
关联规则评分预测的协同过滤推荐算法
2016-04-12 02:06:18王竹婷
合肥学院学报(综合版) 2016年1期
王竹婷
(合肥学院 计算机科学与技术系,合肥 230601)
关联规则评分预测的协同过滤推荐算法
王竹婷
(合肥学院计算机科学与技术系,合肥230601)
摘要:协同过滤算法是目前应用于电子商务个性化推荐系统中的一种最成功的推荐算法。为缓解因数据稀疏性问题导致的算法推荐质量下降,将关联规则分析引入协同过滤算法中,预测部分未评分项目的评分值,再运用传统的基于用户的协同过滤算法实施推荐。实验结果表明:与传统的协同过滤算法相比,采用关联规则预测评分可以一定程度提高算法推荐质量。
随着计算机网络技术和电子商务的深入发展,个性化推荐系统在电子商务领域发挥的作用日益凸显。该系统能够记录并分析用户的网上行为,挖掘出用户感兴趣的商品项目,并将商品快速推荐给相应的用户,同时提高电子商务网站产品的销售量。而协同过滤算法作为目前应用最为成功的推荐算法之一,已广泛应用于各类电子商务网站中。
协同过滤算法又分基于用户的协同过滤[1](user_based CF)和基于项目的协同过滤[2](item_based CF)两大类。前者通过用户共同评分过的项目评分值计算不同用户之间的相似程度,生成与目标用户相似度较高的近邻用户集合,利用近邻用户对某一项目的评分值预测目标用户的评分值;后者则利用同一用户评分过的不同项目评分值计算项目之间的相似程度,再通过目标用户已评分项目预测未评分项目。协同过滤无需对推荐项目进行内容分析,直接通过用户对项目的历史评分数据就可以实施推荐,并可较好的实现跨类别项目的推荐。但随着在线用户规模和项目数量的剧增,传统的协同过滤算法已无法适应新形势下的需求,其中由于数据的稀疏性而导致的推荐质量下降的问题日益突出。
为解决因数据稀疏性导致计算精度下降的问题,一些学者提出了基于协同过滤的填充算法[3],最简单的是利用用户评分域中间值填充未评分项目,或采用某一用户已有的平均评分填充未评分项目,再进行协同过滤推荐。这些方法一定程度上提高了协同过滤算法计算的精确度,但这种利用中间值或均值填充没有考虑到用户对不同项目的兴趣差异。邓爱林等人先利用基于项目的协同过滤算法预测出所有未评分项目的评分值,再利用基于用户的协同过滤方法进行推荐[4],这种算法的效果虽好于均值填充,但也存在大量数据预测偏差。
本文将提出一种关联规则与协同过滤相结合的混合算法。首先,计算每一个项目的支持度和项目之间的置信度,以置信度为权重,根据用户已评分项目值预测部分受欢迎程度较高且未评分项目的评分值填充到用户项目矩阵中,再利用基于用户的协同过滤算法,计算用户间的相似度,选择近邻用户实施项目推荐。
1传统的基于用户的协同过滤算法
基于用户的协同过滤算法是基于这样的推荐思想,如果不同的用户对于某些项目具有共同的兴趣爱好,那么他们对于其他的项目也应该具有相似的兴趣爱好。该算法首先根据用户之间共同拥有的项目评分情况计算出用户之间的相似程度,根据用户间的相似度寻找近邻用户,再通过近邻用户对某一项目的评分值预测目标用户未评分项目,选择评分值高的推荐给目标用户。因此,在基于用户的协同过滤算法中,用户之间的相似度计算方法是非常重要的。
1.1传统的用户相似性度量方法
用户间的相似性度量方法主要分为三种:余弦相似性、修正的余弦相似性、Pearson相关系数,其中Pearson相关系数被实验证明是效果最好的一种计算相似性的方法[5],下文将作重点介绍。
针对一个有m个用户和n个项目的推荐问题,可以用一个m*n列的矩阵R表示用户评分数据,如表1所示,矩阵中第i行第j列个元素Rij表示用户i对项目j的评分值。
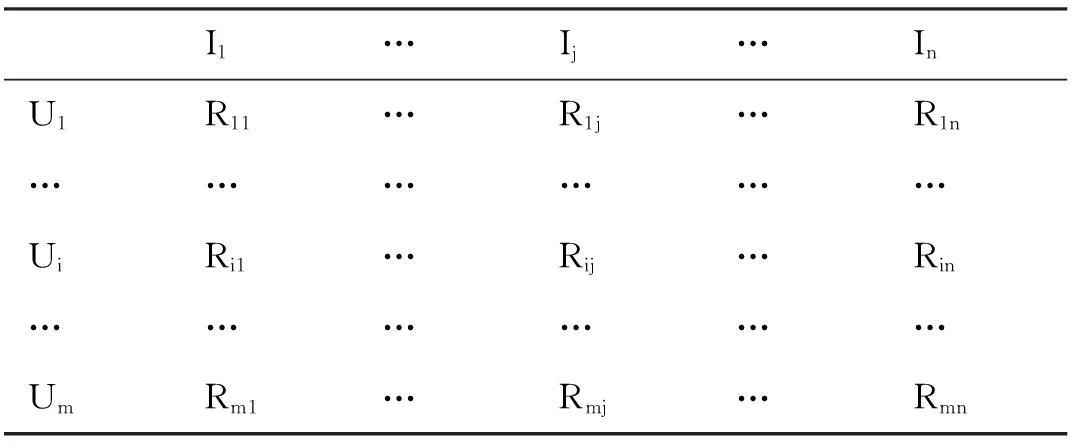
表1 用户-项目评分矩阵
基于用户的协同过滤算法首先要通过用户评分数据计算用户之间的相似度,如用户i和用户a之间的相似度用sim(i,a)表示。Pearson相关系数计算公式如公式(1)所示,Iui和Iua分别为用户i和用户a评分过的项目,Iui∩Iua表示用户i和a共同评分过的项目,Ri表示用户i的平均评分值,该公式通过统计用户之间共同评分项目的评分差异确定他们的相似性。
(1)
1.2传统的用户相似性度量方法缺陷
计算Pearson相关系数,首先要寻找两两用户之间共同评分过的项目。针对公式(1)不难发现,Pearson相关系数计算公式,在用户共同评分项目较多,评分值比较相似的时候,计算出的相似程度较高;当用户间评分差异较大时,计算得出的相似程度较低,能够从一定程度上反映用户之间兴趣爱好的相似与否。但在实际应用中,推荐系统所处理的数据是极端稀疏的,某一个用户的评分项目往往不超过项目总数的1%,两两用户共同评分过的项目就更加稀少,采用Pearson相关系数计算用户相似度会造成较大的误差。比如,某两个用户,他们的兴趣可以完全不相同,只有一到二个项目是共同评分过的,而且评分值非常接近,利用公式(1)计算相似度,那么这两个用户的相似度值可能接近于1,计算结果表示该两名用户属于近邻用户,在这个基础上进行推荐,推荐效果并不理想。
为降低因共同评分项目过少而带来的负面因素,有学者提出在计算用户相似度时先统计共同评分项目数,当共同评分的项目数过低时认为两者的相似度为0,或加入惩罚因子,适当降低相似度值。这种方法可以一定程度上提高相似度值的可信赖程度,但可能导致整体近邻用户减少而降低预测的准确性。本文利用不同项目之间的相关性和用户已有评分值预测出部分未评分项目评分值填充致稀疏矩阵,再通过基于用户的协同过滤算法进行推荐,提出了一种基于关联规则评分预测的协同过滤算法。
2基于关联规则评分预测的协同过滤算法
关联规则是数据挖掘领域研究的一项重要技术,可以挖掘出不同类别的项集之间的关联关系[6]。在个性化推荐系统中,传统的关联规则挖掘通过计算项集的支持度和置信度,找出满足最小支持度和置信度的强关联规则集合,并以此为依据帮助用户根据其已经购买过的项目预测其可能喜欢的项目。
关联规则挖掘最早应用于零售业,用于发现不同商品在销售过程中的相关性,取得了较好的效果,也是个性化推荐技术中的重要方法之一。但是,由于其在处理大规模数据时,产生了大量的冗余规则,严重影响了算法的执行效率,而且关联规则只能挖掘出用户偏爱的项目,无法预测评分值。本文则利用关联规则分别挖掘一阶和二阶频繁项集,再以二阶频繁项集的置信度为权值和用户已选项目的评分值加权平均预测出部分未评分项目值,改善用户评分数据的稀疏性,利用填充后的评分数据计算用户相似性,根据近邻用户的相似性进行推荐。
2.1关联规则的相关概念
对于一个有n个的不同项目的集合I={I1,I2,…,In},其中Ii表示编号为i的项目,多个项目的集合成为项集,k阶项集则表示一个包含k个项目的集合。在推荐问题中,可以将每一位用户曾经购买过所有项目的集合作为一个事物T,每一个事物T是项集I的一个子集,所有m个用户购买过的事物集合构成交易数据库D。本文将利用交易数据库D,使用强关联规则挖掘出项目与项目之间的关联程度。
支持度反映的是某一个或多个项集在数据库D中同时出现的概率,例如项集A和项集B的支持度可以用P(A∪B)表示;置信度反映的是两个项集之间相关联的程度,例如项集A对项集B的支持度可以用P(B|A)表示,即项集A出现时同时项集B也出现的概率。
support(A⟹B)=P(A∪B)
(2)
confidence(A⟹B)=P(A|B)
(3)
设关联规则的最小支持度和最小置信度分别为sup_min和conf_min。当规则R的支持度和可信度均不小于sup_min和conf_min,则称为强关联规则。关联规则挖掘的目的就是找出满足强关联规则的集合,从而指导商家的决策。
2.2关联规则评分预测
前面分析过传统的Pearson相关系数度量方法在计算用户相似度时由于用户评分数据的极端稀疏导致计算精度下降。因为计算Pearson相关系数需要搜集用户共同评分过的项目,不同的用户之间共同评分的项目越多计算的准确率相对越高,但由于某一位用户的实际购买能力是有限的,导致实际应用过程中绝大多数用户之间共同评分的项目非常稀少。但用户未购买不代表该项目用户不喜欢,尤其对于一些用户购买频率较高的项目,其被新用户的接受的可能性较大的,所以对这些项目进行评分预测是很有必要的。
为提高算法的执行效率,本文不对所有满足强关联规则的项集进行挖掘,只挖掘到二阶频繁项集。首先,计算所有一阶项目的支持度,选择大于最小支持度阈值的一阶频繁项集,再在一阶频繁项集的基础上寻找满足最小支持度和置信度的二阶频繁项集。以二阶频繁项集的置信度为权值,利用用户已有的评分项目预测出那些支持度较高但未被用户购买过的项目评分值。
(4)
2.3基于关联规则预测评分的协同过滤推荐
利用强关联规则预测出的部分项目评分值填充至用户_项目评分矩阵,再利用公式(1)计算出用户与用户之间的相似程度,根据用户间的相似程度产生用户a的最近邻居集合NBua,通过用户a的最近邻居对项目i的评分预测用户a对项目i的评分值Pai,计算方法如公式(5)所示。
(5)
3实验仿真
3.1数据集
本文采用MovieLens站点公开提供的标准数据集对传统的基于用户、基于项目的协同过滤算法和本文所提出的算法分别进行测试。笔者从中选取5组数据,每组数据分训练集和测试集,其中训练集中包括943名用户对1 682部电影的100,000项评分数据;评分值的取值范围为1-5;每位用户至少有20个评分项。实验通过训练集数据预测测试集中用户对项目的评分值,推荐效果越优秀。
3.2度量标准
实验以平均绝对偏差MAE为判断算法的推荐质量的标准,其计算方法如公式(6)所示,pij是通过训练集产生的预测评分,qij是测试集提供的的实际评分,Ni是测试集所提供的用户i的评分项目数量,MAEi是用户i对Ni个项目预测评分的平均绝对偏差,公式(7)中M是全体用户总数,MAE则是全体用户的平均绝对偏差。从公式中不难看出,MAE的值越小,算法预测的结果与实际评分值越接近,算法推荐的准确性越高。
(6)
(7)
3.3实验结果
实验中选用的5组数据训练集中都有80 000条评分记录,用户_项目评分矩阵的数据密度为5.04%。利用三种算法的预测结果和测试集中的实际数据分别计算MAE值,如图1所示,图中纵坐标为算法衡量标准MAE值,横坐标为MovieLens提供的5组数据集的名称。实验结果证明,本文所提出的改进协同过滤算法MAE值最小,推荐质量最优。
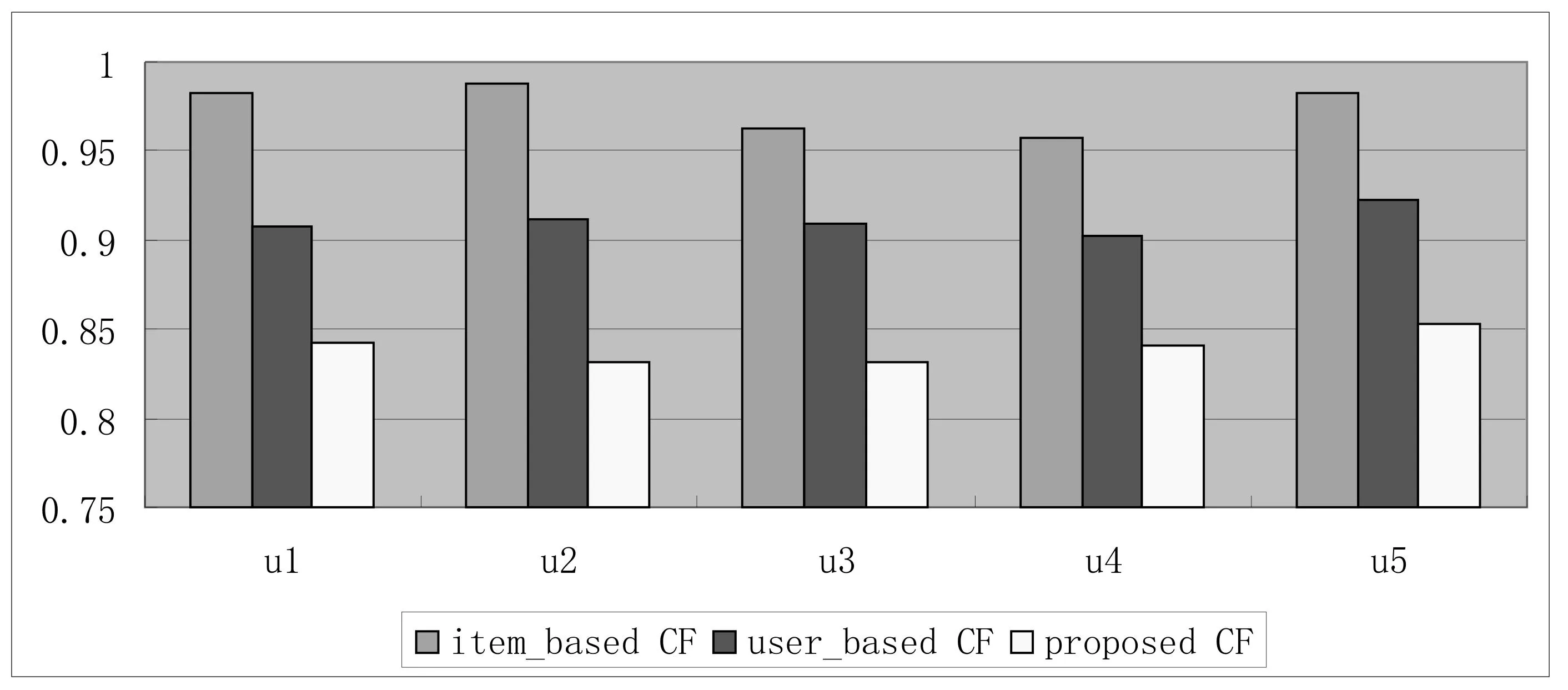
图1 三种协同过滤算法测试结果比较
4结论
针对传统协同过滤算法因数据稀疏性而导致的推荐质量下降问题,提出了一种基于关联规则评分预测算法,利用项目之间的相关性和用户已评分项目值预测部分受欢迎程度较高的未评分项填充至稀疏矩阵,再基于用户的协同过滤进行推荐,实验测试结果表明,本文提出的改进算法其推荐质量优于传统的协同过滤算法。
参考文献:
[1]HerlokcerJ L, KOnstan J A,Borhcesr A,et al. An Algorithmic Framework for Performing Collaborative Filtering[C]//Porceedings of ACM SIGIR,ACM Press,1999:230-237.
[2]Sarwar B,Karypis G,Konstan J, et al.Item-Based Collaborative Filtering Recommendation Algorithms[C]//Proceedings of the 10th International World Wide Web Conference,2001:285-295.
[3]Breese J,Hecherman D,Kadie C.Empirical Analysis of Predictive Algorithms for Collaborative Filtering[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,1998:43-52.
[4]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003.14(9):1621-1628.
[5]Herlocker L J,Konstan A J,Riedl T J.Empirical Analysis of Design Choices in Neighborhood-based Collaborative Filtering Algorithms[J].Information Retrieval,2002,5(4):287-310.
[6]李杰,徐勇,王云峰,等.面向个性化推荐的强关联规则挖掘[J].系统工程理论与实践,2009,29(8):144-152.
[责任编辑:张永军]
Collaborative Filtering Recommendation Algorithm Based on Association Rule Score Prediction
WANG Zhu-ting
(Department of Computer Science and Technology, Hefei University, Hefei 230601,China)
Abstract:Collaborative filtering algorithm is one of the most successful recommendation algorithms applied to the personalized recommendation system of E-commerce.In order to alleviate the problem of the algorithm recommendation quality decline that caused by the data sparse,the association rule analysis is introduced into the collaborative filtering algorithm,which predicts the item ratings of the non rating items,and then uses the traditional user_based collaborative filtering algorithm to implement the recommendation.The experimental results show that compared with the traditional collaborative filtering algorithm,the algorithm uses association rules to predict the item ratings can improve the recommended quality.
Key words:recommendation system;collaborative filtering;association rules
中图分类号:TP301.6
文献标识码:A
文章编号:1673-162X(2016)01-0065-05
作者简介:王竹婷(1984—),女,安徽马鞍山人,合肥学院计算机科学与技术系助理实验师,硕士;研究方向:人工智能、数据挖掘。
基金项目:合肥学院2014年度科研发展基金一般项目(14KY11ZR)资助。
收稿日期:2015-07-01修回日期:2015-12-12
关键字:推荐系统;协同过滤;关联规则
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
当代陕西(2019年15期)2019-09-02 01:52:00
计算机应用(2018年5期)2018-07-25 07:41:26
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电讯技术(2011年11期)2011-04-02 14:00:37
当代修辞学(2011年2期)2011-01-23 06:39:12
