
基于k阶依赖扩展的贝叶斯网络分类器集成学习算法
2016-04-11 02:54张剑飞刘克会杜晓昕
东北师大学报(自然科学版) 2016年1期
关键词:贝叶斯网络
张剑飞,刘克会,杜晓昕
(齐齐哈尔大学计算机与控制工程学院,黑龙江 齐齐哈尔 161006)
基于k阶依赖扩展的贝叶斯网络分类器集成学习算法
张剑飞,刘克会,杜晓昕
(齐齐哈尔大学计算机与控制工程学院,黑龙江 齐齐哈尔 161006)
[摘要]针对传统的KDB(k-dependence Bayesian network classifiers)算法不能用Boosting技术集成进行性能提升的不足,提出了一种放松依赖条件的KDB集成分类器学习算法(BLCKDB).首先放松传统KDB选择最强依赖关系的条件限制,通过参数调节产生不同KDB分类器,然后用Boosting对产生的KDB分类器进行集成,实现集成分类器的构造.实验结果表明,该分类器分类准确性比KDB算法有较大的提升,尤其是对多属性数据集更加明显.
[关键词]贝叶斯网络;KDB;依赖关系;Boosting;集成学习
0引言
分类是模式识别和机器学习的基本内容,其目的是利用样本数据构建一个分类模型,并利用这个模型对未知类别样本进行预测.通过训练样本构造分类器的方法有多种,比较著名的分类器包括决策树分类器、神经网络分类器、支持向量机分类器和贝叶斯分类器等.其中朴素贝叶斯分类器是最简单的贝叶斯网络分类器,以简单高效而著称,被应用于各个领域.人们在朴素贝叶斯分类器的基础上进行改进,得到了许多性能优良的贝叶斯分类器.朴素贝叶斯分类器的改进方法主要有属性依赖扩展、属性选择和整体集成.在属性依赖扩展方面,N.Friedman[1]放宽朴素贝叶斯属性独立性假设,提出了一种树状贝叶斯网络(Tree Augmented Naïve Bayesian,TAN),允许每个属性至多有一个属性父节点;M.Sahami等[2]将朴素贝叶斯和贝叶斯网络结合起来提出了k依赖扩展的朴素贝叶斯分类器(KDB);J.Cheng等[3]在TAN基础上提出了BAN(Bayesian Network Augmented Naïve Bayesian classifier),它假设属性间存在有向无环的网状依赖关系;石洪波等[4]提出了一种限定性的双层贝叶斯分类模型,通过选择对分类影响较大的属性来建立依赖关系,然后使用关键属性将属性间重要的依赖关系表达出来.在属性选择方面按照其对分类影响的大小对不同的属性进行加权,将贝叶斯分类器构造的重点放在关键属性上,从而使分类器的性能得到提升.秦峰等[5]通过训练样本学习得到属性加权参数,然后对每个属性赋予权值,从而构建出分类性能更好的加权朴素贝叶斯分类器;李方等[6]基于卡方拟合构造思想提出了一种新的属性间相关性度量方法,改进了属性加权的贝叶斯分类模型;邓维彬等[7]从粗糙集理论属性的重要性出发,提出了以属性的重要性作为权值的加权朴素贝叶斯分类方法.从整体集成分类角度可以将贝叶斯分类器作为基分类器,采用分类器集成技术将其分类性能进行提升.Boosting是一种重要的集成技术,它能够提升不稳定分类算法性能,但是朴素贝叶斯是稳定分类器,不能直接使用Boosting技术进行集成,因此如何改变贝叶斯分类器的稳定性成为贝叶斯分类器集成的一大难题.K.M.Ting等[8]提出了一种将决策树和朴素贝叶斯相结合的算法,提升了朴素贝叶斯分类器的性能;K.M.Ting[9]又对树状的分层贝叶斯分类器进行集成,取得了良好的分类效果;石洪波等[10]通过放松TAN最大权重树的构造条件,提出了GTAN方法,构造多个TAN分类器,最后对这些分类器进行集成,证明集成后的分类器有较高的分类准确性;李凯等[11]利用Oracle选择机制破坏朴素贝叶斯分类器稳定性,提出了一种基于Oracle的选择朴素贝叶斯集成算法;张雯等[12]提出了基于属性加权的贝叶斯集成方法(WEBNC),这种分类方法不仅具有较高的分类准确性还有较高的泛化能力.对于比较复杂的贝叶斯分类器,人们主要使用启发式的方法来获得最优的网络结构[13].
近年来,贝叶斯网络学习方面的研究主要集中在使用各种智能算法来减小候选网络的搜索空间,以达到更快找到最优网络结构的目的.常用于贝叶斯网络学习的智能算法有遗传算法[14]、蚁群算法[15]、进化算法[16]等.目前,贝叶斯分类器的集成主要是通过对属性空间进行划分和选择,然后根据选择的结果训练不同的贝叶斯分类器,而在通过结构学习方法上实现分类器集成方面的研究相对较少.朴素贝叶斯分类器的k阶依赖扩展(KDB)允许每个属性节点和其他属性节点最多有k条依赖边,能够比TAN和朴素贝叶斯更好地利用属性间的依赖信息,使之分类准确性更高.但是使用传统方法构造的KDB分类器是不稳定的,需要采取有效方法来改变其稳定性,才能使用Boosting技术对其进行性能提升.本文通过放松KDB构建条件,产生不同的KDB分类器,并采用Boosting技术对其集成,达到提高传统KDB算法的分类性能目的.
1KDB模型及其构造算法
1.1KDB模型
朴素贝叶斯分类器是一种简单高效的贝叶斯分类方法,但其属性独立性假设使其不能利用属性间依赖信息,限制了它的分类性能.Friedman提出的TAN算法,假设每个属性至多有一个属性父节点,能够较好的利用属性间的依赖信息,但也只能较少部分利用依赖信息.为了更进一步利用属性间的依赖信息,Sahami提出了KDB方法,将属性父节点的个数增加到k.依赖属性的个数k可以根据需要设定,因此可以通过k值来调节分类器和数据拟合程度,从而获得更好的分类性能.当k=1时,朴素贝叶斯的k依赖扩展就是TAN分类模型.但是随着k值的增大,在分类器准确率提高的同时,分类效率也会随之下降,因此综合考虑分类正确率和分类效率问题,将朴素贝叶斯进行二阶扩展比较合适,本文中k取为2.
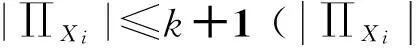

图1 朴素贝叶斯二阶依赖扩展结构
1.2KDB的构造算法
对于给定训练集Dataset={(x1,y1),(x2,y2),…,(xi,yi),…,(xn,yn)},其中xi是训练数据中第i个实例,yi是该实例的类别.分类的目的是使用特定方法对数据集Dataset进行分析,形成一个能对未知类别样本进行预测的分类模型.根据贝叶斯最大后验准则,对于任意给定的实例(xi1,xi2,…,xiN),贝叶斯分类器将其归入到后验概率P(c|xi1,xi2,…,xiN),则最大的类C*为

(1)
1.2.1KDB分类器的模型
在KDB模型中,由于每个节点最多有k个属性节点,所以KDB分类器的模型表述为

(2)
对于2阶依赖扩展的KDB,∏xik有3种形式:
(1) ∏xik={ci},即xik仅有类似其父节点,而没有属性父节点;
(2) ∏xik={ci,xjl},即xik有1个属性父节点和类父节点;
(3) ∏xik={ci,xjl,xjk},即xik具有2个属性父节点和1个类父节点.
因此,构造KDB分类模型的主要问题就是确定每个节点的属性父节点.Sahami提出的KDB构造算法的主要思想是根据属性和类间的互信息I(X;C)来指定依赖弧的方向,根据类条件互信息来判断属性间是否存在依赖关系.
1.2.2KDB算法过程
(1) 计算每个属性和类的互信息I(Xi;C)以及不同属性间的类条件互信息I(Xi;Xj|C),计算方法为:

(3)


(4)
(2) 初始化贝叶斯网络结构G,G初始化时仅有一个类节点C,用S表示添加到G中的属性节点集,初始化时S置为空.
(3) 重复以下过程至S中包含所有的属性节点.
(a) 选择不在S中并且I(Xi;C)值最大的属性为Xmax,在G上添加一个节点表示Xmax,并添加一条从类节点指向Xmax的弧.

(c) 将Xmax添加到S中.
(4)根据贝叶斯网络G和数据Dataset计算概率和条件概率.
算法使用互信息作为衡量属性间是否存在依赖关系的标准,但是某一属性和其他属性依赖关系较弱时,它们间的依赖关系对分类结果影响不大,因此又提出了一种改进算法KDB-θ,该算法为类条件互信息I(Xi;Xj|C)设置一个阈值θ,只有条件互信息大于θ时才会添加属性节点之间的弧.因此,可以通过调整阈值θ来控制属性的依赖关系.
2KDB的集成方法
KDB利用条件互信息来表征属性间的依赖关系,条件互信息越大依赖关系越强.我们放松对依赖弧的选择条件,选取符合一定条件的依赖关系来添加相应弧.这样构造出来的KDB分类器虽然分类能力不是最好,但是它能从不同方面反映属性间关系.在此基础上进行分类器集成学习可以有效地提高分类器准确率和泛化能力.
2.1LCKDB算法
下面为放松约束条件的KDB算法(Loosing Constraint k-dependence Bayesian network classifiers,LCKDB).
输入:数据集Dataset={(x1,y1),(x2,y2),…,(xi,yi),…,(xn,yn)},阈值ε;
输出:KDB分类模型.
(1) 计算每个属性和类的互信息I(Xi;C)以及属性间的类条件互信息I(Xi;Xj|C).
(2) 初始化贝叶斯网络结构G,初始化时G中仅有一个类节点C,用S表示添加到G中的属性节点,初始时S置为空.
(3) 重复以下过程至S中包含所有的属性节点.
(a) 选择不在S中并且有最大的I(Xi;C)的属性Xmax,在G上添加一个节点表示Xmax,并添加一条从类节点指向Xmax的弧;
(b) 在S中选择I(Xi;Xj|C)≥ε不同变量Xj,将Xj放入一个集合Xc,选取符合条件的start≤|Xc|,L+start<|Xc|(|Xc|为满足条件属性的个数)的2个属性Xc(start)和Xc(start+L)作为Xmax的父节点,在G上添加从Xc(start)和Xc(start+L)这2个节点指向Xmax的弧(如果Xc中只有一个元素,则增加一条该元素指向Xmax的弧,没有元素就不添加);
(c) 将Xmax添加到S中.
(4) 输出KDB模型G.
在上述算法中,通过参数ε可以对属性间依赖关系存在与否进行控制,如果ε选择过小,就可能使任意2个属性间都存在依赖关系,但是这种依赖关系十分微弱,在KDB结构中添加弧会造成分类精度的下降.如果ε选择过大,可能导致属性间不存在依赖关系,从而退化到朴素贝叶斯分类模型.start和L+start对应的是符合条件属性集合Xc中的2个属性,通过改变start和L的值可以改变一个属性的2个父节点,因此可以构造反映不同依赖关系的KDB分类器.
2.2KDB集成
Boosting算法能够提升不稳定分类器的分类性能,其原因是用于集成的基分类器之间存在差异,这些差异的存在使得最后形成的组合分类器能够综合多个基分类器的优点,具有更高的分类准确性和泛化能力.
LCKDB算法通过调整参数start和L构建的KDB分类器能反映不同的依赖关系.在分类过程中每个KDB分类器的侧重点有所不同,在一些分类器中被错误分类的样本在另一个分类器中就可能被正确分类.为此,可以将这些不同的KDB分类器作为集成基分类器.在原始数据集上用LCKDB方法训练分类器,然后根据其分类结果调整样本分布,将其作为新的数据集训练分类器,最后根据这些分类器的表现,按照加权的方式将其组合起来形成一个强分类器,其具体算法如下.
BLCKBD集成算法(Boosting LCKBD algorithm,BLCKBD)
输入:数据集Dataset={(x1,y1),(x2,y2),…,(xi,yi),…,(xn,yn)},弱分类器数T,阈值ε;
输出:组合分类器H.

2:start←1
3:fort=1:T//构建弱分类器ht
4:ComputeI(Xi;C),I(Xi;Xj|C) //计算互信息和条件互信息
5:G={C},S=φ,L←1//G是贝叶斯网络,S是添加到G的属性节点
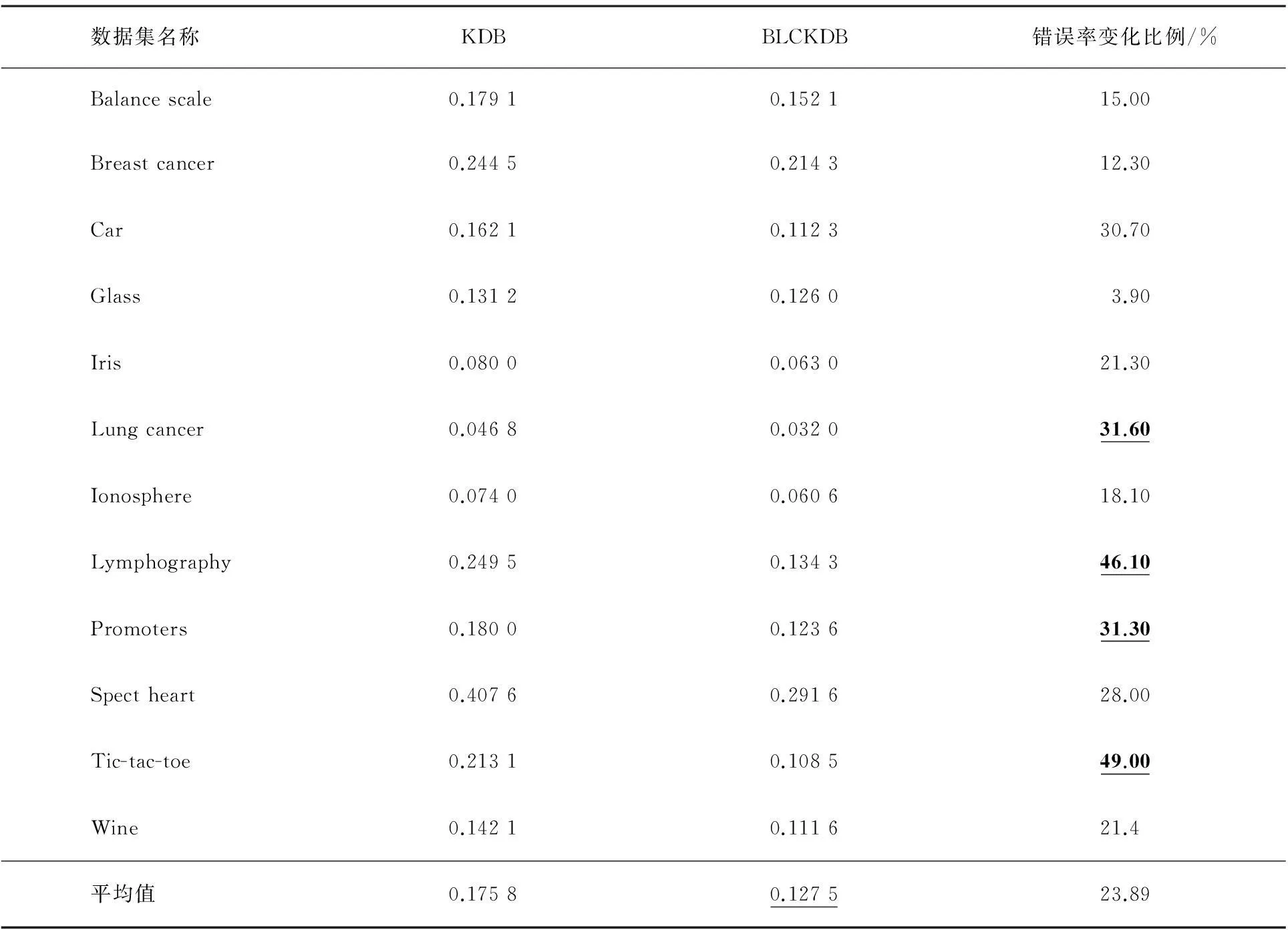
6:while (length(S) 7:ifI(Xmax;Xj|C)≥εthen 8:AddXjtoXc//选取条件互信息大于ε的属性加入集合Xc 9:endif 10:iflength(Xc)<2 11:add an arc fromXctoXmax//在G中添加Xc指向Xmax的弧 12:else 13:if (start+L 14:add two arcs fromXc(start),Xc(start+L) toXmax 15:else 16:choose two attributes fromXcand add corresponding arcs //随机选择Xc中的2个属性并添加指向Xmax的弧 17:endif 18:endif 19:AddXmaxtoS//将Xmax加入S 20:endwhile//结构学习结束 21:returnG//返回贝叶斯网络结构G 22:L←L+1 23:constructhtbasedG//根据G进行参数学习得到分类器ht 24:computeet//计算分类错误率 25:ifet<0.5 26:αt←0.5*log((1-et)/et)//计算第t个分类器权重αt 29:else 30:goto 32 31:endif 32:start←start+1 33:endfor 3实验与分析 从UCI机器学习数据集中选取12个用于实验,数据集信息如表1所示.本文提出的算法是针对离散数据进行分类的,因此需要对连续数据进行离散化处理,对不完整数据集的属性值丢失的样本剔除.所有实验是使用Matlab来实现的,实验中基分类器个数T=20,ε根据实际情况选取0.01~0.03间数值.实验对KDB和BLCKDB算法在分类错误率方面进行比较.对不同的数据集采用十折交叉验证方法来估计分类错误率(见表2). 表1 实验数据集信息 表2 分类错误率的对比 根据表2中的实验数据可以做如下分析: (1) 整体上BLCKDB算法比KDB具有更高的分类准确率.KDB算法的平均分类错误率为17.58%,明显高于BLCKDB的12.75%.这是因为传统的KDB分类器仅仅依靠属性间的强依赖关系进行分类,而BLCKDB算法将反映不同数据信息的KDB分类器通过加权的方式组合起来,从而使最终形成的强分类器能够更好地表达数据间依赖关系. (2) 从分类错误率变化可以看出,对属性较多的数据集BLCKDB方法的错误率下降更多.例如在Lung cancer,Lymphography,Promoters和Tic_tac_toe数据集上分类错误率下降达到30%以上.这是因为属性较多的数据集属性间可供选择依赖关系较多,利用BLCKBD方法构造出来的分类器差异较大,使最终形成的分类器与数据拟合程度更高. (3) 从实验数据可以看出BLCKDB比KDB具有更好的分类性能,这充分说明了利用Boosting技术对存在差异性分类器进行集成能够大幅度地提高其分类准确性和泛化能力. 4结束语 在传统KDB结构学习中,选取与新添加属性节点具有最大条件互信息的k个属性作为该属性节点的父节点,构造出来的KDB具有较好的分类性能,但由于其是稳定分类器,不能使用Boosting技术对其集成.本文提出的BLCKDB算法通过放松选取最大条件互信息的k个属性节点作为其属性父节点的条件限制,选取满足一定条件的k个属性,然后通过调整参数L和start的值来构造不同的KDB分类器,最后使用Booting技术对构造的KDB分类器作为基分类器进行集成,从而形成分类精度更高的组合分类器. 提出的BLCKBD算法的准确性一定程度的受阈值ε影响,因此如何合理选取有效阈值还需要进一步地研究.同时算法需要训练不同的KDB分类器,花费时间较长,因此如何选取合适的训练次数T以达到分类准确性和分类效率的平衡,仍需进一步深入研究. [参考文献] [1]FRIEDMAN N,GEIGER D,GOLDSZMIDT M. Bayesian network classifiers [J]. Machine Learning,1997,29(2/3):131-163. [2]SAHAMI M. Learning limited dependence Bayesian classifiers[C]. //Proceedings of the Second International Conference on Knowledge Discovery and Data Mining,Menlo Park:ACM,1996,335-338. [3]CHENG J,GREINER R. Comparing Bayesian network classifiers[C].// Proceedings of the Fifteenth International Conference on Uncertainty in Artificial Intelligence,Sweden:Stockholm,1999,101-108. [4]石洪波,王志海,黄厚宽,等. 一种基于限定性的双层贝叶斯分类模型[J]. 软件学报,2004,1(2):193-199. [5]秦峰,任诗流,程泽凯,等. 基于属性加权的朴素贝叶斯分类算法[J]. 计算机工程与应用,2008,44(6):107-109. [6]李方,刘琼荪. 基于改进属性加权的朴素贝叶斯分类模型[J]. 计算机工程与应用,2010,46(4):132-133. [7]邓伟斌,王国胤,王燕. 基于Rough Set的加权朴素贝叶斯分类模型[J]. 计算机科学,2007,34(2):204-206. [8]TING K M,ZHENG Z J. Improving the performance of boosting for naive Bayesian classification[C]. //Proceedings of the third Pacific-Asia Conference on Knowledge Discovery and Data Mining,Beijing:Pacific-Asia Conference commitee,1999:296-305. [9]TING K M,ZHENG Z J. A study of adaboost with naïve Bayesian classifier:weakness and improvement [J]. Computational Intelligence,2003,19(2):186-200. [10]石洪波,黄厚宽,王志海. 基于Boosting的TAN组合分类器[J].计算机研究与发展,2004,41(2):340-345. [11]李凯,郝丽锋. 基于Oracle选择的朴素贝叶斯集成算法[J]. 计算机工程,2009,35(5):183-185. [12]张雯,张华祥. 属性加权的朴素贝叶斯集成分类器[J]. 计算机工程与应用,2010,46(29):144-146. [13]曾安,李晓兵,杨海东,等. 基于最小描述长度和K2的贝叶斯网络结构学习算法[J]. 东北师大学报(自然科学版),2014,46(3):53-58. [14]汪春峰,张永红. 基于无约束优化和遗传算法的贝叶斯网络结构学习方法[J].控制与决策,2013,28(4):618-622. [15]JI J Z,HU R B,ZhANG H X,et al. A hybrid method for learning Bayesian networks based on ant colony optimization [J]. Applied Soft Computing,2011,11(4):3373-3384. [16]LARRANAGAA R,KARSHENAS H,BIELZA R,et al. A review on evolutionary algorithms in Bayesian network learning and inference tasks [J]. Information Sciences,2013,233(1):109-125. (责任编辑:石绍庆) Ensemble learning basedk-dependence Bayesian network classifiers ZHANG Jian-fei,LIU Ke-hui,DU Xiao-xin (College of Computer and Control Engineering,Qiqihar University,Qiqihar 161006,China) Abstract:For the performance of traditional KDB (k-dependence Bayesian network classifier) can not be enhanced by singly using Boosting technology,this paper proposed a classifier ensemble algorithm called RLCKDB by loosing the dependent condition of KDB. First it relaxes the he constraints of KDB-choosing the strongest dependences and adjusts the parameter to generate different KDB,then asset these different KDBs through Boosting algorithm to construct the ensemble classifier. Experimental results show that the classification accuracy of BKDB is higher than that of KDB,especially in the dataset with more attributes. Keywords:Bayesian networks;KDB;dependence relationship;Boosting;ensemble learning [中图分类号]TP 181[学科代码]510·80 [文献标志码]A [作者简介]张剑飞(1974—),男,博士,教授,主要从事智能算法研究. [基金项目]黑龙江省自然科学基金资助项目(F201333);教育部人文社会科学研究青年基金项目(14YJC630188). [收稿日期]2014-12-16 [文章编号]1000-1832(2016)01-0065-07 [DOI]10.16163/j.cnki.22-1123/n.2016.01.015

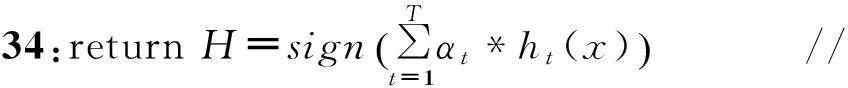

 猜你喜欢
移动通信(2016年22期)2017-03-07商情(2016年46期)2017-03-06现代电子技术(2017年1期)2017-02-16科技资讯(2016年25期)2016-12-27南水北调与水利科技(2016年5期)2016-12-27会计之友(2016年22期)2016-12-17软件导刊(2016年9期)2016-11-07计算技术与自动化(2015年3期)2015-12-31
猜你喜欢
移动通信(2016年22期)2017-03-07商情(2016年46期)2017-03-06现代电子技术(2017年1期)2017-02-16科技资讯(2016年25期)2016-12-27南水北调与水利科技(2016年5期)2016-12-27会计之友(2016年22期)2016-12-17软件导刊(2016年9期)2016-11-07计算技术与自动化(2015年3期)2015-12-31
