
MOOCs交互模式聚类研究
2016-04-28 09:59孙洪涛李秋劼郑勤华
中国远程教育 2016年3期
孙洪涛++李秋劼++郑勤华


【摘 要】
聚类分析是学习分析和数据挖掘的常见方法,其核心在于通过分析对象特征属性集合的相似程度来进行分类。聚类分析在远程教育中有着广阔的应用空间,可以对在线学习行为模型和绩效水平进行有效划分,使之成为后续研究的重要基础。对在线学习领域的典型聚类研究进行分析,将聚类研究的流程和要点进行总结,着重探讨了聚类变量选择和有效性检验等方面,并对252门MOOCs的在线交互状况进行了聚类分析。研究发现,我国大多数MOOCs交互水平较低,教师在交互中并不活跃,没有进行积极的答疑辅导和交互组织;随着教师发布主题帖数量的增加,课程的交互水平会随之提高;教师的积极参与能够促进课程交互水平,但在交互水平较高的课程中,教师投入的增加并没有带来课程交互水平的增长;教师需要对学生的交互进行有效组织,才能促进交互水平的进一步提高。
【关键词】 聚类;MOOC;学习分析;交互分析
【中图分类号】 G40-057 【文献标识码】 A 【文章编号】 1009—458x(2016)03—0033—07
随着MOOCs的蓬勃发展,在线学习数据不断激增,学习分析和教育大数据也越来越受到关注。如何通过数据提升教育教学质量,提高教学管理水平,促进有效学习发生,吸引着越来越多的研究者和实践者。对在线学习过程数据的分析并非新生事物。从分析方法上,学习分析将统计分析、机器学习和复杂网络等方法进行了整合应用;从数据来源上,由于教育自身的特殊规律,在线教育大数据之“大”不同于医疗、交通乃至其他互联网领域,分析方法也有着不同的情境,需要远程教育领域的研究作为指导。
聚类分析是数据挖掘和机器学习的常见方法之一,属于无监督学习(unsupervised learning),其核心在于分析对象特征属性集合。通过分析对象属性集合的相似程度,将其划分为不同的类别,使类别内的数据相似度较大而类别间的数据相似度较小。从本质上,聚类分析是一种具有相对性的分析方法。在应用过程中,聚类分析可以对没有客观评价标准的对象属性进行分析,从而获得隐含的模式分类。聚类分析是研究在线学习的重要方法,在远程教育中有着广阔的应用空间,适用于在线教学中的多类问题解决。本文通过对在线学习领域的典型聚类研究进行分析,将此类聚类研究的流程和要点进行了总结,并通过聚类对252门MOOCs的在线交互状况进行分析。
一、在线学习领域的聚类研究
在线学习领域的聚类多针对在线学习主体的属性进行相似性分析并确定其类别。通过聚类分析学习者在学习环境或学习任务中的行为模式,分析学习者的特征属性(如人口学特征),或探索多类属性(如学习策略与学习绩效等)之间的关系。
现有的聚类研究中,较常见的方式是通过在线学习平台日志中的数据直接进行聚类分析,并以聚类结果为基础分析学习者的行为模式或绩效特征。例如,Amershi和 Conati(2006)在智能教学系统中对学习者的算法学习过程进行了分析,采用K-means基于描述学习者创建、修改和测试行为的24种变量进行聚类分析。该研究发现,通过聚类分析可以将学习者划分为不同类别,不同类别的学习者呈现出不同的学习行为和学习绩效特征。
魏顺平(2011)以Moodle教学平台的forum、course、wiki、assignment、resource、user 行为为聚类变量,将学生分成了三类,分析了学生活跃度集中于forum、course 和wiki,但resource 模块的访问频次却很低,并分析了这一现象的可能成因。田娜和陈明选(2014)根据网络学习平台的系统日志对学生进行了K-means 聚类分析,将学生分成了两类:一类是学前测试和学后测试成绩优秀的学生,另一类是学习比较活跃和花费时间较多的学生。研究者进而根据聚类结果对聚类影响因素进行了分析。
随着MOOCs的发展,在线学习数据日益丰富。聚类研究也随之走向深入,研究者试图通过聚类来分析更为复杂的学习者特征。聚类分析的输入变量渐渐由直接提取日志变量,变为通过日志中的单一变量进行整合和汇聚,试图揭示深层次的学习规律。例如,斯坦福大学的Kizilcec等人(2013) 以学生在MOOCs平台上观看视频和完成测验的行为数据为基础,设计了四类取值来表示学习者的学习状态。其中,0为“out”,表示完全没有参与到课程中;1 为“auditing”,表示没有完成测验但是观看了视频;2 为“behind”,表示在指定的时间点之后完成测验;3为“on track”,表示学生按时完成测验。研究者进而根据这些状态变量对来自三门课程中的超过9万名学生进行聚类,最终将学习者分为四类,包括“完成者”(Completing)“旁听者”(Auditing)“低参与度者”(Disengaging)和“筛选者”(Sampling)。英国开放大学的Ferguson和Clow(2015)同样采取了这种学习者状态评定的研究方法,最终获得了更为细致的七个学习者分类。基于这一趋势,我们对在线学习聚类研究的流程和要点进行了总结,并通过这一流程对在线学习中的典型聚类研究进行了解析。
二、在线学习研究中聚类的一般流程
1. 变量选择
聚类研究的核心思路是通过一组变量的取值计算变量对应的对象相似程度。变量参数的选取对聚类研究有着非常重要的影响。基于各自的研究问题,研究者需要从可获得的数据中选择或设计能够表征学习特征的变量作为输入到聚类算法中的原始参数。这些分析变量有些可以从学习平台中直接获得。例如, Beal等人 (2006)根据学习者自我报告的动机数据对学习者进行聚类。Amershi和Conati (2006) 选用描述学习者与学习环境之间各种交互的频率以及两次交互之间的时间间隔作为聚类变量,通过聚类得出学习者与学习环境交互的不同模式。
基于此类变量选择的聚类分析较为简便易行。但当涉及学习行为数据分析时,学习管理平台记录下来的数据往往较为琐碎,难以体现足够的教学意义。例如Moodle平台(2.6以上版本)中仅view类行为就超过30种,通过这些行为直接进行聚类可能会使结果难以解读。因此,为了确保聚类结果的实际意义,越来越多的研究者倾向于对学习平台中的数据进行处理,聚合成新的、具有更强解释力的数据。Kizilcec等人(2013)通过对测验和视频观看情况分析获得的参数,能够更好地对学习者的学习状态进行表征。该研究抓住观看视频和完成测验这两个MOOCs学习中的常见行为,将学习者行为分成了四种情况,构建了学习过程评价的指标。基于这些指标参数进行了聚类,更好地对学习者类别进行了划分。
通过上述分析可见,聚类分析的变量选择可以简单选取描述研究对象的某一类参数(如学习动机、交互频次等),也可以通过该对象的多个相关参数进行聚合(如通过观看视频和完成测验进行构建)。
2. 聚类过程
聚类分析通过对象属性的相似性进行分类。对象相似性比较有多种方法,对应的聚类算法可以分为四类:层次化聚类算法、划分式聚类算法、基于密度和网格的聚类算法和其他聚类算法(孙吉贵等,2008)。目前,采用较多的聚类算法包括K均值(K-means)聚类、 Kohonen 聚类和层次聚类(Hierarchical cluster)等。由于相似度比较具有一定程度的相对性,聚类结果(包括类别个数和对象特征)具有不确定性。不同聚类方法获得的结果可能有所不同。聚类分析往往需要经过多轮迭代才能获得有效的最终结果,在迭代过程中需要对不同聚类结果进行对比。
3. 类别分析
对聚类获得的各类别的分析和解释主要基于各类别原始参数的组内变量值域分布和组间值域差异。对于聚类结果的解释和分析需要对各类对象进行概括的描述。通过取值高低来衡量活跃水平和学习绩效等是常用的分析方法。例如,Amershi和 Conati(2006) 通过分析获得的各类别学习绩效的平均值,将聚类结果描述为高绩效组和低绩效组。同时,根据对高绩效组和低绩效组的比较,研究者进一步发现了低绩效组较频繁地对其算法设计进行调整,而每次调整之间的间隔较短。
但在更多的研究中,单纯的变量数值高低难以对聚类结果进行有效解释,需要进一步结合教学过程进行更加深入的解读。Kizilcec等人(2013)根据聚合的状态指标将MOOCs中的学习者划分为四类: ① “完成者”,此类学习者完成了课程中大部分测验; ② “旁听者”,此类学习者持续观看课程视频,但是很少完成测验;③ “低参与度者”,此类学习者在课程初期完成测验,但是之后没有持续下去;④ “筛选者”,此类学习者在课程进行过程中仅选择性地观看视频并完成测验。此类分析对学习过程进行了更为深入的解读。值得注意的是,聚类结果的分析往往和聚类过程迭代进行。由于聚类方法的相对性,聚类结果并不一定可以获得有效解释。研究者往往需要对聚类的类别个数和聚类变量等进行不断调整,才能最终获得具有教学意义的有效解释。
4. 有效性检验
聚类分析有效性的分析主要包括两个方面,聚类变量自身的统计有效性和其他变量的意义一致性。统计意义上的有效性主要通过各类统计指标判断。研究者可以通过调整类别数对比统计指标来获取较好的聚类方案。例如,Ferguson和Clow(2015)采用了侧影(silhouette)指数来衡量某个聚类结果中同类别中对象之间的相似度以及不同类别之间对象的差异度。平均侧影指数最大值为1,其值越接近1,聚类效果越好。在这两个MOOCs学习者分类研究中,平均silhouette 指数分别约为0.8和0.5。此外,聚类结果各组内方差和(Within group sum of square)也是常用的指数之一,衡量各组内成员之间的距离。组内方差和越小,聚类效果越好。聚类轮廓系数是另一种常用聚类质量评价指标(朱连江等,2010),对聚类结果(聚类簇)的凝聚度和分离度进行整合,较为有效地对聚类有效性进行了评价。
此外,聚类结果的意义一致性需要根据聚类结果对聚类变量之外的变量进行分析,以此来判断所获得的类别中其他变量的取值情况是否符合类别分析。例如,通过分析MOOCs中“旁听者”的学习成果,发现这类学习者中没有人最终获得课程证书,与这类学习者的行为特征相符。Beal等人(2006) 的研究中,对学习者自我报告的动机数据的聚类结果和教师对学习者动机和绩效的评价相一致。
5. 扩展研究
聚类分析的重要性在于在没有目标变量参照的情况下对研究对象进行分类,并可以成为后续研究的重要基础。基于聚类结果,研究者既可以通过调查研究和理论研究,深入挖掘各类别对象的特性,也可以通过有监督学习(supervised learning)探索影响因素和关联关系,还可以作为教学干预研究的起点。
Kizilcec等人(2013)在聚类分析结果的基础上,对四类MOOCs学习者的性别、年龄、工作状态、学习目的、学习满意度以及论坛参与情况等展开了调查和对比,丰富了对各个类别学习者的理解。通过对各类别学习者学习满意度的分析,研究者发现“旁听者”自我报告了与“完成者”类似的较高的学习满意度,进而认为“旁听者”与“完成者”之间学习行为的差异可能来源于两类学习者不同的学习偏好,而未来的课程设计需要进一步发现“旁听者”,并为他们提供针对性的服务。
Berland等人(2013)对新手程序员学习过程中的编程结果进行描述和聚类,发现了六种不同的学习状态。在学习理论的支持下,该研究者发现了新手程序员学习的三个主要阶段,包括探索阶段、基于探索的修改阶段以及改良阶段,并根据数据对基于探索的修改阶段进行了重新定义,加深了对程序员学习过程的认识。
Amershi和Conati(2006)在其关于探索性学习环境中聚类分析的研究中通过收集到的完整数据进行聚类之后,将聚类结果用于学习者实时数据分析中,通过聚类方法对学习者的学习进行实时监控和测评,并基于聚类结果进行了教学干预。该研究还对聚类方法进行了优化,分析了数据点采集的数量和分类结果准确性之间的关系,发现基于10%的数据也能够对学习者进行较为准确的分类。
三、MOOCs交互聚类案例研究
1. 研究目标与数据来源
案例研究旨在通过对我国MOOCs交互数据进行聚类分析,发现其交互现状,并对其交互特征进行探索。本研究的数据来自我国现有14个主要MOOCs 平台中的课程。在这14个平台中所有可见的1,388 门课程中,有622 门课程(占44.8%)在研究者访问阶段是可以浏览的,其他课程已经结束或还未正式开课,无法获得完整的课程信息(郑勤华等,2015)。由于MOOCs中的交互主要发生在课程论坛中,发帖和回帖是交互的主要形式(Barak et al., 2016),因此,本研究分析的是论坛交互。分析发现,622门课程中产生了交互的仅有295门,占47.4%,327门课程(占52.6%)中没有论坛交互。针对主题帖数量进行深入分析可以发现,交互状况极度不平衡(孙洪涛等,2016),在全部课程中仅有252门课程能够采集到交互数据。本研究针对这些课程进行了分析。
2. 分析方法
本研究通过K-means聚类分析对存在有效交互的课程进行了分析。K-means 聚类算法是聚类分析中使用最为广泛的算法之一。该算法选取 k个初始聚类中心,按最小距离原则将各样本分配到 k 类中的某一类,之后不断地计算类别中心,并调整各样本的类别,最终使各样本到其所属类别中心的距离平方之和最小(周世兵等,2010)。本研究采用的分析工具是SPSS Modeler 14.1。
在聚类变量选取方面,为了更好地表征MOOCs交互特征,我们采取了数量变量和状态变量相结合的方式。在论坛交互中,帖子数量、回帖的时间特性和教师的交互投入情况是表征论坛交互状况的重要方面。在本研究中,我们采用了主题帖数、教师发布的主题帖数、教师答疑辅导帖数、回帖热度和回帖时间间隔五个变量对MOOCs中的交互总量、交互时间和教师投入进行了分析。其中,主题帖、教师主题帖和答疑辅导帖等指标直接采用数量;回帖热度采用等级表示,0为未回帖,1为每主题帖平均3个以下回帖,2为平均4-8个回帖,3为平均8个以上回帖;回帖时间间隔也采用了等级表示,其中1为12小时以内回帖,2为24小时之内回帖,3为24-48小时回帖,4为回帖间隔大于48小时,5为未回复。由于各类数据的取值区间不同,在聚类分析中对数据进行了预处理,避免了数值差异过大引起的结果偏差。主题帖数等数据偏度较高,且存在极值。但这些数据可能体现特殊的交互模式,因此没有剔除极值。
3. 聚类分析
(1)聚类总体情况
通过聚类将全部课程分为5类(如图1所示)。其中,最大类别包含139门课程(占55.16%),最小聚类为4门课,仅占1.59%(如表1所示)。
如图3所示,在聚类影响因素方面,答疑时间间隔和回帖热度是聚类结果的最重要影响因素。这两个变量对于类别划分起到了最为重要的作用。
(3)各类别对比分析
通过分析可以看出,聚类3所占比重最大,占全部课程的55.16%(139门),课程的答疑时间间隔非常长(均值4.67),平均回帖热度仅为1.03,教师在线答疑帖子均值为16.71,课程主题帖平均为128.29个,教师评价发主题帖2.38个。可见,这类课程的交互水平较低,教师很少发主题帖,也很少答疑。
聚类5占全部课程的29.37%(74门),课程的答疑时间间隔较短(均值为2.19),平均回帖热度也较低,仅为1.03,教师在线答疑帖子较多,平均为91.74,课程主题帖平均为228.93个,教师发主题帖平均为8.72个。这类课程中的交互水平稍高,教师发主题帖和答疑较为积极。
聚类4占全部课程的10.71%(27门),课程的答疑时间间隔较长(均值3.07),平均回帖热度在各个类别中最高(2.48),教师在线答疑帖子均值为85.41,课程主题帖平均为230.7个,教师评价发主题帖21.48个。此类课程交互水平较高,教师发布了更多主题帖,吸引了更多学生参与,形成了很高的回帖热度。
聚类1课程数量很少,仅占全部课程的3.17%(8门),课程的答疑时间间隔较短(均值2.5),平均回帖热度为2.25,教师在线答疑帖子均值在各类中最高(266.13个),课程主题帖非常多,达到了 2,071.5个,教师评价发主题帖15.13个。教师发布的主题帖不多,但花费了大量精力进行答疑辅导。虽然回帖热度不是各类别中最高的,但由于主题帖数量极多,总体帖子的数量非常多,课程交互水平很高。
聚类2的课程数量更少,仅占全部课程的1.59%(4门)。这类课程的答疑时间间隔在各类别中最短(均值1.25),平均回帖热度为2.00,教师在线答疑帖子均值达到了912个,课程主题帖平均为1,110.5个,教师评价发主题帖88.75个。这类课程总体也体现出了很高的交互水平,但和前一个类别又有着较大差异。此类课程的教师发帖数量达到了极高的水平,无论是主题帖还是在线答疑帖子,都远远高于其他类别。课程答疑间隔也是各类课程中最短的。教师的高投入促进了课程整体交互水平的提高。
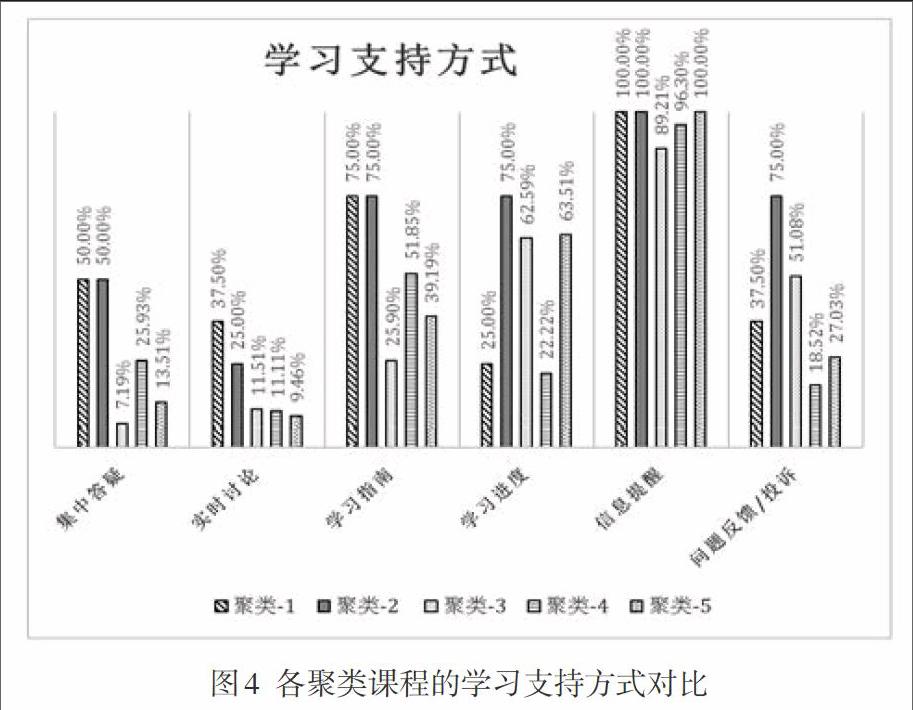
(4)各类别学习支持方式分析
学习支持是远程教学的重要组成部分。学习支持状况对于在线教学交互有着重要的影响。通过聚类对各个课程的交互进行分析之后,笔者进而对各类课程的学习支持方式进行了分析。通过图4可以看出,交互效果最好的聚类2采用了丰富的学习支持方式,在各项学习支持中采用的比例几乎都是最高的(仅实时讨论采用率位居第二),交互效果次之的聚类1的学习支持方式也非常丰富,交互水平最低的聚类3中各项学习支持方式采用的比例都非常低。
4. 结果讨论
通过上述分析可以发现,大多数MOOCs的交互水平较低,教师在交互中并不活跃,没有进行积极的答疑辅导并组织论坛中的交互。教师的积极参与能够促进课程交互水平。随着教师发布主题帖数量的增加,课程的交互水平会越来越高。这一现象在聚类3、聚类4和聚类5的对比中非常明显。但在交互水平较高、论坛非常活跃、帖子数非常多的课程中,教师的投入增加并没有带来课程交互水平的线性增长。这一现象与García-Saiz 等人(2013)和Hernández-García等人(2015)的发现相吻合,即在线论坛交互非常活跃的教师,反而在一定程度上阻碍了学生之间的交流,降低了学生的发帖率。
对比聚类1和聚类2可以看出,在交互水平高的课程中,学生之间的交互发挥了更加重要的作用。在主题帖最多的聚类1中,教师只发了大约15个帖子,不足总主题帖数的1%,教师也只回复了全部帖子的12.84%。聚类2中,教师发主题帖的数量是聚类1的5.87倍,答疑帖数是聚类1的3.43倍,但总主贴数却仅有聚类1的53.60%,总回帖热度也比聚类1低。这个对比表明,在聚类1中存在大量的生生交互,聚类1中的教师通过自己较高的投入带动了学生的交流,形成了较高的交互水平。
诚然,我国MOOCs中大多数课程的交互水平仍然偏低。在这种情况下,教师的积极发帖值得鼓励。聚类2中教师的高投入难能可贵。而在交互水平较高的课程中,聚类1的课程更加重视组织和调控,从而取得了比聚类2更好的效果。
对于更多课程而言,交互水平的提高需要教师增加投入,更好地通过教学设计组织教学交互。从各类课程学习支持方式的差异可以看出,采用更加丰富的学习支持方式,对学生的学习过程进行全面支持,有助于交互水平的提高。
四、聚类研究展望
聚类研究对于学习分析有着重要意义。通过聚类可以将较为复杂的学习行为和绩效水平等进行有效划分,便于开展更为深入的学习规律探索。目前,在线学习研究中聚类分析尚处于探索阶段,多用于发现行为模式或者描述学习者的多样性,对聚类结果的深入探索和基于聚类的教学干预还较为少见。
首先,多数研究者并没有讨论研究情境和聚类结果之间的关系,对聚类结果的解释也少有与理论的结合,因而无法得知聚类结果能在多大范围内推广,与已有的远程学习研究成果有何关系。例如Ferguson和Clow(2015) 采用了与Kizilcec等人(2013) 研究中类似的方法,对基于社会建构理论的多门课程进行分析,发现了不同于先前研究结果的多个新的学习者类别。这说明不同学习情境中的类似行为的聚类结果可能不同,而这种不同也许与学习情境背后的教学和学习理论有关。其次,虽然许多研究者常比较聚类得到的行为模式或者学习者类别之间学习绩效的差异,但少有研究者定量地使用聚类的结果来预测学习绩效或者分析学习者的需求。最后,对于如何采用聚类分析的结果支持教育干预的设计以及教育决策的制定还有待进一步探索。
因此,基于聚类分析的在线学习研究应更多地将模式发现与已有理论结合起来,探索聚类结果的深层意义。正如Wise和Shaffer(2015)所指出的,基于大数据的学习分析研究更应该注重与理论的结合。远程教育理论研究成果能够帮助研究者选择出更有教育意义的聚类变量,辨别出更有价值的聚类结果,并对聚类结果做出更合理的解释。在聚类研究结果的基础上开展应用研究,对在线学习者的学习状态进行更为及时的分析,提供相应的教学干预和学习支持。
(编者注:北京师范大学远程教育研究中心就“学习分析的核心技术与实证研究”主题为本刊撰写了系列论文,旨在对重要学习分析技术和经典研究进行解析,阐明不同分析技术在远程教育领域应用的关键环节和要点,并通过案例研究呈现具体的学习分析技术应用过程。本篇为该系列第一篇。)
[参考文献]
[1] Amershi, S., & Conati, C. (2006). Automatic recognition of learner groups in exploratory learning environments. In M. Ikeda, K. D. Ashley & T. Chan (Ed.), Intelligent Tutoring Systems (pp. 463-472). Springer Berlin Heidelberg. doi: 10.1007/11774303_46.
[2] Barak, M., Watted, A., & Haick, H. (2016). Motivation to learn in massive open online courses: Examining aspects of language and social engagement. Computers & Education, 94, 49-60. doi:10.1016/j.compedu.2015.11.010.
[3] Beal, C. R., Qu, L., & Lee, H. (2006). Classifying learner engagement through integration of multiple data sources. In Proceedings of the National Conference on Artificial Intelligence (Vol. 21, No. 1, p. 151). London: AAAI Press.
[4] Berland, M., Martin, T., Benton, T., Petrick Smith, C., & Davis, D. (2013). Using learning analytics to understand the learning pathways of novice programmers. Journal of the Learning Sciences, 22(4), 564-599. doi:10.1080/10508406.2013.836655.
[5] Bowers, A. J. (2010). Analyzing the longitudinal K-12 grading histories of entire cohorts of students: Grades, data driven decision making, dropping out and hierarchical cluster analysis. Practical Assessment, Research & Evaluation, 15(7), 1-18.
[6] Ferguson, R., & Clow, D. (2015). Examining engagement: analysing learner subpopulations in massive open online courses (MOOCs). In Proceedings of the Fifth International Conference on Learning Analytics And Knowledge (pp. 51-58). ACM.
[7] García-Saiz, D., Palazuelos, C., & Zorrilla, M. (2013). Data mining and social network analysis in the educational field: An application for non-expert users. In A.Pe?a-Ayala (Ed.), Educational data mining: Applications and trends (pp. 411-439). Berlin, Heidelberg: Springer, Berlin/Heidelberg.
[8] Hernández-García, ?., González-González, I., Jiménez-Zarco, A. I., & Chaparro-Peláez, J. (2015). Applying social learning analytics to message boards in online distance learning: A case study. Computers in Human Behavior, 47, 68-80.
[9] Kizilcec, R. F., Piech, C., & Schneider, E. (2013). Deconstructing disengagement: analyzing learner subpopulations in massive open online courses. In Proceedings of the third international conference on learning analytics and knowledge (pp. 170-179). ACM.
[10] Wise, A. F., & Shaffer, D. W. (2015). Why Theory Matters More than Ever in the Age of Big Data. Journal of Learning Analytics, 2(2), 5-13.
[11] 孙洪涛,郑勤华,陈丽. 中国MOOCs教学交互状况调查研究[J]. 开放教育研究,2016,(1):72-79.
[12] 孙吉贵,刘杰,赵连宇. 聚类算法研究[J]. 软件学报,2008,(1):48-61.
[13] 田娜,陈明选. 网络教学平台学生学习行为聚类分析[J]. 中国远程教育,2014,(11):38-41.
[14] 魏顺平. Moodle平台数据挖掘研究——以一门在线培训课程学习过程分析为例[J]. 中国在线学习,2011,(1):24-30.
[15] 周世兵,徐振源,唐旭清. K-means算法最佳聚类数确定方法[J]. 计算机应用,2010,(8):1995-1998.
[16] 朱连江,马炳先,赵学泉. 基于轮廓系数的聚类有效性分析[J]. 计算机应用,2010,(S2):139-141,198.
收稿日期:2016-01-20
定稿日期:2016-02-29
作者简介:孙洪涛, 博士,高级工程师,中央民族大学现代教育技术部(100081)。
李秋劼,在读博士,加州大学尔湾分校教育学院(92697)。
郑勤华,博士,副教授,北京师范大学教育学部(100875)。
责任编辑 日 新
猜你喜欢
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国远程教育(2016年11期)2016-12-27
中国远程教育(2016年11期)2016-12-27
新课程·小学(2016年10期)2016-12-12
人间(2016年28期)2016-11-10
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
