纠错查询q′ 的点击通过率得分,search(q′)表示候选纠错查询q′被提交的次数,click(q′)表示q′提交给搜索引擎后,用户点击了返回结果的次数。
搜索引擎中输入的查询,其词顺序往往不重要,所以我们也忽略了词顺序,把所有和q′用词一致,但词顺序不一致的查询q″,当作是q′的同义查询。尽量避免q′数据稀疏的问题,如式(3)所示。
(3)
{q″}≈{q′}表示q″和q′仅在所用词上一致,词顺序可以不同。直观上来看,ctr越大,说明这个候选纠错查询q′的质量越高。用候选串和原串的相对ctr得分计算fctr特征值,如式(4)所示。
(4)
这是一个相对比值,表明候选纠错查询相对于原查询在点击通过率上的得分差异。
3.3.2 语言模型特征
点击通过率的计算是面向整个查询的,比较准确,但是对新候选串处理能力不足。用语言模型可以精细地刻画局部片段替换的合理性。对一个候选纠错查询(q′=w1w2w3...wl),需要评价它在多大程度上符合汉语的语言习惯,用q′各个词之间的联合概率来表示。在实际应用中联合概率根据马尔科夫链的特性,可约简成bigram语言模型,如式(5)所示。
(5)
对语言模型的参数估计,Stanley F. Chen 和 Joshua Goodman改进了Kneser-Ney平滑获得了较好的性能[13],在实际语言模型的设计中,我们采用了这种平滑策略。
由于只有发生变化的地方,才会带来n-gram模型计算上的差别,所以在语言模型的实际应用中,首先找到[wi,wj]片段。[wi,wj]片段定义为候选串q′相比原串q发生变化的最小片段,也就是说,所有的变化都包含在[wi,wj]范围内,i,j是最小边界位置,i (6) 语言模型的对比集中在查询的局部,而不是整个查询,所以语言模型对新查询的覆盖能力比点击通过率要强,但是因为只考虑变换前后查询的局部质量,所以语言模型相比点击通过率模型而言,准确性不够。这个事实在实验部分也能看到。 3.3.3 点互信息特征 语言模型的依据来自前后相邻的词之间的关系,我们用点互信息(Pointwise Mutual Information,PMI)[14]得分衡量替换前后的子串,和查询语境中其他没有变化的词的关联程度,依此判断替换是否合理,如公式(7)所示。 (7) 其中的概率可近似为Pr(wi,wj) =C(wi,wj)/N,Pr(wi)=C(wi)/N,Pr(wj)=C(wj)/N。C(.)表示在日志中,"."所代表的单个词或词对,曾经出现过的查询的个数,而N是所有查询的计数。替换后的词wi′ 和查询q′ 中除wi其他词{q′wi}之间的点对点互信息得分由式(8)来决定。 (8) 如果原串q发生替换的局部不止一处,那么q′的PMIS就是多处替换的综合考虑,如式(9)所示。 PMIS(q′)= (9) 其中K是query中发生了局部替换的词个数。 PMI 模型表示的词与词之间的关系是无方向性的,与wi算PMI的词之间也没有顺序性,是位置不敏感的。所以可以弥补语言模型词对顺序相邻的不足,又不像点击通过率模型那样只关心整个查询,所以是点击通过率模型和语言模型的补充。类似的,对比候选串q′和原串q,得到PMI的fpmi的得分为式(10)。 (10) 3.3.4 其他一些特征 还有其他可用于比较两个候选纠错查询质量相对高低的信息。 1. 词切分个数。一般情况下有错误的查询,分词后词个数相对较多,因为错误的输入往往不能和前后字构成词,形成“碎片”的概率很高。 例如,“对振”会被切分成两个词,“对”和“振”,而“对阵”是一个词。 2. 片段替换是否是一个好的替换。 一个替换,如<下栽, 下载> ,在纠错历史上经常出现,则说明这是一个好的替换,反之则是一个不好的替换。 3. 读音是否相似。对查询错误原因的分析能看到,大部分的错误还是来自于拼音输入法导致的错误,所以拼音是否模糊相似,也是判断纠错的一个重要的依据。 3.4 候选排序 我们利用标注数据训练了分类器,分类界面用于区分候选纠错查询相对原查询是“GoodCorrection”,还是“BadCorrection”。查询q′ 和q的关联特征向量各个纬度代表的含义如下。 f1: 表示q′的用户点击信息相对于q的用户点击信息的倍数; f2: 表示q′的bigram得分相对于q的bigram得分的倍数; f3: 表示q′的PMI得分相对于q的PMI得分的倍数; f4: 表示q′的词切分个数是否少于q的词切分个数,1表示是,0表示否; f5: 表示q到q′的片段替换是否是一个好的替换,1是好的替换,否则为0; f6:表示q′的读音相对于q的读音是否足够相似;是则为1,否则为0; 人工标记训练数据(q′,q,y)。 其中y=1表示q′ 的质量好于q;y= -1,表示q′ 的质量差于q。如果一个新的(q,q′)对应的关联特征向量到分类决策面的距离是d,则得到公式(11)。 (11) 其中w,b都是用得到的支持向量表示的平面参数,具体的细节可参考文献[7]。排序最高的候选纠错查询在分类"GoodCorrection"一侧,则表示是原始查询的一个最优纠错。 由于实际可替换的局部可能对应多个替换,生成的候选串有组合爆炸的可能。本文采用先粗筛选,再精排序的方式规避组合爆炸的问题。 粗筛选是从所有的候选中,先用比较有效的特征筛选出TopN(取N= 3)的候选纠错查询,在筛选出的查询中再用排序的方式,决定最好的纠错方案。粗筛选使用点击通过率模型和语言模型的对比得分:如果点击通过率对比得分不为0,则按此挑选TopN, 否则按语言模型对比得分挑选。由于用语言模型时,所有的候选纠错查询都要计算得分,其中有大量的重复乘法和查表操作,所以本文用Viterbi算法加速遍历。 表3 Top N 候选生成 在表3算法里,当需要保留N个最好的候选时,先用点击通过率挑选大于0的,如果已经满足有N个的条件,直接返回TopN结果;如果不够N个,则用语言模型挑选剩下的候选串。在使用语言模型时,用到了动态规划的Viterbi算法生成基于动态规划的候选集DyProSet。 4.1 实验设置 第一个实验是从linear, polynomial, RBF 和sigmoid 中挑选一个适合纠错任务的核函数,并且和其他单特征的纠错系统做了对比。验证本文方法纠错的正确性;第二个实验从实际搜索引擎结果的角度出发,用DCG评价指标,对比了纠错在搜索引擎上的实际效果。 4.2 测试集实验 就这个实验而言,我们把所有标记过<原查询,纠错查询,纠错是否正确>的样本,按比例划分为50 000个训练样本和17 590个测试样本。具体的数目分布可见表4。 表4 训练数据和测试数据 按之前讨论抽取了六个对比特征,分别采用linear, polynomial, RBF 和sigmoid核函数生成分类界面,这个实验的目的是挑选最适合这个纠错系统的核函数。表5给出了在测试语料上使用不同核函数纠错正确率的结果。 表5 测试语料上四种不同核函数在分类性能上的比较 在测试集上最好的测试结果是RBF核函数得到的,我们在这个基础上对比了其他单特征的结果。Only CTR表示只用点击通过率对比得分排序候选纠错查询,挑选CTR最高的作为最好的纠错候选;Only Ngram则是只用语言模型对比得分排序候选串,同样挑选最高的作为最好的纠错候选,Only PMI也是同样的原则;FULL_ME和FULL_Kernel则是用了所有特征,但分别用了最大熵模型[15]和核函数分类实现的排序机制。 表6 测试集上的多个模型对比实验 表6中可以明显的看到先用点击通过率和语言模型粗挑选候选串挑选TopN后,再用所有特征的核函数方法排序挑选最佳候选的策略,取得了测试集上最好的实验结果。另外FULL_ME表示用最大熵模型训练,和FULL_Kernel大致相当。但从p-value角度衡量,FULL_Kernel相比FULL_ME的提高是有意义的。同时能看到,单特征排序的P, R, F指标普遍低于多特征的。而且,由于Only Ngram只关注查询替换时的局部特性,所以相比其他的单特征模型Only CTR, Only PMI正确率上差一些,但召回能力较好。 4.2 DCG实验 Discounted Cumulative Gain(DCG)是一个衡量搜索引擎结果相关性的指标[16]。逐条对搜索结果相关性进行分等级的打分。在本文,搜索引擎上搜索一个词,然后分析检索结果的前五条,我们把这些结果进行五个质量等级的区分:Perfect, Good, Fair,Not Good, Bad,其得分分值分别为10、7、3、0.5、0。 表7看到的是纠错系统在搜索引擎中发挥的作用,评测的查询都是带有错误的,提交给带纠错的搜索引擎(Correction-SE),以及没有纠错的搜索引擎(None-Correction-SE),做DCG评测对比。 表7 DCG 实验结果 可以看到,在有错误的查询上,带纠错的搜索引擎DCG得分远高于不带纠错的搜索引擎,这也说明本文的方法取得了不错的效果。 本文提出了一个查询纠错方法,决定最佳纠错候选串。整体系统在纠错的召回率和正确率,以及实际的DCG评测中都取得了较好的成果,所以,本文方法是一个实际可行的方案。但从纠错失败的例子也能看到,纠错的困难是显而易见的。 (1) 对于长尾查询(long-tail query)而言,由于资源统计的局限性,导致覆盖不到有错误的查询,或者对没有错误的查询误纠。 (2) 纠错资源主要来源于日志数据,带来纠错的偏向性,例如,纠错很容易靠向日志中相对热门的查询或查询的局部。所以从其他来源获得知识补充也很必要。 本文的方法还有很多资源和算法上的可优化的途径。例如, CTR平滑: 使用query log中的点击信息时, 尝试使用Random Walk平滑,通过动态分析两个查询点击行为的相似性,能把两个有一定关联意义的查询数据联系起来,互补有无。 Random Walk的方法已经应用在文献[1]里,相信利用Random Walk能进一步解决CTR的数据稀疏问题。 N-gram平滑: 除了高阶和低阶复合的统计平滑之外,上位概念也可以解决部分数据稀疏问题:一个具体词出现的次数可能较少或者没有,但是它的上位概念出现的次数可能足够多,在语义上可以用上位概念代替这个词。例如,“超人归来”是个电影(用<电影>表示概念),则可得公式(12)。 (12) 显然语料中(下载<电影>)出现的次数会多很多,可以得到公式(13)。 (13) 随着搜索引擎功能的日益强大,查询纠错的实现和表现将有所不同:纠错不再以非此即彼的方式发挥作用,而是把多个候选纠错查询的搜索结果混合在最终的排序中;和用户个人Profile相结合,实现特定用户的特定纠错;另外,查询纠错仅仅是查询处理的一个方面,它势必会和其他的查询处理任务结合起来,发挥更大的作用。 [1] Cucerzan S, Brill E. Spelling correction as an iterative process that exploits the collective knowledge of web users[C]//Proceedings of EMNLP′04, 2004: 293-300. [2] Damerau F. A technique for computer detection and correction of spelling errors[J]. Communication of the ACM, 1964, 7(3): 659-664. [3] Mu Li, Muhua Zhu, Yang Zhang, et al. Exploring Distributional Similarity Based Models for Query Spelling Correction[C]//Proceedings of ACL, 2006: 1025-1032. [4] Golding A R, Roth D. Applying winnow to context-sensitive spelling correction[C]//Proceedings of ICML, 1996: 182-190. [5] Jianfeng Gao, Xiaolong li, Daniel Micol. A large scale ranker-based system for search query spelling correction[C]//Proceedings of Coling, 2010: 358-366. [6] Brill E, Moore R C. An improved error model for noisy channel spelling correction[C]//Proceedings of 38th annual meeting of the ACL, 2000: 286-293. [7] Toutanova K, Moore R. Pronunciation modeling for improved spelling correction[C]//Proceedings of the 40th annual meeting of ACL, 2002:144-151. [8] Ahmad F, Grzegorz Kondrak G. Learning a spelling error model from search query logs[C]//Proceedings of EMNLP, 2005: 955-962. [9] Golding A R, Roth D. Applying winnow to context-sensitive spelling correction[C]//Proceedings of ICML, 1996: 182-190. [10] Mangu L, Eric Brill E. Automatic rule acquisition for spelling correction[C]//Proceedings of ICML, 1997: 734-741. [11] Huizhong Duan, Bo-June (Paul) Hsu. Online Spelling Correction for Query Completion[C]//Proceedings of WWW, 2011. [12] Nello Christianini, John Shawe-Taylor. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods[M]. Cambridge University Press. 2000. [13] S F Chen, J T Goodman. An Empirical Study of Smoothing techniques for Language Modeling[R]. Technical Report: TR-10-98, Harvard University, 1998. [14] Church K, Gale W, Hanks P, et al. Using Statistics in Lexical analysis[J]. Lexical Acquisition: Using Online Resources to Build a Lexicon, Lawrence Erlbaum, 1991: 115-164. [15] Stephen Della Pietra, Vincent Della Pietra, John Lafferty. Inducing features of random fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(4): 380-393. [16] Kalervo Jarvelin, Jaana Kekalainen. Cumulated gain-based evaluation of IR techniques[J]. ACM Transactions on Information Systems 2002, 20(4): 422-446. [17] Craswell N, Szummer M. Random walk on the click graph[C]//Proceedings of SIGIR, 2007: 239-246. [18] Qing Chen, et al. Improving Query Spelling Correction Using Web Search Results[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, 2007: 181-189. [19] Guo J, Xu G, Li H, et al. A Unified and Discriminative Model for Query Refinement[C]//Proceeding of SIGIR, 2008: 379-386. An Online System for Chinese Query Correction in Search Engine HU Yi1, LIU Yunfeng2, YANG Haisong2, ZHANG Xiaopeng2, DUAN Jianyong3, ZHANG Mei3, QIAO Jianxiu2 (1. Alibaba Inc, Hangzhou, Zhejiang 310052, China; 2. Tencent Inc, Shenzhen, Guangdong 518057, China; 3. College of Information Engineering, North China University of Technology, Beijing 100144,China) The focus of this paper is to deal with the problem of Chinese query correction in a real world search engine. A wrong query usually confuses a search engine. We propose a complete approach to correct Chinese query in our search engine, which includes query candidates creating, query candidates evaluation and ranking by kernel based methods. After being experimented in the test set through precision/recall performance and proved in our search engine via DCG performance, the approach achieves good effects. Chinese query correction; multi features; Kernel Function Ranking 胡熠(1978—),博士,高级技术专家,主要研究领域为电子商务、搜索引擎及自然语言处理。E⁃mail:erwin.huy@alibaba⁃inc.com刘云峰(1977—),博士,专家工程师,主要研究领域为自然语言处理和机器学习。E⁃mail:glen@vip.qq.com杨海松(1976—),博士,专家工程师,主要研究领域为搜索引擎。E⁃mail:jackieyang@tencent.com 1003-0077(2016)01-0071-08 2013-09-15 定稿日期: 2014-04-20 国家自然科学基金(61103112);国家社会科学基金(11CTQ036);国家语委十二五规划基金(YB125-10);北京市哲学社会科学规划基金(13SHC031) TP391 A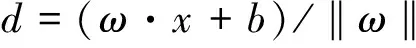

4 实验和结果
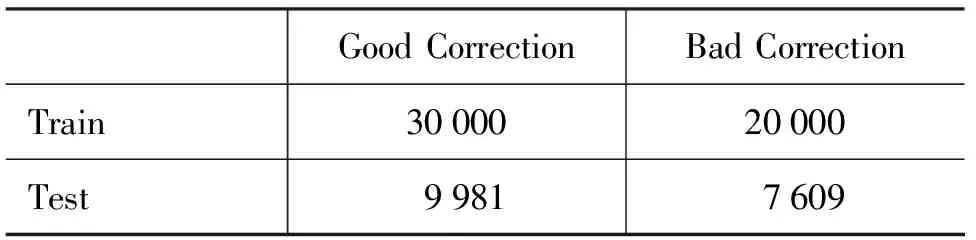


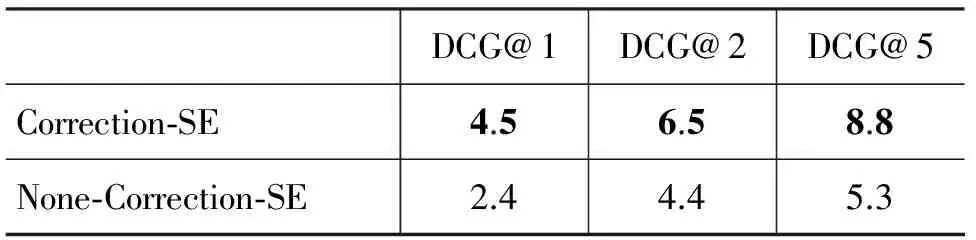
5 结论


猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
昆明医科大学学报(2022年1期)2022-02-28
中国医学物理学杂志(2021年12期)2022-01-07
名家名作(2021年4期)2021-05-12
装备制造技术(2020年4期)2020-12-25
疯狂英语·新阅版(2020年11期)2020-12-21
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
中国卫生(2015年12期)2015-11-10
科学导报·学术论坛(2013年5期)2013-06-26
