
采用改进最长公共子序列的人名消歧
2016-04-05 08:20:49林翠萍吴扬扬
华侨大学学报(自然科学版) 2016年2期
林翠萍, 吴扬扬
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)
采用改进最长公共子序列的人名消歧
林翠萍, 吴扬扬
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)
摘要:将名词、形容词、动名词和命名实体作为文本特征,考虑词序与词频,结合特征项的语义,提出一种基于改进最长公共子序列的文本聚类(LCSC)方法.实验结果表明:相对于传统的余弦值聚类方法,LCSC方法在人名消歧的P-IP指标上,F平均值由74.2%提高到了84.9%;相对于最长公共子序列方法,总体性能也提高了3.7%.
关键词:人名消歧; 文本相似度; 最长公共子序列; 层次聚类
据统计,在Google或Yahoo上搜索人名的量达到了30%[1],作为互联网检索的一个子任务,人名搜索返回结果往往是相关重名人的网页.目前人名消歧的主流方法是基于向量空间模型的聚类方法,该方法的研究主要集中在特征提取和表示.Bagga等[2]用向量空间模型解决跨文档人名的共指消解问题.Mann等[3]自动提取了出生地、出生年月、职务等的人物传记信息,构成丰富的特征空间.Pedersen等[4]抓住文档中的共现词,以前词为行、后词为列的矩阵经过奇异值分解后得到表示文档的特征.Chen等[5]把特征系统地划分为基于名词和基于命名实体的特征,用SoftTFIDF计算特征权重,最后进行层次聚类.Ikeda等[6]在以人名实体、混合关键词和网络链接为特征的基础上,提出两阶段聚类方法.在中文人名消歧方面,Yang等[7]把特征分为命名实体特征和普通词特征,通过引入同义词词林和词语相似度来降低数据的稀疏性.一方面,传统的向量空间模型[8]把特征词或短语组成一个集合;另一方面,特征空间的稀疏性将会限制文本相似度计算的精度.针对上述问题,本文提出了一种改进最长公共子序列的聚类方法(longest common subsequence clustering,LCSC).
1相关工作
1.1知网词语相似度
知网是一个网状知识库,描述了概念与概念之间的关系[9].每一个词汇可以有多个概念,每一个概念都用一系列的义原来描述.这些义原用树状结构组织起来,义原根据义原之间的属性关系分为多棵义原树,这些存在一定关系的义原树就形成了网状知识结构.刘群等[10]提出了一种计算语义相似度的方法,该方法实际上是获取两个词汇的最大概念相似度.特征项w1有m个概念:s1,1,s1,2,…,s1,m,特征项w2有n个概念:s2,1,s2,2,…,s2,n,则w1和w2的语义相似度为
(1)
文献[10]对实词概念语义的表达式分成了4个部分:第一独立义原描述式,记为sim1(s1,s2);其他独立义原描述式,记为sim2(s1,s2);关系义原描述式,记为sim3(s1,s2),符号义原描述式,记为sim4(s1,s2).因此,两个概念的语义表达式的整体相似度记为
(2)
式(2)中:βi(1≤i≤4)是可调节的参数,且满足b1+b2+b3+b4=1,β1≥β2≥β3≥β4.
1.2最长公共子序列算法描述
最长公共子序列(longestcommonsubsequence,LCS)最初是Wagner等[11]在1974年提出来的,即一个数列S,如果分别是两个或多个已知数列的子序列,且是所有符合此条件序列中最长的,则S称为已知序列的最长公共子序列.
Hirschberg[12]用动态规划有效地解决了此问题.假设有两个字符串X,Y,其分别表示为X={a0,a1,…,am-1}和Y={b0,b1,…,bn-1}. 用一个二维矩阵Cm×n存储迭代过程中当前的最长公共子序列长度. 其中:c[i][j]记录a0到ai和b0到bj的最长公共子序列的长度,即原始问题的一个子问题的解.当i=0或j=0时,空序列是ai和bj的最长公共子序列,故c[i][j]=0.其他情况下,结合语义相似度可建立递归关系为
(3)
2LCSC方法
从计算机角度看,人名消歧是将多个重名人的文档集合划分为若干个子集合,即给定包含同一人名n的文档集合D,背景知识K,求D的划分 p={D1,D2,…,Dm},并使划分中一个子集合对应一个人物ρi(1≤i≤m).人名消歧步骤,如图1所示.
2.1文本预处理及特征表示
假设一个人物实体对应一篇文档,先对每篇文档进行分词、词性标注、命名实体识别,并去除不相关文档.文中所采用的分词器是孙健开发的Ansj(http://www.ansj.org/),以人民日报1998年1月的语料库为测试的结果准确率高达98%,召回率为96%,被广泛运用于自然语言处理中的命名实体识别、多级词性标注、关键词提取等.
特征提取的目的是降维,并得到有区分度的特征词.对于人名消歧而言,其作用可归纳为:找到能区分不同人物的重要词,即对相似度计算重要的词.在文本相似度计算上,以最长公共子序列为依据;在特征提取上,需要尽可能保留较全面的文本信息.因此,文中依次抽取文中出现的名词(n)、形容词(a)、动名词(vn)和命名实体(nr,ns,nt),按其在原文的顺序组成一个有序的词语序列表示文本,即d={w1,w2,…,wn},其中,wi即为所抽取的特征项.
采用经典的TFIDF(termfrequency,inversedocumentfrequency)方法来计算特征权重.其核心思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力[13].加权函数为词频乘以反文档频率,即
(4)
式(4)中:TF即为词频,指特征i在文档k中出现的频率;IDF为反文档频率;N为所有类别中的文档的总数;nk为包含特征i的文档数.
利用词语分类的重要程度为后续的文本相似度服务,并非要利用TFIDF进行特征的选择.
2.2改进最长公共子序列的文本相似度
为了充分利用文本自身的词序和词频信息,提出一种基于最长公共子序列的文本相似度计算方法.
2.2.1词语相似度为了弥补向量空间模型中特征项相互独立正交的缺陷,文中借助知网(Hownet)的词汇描述方式,根据文献[10]的语义相似度,建立特征项相似度矩阵.二维矩阵SL(A),L(B)用于存储特征项之间的相似度.特征项ai和bj若是完全匹配,它们的词语相似度sim[i][j]将被置为1.0;否则,根据知网词语相似度计算方法返回相应的值.
2.2.2结合语义知识的LCS算法文本去除停用词以后,抽取其中的名词、形容词、动名词和命名实体组成一个有序的特征词语序列.当结合语序考虑文档相似度时,与经典的最长公共子序列的问题极为类似.设文档A和文档B的特征项序列分别表示为a1,a2,…,am和b1,b2,…,bn.用一个二维矩阵C(m+1)(n+1)存储当前的最长公共特征子序列长度.其中:c[i][j]记录a1到ai和b1到bj的最长公共特征子序列的长度.
考虑表达的多样性,将原始的LCS算法结合词语之间的语义信息,即添加特征项相似度,提出一种结合语义的LCS算法,即

(5)
式(5)中:sim[i-1][j-1]是A文档特征序列中第i个特征项和B文档序列中第j个特征项的相似度,若两个特征项的相似度超过了一个阈值ε,认为它们是匹配的,最长公共特征子序列长度动态增加一个单位.
2.2.3基于LCS的文本相似度自Hirschberg[14]提出基于LCS的文本相似度方法之后,不少研究人员在此基础上提出改进并优化.比较常见到的计算方法有文献[15]提到的LCS与较长的文本长度的比值,即
(6)
2倍的LCS[16]除以两文本的长度之和,即
(7)
式(7)中:LCSL(A,B)为文档和文档的最长公共特征子序列长度;L(A),L(B)分别为文档A和文档B的特征向量的长度.
对于两篇描述同一人物的长文本和短文本来说,如果采用文献[15]的方法计算文本相似度,将会得到较小的值.通过加入特征项的权重,提高文本相似度的精度.改进的文本相似度为
(8)
(9)
式(9)中:wi,k,wj,k分别是两篇文档的最长公共特征子序列中对应特征项的权重,包括了两个特征序列中的完全匹配特征项和不完全匹配特征项;δ是一个平衡参数.由于文档特征向量普遍较长,而最长公共特征子序列的长度则较小,所以加入Tk进行适当调节.只有当两个对应特征的权重都超过δ时,Tk才增加1个单位.因此,该方法不仅考虑到了词序与词频,而且在LCS算法中结合了特征项之间的语义相关度,最终达到提高具有相同含义但使用不同词汇的文本相似度的目的.
2.3聚类算法
对于人名消歧,由于重名者个数的不确定性,采用层次聚类算法比较合适.文中采用自底向上的单链的层次聚类算法.
3评价指标
实验选用CIPS-SIGHAN提供的两种人名消歧评价方法:P-IP和B-Cubed指标.两种方法分别计算了聚类结果的正确率,召回率和F值.P-IP指标为
(10)
(11)
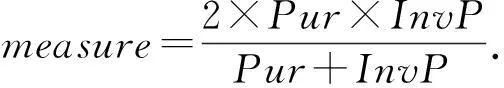
(12)
B-cubed指标的公式为
(13)
(14)
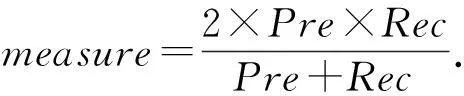
(15)
式(13)~(15)中:S={S1,S2,…}是系统输出的聚类结果;R={R1,R2,…}是人工标注的聚类结果.
通常情况下,为了验证人名消歧系统的整体性能,取各个人名消歧效果的平均表现,即
(16)
(17)
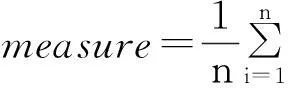
(18)
4实验结果与分析
为了检验文中提出方法的有效性,进行了对比实验,将提出的LCSC方法与Baseline、LCS及文献[17]中的AE方法进行对比.其中:Baseline是传统的基于向量空间模型的聚类方法,以全文除停用词外的所有词为文本特征,采用TFIDF为特征权重计算公式,以特征向量的夹角余弦值作为文本相似度,再进行单链层次聚类.LCS方法中LCS和文本相似度分别采用式(3),(7)计算.文献[17]中的AE方法通过抽取人物属性信息作为特征来进行人名消歧.
4.1数据集
采用的数据集是搜狗全网新闻人名消歧语料[17],该语料选取了国内最常用的50个人名,抽取含有这50个人名串的新闻报道.对其中新闻报道最多的12个人名的总共11 876篇文档进行了人工标注.
4.2实验结果分析
通过对搜狗全网人名消歧语料中12个人名进行实验,结果表明:提出的基于改进的LCS的文本相似度的聚类算法在两个评测指标上都表现出了良好的效果.P-IP的F值对比,如图2所示.B-Cubed的F值对比,如图3所示.
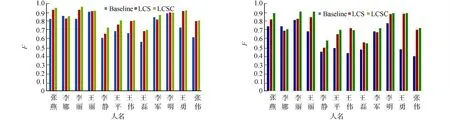
图2 P-IP的F值对比 图3 B-Cubed的F值对比 Fig.2 Comparison of P-IP F-measure Fig.3 Comparison of B-Cubed F-measure
图2,3结果表明:除“李娜”以外的其他人名,LCS方法和文中提出的LCSC方法的F值都比Baseline有所提高.
在进行LCSC方法的实验过程中需要调节3个参数,分别是聚类停止阈值l,式(5)的词语相似度阈值ε及式(9)计算文本相似度时的权重平衡参数δ.结合多个重名人的实验结果,l在0.25左右取得总体较高的F值.在l保持一定的情况下,分别对ε和δ进行控制变量法获取最优值.
“张伟”的聚类阈值4在调整过程中对结果的影响,如图4所示.由图4可知:ε和δ的最优值分别为0.9和0.01.12个人的平均F值的对比,如图5所示.由图5可知:P-IP的F值从Baseline的74.2%提高到84.9%;B-Cubed的F值从55.0%提高到75.7%.与LCS相比,LCSC方法也分别高出3.7%和3.5%;与AE方法相比,文中方法在P-IP指标上体现出一定的优势.可见,加入了特征项的权重信息对文本相似度计算起到了一定的作用,使得LCSC方法体现出了较好的性能,与人物属性抽取方法比较也略胜一筹.
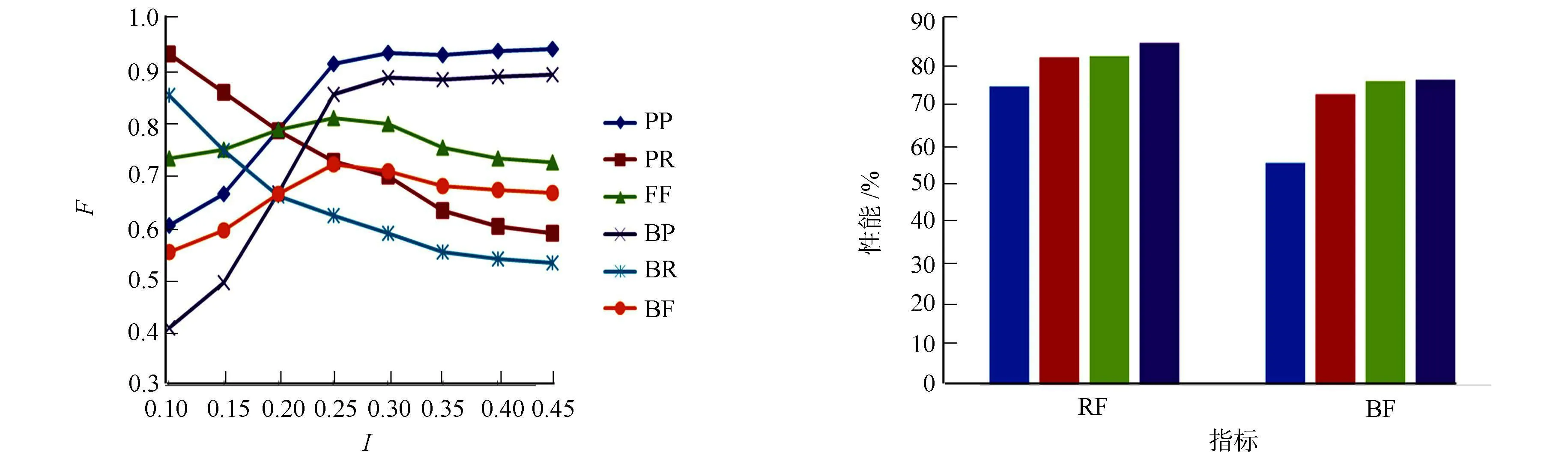
图4 “张伟”的聚类阈值对结果的影响 图5 12个人的平均F值的对比 Fig.4 Effect of Zhang wei′s clusterin Fig.5 Comparison of average F-measure threshold to result for 12 persons
5结束语
通过引入知网的词语相似度计算,弥补了向量空间中特征项之间相互独立的缺陷.在最长公共子序列的计算中加入了权重的平衡参数,避免了传统余弦相似度导致的特征稀疏性,从而提高了文本相似度计算的准确率.针对LCSC方法的不足,后续工作将从预处理和语义分析两方面入手.此外,提取与LCSC方法结合的文本特征,也是需要进一步深入的问题.
参考文献:
[1]ARTILES J,GONZALO J,VERDEJO F.A testbed for people searching strategies in the WWW[C]∥Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Piscataway:ACM,2005:569-570.
[2]BAGGA A,BALDWIN B.Entity-based cross-document coreferencing using the vector space model[C]∥Proceedings of the 17th International Conference on Computational Linguistics.Boston:Association for Computational Linguistics,1998:79-85.
[3]MANN G S,YAROWSKY D.Unsupervised personal name disambiguation[C]∥Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL.Edmonton:Association for Computational Linguistics,2003:33-40.
[4]PEDERSEN T,PURANDARE A,KULKARNI A.Name discrimination by clustering similar contexts[C]∥Computational Linguistics and Intelligent Text Processing.Berlin:Springer Berlin Heidelberg,2005:226-237.
[5]CHEN Y,MARTUB J.Towards robust unsupervised personal name disambiguation[C]∥EMNLP-CoNLL.Washington D C:IEEE Press,2007:190-198.
[6]IKEDA M,ONO S,SATO I,et al.Person name disambiguation on the web by two-stage clustering[C]∥2nd Web People Search Evaluation Workshop.New York:Association for Computing Machinery,2009:33-38.
[7]YANG Xia, JIN Peng, XIANG Wei.Exploring word similarity to improve Chinese personal name disambiguation[C]∥Web Intelligence and Intelligent Agent Technology.Washington D C:IEEE Press,2011:197-200.
[8]SALTON G,WONG A,YANG C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[9]董振东,董强.知网简介[EB/OL][2014-03-16].http://www.keenage.com.
[10]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
[11]WAGNER R A,FISCHER M J.The string-to-string correction problem[J].Journal of the ACM (JACM),1974,21(1):168-173.
[12]HIRSCHBERG D S.A linear space algorithm for computing maximal common subsequences[J].Communications of the ACM,1975,18(6):341-343.
[13]施聪莺,徐朝军,杨晓江.TFIDF 算法研究综述[J].计算机应用,2009,29(B6):167-170.
[14]HIRSCHDERG D S.Algorithms for the longest common subsequence problem[J].Journal of the ACMWeb Intelligence and Intelligent Agent Technology.Washington D C:IEEE Press,1977,24(4):664-675.
[15]全方磊.数据特征提取在高铁车地传输中的应用研究[D].杭州:浙江大学,2013:39-40.
[16]牛永洁,张成.多种字符串相似度算法的比较研究[J].计算机与数字工程,2012,40(3):14-17.
[17]张鑫.人名消歧关键技术研究与实现[D].哈尔滨:哈尔滨工业大学,2012:32-33.
(责任编辑: 陈志贤 英文审校:吴逢铁 )
Person Name Disambiguation Based on Revised Longest Common Subsequence
LIN Cuiping, WU Yangyang
(College of Computer Science and Technology, Huaqiao University, Xiamen 361021, China)
Abstract:This paper uses nouns, adjectives, gerunds and named entities as text features, and also considers the word order and word frequency when computing the text similarity. A text clustering method based on revised longest common subsequence (LCSC) is proposed. The experimental results show that the LCSC method can significantly improve the overall performance in person name disambiguation compared with traditional clustering method and make the average F-measure increase from 74.2% to 84.9%. The overall performance also improved by 3.7% when compared with the longest common subsequence method.
Keywords:person name disambiguation; text similarity; longest common subsequence; hierarc
中图分类号:TP 391
文献标志码:A
基金项目:福建省科技计划重大项目(2011H6016); 福建省科技计划重点项目(2011H0028)
通信作者:吴扬扬(1957-),女,教授, 博士,主要从事数据库技术和数据挖掘的研究.E-mail:wuyy@hqu.edu.cn.
收稿日期:2014-08-31
doi:10.11830/ISSN.1000-5013.2016.02.0201
文章编号:1000-5013(2016)02-0201-06
