
基于MooseFS分布式云存储系统负载均衡方法的研究
2016-04-05 10:02崔海莉黄戈合肥学院信息化建设与管理中心安徽合肥230601
合肥工业大学学报(自然科学版) 2016年1期
崔海莉,黄戈(合肥学院信息化建设与管理中心,安徽合肥 230601)
基于MooseFS分布式云存储系统负载均衡方法的研究
崔海莉,黄戈
(合肥学院信息化建设与管理中心,安徽合肥230601)
摘要:基于MooseFS的分布式云存储系统,在节点间性能差异较大时存在负载不均衡问题,文章提出了一种两级负载均衡的策略,将存储节点分为若干集合,不同集合节点采用优先权值进行调度,同一个集合中节点采用权重轮询均衡算法。实际部署及实验结果表明,该文提出的负载均衡方法在存储结点性能差异较大时,可以很好地实现基于MooseFS分布式云存储系统的负载均衡。
关键词:分布式文件系统;负载均衡;集中式;动态反馈
数据的高可靠性和系统的高访问性是云存储系统的重点。云存储系统一般采用分布式存储技术来管理和存储数据,即数据被拆分成多个相同大小的数据块尽量存储到不同的数据服务器中,分摊节点访问压力[1],避免性能瓶颈以提高系统性能;另外,采用副本机制,数据块有多个副本,用冗余副本保证数据的可靠性。这种分布式的模式对系统的负载均衡提出了要求。
本文针对基于MooseFS分布式文件系统构建的云存储系统,在节点间性能差异较大时存在负载不均衡问题,提出了一种两级负载均衡的策略,在性能差异较大的节点之间做到负载均衡并且能分担中心节点的负载均衡压力,降低中心节点的性能瓶颈。实验验证了该方法的有效性。
1 相关研究
MooseFS(Moose File System,简称MFS)[2]是由Gemius SA开发的一个具有容错、可扩展、兼容POSIX标准和多用途功能的文件系统。它通过分布式技术将数据分散存储在多个不同的物理机器中,但这些对于用户是透明的。
MFS分布式文件系统由“managing server (master server)”、“metadata backup server(s)(metalogger server)”、“mata servers(chunk servers)”、“client computers”组成。系统采用主从式结构,master server主要负责元数据管理,包括“每个文件信息与属性和文件位置(多个)”、存储节点管理、节点负载均衡、数据块副本管理等;数据真正是存储在chunk servers上,并且“在它们之间进行同步(如果某个文件的多个副本存在)”。客户端和“master server通信(接收和修改文件元数据),和chunk servers通信(进行实际的文件数据交换)”。metalogger server作为master server的备份,主要“存储元数据更新日志,并定期下载主要的元数据文件”,用于master server的故障恢复[2]。其逻辑拓扑图如图1所示。除主控点是单点外,其余各点均具备冗余性。
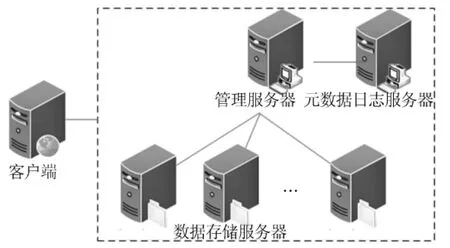
图1 MFS拓扑结构
云存储系统为了提高系统访问性能,避免性能瓶颈,必须确保数据分散存储在各个存储节点,这样才能分摊节点访问压力,从而实现存储空间的负载均衡和网络访问带宽的负载均衡[3]。在数据分布策略上人们提出了一系列的经典算法,如早期的LH*[4]、一致性哈希[5]等经典算法。随着技术的发展,在Dynamo[6]、Lustre[7]、GPFS[8]等系统中,根据不同的应用需求又有不同的数据分布解决方案。
虽然目前开始出现一些分布式文件系统如IBM的GPFS[9],利用文件分块技术对文件的元数据进行分布式管理,但大多数分布式文件系统(Google的GFS[10]、Hadoop的HDFS[11]、MooseFS 的MFS[2])仍采用中心节点来担当负载均衡节点,例如MFS中的master节点,它主要用来维护文件块被分配到chunkservers的位置。
负载均衡的实现方法主要分静态负载均衡和动态负载均衡。静态方法的均衡策略是事先制定好的、固定的,对于构成复杂的云存储系统来说,不能适应随时变化的节点的负载状况,负载均衡效果并不好。动态方法则是实时收集、存储和分析系统的当前状况,在各节点间有目的地、动态调度任务。动态方法的负载均衡效果显然比静态要好,但是不可避免地会增加额外开销[12]。
云存储系统中,每个存储节点都有性能监测模块收集诸如磁盘剩余空间、网络带宽利用率、CPU利用率等状态信息。在动态负载均衡算法中,这些信息实时地向负载均衡节点反馈,负载均衡节点再根据请求任务的需求在各存储节点间分配。分配的策略主要是依据云存储系统应用环境的类型,比如计算任务大的,分配依据就偏重于CPU利用率;读写任务大的,分配依据就偏重于读写次数。集中式动态负载均衡一般是在节点的初始集群生成后,负载均衡节点依据制定的选择策略,根据所提出的目标函数,首先获取当前集群中各节点的目标值,然后依据该目标值进行评价,计算相对应的评价值,以确定选择该节点的概率[13-16]。这些必然会增加负载均衡节点的额外开销,所以还要考虑由负载均衡策略带来的这些额外开销和增加的系统性能之间的平衡。
MFS分布式文件系统采用集中式动态负载均衡算法,由master担任负载均衡节点角色。
2 MFS负载均衡策略
MFS中采用拆分技术,大文件被拆分成每份大小不超过64 M的chunk进行存储;小于64 M的文件,该chunk的大小即为该文件大小。
当有数据存储请求时,由master负责选出当前可用的chunkserver。MFS对chunkserver可用性的解释为:每个chunkserver的磁盘都要为增长中的chunks保留一些磁盘空间以满足创建新的chunk的需求。MFS要求的这一值为1 GB。然后根据评价策略,在可用chunkserver的集合中计算出每个chunkserver的评价指标值,将这些评价值从大到小做快速排序,优先选择评价值最大的chunkserver。显然如何选择用于存储数据的chunkserver在一定程度上影响了系统负载的均衡。
当有数据访问请求时,master根据元数据信息找到文件对应数据块所在的chunkserver,并向MFS client返回。client收到master传递过来副本所在chunkserver的ip和port时,选择当时正在读写次数少的chunkserver作为访问对象。
chunkserver的评价指标是MFS中数据分布算法的核心。MFS中chunkserver的负载均衡部分在文件matocsserv.c中实现。在服务开启时,先通过函数rndu32()为每个chunkserver随机产生一个评价指标值carry:
eptr→carry=(double)(rndu32())/(double)(0xFFFFFFFFU)。
而carry的修正量是用当前chunkserver的总空间(totalspace)和系统中最大的chunkserver总空间(maxtotalspace)的比值产生的:
servtab[allcnt].W=(double)eptr→totalspace/(double)maxtotalspace。
由修正量的迭代累加得到评价指标:
carry=servtab[i].carry+servtab[i].W。
从上面的分析可以看出决定chunkserver选择的评价指标值与该chunkserver的totalspace有关。在chunkserver的总空间(totalspace)差别不大的情况下,chunk基本上可以均衡地分布到各个chunkserver上。在4.1节的性能测试中有数据证明了chunkserver配置相同时chunk的均衡分布。
如果chunkserver的总空间(totalspace)差别较大,上述算法容易导致在有存储请求时存储空间越大的chunkserver,chunk的分布就越多,访问压力越大。各chunkserver之间的访问压力不均衡,机器之间无法达到更好的网络带宽使用率,最终会影响系统的整体性能。而有访问请求时读写次数也不能真实反映服务节点的负载情况,这有可能是因为节点的外在性能不好而无法接受新的任务导致的。这种任务调度策略在节点外在性能差异较大的情况下,也不能做到负载均衡。
3 改进的MFS负载均衡策略及算法
基于MFS原有的集中式管理,改进的策略中充分考虑导致存储节点性能差异的因素和节点负载状况,由此增加的额外开销采用分摊的方式分散到各存储节点,即采用各存储节点自适应收集信息,根据自身状态反馈给中心节点的分步式主动反馈替代原来由中心节点主动收集的集中式反馈,同时尽量减小负载均衡算法的复杂度。
3.1改进的负载均衡策略
影响chunkserver性能的因素很多,chunkserver选择的基本依据是计算能力强、存储容量大、带宽充足等这类资源充足的节点。首先分析所有存储节点的负载权重状况,依据各存储节点的负载状况监测模块监测到的节点计算资源、存储资源和网络资源等状态信息可以设计存储服务器的负载评价函数,由负载评价函数得到的负载值将服务器划分成3个集合:轻载集合、适载集合和重载集合。
定义1 C代表chunkserver,那么Ci就是第i 个chunkserver,第i个chunkserver可用必须同时满足条件:①Ci是存活状态;②Ci剩余可用空间大于一个设定的值,在MFS中该值为1 G。
按定义1,对可用节点服务器负载信息采用资源消耗模型,这里主要考虑CPU利用率、内存使用率、网络带宽利用率等因素。可用存储节点Ci在某一时刻负载评价函数如下:
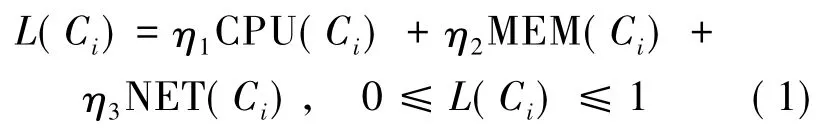
这里设计可用存储节点Ci的负载主要包含3项指标:CPU(Ci)为CPU利用率,MEM(Ci)为内存利用率,NET(Ci)为网络带宽利用率,ηi为3项负载指标的加权系数,η1+η2+η3=1,ηi的取值取决于CPU、内存和网络带宽利用率对负载变量L(Ci)的影响程度,依据系统的服务不同,各权值的影响也各不相同,可以根据系统实际测试进行设置,以期达到最佳状态。
在负载指标收集过程中,由于多种因素的影响会出现某项指标值的暂时波动从而导致负载评价函数曲线的扰动。为了降低因这种波动而导致服务器集合划分时出现误差的可能性,这里引入降扰修正函数:
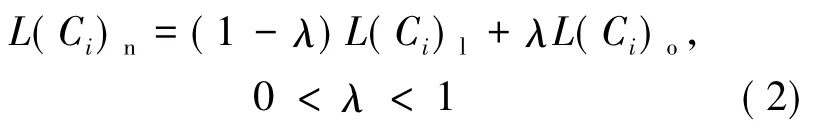
其中,L(Ci)n为经修正计算过的负载值;L(Ci)l为前一次采集后进行修正的负载值;L(Ci)o为当前采集的负载值;λ为修正因子。修正因子的取值依据其对负载曲线的影响程度,在系统实际测试中进行设置,选取负载曲线较为平滑时的值,这样有利于后续划分服务器集合策略的准确性,而使得服务器的负载信息数据的采集不容易受到非正常扰动的影响。
依据L(Ci)将整个负载状况分成3个集合,区间划分为(0,θ1]、(θ1,θ2]、(θ2,1],其中θ1、θ2为负载轻重阈值(0<θ1<θ2<1)。据此划分,主控服务器节点管理模块把存储节点分成3类,分别存放在SCH、SCM、SCL3个集合中。其中,SCH、SCM、SCL分别表示重载、适载、轻载的存储节点集合。集合中保存了所有可用存储服务器节点的信息。分布式主动反馈中,各存储节点每隔一段时间,根据负载评价函数的影响因素计算出自己的负载值L(Ci),只在当某存储节点的负载L(Ci)发生较大变化,从一个集合跳至另一集合时,才向主节点反馈信息,这样可以降低存储节点周期性反馈所占用的网络开销,也不影响该节点的负载状况在主节点的及时更新。主节点根据存储节点的反馈信息对节点进行出队、入队等操作。
集合内采用加权轮询调度算法选择可直接存储数据的chunkserver。针对原chunkserver选择算法中仅考虑总存储空间这一单一因素,充分考虑各个节点自身能力的大小,进行合理选择,尽可能使chunk块平均地分布到各chunkserver上。设Ci的调度评价值为carryi。
定义2第i个chunkserver可直接存储数据必须同时满足条件:①可用chunkserver的定义;②Ci的评价指标值不小于1,即carryi≥1。
存储节点的调度思想是资源充足、负载低的节点优先被选择。根据负载评价函数划分出集合后,对于同一集合内的存储节点负载状况在同一区间,差别不大,这时的主要选择依据为节点自身的资源使用状况。对存储容量来说,容量大的节点有优势,但是还要看容量使用情况,只要存储空间使用率不超过某一阈值,也应该有被调度的机会。这样对各节点的存储空间利用相对平均,保证数据有目的地均衡分散到系统各节点,而不仅仅集中于空间容量大的节点。
按定义2,设可直接存储数据的节点总存储空间为Ti,该系统中所有节点总存储空间最大的存储空间为Tmax,节点已使用空间为Ui。
根据第2节的分析,为避免在chunkserver总空间差别较大时出现chunk分布不均的问题,可以加入存储空间使用率因素来加以控制。修改原算法中carry的修正量W为:
servtab[allcnt].W=(maxtotalspace-eptr→usedspace)/eptr→maxtotalspace
进一步,单纯考虑存储空间使用率虽然可以避免上述可能出现的问题,但是这样又会使得原存储空间优势较大的节点没有充分发挥其性能,因此引入存储空间容量权重因素,节点的评价指标值carry的修正值W为:其中,Wt为节点总存储空间权重;Wu为已使用空间权重;Wt+Wu=1;μ为存储空间使用率阈值。
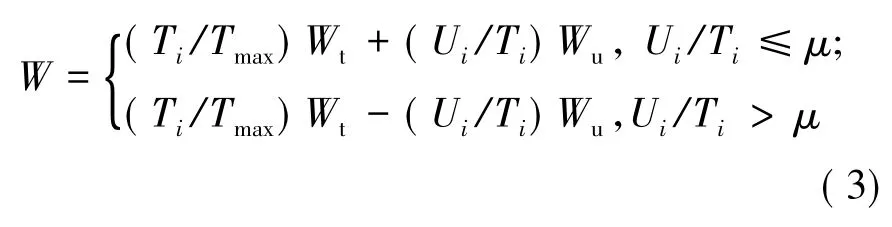
3.2算法设计
当有访问任务请求到达时,在主控服务器节点管理模块的可用存储服务器节点集合中,优先选择轻载集合SCL,若SCL∉Ø,选取该集合中的存储节点加入备选节点集合S;否则选择适载集合SCM,若SCM∉Ø,选取该集合中的节点加入备选节点集合S;否则选择重载集合SCH,若SCH∉Ø,选取该集合中的节点加入备选节点集合S;否则返回失败(无可用节点)。
系统在集合内选择的算法流程如下:
(1)服务开启时,每个chunkserver随机产生一个评价指标值carry。
(2)master获取备选集合S内各存储节点的carry值。此时,各节点的carry=carry+W,对其按从大到小进行快速排序,其中W为按(3)式得出的carry的修正值。
(3)如果此时最大的carry值大于1且同时拥有该值的chunkserver剩余的空间大于1 G,即满足定义2,为可直接存储节点,则选择该值对应的chunkserver,之后修正该节点的评价指标值carry=carry-1。
(4)如果carry最大值小于1,则每一个节点的carry值均加上W。之后重新排序回到步骤(2)进行选择,直到选到1台chunkserver的carry值大于1为止,然后重复步骤(3)。
4 实验结果及分析
4.1MooseFS集群性能测试及分析
实验环境采用MooseFS 1.6.27版本软件,集群服务器为6台物理机:1台MFS元数据服务器(Master),IP为192.168.20.41,2.0 GHz双核CPU,32 G内存;5台MFS数据存储服务器(ChunkServer),IP为192.168.20.42~46,2.4 GHz单核CPU,16 G内存;其中IP为192.168.20.42也作为元数据日志服务器(Metalogger)。每台服务器各自挂载28 T存储空间,服务器操作系统采用符合POSIX规范的CentOS6.5。为保证数据传输,所有服务器均配置千兆全双工网卡,之间通过1台千兆交换机互连。MFS将多台存储服务器的硬盘空间在逻辑上虚拟成一个大容量存储池,为业务系统提供存储服务。MFS client能通过Linux内核FUSE模块将MFS所构建的大容量存储池挂载到本地文件系统中使用。云存储系统建成,获得136 T的可用空间。图2所示为系统在有持续读写时各存储节点磁盘运行状态的基本信息,可以看出采用MFS选择算法在各节点存储空间差别不大的情况下chunk均衡分布。

图2 MooseFS集群的磁盘运行状态
4.2改进算法测试与分析
在当前实验环境下,为测试改进算法负载均衡效果,调整其中1台存储节点chunkserver 4的配置,改变MFS挂载分区的大小为2 T,其他配置相同。在4.1节介绍的实验环境中,各节点外部性能差异不大,集合之间的加权因素无法充分体现,因此本次测试的主要目的为:①观察改进的算法在集合内chunkserver容量不均的情况下数据分布状况;②观察存储节点动态管理策略对主服务器流量的影响。
在3.1节提出的改进算法中修改了MFS原 chunkserver选择算法中仅考虑总存储空间这一单一因素,引入存储空间容量权重因素。因此此次实验从3个方面对比chunk的分布情况:①存储节点的评价指标为节点总存储空间大小;②存储节点的评价指标为节点存储空间使用率;③存储节点的评价指标引入存储空间容量权重因素。测试前将chunkserver 4调整挂载分区大小后各chunkserver的初始状态见表1所列。
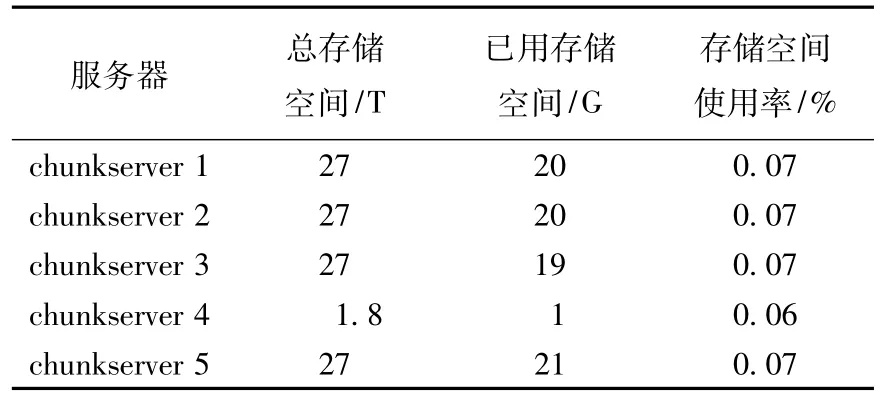
表1 各chunkserver初始条件
使用MFS提供的mfssetgoal命令,该命令的作用是设置文件副本数。在这里设置goal为2,即每份数据存储2份副本。对算法中涉及的参数做如下设置:Wt节点总存储空间权重设为0.6,Wu已使用空间权重设为0.4,存储空间使用率的阈值μ设为0.5。用dd命令,goal=2,bs=2 M,count=5 000多次写入10 G文件,观察数据块在存储节点上的分布情况,测试结果见表2所列。

表2 3种算法chunkserver存储空间使用情况
实验对原算法、考虑存储空间利用率和考虑存储容量权重3种集合内选择算法分别做3次数据写入测试。为方便说明,先根据节点性能把chunkserver 1、2、3、5称为第1组节点,chunkserver 4称为第2组节点。在进行完3轮数据存储后,评价指标为节点总存储空间大小时第1组节点平均空间使用率为0.126 8%,第2组为0.111 1%;评价指标为存储空间使用率时,第1组节点平均空间使用率为0.125 9%,第2组为0.111 1%;引入存储空间权重因素后,第1组节点平均空间使用率为0.128 7%,第2组为0.111 1%。
原算法中只考虑存储服务器的总存储空间,在节点总存储空间差异较大时,数据分布选择总存储空间大的节点的概率很高。修改为存储空间使用率因素后,由于本实验环境中节点之间的空间差异没有梯度化,2组节点空间差异较大,所以算法优化后存储空间利用率变化没有呈现梯度化的差异,但是仍可明显看出第1组性能好的节点空间使用率有所下降,相对来说第2组节点空间使用率则没有发生变化。引入容量权重因素后,因为系统中存储的测试数据量相对节点总存储空间来说,各节点存储空间使用率远远小于设置的阈值,在这种情况下,性能好的节点权重修正量W远远大于性能差的节点(按本次实验所取参数,第1组节点的权重修正量为0.6,第2组为0.04),所以此时第1组节点的空间使用率又有所上升。引入容量权重因素可以使chunk的分布更加合理,而且权重因子可以根据实际应用环境,选择更加合理的值,以使整个系统负载更加均衡。
采用两级负载策略,存储服务器根据自身状态和设置的阈值,分步式主动反馈给中心节点负载状况,分流了计算任务,避免因算法中考虑因素增多而加重中心节点的负担,图3所示为在测试期间监控到的主节点的数据流量分布,3段峰值分别对应原算法、考虑存储空间使用率和考虑存储空间容量权重算法时的流量,可以看出主节点的流量负担并没有加重。
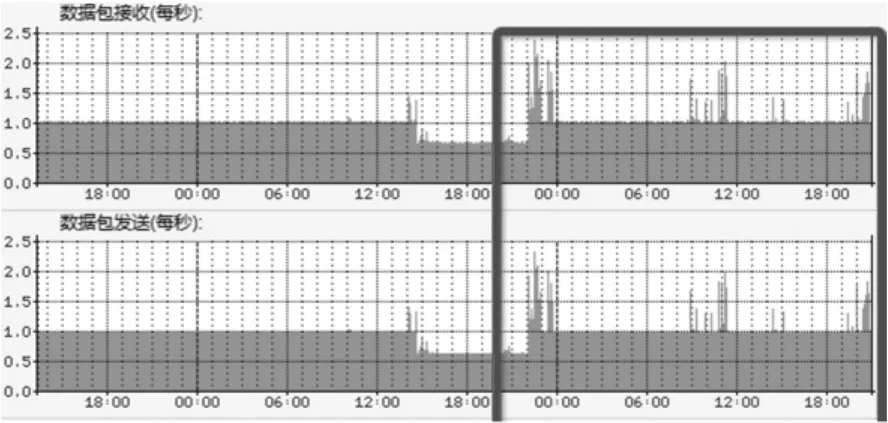
图3 3种算法主节点流量分布图
5 结束语
本文对现有MFS负载均衡算法的核心进行分析,指出在集群性能差异较大的情况下考虑因素单一、负载均衡效果不明显的缺陷,提出按节点负载权重状况划分集合,集合之间采用优先权法,根据优先值选择集合;集合内采用权重轮询均衡算法,充分考虑各个节点自身能力的大小,进行合理选择。实验验证了该算法的有效性。
[参考文献]
[1]Rabinovich M,Rabinovich I,Rajaraman R,et al.A dynamic object replication and migration protocol for an Internet hosting service[C]//Proc of the 19th IEEE International Conference on Distributed Computing Systems,1999:101-113.
[2]MooseFS Team.MooseFS[EB/OL].[2005-09-12].http://www.moosefs.org/about-mfs.html.
[3]Zeng Wenying,Zhao Yuelong,Ou Kairi,et al.Research on cloud storage architecture and key technologies[C]//ICIS ' 09:Proceedings of the 2nd International Conference on Interaction Sciences:Information Technology,Culture and Human.New York:ACM,2009:1044-1048.
[4]Litwin W,Neimat M-A,Schneider D A.L H*:a scalable,distributed data structure[J].ACM Transactions on Database Systems,1996,21(4):480-525.
[5]Lewin D.Consistent hashing and random trees:algorithms for caching in distributed networks[D].Cambridge,Massachusetts:Massachusetts Institute of Technology,Department of E-lectrical Engineering and Computer Science,1998.
[6]Decandia G,Hastorun D,Jampani M,et al.Dynamo:Amazon’s highly available key-value store[C]//SOSP’07:Proceedings of the 21st ACM Symposium on Operating Systems Principles.New York:ACM,2007:205-220.
[7]Oracle Corp.Lustre file system[EB/OL].(2011-06-12).http://wiki.lustre.Org/index.php/Main-Page.
[8]Schmuck F,Haskin R.GPFS:a shared-disk file system for large computing clusters[C]//FAST’02:Proceedings of the 1st USENIX Conference on File and Storage Technologies.Berkeley,CA:USENIX,2002:231-244.
[9]Hsiao H,Chung H,Shen H,et al.Load rebalancing for distributed file systems in clouds[J].Applied Soft Computing,2012,21:102-105.
[10]Ghemawat S,Gobiof H,Leung S T.The Google file system [J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43.
[11]Shvachko K,Kuang Hairong,Radia S,et al.The Hadoop Distributed File System[C]//Proc of the 26th IEEE Symposium on Mass Storage Systems and Technologies,2010:1-10.
[12]陈亮.集群负载均衡关键技术研究[D].长沙:中南大学,2009.
[13]薛伟.分布式文件系统关键技术研究与实现[D].合肥:中国科学技术大学,2011.
[14]刘玉艳,沈明玉.一种LVS负载均衡调度算法WLC的改进[J].制造业自动化,2010,32(9):187-191.
[15]刘玉艳,沈明玉.LVS负载均衡技术在网络服务中的应用[J].合肥工业大学学报:自然科学版,2007,30(12):1592-1595.
[16]王命全.网格环境中基于负载均衡的工作流调度算法[J].计算机应用,2010,30(12):3184-3186.
(责任编辑张镅)
Research on load balancing method for distributed cloud storage system based on MooseFS
CUI Hai-li,HUANG Ge
(Center of Information Development and Management,Hefei University,Hefei 230601,China)
Abstract:In the distributed cloud storage system based on MooseFS,there is load imbalance problem due to the large difference in performance between nodes.In this paper,a two-stage load balancing strategy is proposed,in which the storage nodes are divided into several sets,and different sets of nodes are scheduled by using priority values and the same sets of nodes using weights polling algorithm.The application and experimental results show that in the case of large difference in performance between nodes,the proposed load balancing method can be very good for achieving the load balance of the distributed cloud storage system based on MooseFS.
Key words:distributed file system;load balancing;centralization;dynamic feedback
作者简介:崔海莉(1970-),女,安徽铜陵人,合肥学院讲师.
基金项目:安徽省2014年度省级质量工程教学研究资助项目(2014jyxm319)
收稿日期:2015-09-16;修回日期:2015-10-29
Doi:10.3969/j.issn.1003-5060.2016.01.014
中图分类号:TP393
文献标识码:A
文章编号:1003-5060(2016)01-0073-06
猜你喜欢
能源(2018年8期)2018-09-21
软件导刊(2016年12期)2017-01-21
软件导刊(2016年12期)2017-01-21
计算技术与自动化(2016年4期)2017-01-11
企业技术开发·中旬刊(2016年10期)2016-11-12
河南水利年鉴(2016年0期)2016-08-03
现代工业经济和信息化(2016年4期)2016-05-17
电气化铁道(2016年5期)2016-04-16
工业设计(2016年10期)2016-04-16
科技视界(2016年3期)2016-02-26
