
逻辑回归算法在通信GPRS业务中的应用
2016-03-04 02:01:29潘莉英
西安工业大学学报 2016年11期
潘莉英,曹 岩
(1.陕西省宝鸡教育学院 数学系,宝鸡 721004;2.西安工业大学 机电工程学院,西安 710021)
逻辑回归算法在通信GPRS业务中的应用
潘莉英1,曹 岩2
(1.陕西省宝鸡教育学院 数学系,宝鸡 721004;2.西安工业大学 机电工程学院,西安 710021)
为了对通信GPRS业务用户的流失情况进行有效的预测,对预测中常用三种算法的优劣势进行了比较,选取能很好处理0/1分类问题的逻辑回归算法,并基于逻辑回归算法建立了GPRS业务流失预测模型.提取了广东省移动公司GPRS业务用户流失概率最高的前5%和10%用户,通过查准率、查全率和提升率这三个指标对该模型进行检验,发现该模型定位流失用户的准确率和确定流失用户的覆盖率都是相当高的,说明其能对GPRS套餐使用客户的流失情况进行有效地预测.另外,通过把利用逻辑回归算法与利用决策树算法建立的预测模型的应用效果进行了对比,结果充分说明了利用逻辑回归算法建立的GPRS业务流失预测模型在实际应用中更具优越性.最后,根据该模型解在决实际预测问题中的效果,进一步验证了其具有很强的实用性.
GPRS业务;逻辑回归;流失预测模型;查准率;查全率
通用分组无线服务技术(General Packet Radio Service,GPRS),它是第二代全球移动通信系统向第三代全球移动通信系统的过渡、衔接性技术,GPRS业务是全球手机系统移动电话用户可用的一种移动数据业务[1],这项业务推动了电信事业的飞速发展.但是,随着各种实际因素不断增多,加之各因素间又存在着相当复杂的关系,GPRS业务市场也受到了一定的影响.近年来,尽管电信运营商靠对计费政策进行的调整,也对移动增值市场收入产生了一些负面的影响,但是根据文献[2-3]所述可知,伴随着智能手机的普及,移动互联网已成为人们日常生活里不可或缺的东西,手机电子商务、手机搜索等业务领域也有了良好的市场表现,这些都推动着移动互联网市场规模平稳增长.
目前,全球移动商GPRS数据流量在2013至2015年这三年之内已出现井喷式发展,收入也将随之攀升.全球2013年移动商GPRS数据总流量达到112PB/月,预计2018将达到1400PB/月,平均增长速度高达67%;而且,全球承载在GPRS管道上的移动内容应用总收入2013年达到了2.5千亿美元,预计未来5年将以14%的速度提升[4].另外,随着越来越多的人使用智能手机,手机终端智能化也将对GPRS业务发展起着必然的推动作用.因此,在很长一段时间内,GPRS业务将呈增长趋势.值得注意的是,虽然近年来GPRS业务整体新增市场很大,但客户流失的问题也不容小觑,如果不及时对流失用户的情况进行科学的分析,不制定出有效的针对性挽留策略,随着时间的推移,将会给移动公司及其子公司的营销业务造成更大的损失.因此,有必要组织专门的研究人员通过科学的方法对GPRS业务的流失情况进行预测,以便制定有效对策,从而最大限度地阻止这种不良情况的发生.
1 建立流失预警模型的算法选取
线性回归与逻辑回归都可以用来做预测,但它们之间不存在包含关系.一般情况下,线性回归只可用来进行连续值预测,可以准确的剂量各个因素之间的相关程度与拟合程度的高低,提高预测方程式的效果,但它忽略了交互效应和非线性的因果关系,而且不能处理0/1分类问题,只能处理比如预测投入一定的营销费用时会带来多少收益的连续型变量问题.
逻辑回归和决策树算法则可以轻松处理0/1分类问题,常用来进行二值预测,比如预测一个客户是否会流失,只有0-不流失,1-流失.其中,决策树算法擅长分析数据局部结构,能够对不完整数据进行处理,可以自动处理大量的自变量,容易上手,需要的数据预处理较少,更适合于对各种复杂的联系进行分析.但它对线性关系把握较差,需要较大的样本量,无法支持对多变量的同时检验,不能对影响因素的作用大小进行精确的定量描述,对于结果的解释和应用过于灵活,没有严格的标准可循;逻辑回归算法适用于任何形式变量,擅长分析数据整体结构和线性关系,始终着眼整个数据的拟合,对全局把握较好,可以提供数据中每个观点的概率,结果细腻.但对极值比较敏感,容易受极端值的影响,缺乏探查局部结构的内在机制,运用时需要一定的训练和技巧.
通过以上对几种常用预测算法优劣势的分析,发现逻辑回归和决策树算法都可用来解决GPRS业务流失问题,但经过实际应用对比评估后,逻辑回归预测法能更好地解决这个问题,具体评估比较情况将在本文第3部分进行详细的说明.
2 基于逻辑回归算法的GPRS套餐流失预测模型
2.1 逻辑回归算法原理
逻辑回归是一种特殊的回归模型,与古典的线性回归模型不同,其响应变量是分类变量而非连续变量.例如,研究客户是否会购买某种产品(即买抑或不买),或者研究客户交易是否存在欺诈(即欺诈交易抑或非欺诈交易),等等都属于这类情况.由于现实中存在大量类似的问题,逻辑回归被广泛运用以解决所谓的分类问题.
在逻辑回归问题中,自变量xi(i=1,…,m)与发生率p之间通常都不存在线性关系,更不能保证在自变量的各种取值下,因变量的取值仍能限制在0~1范围内,因此,需作如下变换[5]
y=β0+β1x1+…+βmxm
(1)
(2)
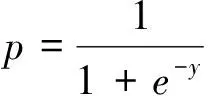
(3)
式(3)即为逻辑回归算法下的发生率p的计算公式,式(1)中的β0是常数项,表示自变量取值全为0时,事件发生与不发生时的概率之比的自然对数值;βi(i=1,…,m)为逻辑回归系数,表示当其它自变量取值保持不变时,该自变量取值增加一个单位引起比数比自然对数值的变化量.
2.2 基于逻辑回归算法的GPRS套餐流失预测模型的建立
2.2.1 数据准备
这个阶段的工作比较繁琐,主要是根据目标问题确定所需数据的来源,对得到的数据进行适当的筛选和分类.主要做法是:排除掉那些记录为空的或记录不完整的无效数据;再将符合条件的数据分成训练集和测试集两个部分,一部分用来建立符合要求的模型,另一部分用来进对该模型的测试能力做出科学的评估[6].
为了满足数据的合理性、有效性和完整性等实际要求,根据现有条件,本文的研究采用了广东省GPRS标准套餐用户在2015年8、9、10这三个月内的通信数据来进行研究.为了得到有效信息,首先需准备这三个月内GPRS标准套餐用户的相关资料,包括:用户基本资料表、用户接触资料、用户通话资料、用户账单资料、清单月汇总表、GPRS标准套餐产品关系历史、家庭网用户信息历史、集团客户基本资料历史等.
根据模型的实际开发需求,采集了广东省GPRS标准套餐用户在2015年8份停机用户记录共2387711个,为了确保建模用户不重复,保证数据的有效性,信息采集时,有先保障用户为月初信控停机,只保留了首次停机用户记录共1870229个;采集的指标共有65个,但其中有11个指标由于数据缺失或数据失效等原因,无法使用,不纳入建模宽表,最终保留了54个指标.
接下来的工作,就是对采集用户和指标数据进行清洗,主要是对采集的指标进行数据降噪处理,主要处理对象为:数据值缺失较多的指标、出现异常值的指标、内容相似的指标、含单一值过多的指标、离散指标值过多的指标、不能直接进入模型的指标等[7-9],具体处理情况归纳如下:
1) 是否为集团客户和是否为VIP客户这两个指标值缺失的比较多,为了方便处理,就用0来替代.
2) 部分用户的年龄高于100岁,这些数据值不在正常范围内(异常值),就要对其进行规定,用100岁来替代.
3) 用户总流量和GPRS总流量所代表的内容相近,交往圈人数和交往圈GPRS使用人数所代表的内容相近,参与活动个数和数据业务使用个数相似,就需将用户总流量合并到GPRS总流量中,交往圈人数合并到交往圈GPRS使用人数中,参与活动个数合并到数据业务使用个数中,然后对这三个指标重新编码.
4) 经统计,呼转异网号码的用户极少,导致异网互转指标0值达到95%以上,单一值所占比率太高,单独研究的意义不大,可将其纳入主叫计费时长指标中.
5) 随着智能手机的飞速发展,各种手机型号就有成百上千个,这就会导致终端型号指标值非常多,使得离散指标值过多,需将其进行归类,重新编码为“苹果”“三星”和“华为”等终端大类(品牌)才可以进入模型.
6) 由于活动合约期截止日期、离网时间等与日期、时间等相关的指标,不能直接进入模型,必须经过处理,衍生出参与活动时长、入网时长等新的数值指标才可以进入模型.
使用以上六种方法,对确定采集的1870229个用户和65个指标数据进行清洗,有11个指标不能直接使用,经处理后,最终得到1869209个有效用户和54个有效指标.
2.2.2 数据处理
数据处理的过程是对清洗过的干净的数据进行数据分析,量化指标对目标的影响性.这个阶段的工作,主要是对上一阶段工作中准备好的数据进行进一步的分析和探索,判断其是否符合建模指标.根据模型分析的具体业务目标,对所采集的数据集按照指标逐项进行净化和质量检查,舍弃不符合要求的数据,以充分保证数据集的质量.然后,考察所选数据之间的关系,以便对其进行整理.
针对数据准备中的最基础原始清单数据,根据模型分析的业务目标,通过对连续性指标进行分箱,使其离散化,剔除那些与流失的关系比较复杂或者和流失的关系不是很紧密的变量;通过相关性分析剔除相关性大的指标变量.对各个字段进行不同粒度的分解与汇总,经过这些筛选工作之后,最终有38个指标被纳入“聪明变量”,进入模型宽表,对能进入模型宽表的38个指标变量进行归类分析后,最终得到23个有效指标变量,为方便起见,分别用x1,x2,……,x23表示每个用户相对应的23个GPRS标准套餐流失模型使用的指标变量.对于每一个用户来说,xi(i=1,…,23)代表的具体指标变量名称见表1.

表1 每个用户对应的23个指标变量名称
2.2.3GPRS业务流失预测模型的构建过程
由于对GPRS业务是否流失进行预测的问题是一个二元预测问题,而且,经过对相关数据进行探索和分析后,发现与此问题相关的数据有数值型的也有离散型的指标数据.所以,要解决这个问题可以用决策树和逻辑回归这两种算法来建立模型.但经过对模型优越性进行检验后,确定选用逻辑回归算法,具体原因详见文中3部分所述.
1) 训练模型
接下来的主要工作是根据准备好的训练集,使用前向迭代法对模型进行训练.迭代进行时,通过-2对数似然值、考克斯-斯奈尔R方(Cox&SnellR方)、内戈尔科R方(NagelkerkeR方)等指标来考察模型的拟合效果.具体迭代步骤及相关数据见表2.
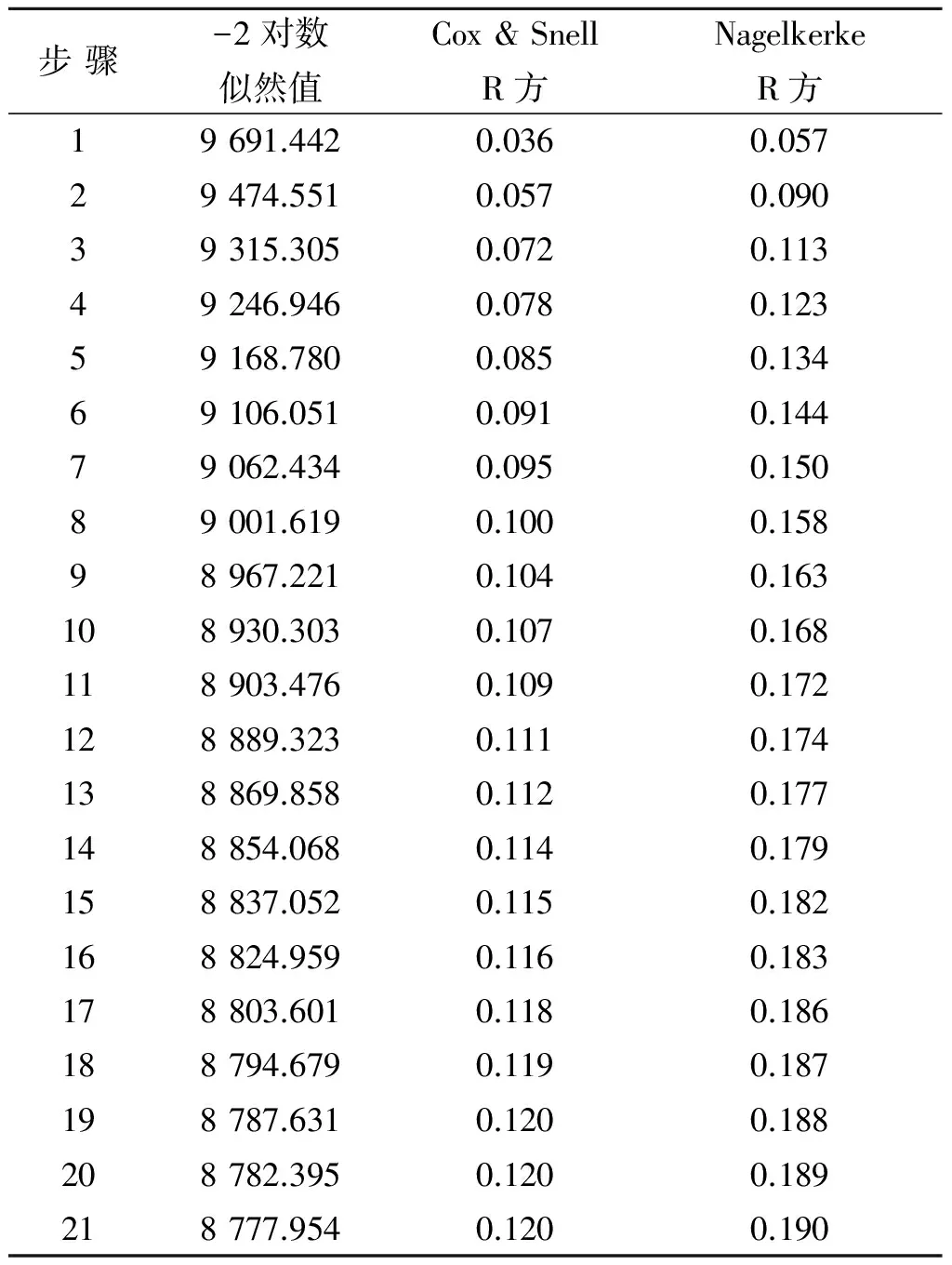
表2 模型摘要
当迭代进行到第21步时,所有变量对应的显著性均为0.000;-2对数似然值从9691.442降为8777.954,其中从第1步到第18步,-2对数似然值降了近900,但从第19步到21步,-2对数似然值每次只降了5,说明此时步差的幅度已经很小了,已达到模型迭代的终止条件,表明模型拟合效果较好;大部分Cox&SnellR方和NagelkerkeR方都超过了0.1,表明模型拟合效果较好.所以,利用逻辑回归算法建立的GPRS业务流失预测模型拟合度高,性能好,可以使用.
2) 优化模型
模型训练好后,还要对模型进行优化分析,主要利用偏回归系数(B)、标准误差(S.E.)和卡方值(Wald)三个指标进行检验,以便考察方程中随着自变量的变化因变量的变化情况,以及自变量与因变量的密切程度.根据检验结果,对模型进行调整,最终得到性能最好的模型.根据模型训练情况,对建立的GPRS业务流失预测模型优化了三次,最终得到最优模型.具体模型见表3.

表3 GPRS业务流失预测模型
具体模型输出结果见表4.

表4 GPRS业务流失预测模型输出结果
对上表中的数据进行分析后,发现在控制其他变量的前提下,自变量每变化一个单位,因变量会变化0~1.1897个单位,因变量变化对自变量变化的影响比前三个模型都大;标准误差均小于0.05;相应的卡方值也足够大.由此说明,这23个指标自变量的变化能够引起因变量的变化,也就是说该用户是否流失直接与这些因素有着密不可分的关系.所以,这次所建模型就是最优的模型,可以用来解决实际问题.
3 GPRS业务流失预测模型的评估和检验
当一个模型建立之后,要通过科学的方法对其使用效果进行评估检验,来衡量其有效性和优越性,进而确定是否能用此模型很好地解决实际问题.下面,就对第三部分中所建立的GPRS业务流失预测模型的有效性和优越性进行评估和检验.
3.1 模型评估
为了检验利用逻辑回归算法建立的GPRS业务流失预测模型的科学性和有效性,就要对其预测效果进行评估,以确保其能在现实环境中使用.
3.1.1 模型评估的方法
常用的模型评估方法是:根据模型输出的结果,依据一定的顺序,提取范围合理的预测对象,通过计算查准率、查全率和提升率等指标,对所建立的模型进行评估[10],进而确定所建立的模型是否能更好地解决目标问题.
以广州移动公司2015年11、12两个月的GPRS套餐用户为例,对模型进行评估。首先,将根据公式(3)算出的测试集中各个用户流失的概率按由大到小的顺序进行排序,确定出每个概率对应的实际流失用户数和不流失用户数,为评估提供有力的数据支撑[11].具体流失概率排序和用户是否流失情况见表5.
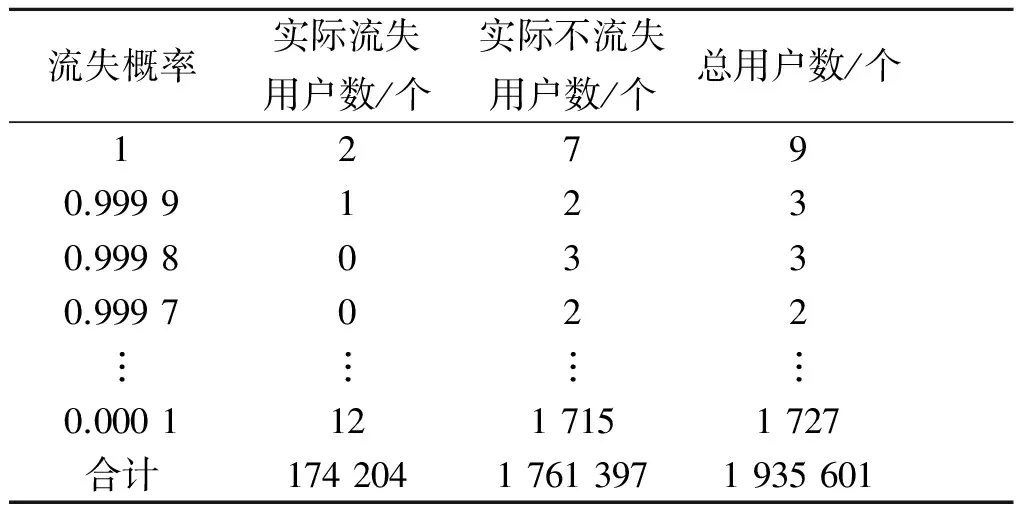
表5 利用逻辑回归算法求得的流失概率排序表
根据表5中的数据,计算出相应的查全率、查准率和提升率这三个指标值,根据这些数值,即可对建立的模型的有效性进行评估,下面就对这三个指标的概念和具体作用作以介绍[12-15].
查准率 表示提取的用户中实际流失的用户数与提取的用户总数的比率,即所提取用户的流失率.查准率常用来衡量定位流失用户的准确率,而且查准率值越高,模型越好.
查全率 表示提取的用户中实际流失的用户数与总流失用户数的比率,即提取用户中流失用户占全部流失用户的比例.查全率常用来确定流失用户的覆盖率,而且查全率越高,模型越好.
提升率 表示提取用户的查准率与全部用户查准率的比率,模型相对于总体的提升倍率.提升率与用户提取量有关,而且提升率值越高,模型越好.
为了方便计算,根据定义总结出查全率、查准率和提升率这三个指标的计算公式:
查准率=提取的用户中实际流失的用户数/提取的用户数
查全率=提取的用户中实际流失的用户数/总体的流失用户数
提升率=提取用户的查准率/全部用户的查准率.
3.1.2 模型评估结果
一般情况下,在利用查全率、查准率和提升率这三个指标对建立的GPRS业务流失预测模型进行检验评估时,所要提取用户数的确定十分关键,会直接影响到这三个指标值,进而影响到模型的检测效果.如果提取的用户数少于所有用户数的5%,则覆盖面太小,会影响到预测流失用户的覆盖率;如果提取的用户数多于所有用户数的10%,则会降低预测的命中率.因此,提取了流失概率较高的排名前5%和10%的用户,认为他们是流失的用户,计算出相应的查全率、查准率和提升率.具体数据见表6.

表6 利用逻辑回归算法建立的GPRS业务流失预测模型的查全率、查准率和提升率
由表6中的数据可知,提取广州移动公司2015年11、12两个月的GPRS套餐用户流失率最高的前5%用户,准确率达57%,将覆盖60%的流失用户,提取的这些用户是随机抽取用户准确率的6.4倍;提取流失率最高的前10%用户,准确率达40%,将覆盖72%的流失用户,提取的这些用户是随机抽取用户准确率的4.4倍.所有这些数据说明,利用逻辑回归算法建立的GPRS业务流失预测模型定位流失用户的准确率和确定流失用户的覆盖率都是相当高的,也就是说,这一模型能对GPRS套餐使用客户的流失情况进行有效地预测.
3.2 模型优越性检验
通过上面的评估,知道利用逻辑回归算法建立的GPRS业务流失预测模型能科学有效地对使用GPRS套餐用户的流失情况进行预测,但它是不是可用来解决这一问题的最好方法呢?这就需将这种预测法与同样可以用来解决预测问题其它方法的预测效果进行比较,来衡量该模型的优越性.
其实,利用决策树算法也可以建立模型,对GPRS业务流失情况进行科学预测.在利用决策树算法建立预测模型时,通过对广州移动公司2015年11、12两个月的GPRS套餐用户数据进行探索分析,确定了ARPU、GPRS费用波动、交往圈中的GPRS用户数、GPRS上网次数、GPRS实际单价、单次上网流量、GPRS流量、GPRS超流量;GPRS
套餐类型、GPRS利用率、ARPU趋势、GPRS上网次数趋势、GPRS流量趋势、GPRS超流量趋势、GPRS利用率趋势、数业ARPU趋势、入网时长、账户余额等18个有效指标,它们与利用逻辑回归算法建立的预测模型中的约80%的关键因子重合.与前面利用逻辑回归算法建立的GPRS业务流失预测模型的评估方法相同,先把根据公式(3)算出的测试集中各个用户流失的概率按由大到小的顺序进行排序,确定出每个概率对应的实际流失用户数和不流失用户数.具体流失概率排序和用户是否流失情况见表7.
根据上表中的数据,提取流失率较高的前5%和10%用户,利用公式计算出相应的查全率、查准率和提升率,具体数据见表8.
通过对比分析表6和表8中的数据发现,利用逻辑回归算法建立的GPRS业务流失预测模型的查准率、查全率、提升率分别约是利用决策树算法建立的预测模型的5.8倍、6倍、10—20倍.从这些数据可以看出,利用逻辑回归算法建立的GPRS业务流失预测模型比利用决策树算法建立的预测模型定位流失用户的准确率更高,确定流失用户的覆盖面更广,按比率提取的用户比随机抽取用户的准确率更高.所以,利用逻辑回归算法建立的GPRS业务流失预测模型比利用决策树算法建立的预测模型更优.
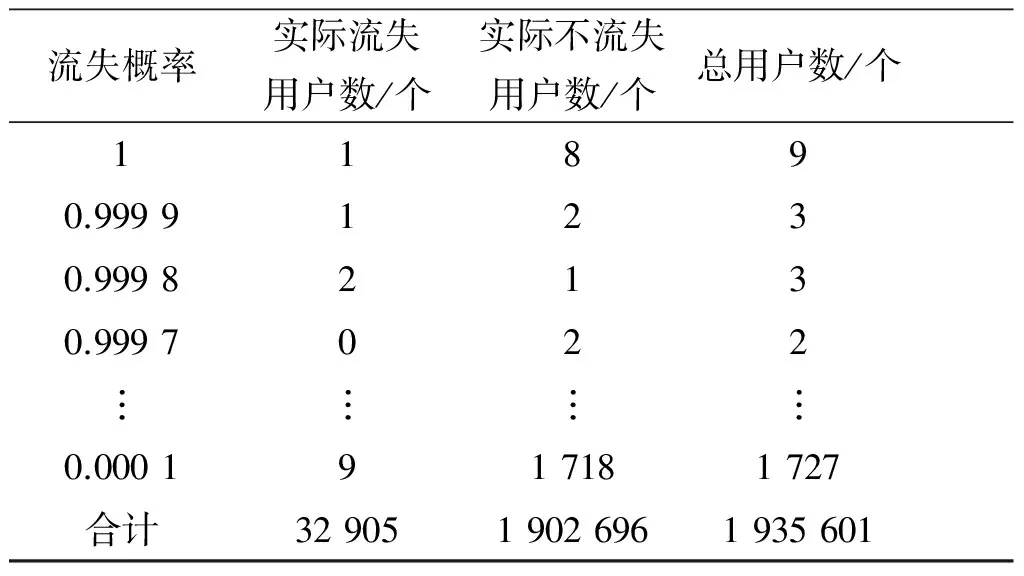
表7 利用决策树算法求得的流失概率排序表
其实,任何模型都不可能是完美无缺的,虽然利用逻辑回归算法建立的GPRS业务流失预测模型能有效解决0/1分类的预测问题,但却也无法避免指标间的相关性对预测结果带来的影响.如果两个或两个以上的指标间相关性太强,就会相互产生抵消作用,进而影响到预测的准确性.虽然利用逻辑回归算法建立的预测模型有这样的不足,但这却是目前使用效果最好的建立预测模型的方法.

表8 利用决策树算法建立的GPRS业务流失预测模型的查全率、查准率和提升率
4 GPRS业务流失预测模型的应用
在2015年底,利用建立的GPRS业务流失预测模型对广州移动公司2016年上半年的GPRS套餐用户流失情况进行预测,制定合理的挽留策略,以便为公司减少损失,创造更多的价值.
4.1 按流失级别划分GPRS套餐用户
根据2015年底广州移动公司使用GPRS套餐客户数(19 267 390人),为方便起见,假定2016年上半年广州移动公司使用GPRS套餐客户数为12 000 000人,根据表1中的23个有效指标和对应数据,利用式(1)、式(3)和流失预测模型能给每个GPRS套餐用户计算出一个流失概率,概率值越高说明流失的可能性越大;概率越低则说明流失的可能性越小[16].经计算,流失的总用户数约为120万.根据流失概率可将流失用户划分为三个流失级别:
第一级别 高流失级别.在这一流失级别中,用户的流失概率都大于0.62,约有用户24万,占到了总流失用户的20%,流失率高达28%,明显高于GPRS套餐总体流失率(8%).流失率在这一级别的用户是挽留的重点.
第二级别 中流失级别.这一级别中的用户流失概率都处于[0.47,0.62]之间,约有用户36万,占到了总流失用户的30%,流失率约为5.7%,略低于总体流失概率.
第三级别 低流失级别.这一级别中的用户流失概率都低于0.47,有用户60万,占到了总流失用户的50%,流失率不到3.2%,远远低于GPRS套餐总体流失率.
4.2 挽留策略
为了有效挽留这24万高流失用户,广州移动公司针对2016年上半年GPRS标准套餐制定了新的资费标准.由以前的5元、10元、20元、50元、100元和200元套餐扩展到5元、10元、20元、30元、40元、50元、58元、100元、130元、180元和200元等多种类型套餐,以加大用户选择的余地,尽量避免因业务资费和上网体验而造成的客户流失。
除了GPRS标准套餐资费进行调整之外,广州移动公司还根据流失原因开展了四个挽留营销活动:
活动一 使用58元以上(含58元)GPRS标准套餐的用户,在2016年1—6月份每月均可获得1G的赠送量;
活动二 入网3个月以上且正在使用58元以上GPRS标准套餐的老客户,从2016年1月起,即可领取12G流量半年包,分6个月赠送,每月2G;
活动三 针对包月流量不够的客户,开通流量加油包业务,资费标准为:5元30M、10元70M和20元150M;
活动四 针对当月临时有较高上网流量需求的用户,推出手机流量叠加包.在不影响原有套餐的基础上,可同时购买流量包,资费标准为:10元100M、20元300M、30元500M、50元1G、70元2G、100元3G、180元6G.
广州移动公司把使用全球通、神州行、动感地带、TD品牌这四种品牌的客户的高流失级别用户分别按流失概率从高到低进行排名,指派专门的营销人员按从上往下的顺序派发挽留营销活动单,以此来维系老用户,达到防止客户流失的目的.
经GPRS标准套餐制资费标准调整和开展挽留营销活动半年后,2016年7月,对广州移动公司2016年上半年使用GPRS业务流失预测模型及维挽策略后的效果进行了评估.发现实际流失客户数(1 103 200个)比预测流失客户数(1 200 000个)少了很多,连续6个月GPRS流失率出现下降趋势,总降幅达30%,为公司挽留用户50多万,节省营销成本200多万,提升了流量业务整体利润,促进了GPRS营收和业务的健康发展.
5 结 论
1) 本文主要利用逻辑回归算法建立了GPRS业务流失预测模型,通过科学的方法对其进行评估,并将其在实际问题当中检验了该模型的应用效果.对解决预测问题中常用的三种算法优劣势进行了比较,明确了利用逻辑回归算法能很好处理0/1分类问题.利用逻辑回归算法建立的GPRS业务流失预测模型拟合效果好,性能优良.
2) 通过查准率、查全率和提升率三个指标对该模型进行检验,发现利用逻辑回归算法建立的GPRS业务流失预测模型定位流失用户的准确率和确定流失用户的覆盖率都是相当高的,能对GPRS套餐使用用户的流失情况进行有效地预测.而且比利用决策树算法建立的预测模型定位流失用户的准确率更高,因此更具优越性.
3) 通过将该模型应用在广州移动公司2016年上半年GPRS标准套餐流失用户的预测和维挽营销中后,连续6个月GPRS流失率出现下降趋势,为公司挽留用户50多万,节省营销成本200多万,提升了流量业务整体利润,进一步说明了该模型实用效果明显.
由于条件限制,本文研究所采用的数据均来自广州移动公司GPRS业务使用客户,有一定的局限性,在今后的研究中争取能得到西安、宝鸡等更多地区移动公司的支持,获得相关用户数据,进一步优化GPRS业务流失预测模型;本文所研究的模型和算法还可应用到医学、农林、消防等多个领域,对这些领域中有可能产生的不良情况进行预测,以便及时制定对策,进行有效预防;根据实际需要,还可利用类似方法建立GPRS业务挽留机会模型和GPRS业务流失原因模型,以便找出需要挽留且值得挽留的客户和识别最可能导致用户流失的原因,进而制定有效对策,最大可能地保留老用户、发展新客户.
[1] 张爱华.WiTi技术与GPRS技术比较[J].信息通信,2015(6):235.
ZHANG Aihua.The Comparison of WiFi Technology and GPRS Technology[J].Information & Communication,2015(6):235(in Chinese)
[2] 高弋坤.移动互联网“地位争夺战”[J].通信世界周刊,2011(38):13.
GAO Yikun.“Battle for Position” of the Mobile Internet[J].Communications World Weekly ,2011,(38):13.(in Chinese)
[3] SUKI N M.Students’ Demand for Smartphones Structural Relationships of Product Features,Brand Name,Product Price and Social Influence[J].Campus-Wide Information Systems,2013,30(4):236.
[4] 中研普华宽带网络行业分析专家.2014—2018中国宽带网络产业市场前景预测及投资价值评估报告[R].北京:中研普华公司,2014.
Broadb and Network Industry Analysts of Zero Power Intelligence Group.Annual Research and Consultation Report of Pan-orama Survey and Investment Strategy on China Industry(2014-2018)[R].Beijing:Zero Power Intelligence Group,2014.(in Chinese)
[5] 张秀兰.逻辑回归模型下的企业财务预测实证研究[J] .求索,2012(1):36.
ZHANG Xiulan.Logistic Regression Model of Enterprise Financial Forecast and Empirical Research [J].Seeker,2012,(1):36.(in Chinese)
[6] 米子川.统计建模的数据来源和数据准备的方法[J].统计与决策,2012,(17):16.
MI Zichuan.Statistical Modeling Method of Data Source and Data Preparation[J].Statistics & Decision,2012,(17):16.(in Chinese)
[7] ASHURI A,AMIRI A.Evaluating Estimation Methods of Missing Data on a Multivariate Process Capability Index [J].Inter-national Journal of Engineering,2015:88.
[8] 宋哲.浅谈化探数据异常下限处理方法及其评价[J].甘肃科技,2015,31(22):38.
SONG Zhe.Introduction to Geochemical Anomaly Threshold Data Processing Method and Its Evaluation[J].Gansu Science and Technology,2015,31(22):38.(in Chinese)
[9] 司亚清,孟亚楠.基于Logistic模型的电信业务潜在用户预测研究[J].软件,2012,33(11):218.
SI Yaqing,MENG Yanan.Research of Predicting Potential Customers Based on Logistic Model in Telecommunications[J].Software,2012,33(11):218.
(in Chinese)
[10] 彭凯,秦永彬,许道云.基于逻辑回归的客户稳定度建模[J].计算机程,2011,37(9):12.
PENG Kai,QIN Yongbin,XU Daoyun.Customer Stability Modeling Based on Logistic Regression[J].Computer Engineering,2011,37(9):12.(in Chinese)
[11] 肖远.电信企业客户的流失概率模型探讨[J].无线互联科技,2015 (19):58.
XIAO Yuan.Exploration on the Loss Probability Model of Telecom Enterprise Customers[J].Wireless Internet Technology,2015(19):58.(in Chinese)
[12] 赵小苏.科技查新中的查全率与查准率[J].警察技术,2012 (5):71.
ZHAO Xiaosu.Recall Rate and Precision Rate in the Science and Technology movelty Search[J].Police Technology,2012,(5):71.(in Chinese)
[13] HU J,SHIH W,LIN Y.Development of Stock Evaluation System Based on Quasi-Linear Regression Model[J].International Journal of Electronic Business Mangement,2013,11(1):23.
[14] 周生宝,郭俊芳.客户流失预测模型设计与实现[J].实践经验,2012(5):170.
Zhou Shengbao,Guo Junfang.Design and implementation of Customers Churn prediction Model in Telecommunication[J].Practical Experience,2009,(5):170.(in Chinese)
[15] STEFAN B,CHARLES L A C,GORDON V.Cormack.Information Retrieval:Implementing and Evaluation[M].Boston:MIT Press,2012.
[16] 刘晓.提高信息检索效率的途径——提高查全率与查准率 [J].科技信息,2013(22):236.
LIU Xiao.Ways to Improve the Efficiency of Information Retrieval-Impring the Recall Rate and Precision Rate[J].Science & Technology Information,2013,(22):236.(in Chinese)
(责任编辑、校对 肖 晨)
Application of Logistic Regression Algorithm in GPRS Business
PANLiying,CAOYan
(1.Math Department,Baoji Education Institute of Shaanxi,Baoji 721004,China; 2.School of Mechatronic Engineering,Xi’an Technological University,Xi’an 710021,China)
In order to effectively predict the loss of the users of communication GPRS business,a comparison between three algorithms was made that are commonly used in practical predictions.The Logistic algorithm which is better for the 0/1classification was selected,on the basis of which the model for predicting the loss of users of GPRS business was built.The top 5% and 10% users of the GPRS business in the Guangzhou Mobile Company were extracted whose loss probabilities were the highest.The model was tested with three indicators,including accuracy rate,recall rate and increase rate.It is found that both the accuracy rate of positioning the loss of the users and the coverage rate of confirming the loss of the users are fairly high,showing that the model can effectively predict the loss of the GPRS package users .In addition,the applications of the two predicting models built respectively on the Logistic algorithm and the Decision tree algorithm were compared.The comparison shows that the model built on the Logistic algorithm is superior in practical use.And its practicality was further verified.
GPRS business;logistic regression;loss-predicting model;accuracy rate;recall rate
10.16185/j.jxatu.edu.cn.2016.11.007
2016-03-18 基金资助:广东移动数据部流量业务专项运营项目(G001-YDSH-BX-140020)
潘莉英(1980-),女,宝鸡教育学院讲师,主要研究方向为应用数学.E-mail:481322320@qq.com.
F626.3
A
1673-9965(2016)11-0897-09
猜你喜欢
小猕猴学习画刊(2021年6期)2021-08-05 04:26:44
幽默大师(2019年6期)2019-06-06 08:41:42
现代电子技术(2018年20期)2018-10-24 04:39:04
现代情报(2018年11期)2018-01-07 09:41:14
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
海峡姐妹(2016年4期)2016-02-27 15:18:28
环境与生活(2016年6期)2016-02-27 13:47:06
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
中国管理信息化(2009年10期)2009-06-19 08:24:28
