
一种L-M优化BP网络的茶叶茶梗分类方法
2016-02-24 10:41刘孝星郑力新周凯汀
计算机技术与发展 2016年4期
吴 哲,刘孝星,郑力新,周凯汀
(1.华侨大学 工学院,福建 泉州 362021;2.华侨大学 信息科学与工程学院,福建 厦门 361021)
一种L-M优化BP网络的茶叶茶梗分类方法
吴 哲1,刘孝星2,郑力新1,周凯汀2
(1.华侨大学 工学院,福建 泉州 362021;2.华侨大学 信息科学与工程学院,福建 厦门 361021)
传统的茶叶茶梗分选方法在特征选取方面存在着样本颜色特征提取单一的问题,以及现有的茶叶茶梗分类器普遍存在分类精度低、耗费时间长等问题。针对CCD相机采集的茶叶茶梗的数字图像,首先经过二值化、开运算、闭运算、样本图像去噪、图像分割等预处理过程,再根据茶叶茶梗样本形态学特征的差异,提取出圆形度、矩形度、延伸率、Hu二阶不变矩、最大内切圆与其面积比等5类区分度大、独立性好的特征,作为BP神经网络分类器的输入向量,并采用L-M(Levenberg-Marquardt)学习算法对传统的BP神经网络分类器进行优化,用于茶叶茶梗的分类。实验和仿真结果表明,经过L-M算法优化的BP网络分类器对茶叶茶梗样本的分类精度高达95%,且耗时相对较少,是一种有效的茶叶茶梗分类方法。
形态学特征;L-M学习算法;BP网络;茶叶茶梗分类
1 概 述
中国是一个产茶大国,近年来茶叶年产量和年消费量均超过100万吨,茶叶出口量也相当可观[1]。然而毛茶中经常夹杂茶梗、黄叶等杂物,严重影响了优质茶叶的等级。手工拣梗作业一直制约着茶业加工效率的提升。因此寻求一种精度高、耗时少的茶叶茶梗分拣技术成为提高茶叶品质的关键。
目前国内外茶叶茶梗分类方法主要有贝叶斯分类、最小距离分类、支持向量机分类与人工神经网络分类等,然而这些传统的分类方法存在着不同的缺点[2-6]。贝叶斯分类虽然原理简单、易于实现,但当功能属性值分布和正态分布差异太大或样本少时不适用;最小距离分类器稳定性较差,当样本集合聚类的效果不佳时,容易产生茶叶茶梗误判;传统的SVM分类器用于茶叶茶梗分类时虽然分类准确度较高,但是训练耗时长;传统BP神经网络分类器虽然适应性较强、叶梗分类精度高,但以过慢的收敛速度和易于跳入局部极值为代价。
毛茶加工设备中茶叶色选机的设计原理是采用传感器检测传送带上的毛茶样本颜色,以茶叶茶梗的光谱参数为特征,根据两者颜色特征的差异,通过设置合适的阈值,喷气阀就会把其中茶梗等杂物喷出。但仅依靠单一的颜色特征和阈值判别进行分类,当两者颜色相近时,叶梗分类难度增大,误判率也大为增加,无法达到预期的色选精度和效率,而且在样本图像采集时颜色特征受光线、粉尘等外界环境的影响较大。其实茶叶茶梗除了颜色特征有差异外,还有其他诸如形状、纹理等方面不同的特征,可以作为茶叶茶梗分类的依据。
针对当前茶叶茶梗分类算法中样本颜色特征向量选取单一和传统BP神经网络分类器局限性的问题,文中选取茶叶茶梗区分度大的形态学特征,采用L-M学习算法优化的BP神经网络分类器,以样本分类精确度和耗用时间为验证指标,实验结果证明经L-M算法优化的BP神经网络能很好地完成茶叶茶梗的分类。
2 形态学特征选取
良好特征的提取是茶叶茶梗分类时高精度和低时耗的关键。首先用CCD相机在相同的环境下采集的600张茶叶茶梗图像(茶叶茶梗图像各300张)建立样本图像库,以便全方位地研究样本特征。在实验中随机抽取茶叶、茶梗各200张样本图像进行二值化、开运算、闭运算以填充叶梗内细小空洞,图像去噪、图像分割等处理,从而为后续的特征提取做准备。
样本预处理前后的实验图见图1。

图1 样本预处理前后对比实验图
现有的特征提取方法通常分为基于颜色特征的提取、基于形态学特征的提取、基于纹理特征的提取等[7-8]。针对茶叶茶梗分类,形态学特征较颜色特征和纹理特征更简单直观,算法更易实现。研究发现相同品种的茶叶茶梗在形态上差异很大。根据采集的茶叶茶梗样本图,文中从两者的形态学特征上对样本进行分类实验。经过对样本形态学特征的分析,选取两者间具有较大区分度的特征,包括圆形度、矩形度、延伸率、Hu二阶不变矩、最大内切圆面积与样本面积比等5类共6个特征向量,这些形态学特征定义如下:
(1)圆形度。
圆形度是反映茶叶、茶梗轮廓的外形参数,由周长P和面积A确定,用“C”表示。圆形度最常用的定义如下:
(1)
在某种程度上圆形度反映了物体轮廓的复杂程度[9]。C越大,说明区域形状越简单;C越小,说明区域形状越复杂。圆形物体的C值为1。一般地,茶叶较为宽大且呈类圆形,故C值较大;茶梗细小狭长,故C值较小。因此定义圆形度为其特征值T1。
(2)矩形度。
矩形度常用物体的区域面积S0与其最小外接矩形的面积Smer的比值定义,如式(2):
(2)
式中,R取值在0~1之间。当R=1时,物体为矩形;圆形物体的R值为π/4。
矩形度描述的是目标区域面积对其最小外接矩形的占空比,因此定义矩形度为其特征值T2。
(3)延伸率。
延伸率常见的定义如下:
(3)
式中,L、W分别为物体最小外接矩形的长、宽。对于圆形物体,其S为1;细长物体的S值接近0。
一般地,茶叶的延伸率大,茶梗的延伸率小。因此定义延伸率为其特征值T3。
(4)Hu二阶不变矩。
对于一幅大小为M×N的图像,设f(x,y)是像素点(x,y)的灰度,则图像的(p+q)阶几何矩mpq、中心距μpq分别定义为式(4)和式(5):
(4)
(5)

不同类型、阶次的图像矩的物理意义各有差别,如零阶几何矩m00代表图像的总“质量”,一阶矩m10、m01代表图像的质心位置,μ02表示通过区域重心水平轴的矩,μ20表示通过区域重心垂直轴的矩。mpq跟随图像变化而变化,μpq对平移不敏感但对旋转敏感。即几何矩或中心矩不能同时具有平移、比例与旋转不变的特点,故二者不能直接用于表示图像的特征。归一化中心距可以克服几何矩或中心矩的这个缺点。归一化中心距定义为如下:
(6)
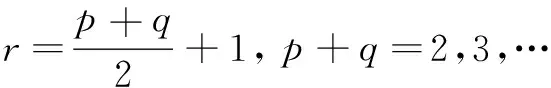
Hu根据二阶和三阶中心矩构造了7个可使图像保持平移、缩放和旋转不变的不变矩[10](这里列出前5个)。具体定义如下:
φ1=η20+η02
(7)
φ2=η20-η022+4η112
(8)
φ3=(η30-3η13)2+(3η21-η03)2
(9)
φ4=η30+η122+(η21+η03)2
(10)
φ5=(η30-3η12)(η30+η12)[(η30+η12)2- 3(η21+η03)]2+ (3η21-η03)(η21+η03)[3(η30+η12)2- (η21+η03)2]
(11)
理论证明,在表述二维物体时只有基于二阶矩的Hu不变矩才与比例、旋转和平移无关[11]。对细小误差敏感的高阶不变矩一般不能对物体有效地分类。在不变矩Φ1~Φ7中,Φ1、Φ2是二阶Hu不变矩,Φ3~Φ7是三阶Hu不变矩,因此选取Φ1、Φ2两个二阶Hu不变矩为特征值T4、T5来处理数据。
(5)最大内切圆面积与面积比。
经研究,茶叶和茶梗的最大内切圆面积与其面积的比值区分度良好。因此定义样本的最大内切圆面积与其面积比为特征值T6。
(12)
式中:Scir表示样本的最大内切圆的面积;S0表示样本的面积。
实验中,样本T6特征的提取实验图如图2所示。
3 BP神经网络与L-M优化算法
3.1 BP神经网络分类器
BP神经网络是一种典型的误差逆向传播的多层前馈网络,一般由输入层、输出层和若干隐含层组成。理论证明一个3层BP网络的隐含层节点数无限大时,可完成任意的由输入到输出的非线性映射[12]。在BP神经网络分类器中,n维向量X=[x0,x1,…,xn-1]为其输入向量,Y=[y0,y1,…,ym-1]为BP网络的输出向量。即有m个可区分的类,每一类记作第i(i=0,1,…,m-1)类。BP网络分类器目的是根据输入向量X得到的输出向量Y来判断X所属的类别。如文中X代表茶叶茶梗样本,样本X可视为由n维形态学特征向量组成,其输入层节点总数即为样本的总属性个数;Y代表茶叶茶梗样本的输出类值,m等于茶叶茶梗样本的分类类别数,即m=2。BP神经网络分类器在误差反馈机制下,反馈信号会不断改变权值W的取值,从而引起网络输出的不断变化,当变化最后消失时,网络达到平衡状态,即分类过程达到收敛。

图2 样本T6特征的提取实验图
BP神经网络分类器具有良好的自适应和自学习能力,易构建、容错强;缺点是收敛速度慢,极易出现“过拟合”现象和跳入局部极值等。
3.2 L-M优化算法
针对传统BP神经网络算法存在的问题,提出了很多优化算法,如自适应学习速率算法、自适应变异粒子群法、遗传算法、附加动量法、误差函数修正法等[13]。经对比,文中采用L-M(Levenberg-Marquardt)学习算法对其进行优化。L-M学习算法实质上是梯度下降法与高斯-牛顿法的折中。在网络训练学习过程中,梯度下降法在前几步时下降迅速,接近最优值的过程中其梯度趋于0,此时目标函数缓慢下降甚至停顿;而在接近最优值时牛顿法可生成一个较好的搜索方向:
S(X(k))=-(H(k)+λ(k))-1f(x(k))
令n(k)=1,则X(k+1)=X(k)+S(X(k))。开始时,λ取一个较大值,对应于小步长的梯度下降法;在接近最优值时λ减少至0,S(X(k))从梯度为负的方向转至牛顿法的方向。
L-M的权值调整率为式(13)[14]:
ΔW=(JTJ+μI)-1·JTe
(13)
式中:μ是标量;J为误差对权值导数的Jacobian矩阵;e是一误差矢量。
文中拟将L-M算法优化的BP神经网络用于茶叶茶梗的识别分类。
4 实验结果与分析
实验将茶叶茶梗各200个样本送入BP网络进行训练,将余下的200个茶叶茶梗送入训练完的BP网络进行测试。对经过预处理的样本图像提取其形态学特征。为了加快训练网络的收敛速度,对这些提取的特征数据利用式(14)进行简单归一化处理。
(14)
经式(14)归一化前后的样本特征值分别见表1和表2。

表1 归一化前后样本的特征数据(1)
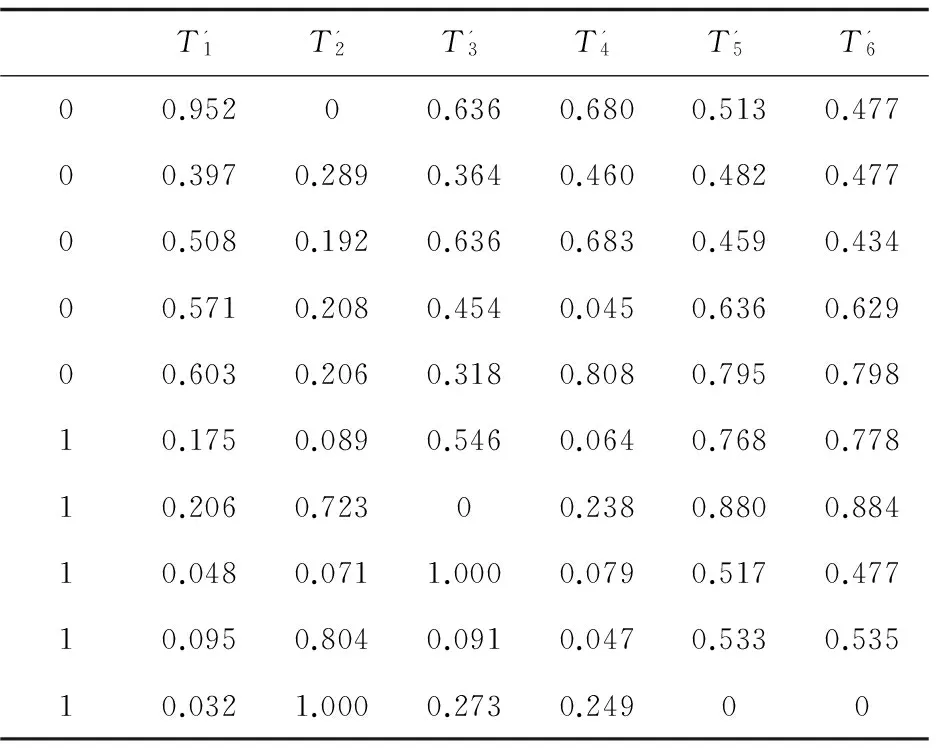
表2 归一化前后样本的特征数据(2)
注:由于篇幅所限,只列举茶叶茶梗各5组特征值。
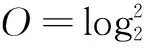
(15)
式中:m为BP网络输入层节点数;n为BP网络输出层节点数;h为BP网络隐含层节点数;a∈(1,2,…,10)。
实验证明,文中隐含层节点数h取5时,两者的分类性能最好。
茶叶茶梗分类的BP神经网络结构如图3所示。
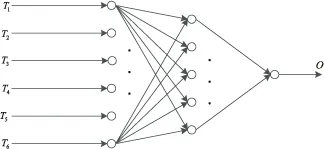
图3 茶叶茶梗分类的BP网络结构示意图
将归一化处理后茶叶茶梗样本的6组特征值输入BP网络,茶叶和茶梗的类别代号则作为BP神经网络的输出。运用Matlab2014a中的神经网络工具箱,建立BP神经网络,训练步长设为1 000步,训练误差设为0.01,学习速率取0.5。传统的BP网络与L-M学习算法优化后的BP网络对茶叶茶梗样本训练误差曲线分别如图4所示。
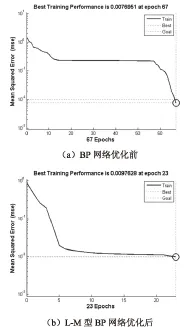
图4 BP网络优化前后茶叶茶梗样本训练误差曲线
将训练好的L-M优化的BP网络对余下200个测试样本进行测试,其中茶叶茶梗正确识别个数分别为96个和94个。测试样本的网络仿真分类见表3。

表3 L-M型BP网络对茶叶茶梗的分类识别结果
注:由于篇幅所限,文中只列举茶叶茶梗各10组测试样本的识别结果。
根据上文所述的分类方法可知,表3中序号2,4,6,9,10,11,14,16,17,19被识别为茶叶,其余序号的测试样本被识别为茶梗。
实验结果表明,经过L-M算法优化的BP神经网络系统对茶叶茶梗的区分性很强,基本上不存在分类模糊的现象,茶叶茶梗的有效识别率高达95%左右。经L-M优化型BP网络对茶叶茶梗的识别分类结果如图5所示。

图5 L-M型BP网络对茶叶茶梗识别分类结果
文中对茶叶茶梗样本库分别采用最小距离分类器、最小错误率贝叶斯分类器、传统SVM分类器、传统BP神经网络分类器4种分类方法与文中提出的L-M型BP网络分类器进行多次重复的茶叶茶梗分类实验,以样本平均分类正确率和平均耗时为验证指标,结果见表4。
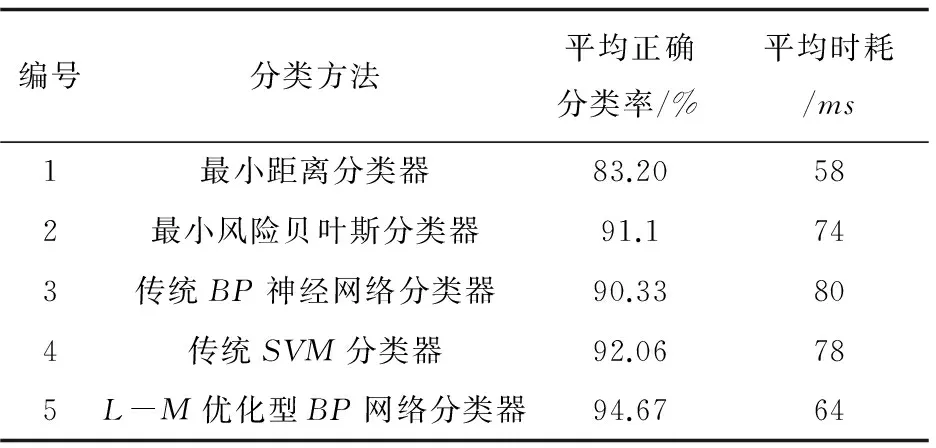
表4 5种分类方法对茶叶茶梗的分类结果
5 结束语
文中针对现有的茶叶拣梗设备中单一的颜色特征判别标准及传统BP神经网络分类器的局限性,采用L-M学习算法优化BP网络并提取茶叶茶梗的形态学特征作为BP网络的输入参数完成分类。仿真结果表明,与现有茶叶茶梗分类方法相比,茶叶茶梗形态学特征较之颜色特征不易受环境等因素的影响,且提取简单。经L-M优化后的BP网络收敛速度快、耗时少,识别精度高达95%,对茶叶茶梗的在线分类有一定的参考价值。
[1] 冯 超.基于多波长的LED荧光系统在茶叶种类和等级方面的研究[D].杭州:浙江大学,2013.
[2] 陈 笋.基于多特征多分类器组合的茶叶茶梗图像识别分类研究[D].合肥:安徽大学,2014.
[3]MuChengpo,WangJiyuan,YuanZhijie,etal.TheresearchoftheATRsystembasedoninfraredimagesandL-MBPneuralnetwork[C]//ProcofICIG.[s.l.]:IEEE,2013:801-805.
[4]PunT.Entropicthresholding:anewapproach[J].ComputerGraphicsandImageProcessing,1981,16(3):210-239.
[5] 张俊峰.基于统计形状特征的茶叶梗分离与识别[D].合肥:安徽大学,2012.
[6] 张春燕,陈 笋,张俊峰,等.基于最小风险贝叶斯分类器的茶叶茶梗分类[J].计算机工程与应用,2012,48(28):187-192.
[7] 沈国峰,程筱胜,戴 宁,等.基于L-M算法优化BP神经网络的储粮害虫分类识别研究[J].中国制造业信息化,2012,41(7):76-80.
[8] 蒋建国,宣 浩,郝世杰,等.最小描述长度优化下的医学图像统计形状建模[J].中国图象图形学报,2011,16(5):879-885.
[9]DaugmanJG.Highconfidencevisualrecognitionofpersonsbyatestofstatisticalindependence[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,1993,15(11):1148-1161.
[10] 文华荣,李 秩,冯 一,等.基于不变矩和改进BP神经网络的目标识别[J].光电技术应用,2013,28(4):49-54.
[11] 刘雄飞,朱盛春.车牌字符多特征提取与BP神经网络的识别算法[J].计算机仿真,2014,31(10):161-164.
[12]ZhaoQuanhua,SongWeidong,SunGuohua.TherecognitionoflandcoverwithremotesensingimagebasedonimprovedBPneutralnetwork[C]//ProcofICMT.[s.l.]:IEEE,2010.
[13] 苏 超,肖南峰.基于集成BP网络的人脸识别研究[J].计算机应用研究,2012,29(11):4334-4337.
[14] 王建梅,覃文忠.基于L-M算法的BP神经网络分类器[J].武汉大学学报:信息科学版,2005,30(10):928-931.
A Tea and Tea-stalk Classification Method of L-M Optimized BP Network
WU Zhe1,LIU Xiao-xing2,ZHENG Li-xin1,ZHOU Kai-ting2
(1.College of Engineering,Huaqiao University,Quanzhou 362021,China; 2.College of Information Science and Engineering,Huaqiao University,Xiamen 361021,China)
Traditional tea and tea-stalk sorting method exists problems that color feature extraction for sample is single in feature extraction aspect and general classifier has low precision and large time consuming.In term of digital image of tea and tea stems collected by CCD camera,according to different shape features between them,firstly after binarization,open and close operation,sample image denoising,image segmentation and other pre-processing process,it extracts circularity,rectangularity,extensibility,Hu second-order moment invariants,and the ratio of maximum inscribed circle and its area,etc in this paper,which has great distinction and independence,as the input vector of BP (Back-Propagation) neural network.It also applies L-M (Levenberg-Marquardt) learning algorithm to optimize the traditional BP neural network for the classification of tea and tea stalk.Experiment and simulation results proves that the BP network classifier optimized by L-M algorithm is as high as 98% on classification accuracy for tea and tea-stalk,and has relatively few time-consuming.It is an effective classification method of tea and tea-stalk.
morphological features;L-M learning algorithm;BP network;classification of tea and tea-stalk
2015-07-09
2015-10-14
时间:2016-03-22
福建省科技新平台建设项目(2013H2002);泉州市开发项目(2011G74)
吴 哲(1991-),女,硕士研究生,研究方向为光电信息检测与智能运算、机器视觉;郑力新,博士,教授,硕士研究生导师,研究方向为运动控制与机器视觉;周凯汀,副教授,硕士研究生导师,研究方向为图像处理和模式识别。
http://www.cnki.net/kcms/detail/61.1450.TP.20160322.1520.058.html
TP391.9
A
1673-629X(2016)04-0200-05
10.3969/j.issn.1673-629X.2016.04.044
猜你喜欢
茶叶通讯(2022年2期)2022-11-15
现代电力(2022年2期)2022-05-23
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
创造(2020年5期)2020-09-10
电子制作(2019年19期)2019-11-23
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2019年24期)2019-02-23
快乐语文(2018年36期)2018-03-12
电子技术与软件工程(2017年14期)2017-09-08
