
汉语“比”字句关键要素的常规序列模式探索
2016-05-03 13:12朴敏浚袁毓林
中文信息学报 2016年4期
朴敏浚,李 强,袁毓林
(1. 北京大学 中文系/中国语言学研究中心/计算语言学教育部重点实验室,北京 100871;2. 上海大学 中文系,上海 200444)
汉语“比”字句关键要素的常规序列模式探索
朴敏浚1,李 强2,袁毓林1
(1. 北京大学 中文系/中国语言学研究中心/计算语言学教育部重点实验室,北京 100871;2. 上海大学 中文系,上海 200444)
表达“差比”义的“比”字句,是比较句的主要句型,也是比较句关键要素抽取研究中不可回避的主要课题。该句型的关键要素(SUB、BI、OBJ、ITM、DIM、RES、EXT)在语义上互相交织,在表层句法上可以实现为多种多样的序列模式。该文面向中文“比”字句关键要素抽取这个目标,对于表示“差比”义的460多个“比”字句文本进行了七种关键要素的标注。在此基础上,利用Apriori和PrefixSpan算法找出这些要素的关联规则及其序列模式,并归纳出六种“比”字句关键要素的分布规律。此外,该文还进一步说明了产生这六种模式规则的动因,为“比”字句特征选取和处理提供了重要的语言学理论依据。
“比”字句;关键要素;关联规则;序列模式;分布规律
1 引言
随着互联网的普及,社交网络(SNS)的影响力也日益增强,成为人们信息交流的重要平台。这自然而然地引起了企业对网络大数据(big data)进行分析与探索的兴趣。其中,与商品销售有着直接关系的网络商品评价,尤其是顾客评价中的比较句成了信息抽取(IE)领域的研究热点*因为对于商品的性能与价格的评价,最好的办法莫过于比较。正如俗话所说的“货比三家,价比八方”。。比如,黄小江[1]提出以类序列规则(CSR)为特征的汉语比较句识别模型。张晨等[2]利用了类序列规则(CSR)、语义角色信息、统计词等多种特征,通过模板匹配和机器学习相结合的方法提高了比较句的识别性能。
此外,中文倾向性分析评测(COAE)连续两年(2012、2013)把比较句的识别与要素抽取列为评测任务。大部分参赛单位在特征词序列模式的基础上利用模式匹配的方式进行了关键要素提取(侯名午等[3];李岩等[4])。虽然通过多方面的努力提高了比较句的识别性能,但现有的比较关键要素提取模型的表现还停留在初步水平*COAE 2013 任务2.2(比较句关键要素提取)与其他任务相比显示较低的成绩(最佳F值仅为0.35)。。这是因为关键要素的提取是覆盖分词、短语识别、未登录词识别、句法分析等多方面的技术[5]。我们认为,目前最关键的问题在于,比较句研究尚没有完全反映中文比较句的特征,尤其是缺少概括比较点(attribute, ATT)和比较结果(result, RES)之间多重关系的细颗粒度的模板。宋锐等[6]也承认,比较结果成分本身的复杂性使得目前的抽取方式还亟待进一步改善。可见,剖析其他要素与比较结果参杂交织而形成的复杂结构对于比较句比较关系的抽取起着重要的作用。因此,本文将对比较句关键要素的种类和数量进行扩充,并在此基础上标注这些关键要素在句子中所表现出来的语义角色类型,从而为下一步寻找出关键要素的序列模式(sequential pattern)奠定基础。
2 汉语比较句概况
关于汉语比较句的研究很早就已经开始,《马氏文通》[7]把比较句分为“平比”、“差比”和“极比”三大类别,这三种类别的含义分别对应于英语中的原级、比较级和最高级的意义。吕叔湘[8]把比较定义为两件事物之间同中见异,或异中见同的过程。他指出,比较两件东西的高下,高者对下者说是“胜过”。张晨等[2]认为,在形式上,以比较特征词的出现与否为准,汉语比较句可以分为显性比较句与隐性比较句两种。隐性比较句指的是虽然句子中体现出比较意义,但是“比、最、更”等比较标志并没出现在句子里。
根据已有的研究成果[9-13],本文将“比”字句划分为四种类型,如表1所示。
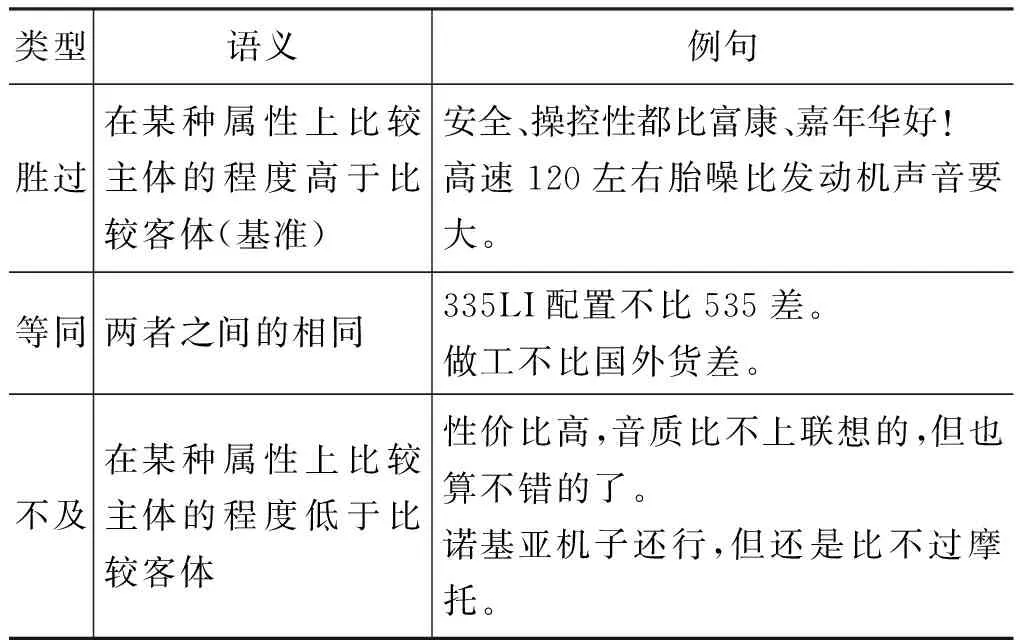
表1 “比”字句的类型

续表
本文主要的分析对象是表达“胜过”义的显性比较句,即包含介词“比”的单、复句形式。本文从COAE 2013 所提供的电子、汽车两个领域1 000个比较句的训练集[14]中,挑出“胜过”义的460多句作为分析数据*通过“比”字匹配方式过滤(排除)非“比”字句(如包含“没有、不如、差不多”等比较词的句子),然后人工挑选出表“胜过”义的460多个“比”字句。(其中汽车领域202句,电子领域262句),总结出这些“比”字句中关键要素的排列顺序以及要素之间的比较关系。
3 “比”字句的关键要素及其定义
从工程角度看,“比”字句可以定义为一个由比较主体(SUB)、比较客体(OBJ)、比较点(ATT)、比较结果(RES)和比较标记(BI)组成的五元组(quintuple):
C = < SUB, BI, OBJ, ATT, RES >
目前大多数比较句识别模型都是在此基础上对“比”字句进行分析。然而,我们认为,这一定义对关键要素的识别和关系抽取不够精密,会错失相当多的语言学方面的启发性特征,尤其是比较点(ATT)和比较结果(RES)之间所隐含的多种配位方式。因此,我们对上面的这一组合进行细化和补充,从而得出以下的七元组(septuple):
C = < SUB, BI, OBJ, ITM, DIM, RES, EXT >
比较主体(SUB): 进行比较的两个项中先出现的成分,比较结果(RES)这个属性值的持有者,一般充当句子的主语。
比较词(BI): “比”字句标记,本文定性为介词“比”。
比较客体(OBJ): 进行比较的两个项中后出现的成分,经常充任“比”字所引导的介宾结构的宾语,又称为比较基准。
比较项目(ITM): 语义上泛指SUB与OBJ共有的部件,比较结果(RES)的次要论元。一般与SUB和OBJ结合成名词短语,充任主语或由“比”引导的介宾结构的宾语。
比较维度(DIM): 语义上泛指SUB与OBJ共有的属性(property),RES的主要论元*在语义网络中,类(class)、属性(property)和属性值(property value)构成基本的语义单位。Fellbaum[14](1998: 40)举“知更鸟(robin)”的例子阐述这三种要素及其关系。名词“知更鸟”是属性尺寸(size)和颜色(color)的持有者,也可以理解为这两种属性的论元,比如SIZE(robin)=small、COLOR(robin) = red,而形容词“小(small)和”红色(red)分别是关于这两种属性的值。。一般与SUB和OBJ结合成名词短语,充任主语或由“比”引导的介宾结构的宾语。
比较结果(RES): 表达进行比较的两个项之间的差异,而且是比较维度(DIM)的属性值。语法上由形容词或动词来实现,充当比较句的谓语。
比较量幅(EXT): 表达进行比较的两个项之间在某种属性上的差异所达到的程度或幅度,一般和比较结果(RES)结合成述补结构。
这个七元组体系比传统的五元组的优越性在于: ①每一个元素的语言学形式特征比较明确;②七元组可以映射到传统的五元组上。下面,我们用一个例句来展示用上述七个元素对句子所进行的标注工作。
例1 新飞度车身结构的刚度比前代提高了164%。
新飞度 车身结构 刚度 比 前代 提高 164%
SUB ITM DIM BI OBJ RES EXT
4 “比”字句关键要素序列特征分析
在实际文本中,上述七种要素纵横交错在一起形成十分灵活的组配模式*现有的自动识别模型已对这些变化无穷的“比”字句进行了一定的归纳,并建成了一些模式库。比如,宋锐等[6]构建了包含106条比较模式的差比模式库(2009:104);侯明午等[3]归纳出否定比较句的若干句型。另外,陈珺等[9]从教学大纲里的比较句语法项目中,选取了具有代表性的20多种比较句型。。虽然比较模式表面上看起来五花八门,但我们相信实际上存在一些把它们贯串起来的规则或倾向性。我们针对COAE语料(第2节),按照上述七元组的基本架构进行了人工标注。经过加工与简化的步骤后,我们得出以下六种(R1-R6)基本序列规则。
4.1 比较维度(DIM)与比较结果(RES)的排序
R1: 比较结果(RES)不能出现于比较维度(DIM)前面。并且,比较结果(RES)必须在句中出现。
例2 NOKIA的信号比我另外一个两千多的手机信号还好。
NOKIA 信号 比 两千多的手机 信号 好
SUB DIM BI OBJ DIM RES
上述例句中,比较维度(DIM)先于比较结果(RES)出现。比较结果(RES)的含义则是关于某种属性(property)的具体值(property value)。从这个角度来看,比较维度(DIM)即是比较结果(RES)所要描述的属性。因此,从信息表达的角度看,描述的属性必须先被确定并出现,然后才能对它进行陈述,即比较结果(RES)随后出现,结果产生DIM-RES的常规语序。
但是,实际语料中也存在一些RES-DIM逆序的情况。条件是: 句子中出现浮现动词(Emergent Verb),比如下面两句中的动词“提供、多出”。
例3 xD卡比市面上的其他存储介质提供了更高速的连接速度与更小的体积。
xD卡 比 其他存储介质 高速 连接速度 小 体积
SUB BI OBJ RES DIM RES DIM
例4 无优点,就算有,也是比卡片机多出个手动模式。
比 卡片机 多出 手动模式(数目)
BI OBJ RES ITM DIM
在这些RES-DIM逆序表达,即比较结果(RES)前置的非常规句子中,大部分情况是有浮现动词充当“比”字句的谓语。这又可以细分为两种情况: ①比较结果(RES)充当比较维度(DIM)的定语,如例3所示;②比较结果(RES)携带比较维度(DIM)作宾语,如例4所示。
4.2 比较点相对于比较词的位置
R2: 比较点(ITM和DIM)一般在“比”前出现
在“比”字句中,ITM与DIM是比较的核心对象,即比较点。因此,它们容易作为“比”字句的话题,提升到句首位置。具体的统计结果如表2所示。
比较项目(ITM)一般在“比”前面出现(58/73, 79%), 比 较 维 度(DIM)也倾向于出现在“比”前面(213/271,79%)。
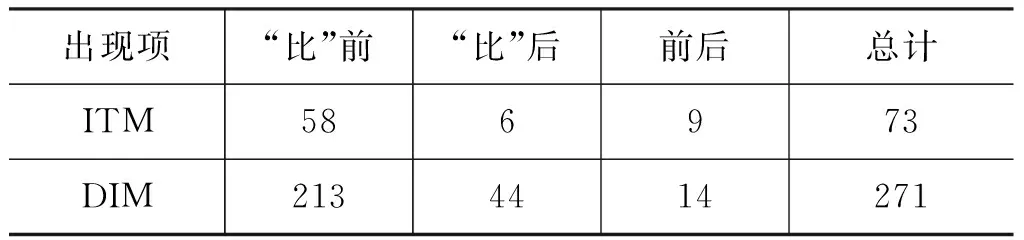
表2 比较点出现位置的分布(词频)
我们认为,出现这种现象的原因是: 虽然ITM和DIM是比较双方SUB和OBJ都具有的共同部分,但它们的描述对象主要是比较主体(SUB),而不是比较客体(OBJ)。因此,比较点(ITM或DIM)在“比”前面跟SUB紧邻着出现。例如:
例5 显然,Xg在电池的续航能力方面比Xt有所提高。
Xg 电池 续航能力 比 Xt 提高
SUB ITM DIM BI OBJ RES
相反,比较点(ITM或DIM)在“比”后出现,这种情况则是非常规的。通过观察语料,我们发现主要包含这样几个小类:
A. DIM出现于介词结构“(在)……方面(上)”。以例6为例:
例6 从使用的过程中来看,比前两代机型的屏幕不管在色彩、亮度方面都有非常大的提高。
比 前两代机型 屏幕 色彩、亮度 非常大 提高
BI OBJ ITM DIM EXT RES
在实际文本中,ITM和DIM同时在“比”后出现的情况,我们只发现了例6这一例。其他情况都是只有DIM一个成分在“比”后出现,并且,DIM都是出现在介词结构“(在)……方面(上)”之中。所以,可以推测,之所以DIM可以出现在“比”后,是因为介词结构“(在)……方面(上)”将比较维度(DIM)包装成有标记的话题,使得DIM的句法位置较为灵活,从而可以出现在“比”后。
B. 比较结果(RES)的语义信息熵较大。以例7为例:
例7 NOKIA的信号比我另外一个两千多的手机信号还好。
NOKIA 信号 比 两千多的手机 信号 好
SUB DIM BI OBJ DIM RES
有些比较结果词(RES)的语义信息熵较大,比如,“好、大、强”等形容词与“贵、快、耐用”等形容词相比,它们所指向的DIM是不易确定的。这些信息熵大的RES在实际解读中可能会导致语义的模糊,所以,DIM有时候紧邻RES出现于“比”字后,从而可以最大程度地减少语义的模糊度。
C. 一个句子中出现多个比较结果(RES)。以例8为例:
例8 原来用的是630K,这个比630速度快,设计更合理。
这个 比 630 速度 快 设计 合理
SUB BI OBJ DIM RES DIM RES
由于像例8这样的句子具有两个比较结果(RES),因此为了避免发生歧义,DIM紧邻RES出现于“比”后,结果导致这种非常规序列的产生。
此外,ITM和DIM对于SUB的语义偏向也反映在关键要素之间的序列模式(sequential pattern*序列模式(sequential pattern) 是指项目的集合I={i1,i2,… im}构成序列(sequence) S =
我们以469个事务为分析对象,利用Prefix-Span 算法挖掘出包含DIM与ITM的部分序列模式。其中,DIM在比较词“比”之前与SUB共现的部分序列有103个(22%);在比较词“比”之后与OBJ共现的有57个(12%)。相应地,ITM在“比”之前与SUB共现的部分序列有34个(7%);在“比”之后与OBJ共现的有12个(3%)。总之,无论是ITM或DIM,它们跟SUB的共现概率都超过跟OBJ的共现概率的两倍,意味着ITM或DIM的描述对象大部分是比较主体(SUB),而不是比较客体(OBJ)。
4.3 比较点的内部序列
R3: 如果句子中ITM和DIM同时出现,一般的情况是ITM出现于DIM前面,而DIM不能出现于ITM前面。例如:
例9 比较便宜,外观不错,喇叭声音也比宏基以前的机型大了不少。
喇叭 声音 比 宏基以前的机型 大 不少
ITM DIM BI OBJ RES EXT
比较维度(DIM)是比较项目(ITM)的属性(property)。属性是相对于实体(entity),即ITM而言的。如果没有相应的实体,属性本身是站不住的。因此,在语序上先要确定实体(ITM),然后才能对该实体的属性(DIM)进行补充描述。
R4: DIM与ITM不能由“比”来隔开。因此,以下序列是不允许的。
*A. … DIM … BI … ITM …
*B. … ITM … BI … DIM …
根据R4,ITM与DIM在同一个句子中一起出现时,要么都在“比”前面,要么都在“比”后面。可是后者的情况被R2排除,因此ITM和DIM只能作为整体出现在“比”前。例如:
例10 急加速时发动机的噪声比福克斯强多了。
发动机 噪声 比 福克斯 强 多
ITM DIM BI OBJ RES EXT
4.4 比较点的分布规则
R5: ITM和DIM的分布大体上是互补的。
通过对语料的整理,我们发现: 比较维度(DIM)在语义上是自足的,而比较项目(ITM)不是自足的。我们利用Apriori算法挖掘出包含ITM与DIM的关联规则(association rule*关联规则(association rule): 项目的集合I = {i1, i2, …, im},事务T= (t1,t2, …, tn), ti ⊆I。关联规则可视为X ⟹Y(X⊂I, Y ⊂I, X∩Y =∅),其中X(或Y)叫做项集(itemset)。(Bing Liu[16]))[17]:
与比较项目(ITM)共现的频繁项(1-item)按置信度降序排列为:
SUB(62%)EXT(38)DIM(21): 汽车领域
SUB(25%)DIM(20)EXT(18): 电子领域
与比较维度(DIM)共现的频繁项(1-item)按置信度降序排列为:
SUB(62%)EXT(37)ITM(6): 汽车领域
EXT(37%)SUB(21)ITM(6): 电子领域
上述关联规则显示,规则ITM→DIM的置信度*置信度(confidence)是在关联规则中常用来衡量关联规则强度的指标。一个关联规则X⟹Y的置信度是指既包含了X又包含了Y的事务(transaction)的数量占所有包含了X的事务的百分比。(Bing Liu[16])是20%,而规则DIM→ITM的置信度只有6%。据此,我们可以把它理解为ITM对DIM的依赖性比DIM对ITM的依赖性更强。从中推导出在“比”字句中,ITM是不能单独出现的,而是需要通过DIM作为媒介才能实现。
这种ITM与DIM之间的置信度不对称现象(20% vs 6%)说明,这两个成分的出现与否并不是互相独立的事件,而是存在某种相互关联。如表3所示。
通过卡方检验(chi-squared test),我们发现了比较项目(ITM)与比较维度(DIM)这两种要素的出现与否存在相互关联*卡方值(χ2)为35.12,大于临界值3.84(df=1, α=0.05)。。表3里,左下右上的出现频率尤其显著。具体而言,ITM在“比”字句中出现
表3 比较项目(ITM)与比较维度(DIM)出现与否的 交叉分布时,DIM倾向于不出现,反之亦然。那为何ITM和DIM具有这种较强的互补分布呢?这是我们把比较点(ATT)分成ITM和DIM两类的自然结果。ATT是说话人要对比的比较焦点,最好只有一个,因为两个或两个以上的比较焦点,容易造成认知上的负担。比如,在文本中会经常出现下面A、B两种情况,能够明显地表现出这一倾向性。
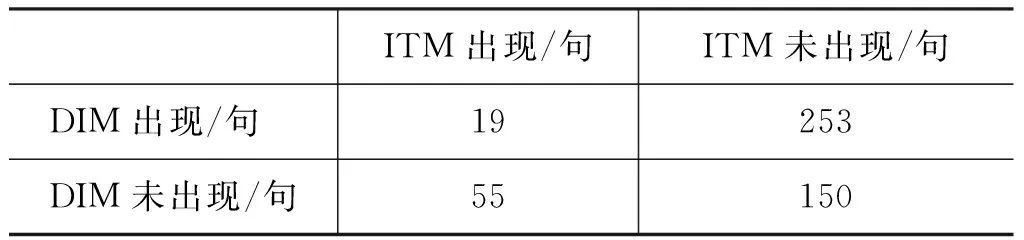
ITM出现/句ITM未出现/句DIM出现/句 19253DIM未出现/句55150
A.比较项目(ITM)出现,但比较维度(DIM)不出现的情况:
SUB ITM(DIM) 比 OBJ RES EXT
JD-Ci,富康三厢 车身(体积)[default] 比 普桑 小 一号
GT630M 显卡(品质)[default] 比 GT610M 强 很多
在上述例句中,比较焦点落实在比较项目(ITM)上。比较维度(DIM)都是比较结果(RES)的缺省属性(default property),因此不用再重复提示DIM,可以直接把它省略。
B.比较维度(DIM)出现,但比较项目(ITM)不出现的情况:
SUB DIM 比 OBJ RES (EXT)
夏利 性能 比 吉利车 好
FIT 外观 比 同类车 大气
广州本田 定价 比 同级别的车 低 5万
比较焦点落实在比较维度(DIM)上,因此比较项目(ITM)没有浮现。
C.比较项目(ITM)与比较维度(DIM)同时出现的情况:
(SUB)ITM DIM 比 OBJ RES(EXT)
发动机 噪声(强度)[default] 比 福克斯 强 多
宝来 刹车系统反应(速度)[default] 比 307 慢
Thinkpad 屏幕 可视度(大小)[default] 比 以前的 大
情况C是R5的反例,但如表3所示,这种情况并不多(4%)。在情况C中,虽然ITM在句子中已出现,但是这个事实不能保证DIM可以省略。因为从RES的意义上不能推导出DIM,所以为了避免模糊性,DIM就很有可能出现。至于DIM的省略条件,我们将在4.5节中探讨。
4.5 成分省略规则
R6: 在“比”字句中,BI、OBJ和RES三种要素强制性出现。
一旦比较点(ITM和DIM)在“比”字句中出现,比较焦点从原有的SUB和OBJ转移到比较点ITM和DIM上,使得它们成为“比”字句的核心比较焦点。这时,关键要素的省略应该考量以下三点。
R6-1: 比较结果(RES)的语义指向是DIM,而不是ITM。因此,原则上DIM不能省略。与比较结果(RES)共现的频繁项(1-item)按 置 信度降 序 排列为:
SUB(71%)DIM(57)EXT(39)ITM(17)
根据上述排序,与RES共现概率较高的关键要素为SUB和DIM。与这两个关键要素相比,ITM的置信度非常低(17%),说明它不是实现比较结果(RES)的必要条件。与ITM不同,SUB和DIM两个成分在述谓结构上正好是属性值(property value,即RES)的两个论元,即实体(entity,由SUB表达)和属性(property,由DIM表达)。从述谓结构的角度看,RES要求以SUB和DIM的出现为自己的实现条件。因此,SUB和DIM必须在RES前出现。
R6-2: 比较结果(RES)决定DIM是否可以省略
在大约40%的“比”字句中,DIM没有出现。这是因为我们一般能猜测到比较结果(RES)所默认(default)的属性(property),即DIM。
从4.4节中的三种情况中,我们发现了一条较为重要的规则,即DIM的省略与否和RES之间存在一定的关系。DIM不出现时(4.4节A),DIM一般都是RES的缺省属性(default property)*关于属性名词缺省的具体机制和条件,详见袁毓林[18-19]。。然而,当DIM出现时(4.4节B和C),DIM不是RES的缺省属性。因此DIM一般不能从RES的词汇意义上推导出来,故不能省略。常见的比较结果(RES)及其缺省属性如表4所示。
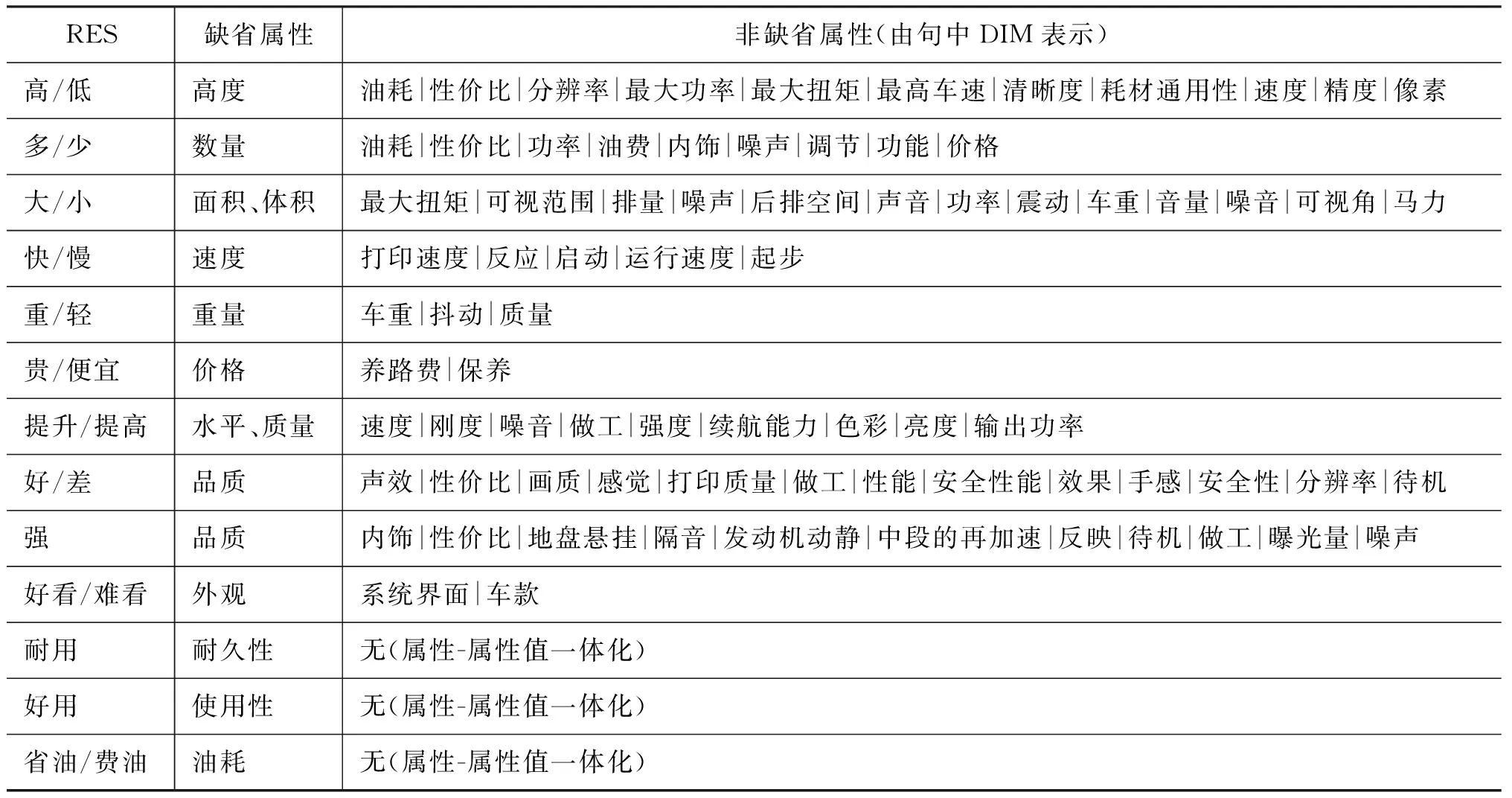
表4 比较结果(RES)的缺省属性及非缺省属性
表4说明,当RES的缺省属性和句子中的DIM不一致时,强制性要求DIM出现;当缺省属性和句中DIM一致时,DIM可以出现,也可以不出现。另外,作为一种特殊情况,有些RES的属性-属性值一体化结构(如“耐用、好用、省油”等)本身已确定其缺省属性,因此DIM强制性省略。
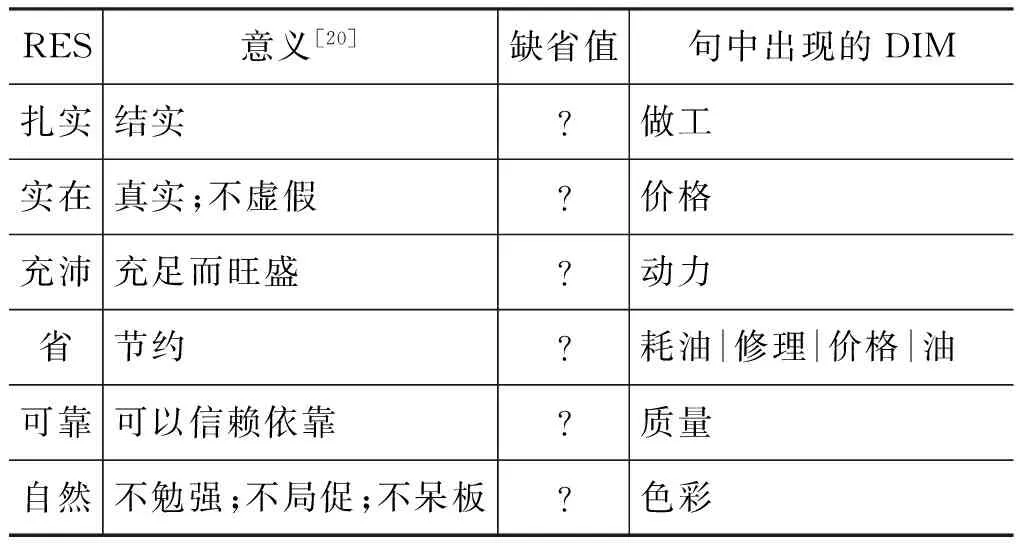
表5 难以决定缺省属性的比较结果(RES)
如表5所示,有的比较结果(RES)本身不具有或无法指定其缺省属性,因此不能推导出相对应的DIM。这时,仅仅通过RES的意义不能预测DIM的具体属性。例如:
例11 夏利比吉利修理上省一点,因为夏利车是个汽修店都能修。
夏利 比 吉利 修理 省 一点
SUB BI OBJ DIM RES EXT
例11的比较结果“省”无法指定其缺省属性。这时我们不能预测它的DIM究竟指什么。与表4中的情况不同,表5中的RES一般不能蕴含其DIM,因此强制性要求DIM出现。
R6-3: 比较主体(SUB)和比较维度(DIM)同时省略条件
虽然SUB和DIM同时省略的情况很少,但
A. BI OBJ RES
例12 出差日本用来暂时通话,比同档次的三星手机好用。
比 同档次的三星手机 好用
BI OBJ RES
A这样的超短形式之所以被允许,是因为虽然句子中省略了比较结果RES的论元SUB或DIM,但是还能从RES和OBJ推导出省略了的成分。对于DIM而言,有些DIM作为缺省值被蕴含在比较结果(RES)的意义里面(表4,属性-属性值一体化),故DIM(如例12“使用性”)不出现却还能推导出来。对于SUB而言,虽然它被省略了,但从OBJ中还是能够推导出来。这是因为SUB与OBJ是属于同一范畴的实体(entity)。比如,例12的OBJ“同档次的三星手机”代表某种品牌和商品。我们能够从中推导出和它相对应的SUB,比如“同档次的联想手机”等。
*B. BI ITM RES (不合格的省略句型)
在序列B中,从ITM本身并不能推导出任何关于SUB的信息。这是因为ITM不像A.
5 序列的合格性判断
我们以469个事务为分析对象,利用Prefix-Span 算法挖掘出常见序列模式(sequential pattern)[17]。然后,根据第4节所提出的六种规则,对实际文本中的序列模式进行合格性检查和特征归纳。序列模式按支持度(support)*序列模式的支持度(support)是指给定的序列S的数量占所有包含了该序列的事务(transaction)的百分比。此外,由于受篇幅限制,本文只展示常见的“比”字句的序列模式,而未展示非常见的“比”字句序列模式。降序分列如下。
(1) DIM BI OBJ RES (EXT)#SUP: 105(22.4%)
够用,待机时间比现在智能机长,老人用还算合适。
待机时间 比 现在智能机 长
DIM BI OBJ RES
R2: DIM一般在“比”前出现,充当话题。
R4: DIM与ITM不能由“比”隔开,因此“比”后不出现ITM。
R5: DIM出现了,因此ITM不出现的概率比较高。
R6-2: 由于DIM“待机时间”不是RES“长”的缺省属性(长度),因此DIM出现。
(2) SUB BI OBJ RES(EXT) #SUP: 81(17.3%)
买宝来都比买这款车合算些。
(买)宝来 比 (买)这款车 合算
SUB BI OBJ RES
R6-2: 由于RES“合算”蕴含其缺省属性(价格),DIM可以省略。
(3) SUB DIM BI OBJ RES(EXT) #SUP: 79(16.8%)
领驭的后门进入空间比老款帕萨特大得多。
领驭后门进入空间比老款帕萨特大多
SUB DIM BI OBJ RES EXT
R1: DIM先于RES出现。
R2: DIM在“比”前面出现,因为DIM的指向是SUB,不是OBJ。
R5: DIM出现了,因此ITM不出现的概率比较高。
R6-2: DIM“空间”不是RES“大”的缺省属性(体积),因此属性DIM出现。
(4) BI OBJ RES (EXT) #SUP: 65(13.9%)
比安卓手机省电多了,外放铃声也大,是正品行货质量有保证,价位还算可以。
比 安卓手机 省电 多
BI OBJ RES EXT
R6-2: 由于RES“省电”蕴含其属性(电耗),所以DIM能省略。
R6-3: OBJ出现,可以推导出省略的相同范畴的SUB(如“苹果手机”等)。
(5) SUB ITM BI OBJ RES(EXT) #SUP: 26(5.5%)
最喜欢的就是这车子的底盘比一般的同级车要高一些,过个减速带什么的感觉很好,很稳。
这车子 底盘 比 一般的同级车 高 一些
SUB ITM BI OBJ RES EXT
R2: 在“比”前出现ITM,成为了比字句的话题(比较焦点)。
R4: 由于ITM在“比”前出现,其他比较属性(DIM)不能在“比”后出现。
R5: 由于ITM已出现,因而DIM不出现的概率较高。
R6-2: 句中RES“高”所描述的DIM是缺省属性“高度”。因此,DIM可以省略。
(6) BI OBJ DIM RES (EXT) #SUP: 21(4.5%)
感觉比以前在京东买的e430的做工好一点,以前的面板和做工好差哦。
比 e430 做工 好 一点
BI OBJ DIM RES EXT
R1: DIM先于RES出现。
R4: 由于DIM在“比”后出现,因而ITM不在“比”前出现。
R5: DIM出现了,因此ITM出现的概率较低。
R6-3: OBJ是商品名,从中能够推导出SUB是属于相同范畴的商品名。
(7) ITM BI OBJ RES(EXT) #SUP: 20(4.3%)
底盘比雅力士要硬,指向性强。
底盘 比 雅力士 硬
ITM BI OBJ RES
R2: 比较点(ITM和DIM)一般在“比”前出现,充当话题。
R4: ITM与DIM不能由“比”隔开,因此“比”后不出现DIM。
R5: ITM已出现,因此DIM不出现的概率比较高。
R6-2: 由于RES“硬”的属性“硬度”是缺省属性,因而DIM可以省略。
(8) SUB ITM DIM BI OBJ RES (EXT) #SUP: 5(1.1%)
新飞度车身结构的刚度比前代提高了164%。
新飞度车身结构刚度比前代提高164%
SUB ITM DIM BI OBJ RES EXT
R1: DIM在RES前出现。
R2: ITM和DIM一般在“比”前出现。
R3: ITM在DIM前出现。
R4: ITM与DIM不能由“比”来隔开。
R6-2: RES“提高”的缺省属性不是“刚度”,因此DIM(刚度)不能省略。
R6-3: 因为从OBJ“前代”不能推导出SUB“新飞度”,SUB不能省略。
6 结论
本文针对汉语“比”字句关键要素的识别问题,重新划分了“比”字句关键要素的范畴。通过研究,我们发现“比”字句中的比较项并不局限于比较主体(SUB)和比较客体(OBJ)。在实际文本中,很多情况下比较项是属于不同范畴、不同级别的两个成分。比如,“做工,外观比它们漂亮”中的比较项是属于不同范畴的DIM(做工、外观)与OBJ(它们)。这种比较项之间的异质性增加了比较结果(RES)的语义倾向性(polarity)判断难度。尤其是“大/小、高/低、多/少”等情感模糊词[21]充当比较结果(RES)时,找出它们相对应的比较维度(DIM)是对整个句子做出正确的极性判断的至关重要的线索。为了解决这些问题,本文在目前通用的五种基本要素的分类基础上,补充了比较项目(ITM)、比较维度(DIM)和比较量幅(EXT)三种要素,提出了由七种关键要素构成的“比”字句的分析架构。然后,利用一些序列模式挖掘算法,抽取出“比”字句关键要素的多种序列模式,从中提炼出六种汉语“比”字句的序列规则,并揭示出这些规则背后的语言学动因。我们希望这种从语言学角度出发,通过对大规模网络文本中真实句子的细致分析,最终可以为“比”字句关键要素抽取任务的实际应用与评测提供一定的帮助。
[1] 黄小江,万小军,杨建武等. 汉语比较句识别研究[J]. 中文信息学报, 2008,22(5): 30-38.
[2] 张晨,马冲,刘全超等. 基于多特征融合的中文比较句识别算法[J]. 中文信息学报,2013,27(6): 111-116.
[3] 侯明午,周红照,程南昌等. 汉语否定比较句句型研究及在工程中的应用[C]//第五届中文倾向性分析评测,2013: 88-96.
[4] 李岩,徐蔚然,陈光. PRIS_COAE COAE2013 评测报告[C]//第五届中文倾向性分析评测,2013: 53-69.
[5] 谭松波,王素格,廖祥文等. 第五届中文倾向性分析评测(COAE2013)总体报告[R].第五届中文倾向性分析评测,2013: 5-33.
[6] 宋锐,林鸿飞,常富洋. 中文比较句识别及比较关系抽取[J]. 中文信息学报,2009,23(3): 103-122.
[7] 马建忠. 马氏文通[M]. 上海: 商务印书馆, 1898.
[8] 吕叔湘. 中国文法要略[M]. 北京: 商务印书馆,1982: 352-370.
[9] 陈珺,周小兵. 比较句语法项目的选取和排序[J]. 语言教学与研究,2005,(2): 22-32.
[10] 耿直. 基于语料库的比较句式“跟、有、比”的描写与分析[D]. 北京大学博士学位论文,2012: 111-164.
[11] 李临定. 现代汉语句型[M]. 北京: 商务印书馆,1986: 285-301.
[12] 刘月华 等. 实用现代汉语语法[M]. 北京: 商务印书馆,2001: 833-854.
[13] 许国萍. “比”字句研究综述[J].汉语学习,1996,(6): 28-31.
[14] 谭松波,王素格,廖祥文 等. 第五届中文倾向性分析评测(COAE2013)标注数据(Task2)[DB/OL]. 2013. http://ccir2013.sxu.edu.cn/COAE.aspx.
[15] Christiane Fellbaum. WordNet: An Electronic Lexical Database[M]. Massachusetts: MIT Press, 1998: 23-43.
[16] Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data[M]. Springer, 2011.
[17] P Fournier-Viger, A Gomariz, A Soltani, et al. SPMF: Open-Source Data Mining Platform[CP/OL]. 2014.http://www.philippe-fournier-viger.com/spmf/.
[18] 袁毓林. 一价名词的认知研究[J]. 中国语文. 1994,(4):241-252.
[19] 袁毓林. 形容词的语义特征和句式特点之间的关系[J]. 汉藏语学报,2013,(7): 147-166.
[20] 中国社会科学院语言研究所. 现代汉语词典(第6版)[M]. 北京: 商务印书馆, 2012.
[21] Yunfang Wu, Miaomiao Wen. Disambiguating Dynamic Sentiment Ambiguous Adjectives[C]//Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, 2010: 1191-1199.
A Study on the Sequential Patterns of Semantic Constituents of the Bi-Comparative Structure
PARK Minjun1, LI Qiang2, YUAN Yulin1
(1. Dept. of Chinese Language and Literature, Peking University, Beijing 100871, China;2. Dept. of Chinese Language and Literature, Shanghai University, Shanghai 200444, China)
The Bi-structure, which highlights a contrasting characteristic between two elements, is the key comparative sentence structure in Chinese. This structure consists of 7 types semantic items (SUB, BI, OBJ, ITM, DIM, RES, EXT), of which various sequential patterns may occur. To provide meaningful information for the keyword extraction task of this comparative structure, this study first begins with the tagging of the 7 semantic items on about 460 sentences. Second, association rules and sequential patterns are extracted using the Apriori and PrefixSpan algorithms, from which 6 rules of the item distribution are established. Finally, this paper illustrates the rationale behind the construct of these 6 rules, providing a better understanding of the linguistic characteristics for feature selection task of the Bi-comparative structure in Chinese.
Bi-structure; keyword extraction; association rule; sequential pattern mining; distribution rule

朴敏浚(1984—),博士研究生,主要研究领域为汉语句法学、计算语言学。E-mail:karmalet@163.com李强(1988—),讲师,主要研究领域为汉语句法学、语义学和语用学,也涉足计算语言学和中文信息处理领域。E-mail:leeqiang2222@163.com袁毓林(1962—),教授、博士生导师,主要研究领域为理论语言学和汉语语言学,特别是句法学、语义学、语用学,也涉及计算语言学和中文信息处理等应用性领域的问题。E-mail:yuanyl@pku.edu.cn
1003-0077(2016)04-0012-09
2014-09-05 定稿日期: 2015-03-20
国家自然科学基金(61375074,61371129)
TP391
A
猜你喜欢
中老年保健(2022年1期)2022-08-17
江苏钢铁(2022年9期)2022-07-02
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
航天工业管理(2020年9期)2020-12-28
汉字汉语研究(2020年1期)2020-04-21
现代语文(学术综合)(2017年9期)2017-10-19
诗选刊(2015年6期)2015-10-26
中文信息学报(2014年6期)2014-02-28
中国商人(2013年1期)2013-12-04
中国商人(2013年1期)2013-12-04
