
基于AmazonS3的云存储系统的设计
2016-03-25 06:13:40郭巍李小勇
微型电脑应用 2016年1期
郭巍,李小勇
基于AmazonS3的云存储系统的设计
郭巍,李小勇
摘 要:BlueOcean Storage System是一款自主设计研发的分布式文件系统。在此基础之上,设计并实现了S3 engine,使其能够胜任云存储的工作。通过对高并发模式的分析,体现出BOSS+S3engine在设计上的优势。最后通过与开源项目的对比来证明结论,是使用可靠的。
关键词:云存储;S3;高并发模式;性能测试
李小勇(1972-),男,甘肃天水人,上海交通大学,信息安全工程学院,副教授,博士,研究方向:操作系统和高性能网络,上海,200240
0 引言
随着互联网技术的发展,各式各样的应用与需求应运而生。云存储作为其中代表,受到了广泛的关注。对比传统网络存储,云存储突破了网络的限制,用户可以在任何时间任何地点,通过网络获取相关服务。
目前,云存储接口的主要标准包括Amazon的S3、OpenStack的Swift的API、SNIA提出的CDMI。相较于后者,Amzaon的S3的优势主要包括:(1)简介且功能全面;(2)考虑到安全性的要求;(3)经过商业化的实践检验。因此,将方案定为Amazon的S3接口是符合实际需求的。
本系统的底层存储是建立在BlueOcean Storage System(简称BOSS)上的。通过BOSS可以搭建一套稳定且高效的S3协议引擎,对上层用户提供云存储服务。用户可以自定义存储的方式(版本信息)、存储的周期(数据的生命周期)、访问控制权限和共享的管理等等,方便上层用户的使用。
1 S3与对象存储
Amazon S3是一个公开的服务,上层用户可以使用它存储数字资产,包括图片、视频、音乐和文档。Amazon 的 S3公开了 RESTful API[1],使用户可以使用任何支持 HTTP通信的语言访问 S3。
S3用容器与对象模型代替了传统的目录与文件模型。上层用户所看到的不再是递归嵌套的目录树结构,而是扁平的二级目录结构。S3规定了容器之间是不允许进行嵌套的,因此所有的对象都存储在同一层次中。同时,S3为每个对象维护了一个全局唯一的ID号,这个ID号由容器名与对象名组成。S3保证容器名的全局唯一性,从而保证了对象号的全局唯一。
对象是S3的基本单元。每个对象都是由数据本身以及与数据有关的元数据组成。元数据是描述数据属性的数据,包括数据分布、服务质量等。S3提供了2种元数据:系统元数据与用户自定义元数据。系统元数据指描述存储系统本身的元数据,包括副本数量、存储区域等。而用户自定义元数据指用户可以选择的服务,包括对象的版本信息、对象的生命周期等。两者从不同的角度支持整个系统的运作。对象的大小可以不同,可以包含整个数据结构,如文件、数据库表项等。
相比于传统的文件目录结构,容器对象结构的主要优势在于:(1)传统目录结构数据很难均衡的分布在所有节点中,造成节点之间的不均衡。而对象存储可以依靠对象号的HASH值,将对象均匀的分布在整个存储集群中,做到负载均衡与线性扩展。(2)相比于目录结构,对象存储可以由对象自身维护自己的属性,从而简化了存储系统的管理任务,增加了灵活性。(3)当目录层次较深时,一次文件的访问会经过多次的读盘与权限的验证,而对象存储只有两级结构,因此可以极大的减少IO路径,同时readahead技术也可以有效的减少同容器下对象的检索时间,提高效率。基于这些优点,相信对象存储将会成为互联网存储领域的领导方向。
2 系统框架解析
本存储系统主要由两部分组成S3engine与BOSS存储系统组成,如图1所示:

图1 S3engine+BOSS体系架构
BlueOcean Storage System(简称BOSS)存储系统,是一款自主设计与研发的分布式对象存储系统,能够向上层提供海量(PB级)、可扩展、高可用、低成本的存储
服务。采用完全对称的存储架构,所有节点在整个存储集群中都是等价的,从而不会存在任何的单点问题。数据通过改良的一致性hash算法[3],被均匀的分布到所有的存储结点,因而也不会存在任何的热点问题。
S3 engine是为BOSS存储系统所设计的S3协议引擎。通过对用户所发送的S3协议内容的解析,转变为某个对象的读写,并按照实际情况将解析好的请求交给下层的BOSS来处理。完成请求后,将应答包装成S3协议格式,向用户发送应答。作为BOSS与用户之间的桥梁,服务于整个系统。
3 关键技术设计
由于篇幅的限制,本文将重点放在高并发模型设计与副本、审计与修复策略上。
3.1 高并发模型设计
S3engine的应用场景是面向百万级链接、为上层用户提供高并发、低延迟的S3协议的存取服务。为此高并发模型设计的好坏直接影响系统的性能与可用性。
BOSS分布式文件系统采用多进程的并发模式。多进程(pre-fork)与传统的线程池模式对比如表1所示:

表1 多进程(pre-fork)与传统的线程池模式对比
从表1的分析中可知,多进程与多线程模式性能的差异主要表现在数据同步与进程切换上。
通过lmbench的测试,进程上下文切换的代价如图2所示:
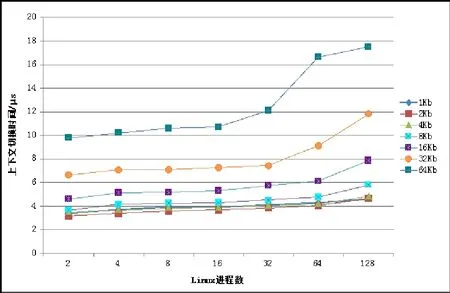
图2 进程在不同情况下上下文切换时间消耗
1K、2K、4K、8K、16K、32K、64K为所切换的进程空间大小。
从图2中可以看出,进程空间的大小与进程并发数共同影响着进程上下文切换时间。由于进程的空间相互独立,所以在并发数相同的情况下空间越大,消耗的时间越多。相对而言线程共享进程空间,切换时的代价仅为自身的堆栈信息,所以代价要低于进程。通过《Linux线程库性能分析》[4]这篇文章可知,在单CPU中,线程大小为10Kb时,10线程的切换所消耗的平均时间为0.968微秒。低于进程的大约4微秒的时间。
线程锁带来的开销主要包括两部分:锁本身的开销与因为锁而造成的线程切换所带来的开销。因此,测试通过程序模拟锁的开销与线程切换的开销,在不同线程数量的情况下总耗时上的差异。测试程序为每个线程执行1000000次加法操作。使用线程锁的测试程序在每次的加法前申请锁,完成一次加法以后释放锁。测试结果如图3所示:

图3 多线程并发执行耗时
不加锁的模式下,消耗的时间随线程数缓慢增加,128个线程并发的情况下所耗费时间约为1.432秒。加锁的模式下,时间消耗陡增,128个线程并发耗时高达19.352秒。通过systemtap工具可以清楚地看到在加锁与不加锁两种情况CPU调度次数。systemtap结果如表2所示:

表2 线程调度次数统计
正常运行的情况下,系统每秒种的CPU调度约为960次。在不加锁的情况下,CPU调度次数随线程数增加而缓慢增加。当加锁的情况下,CPU发生了剧烈的上下文切换,从而浪费了大量的系统时间。从CPU占有情况也可以看出,从32线程到128线程在加锁的情况下,CPU占有率都接近100%,系统处于频繁的上下文切换之中,浪费了大量资源。测试选用一次加法作为临界区,放大临界区会提高一定的性能,但现实情况下很难有对较大规模临界区的加锁使用。除此之外相较于传统的线程池模式,任何进程的错误都不会影响别的进程并能快速恢复,这是线程池模式不可能实现的。
从上述分析,可以得出结论:在线程池模式中,对临界资源,如缓冲区的访问是必须加锁,锁的开销会直接降低系统并发性能,造成大量不必要的调度。在多进程模式下,进程之间彼此独立,加锁操作显著减少。虽然进程调度消耗的时间较多,但在可靠性与可用性方面,多进程显然是具有巨大优势的。因此,选择多进程模式符合系统设计的需求并且便于开发。
3.2 磁盘异步IO
分布式系统的主要事件包括网络事件与磁盘I/O事件。将网络连接设为非阻塞方式可以有效的规避网络接收信息延迟所造成的阻塞。
相比之下,磁盘的I/O特性要复杂许多。I/O通过同步/异步、阻塞/非阻塞可以分为4大类。在磁盘I/O方面使用的最多的是同步阻塞式I/O——标准的read/write,以及异步非阻塞式I/O——AIO。AIO是 LINUX 2.6 版本内核的一个标准特性。AIO 的基本思想是允许进程发起很多I/O操作,而不用阻塞或等待任何操作完成。稍后在接收到 I/O 操作完成的通知时,进程就可以检索 I/O 操作的结果。
磁头的移动是毫秒级的,海量并发请求会使得磁头进行大量无规则运动,浪费大量时间。如果使用AIO,在大量I/O提交以后,内核会优化整个I/O队列,使得寻道时间(磁头的移动)得到相当程度的减少,从而在另一个方面提高整体的吞吐率,减少延迟抖动。epoll是一种阻塞的I/O复用系统调用,是基于事件触发的。AIO事件可以触发epoll,通过epoll可以减少系统不必要的空转与阻塞。最大程度合理利用资源。
3.3 副本、审计与恢复策略
副本策略BOS
S 分布式文件系统的设计目的是为用户提供一个高可用、高可靠的数据存储平台,因而将采用强一致性的模型设计[5]。对象数据通过primary-slave 的模式写入存储系统,primary-slave 数据推送过程如图4 所示:

图4 primary-slave模式数据推送过程
所有读写都通过primary向用户回复。读请求用户任意选择两个节点进行对比,决定读取数据。写流程为:(1)用户发送写请求给primary。(2)primary将请求转发给slave,slave完成相应请求。(3)slave向primary发送应答。(4)primary向另一个slave发送写请求。(5)slave向primary回复。(6)primary汇集所有信息向client回复完成情况。其中(2)、(4)可以并发同时进行。三个副本可以几乎同时进行写的操作,因而读写时延较低。
通过NRW理论[5]可知,任何存储系统想保持强一致性,必须满足写成功的最小次数W与读操作读取副本次数R之和大于副本个数N,即R+W>N。所以在推送流程中,至少保证写成功2个副本,才能返回成功。在读的过程中,必须访问2个副本比较时间戳,获取最新版本。
审计策略与修复策略
审计与修复是系统保证一致性与高可用性的重要方法。审计负责系统不一致性错误的发现并向修复服务报告。审计按照处理任务与执行流程的不同分为两种:实时审计和周期性审计。
实时审计负责副本跟新时错误的汇报。由于网络的传输存在丢包或乱序的可能,多个副本之间数据跟新可能会发生错误。为了捕获这种错误,每次的修改操作都会使对象的版本号加1,实时审计会检查primary节点推送来的数据版本号是否与当前版本一致,从而判断是否进行这次写操作。
由于存储介质的问题,数据长时间存放后可能会发生扇区损坏,出现 Latent Sector Errors(LSEs)[6]错误。当出现这类错误时,系统处于潜在的不一致状态。周期审计会周期性的计算多个副本之间的校验和并进行比较,维护系统一致性。每当发现出问题的对象,审计服务会将这个对象移动到一个修复目录下,供修复进程周期性的修复。
修复服务会检测修复目录发现修复对象。通过与其他的几个节点同一对象的对比,确定正确对象的版本信息,将正确的对象覆盖原有的错误对象。从而使整个系统恢复3副本的一致状态。副本版本之间的判定策略为少数服从多数。如果3个副本的版本信息都不一样,则以primary节点存储的对象为准。
周期性审计与修复服务会占有大量的磁盘IO与网络带宽,造成正常服务性能的降低。所以,周期性审计与修复必须基于一定的流控机制。在开始一次任务前,周期性审计与修复服务会获取当前系统的CPU利用率、磁盘吞吐率等系统重要参数,决定这次任务所处理的数据总量。当系统处于重负载时,减少或推迟本次的审计或修复任务,从而尽可能的减少对正常功能的影响。
4 系统测试
测试对比的开源系统是OpenStack的Swift,以及glusterfs。swift由5个节点组成,1个代理节点、1个认证节点、3个数据节点。glusterfs由3个节点组成。BOSS由3个节点组成,在每个BOSS节点部署S3engine。所有节点通过万兆以太网交换机相连。节点数据如表3所示:

表3 节点数据
swift与S3engine+BOSS对512M大文件读写性能如图5所示:

图5 swift与S3engine+BOSS读写性能测试
Swift与S3engine+BOSS在大文件的写性能上都十分的低,swift只有不到30MB/S,而S3engine+BOSS也只有32MB/S。原因在于,两者在接收到数据的时候都要计算512MB数据的校验和,从而直接降低了两者写性能。在读性能的对比上,S3engine+BOSS的写性能能达到78MB/S要远高于swift。Swift在访问数据时,首先要访问验证服务器,接着逐层访问用户账户account、容器container确定权限,最后才能读取数据。虽然这样能保证安全性,但直接影响了性能。S3engine在设计时并没有如此复杂的安全限制,所以访问速度较快。
基于上述原因,高并发测试选择的对比软件是glusterfs。测试对象为BOSS与glusterfs,测试重点为两系统的在高并发情况下的性能对比。测试结果如图6-图9所示:

图6 单副本大文件写
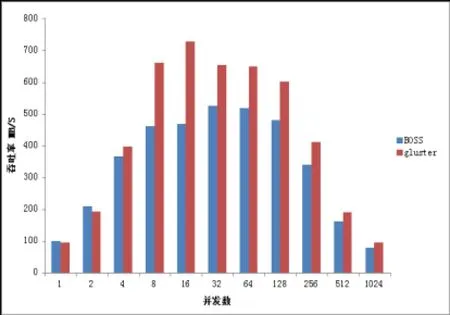
图7 单副本大文件读

图8 双副本大文件写

图9 双副本大文件读
通过数据可以看出,在大文件读写测试的情况下gluster 与BOSS在写性能上类似。读性能方面,gluster要高于BOSS。通过深入地分析,我们发现gluster使用了预读技术,这样会提高大文件顺序读写的性能。然而另一方面,预读会影响小数据块随机读的性能,为了更加明显的体现出差异,我们将测试磁盘换为SSD,随机读的块大小为4KB。测试结果如图10所示:

图10 小文件随机读写性能对比
文件的随机读性能是体现程序并发程度的重要指标。如图10所示,在高并发随机读的情况下,BOSS的性能要远好于gluster。通过计算可以算出,此时BOSS的IOPS约为9万。
5总结
通过与gluster的对比可以证明BOSS所采用并发架构是高效的。虽然通过试验比较可以看出BOSS在性能上十分优秀,然而还需要长时间的开发周期改进现有系统。下一步的工作重点是继续完善S3engine的功能,设计一套有效的安全机制,使BOSS的功能更加完善。
参考文献
[1] Amazon Web Services, Inc. and/or its affiliates. Amazon Simple Storage Service API Reference[EB/OL]. http://docs.aws.amazon.com/AmazonS3/latest/API/s3-api. pdf, 2006,03.
[2] 姚墨涵, 谢红薇.一致性哈希算法在分布式系统中的应用[J].电脑开发与应用, 2012,25(7) .
[3] Laboratories HP,Mcvoy L, Staelin C.lmbench: Portable Tools for Performance Analysis[J]. Usenix Annual Technical Conference, 1996:279-294.
[4] 杨沙洲, Linux 线程库性能测试与分析 [EB/OL]. http://www.ibm.com/developerworks/cn/linux/l-nptl/inde x.html, 2010,09.
[5] BIANCA SCHROEDER, SOTIRIOS DAMOURAS and PHILLIPAGILL .Understanding Latent Sector Errors and How to Protect Against Them[J].ACM Transactions on Storage (TOS) TOS Homepage archive Volume 6 Issue 3, September 2010 Article No. 9.
[6] Werner Vogels. Eventually Consistent - Revisited[EB/OL] http://www.allthingsdistributed.com/2008/12/eventually_ consistent.html, 2008,12.
Cloud Storage System Based on AmazonS3 API
GuoWei, LiXiaoYong
(School of Information Security , Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract:BlueOcean Storage System is a self-design-and-development of distributed file systems. On this basis, design and implement the S3 engine to make it capable of cloud storage work. Through the analysis of high concurrency model, it reflects the BOSS + S3engine advantage in design. Finally, by contrast with the open source projects, it demonstrates results.
Key words:Cloud Storage; S3; High Concurrency Model; Performance Evaluation
收稿日期:(2015.08.04)
作者简介:郭 巍(1989-),男,甘肃兰州人,上海交通大学,信息安全工程学院,硕士研究生,研究方向:海量存储,上海,200240
文章编号:1007-757X(2016)01-0044-04
中图分类号:TP311
文献标志码:A
猜你喜欢
软件导刊(2016年12期)2017-01-21 14:43:14
电脑知识与技术(2016年27期)2016-12-15 18:01:26
出版广角(2016年14期)2016-12-13 02:10:43
出版广角(2016年14期)2016-12-13 02:06:45
电脑知识与技术(2016年26期)2016-11-24 16:47:45
电脑知识与技术(2016年25期)2016-11-16 15:13:09
科学与财富(2016年28期)2016-10-14 02:26:29
电脑知识与技术(2016年15期)2016-07-04 20:24:56
中兴通讯技术(2015年6期)2015-12-09 07:03:04
科学与财富(2015年21期)2015-09-17 17:31:47
