
改进的中心向量算法在农业信息分类中的研究
2016-02-23 06:29赵新苗冯向萍李永可
计算机技术与发展 2016年8期
赵新苗,冯向萍,李永可
(新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830052)
改进的中心向量算法在农业信息分类中的研究
赵新苗,冯向萍,李永可
(新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830052)
自21世纪以来,农业信息网站开始迅速增加。为了给广大农民朋友和农业科研人员提供方便,需要对农业信息进行分类。将农业信息进行分类有利于农业信息的获取和管理,农业分类的方法有很多种,其中中心法分类相对简单且卓有成效。中心向量计算方法是中心法分类的核心,文中实验目的在于找出效率较高的中心向量计算方法来提高分类的准确率。目前文本类的中心向量计算多数是由该类别文本特征向量的简单算术平均得到的,这样计算得出的中心向量往往会有模型偏差,以至于不能得到很好的分类效果。为解决这个问题,使用总和法、均值法和归一化法计算中心向量,并进行对比实验,结果表明归一化法在查准率、查全率和F1测度都有较好的表现。
农业信息;分类;中心法;中心向量;文本特征向量
0 引 言
自21世纪以来,在信息技术迅猛发展的强劲推动下,农业信息化进程明显加快。计算机科学在农业信息领域中发挥着重大作用,农业信息网站开始迅速增加,为广大的农民朋友和农业科研人员提供了极大的方便,但是在众多农业信息中要寻找到自己所需要的信息却面临着极大的挑战。因此如何有效地对农业信息进行分类管理,方便信息的查找成为农业信息化亟待研究的重要领域。
目前使用的网页分类算法主要有KNN算法、朴素贝叶斯算法、支持向量机算法和中心法。KNN(K-最邻近算法)最初由Cover和Hart于1968年提出,金一宁等使用该方法对中文网页进行分类,最终分类的准确率达到80%以上[1];江小平等采用分布式编程的朴素贝叶斯算法对中文网页文本进行分类,其识别率达到86%[2];李琼等使用改进的支持向量机算法对文本进行分类,在一定程度上提高了识别的准确率[3]。
中心法是一种相对简单并且高效的文本分类算法,但是其需要满足一个条件,即待分类向量与它所属文本类别的中心向量相似度要大于其他的类别。因此中心法的准确率在很大程度上依赖于中心向量的计算方法,目前类别的中心向量是由该类别文本特征向量的简单算术平均得到的,但是对于各个类别的文本往往是很分散的,空间上也有和其他类别重叠的区域,这样计算出来的中心向量往往会有模型偏差,以至于不能得到很好的分类效果。
针对上述偏差,文中提出一种改进的中心向量计算方法,并进行了实验对比。
1 农业信息网站的现状与研究
1.1 农业信息网站的现状与分类标准
目前国内农业信息资源的建设在总体上存在缺乏专业特色、信息资源缺乏多样性、信息共享和开放程度较低,以及信息的时效性较差等问题。并且在农业信息资源建设方面缺乏科学权威的农业信息搜索引擎,现代先进的信息科学技术还未得到广泛的应用。现代信息科学技术在农业信息资源建设中的作用需要得到重新认识和足够重视,同时还需要加强对关键技术的研究,如信息自动采集与发布技术、农业信息分类检索技术、网络数据库技术等[4]。
虽然先后在农业领域颁布了1 064个国家标准,却没有全面的农业信息分类国家标准。根据农业信息分类的原则,将农业信息分为四级,其中包括一级分类8项,二级分类42项,三级分类192项,四级分类1 136项[5]。文中使用一级分类标准,具体为林业、种植业及制品、渔业、园林、畜牧业、农业生产资料、农业机械、植物病理共八类。
1.2 农业信息网页分类流程
文中从各大农业网站上获取与农业信息相关的网页样本进行人工标注,并且将标注样本分为训练集和测试集。先进行文本预处理去除文档标签及非中文字符;然后对网页内容进行中文分词,去除停用词;再进行特征词提取,并且构建特征向量;最后构建文本类的中心向量分类器,使用中心法对测试集网页进行测试,进行性能评估。中文农业信息网页分类流程如图1所示。

图1 农业信息网页分类流程
2 主要技术简介
文中使用到的技术主要是分词方法、特征提取、特征加权、中心法。
(1)分词。
对于中文网页分类,分词是很重要的基础。使用高效率的分词方法能够在很大程度上提高网页分类结果的准确性[6]。文献[7-8]对多种分词方法进行了比较,结果表明庖丁解牛分词器从分词效果、性能、准确率方面都表现良好。文中选择庖丁解牛分词器。
(2)特征提取。
在文本分类领域,目前比较常用的特征提取方法有:文档频率(Document Frequency,DF)、互信息(Mutual Information,MI)、期望交叉熵(Expected Cross Entropy,ECE)、信息增益(Information Gain,IG)和X2统计方法(CHI-square,CHI)等。
特征提取的质量将在很大程度上决定分类效果的效率与优劣,因而寻找有效的特征提取方法,不仅能降低文本特征向量的维数,而且可以抑制干扰词语对分类的影响,从而提高分类精度[9]。文献[10-11]对这几种方法都进行了不同程度的介绍,并针对不同的中文语料集通过实验进行分析比较。实验结果表明,CHI分类效果较好,且在样本数据分布不平衡或是样本数据差异较大等情况下,同样表现稳定。文中选择CHI作为特征提取的方法。
(3)特征加权。
特征集合中不同的特征词对样本文档的重要程度和区分度不同,所以需要对特征集合中的所有特征词进行赋权重处理。常用的加权算法有:布尔权重(BooLean,BL)、词频权重(TermFrequency,TF)、倒文档权重(InverseDocumentFrequency,IDF)和TFIDF权重(TermFrequency,InverseDocumentFrequency)等等[12]。
TFIDF权重规避了TF权重与IDF权重的缺点,将两种权重算法结合起来,寻求一种折中[13]。即将以下两种思想综合考虑:特征词t在样本集中的文档频率df(t)越高,词语t越不重要;特征词t在文档di中出现频率越高,词语t越重要。因此文中选择了TFIDF方法进行特征权重的计算。
(4)中心法。
中心法文本分类的思想是:对于每个已知的类别i都存在一个类别的中心向量Ci,这个中心向量为该类别的代表向量。当需要对一个未知类别文本分类时,把文本向量d和每个类别的中心向量Ci进行对比,通过最大相似度确定该文本类别。但是,中心法分类需要满足一个条件,即待分类向量与它所属于的向量相似度要大于其他的类别,但是数据分布是有偏差的,这些偏差会导致判断失误,如图2所示。

图2 中心法偏差图
如图2所示,C1和C2分别为两个类别,但是如果属于C1类别的待分类文本位于两个类别中心右侧的位置,那么模型会将其判断为C2类别,因为这样待分类文本距离C2距离较近,若是如此将会出现偏差。
为了解决这一问题,进行两点改进:一是修改中心向量的计算方法,使中心向量更具有显著性和通用性;二是在中心法分类中尽量选择更加合适的相似度计算方法。
通过以上分析,文中将尝试使用不同的中心向量计算方法:均值法、总和法和归一化法。分别对这些方法得到的结果进行评估,以确保中心法有更好的表现。
3 实验设计
3.1 样本的选取及处理
(1)样本的选取。
由于目前国内尚无关于农业网页的开放语料库,文中的农业信息网页样本主要来源于国内农业相关网站。下面将简单介绍样本的选取和处理。
首先,从各大农业网站上抓取林业、种植业及制品、渔业、园林、畜牧业、农业生产资料、农业机械、植物病理农业相关的网页,选取18 000张网页。然后,组织30名学生每组3人共10组,每组标记1 800张网页,每组三人对相同的1 800张网页分别进行标记,标定结果写入到结果表中。对每1张网页3人标记相同时,才判定该网页类别,不同则重新标记,标记结果差异数据统计见表1。
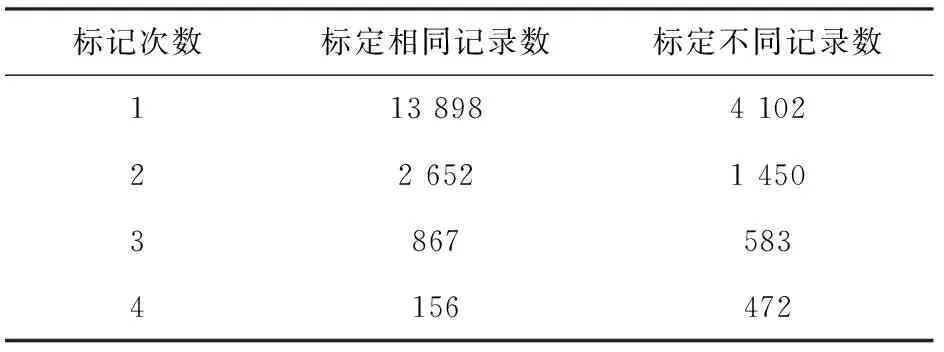
表1 数据标记差异统计
去除无法确定类别的剩余472条记录。对分类结果进行数据统计,见表2。

表2 分类结果统计
取其中每类70%作为训练样本集,其他每类30%作为测试样本集。最终得到训练样本集共12 270个样本,测试样本集共5 258个样本。
(2)样本的处理。
首先,对样本进行分词,去除停用词,提取特征词。提取特征词使用的方法是CHI,公式如下:
(1)
其中,N为训练集中的文档总数;A为属于类别Ci且包含特征词t的文档频数;B为不属于类别Ci但包含特征词t的文档频数;C为属于类别Ci但不包含特征词t的文档频数;D为不属于类别Ci也不包含特征词t的文档频数。
(2)
其中,w为使用TFIDF计算各项特征的权重。
(3)
其中,tfij为特征词tj在文档di中的词频权重;df(tj)为特征词tj在样本集中的文档频率。
然后,计算出每类样本的中心向量,三种中心向量计算方法如下所示。
均值法计算公式为:
(4)
总和法计算公式为:
(5)
归一化法计算公式为:
(6)

最后,使用欧氏距离计算待分类样本与各类中心向量的相似度,待分类样本与某类的相似度最高即属于该类。
欧氏距离公式为:
(7)
3.2 实验方案
中心法分类中需要两步:第一步是训练阶段,即使用已给定的样本标记集合生成具有分类能力的中心向量分类器;第二步是分类阶段,即使用训练阶段生成的分类器对未知类别样本进行分类,确定其所属的类别。
(1)训练阶段。
①将从农业网站上获取的农业网页进行预处理,去除文档标签。
②使用庖丁解牛分词器对中文文本进行中文分词和去除停用词等操作。
③使用X2统计提取出对分类贡献较高的特征词,将每篇文档用一个特征词集的向量表示。

(2)分类阶段。


4 实验结果
4.1 分类器性能评估
评估分类准确程度的依据是通过对网页分类结果与人工分类结果进行比较,结果越相近,分类的准确程度就越高。国际上通用的评价指标有:查准率(Precision,P)、查全率(Recall,R)和F1测度[14]。
假设A、B、C、D含义如下:A表示样本集中原本是正例,被模型判断为正例的样本数;B表示样本集中原本是正例,却被模型判断为反例的样本数;C表示样本集中原本是反例,被模型判断为反例的样本数;D表示样本集中原本是反例,却被模型判断为正例的样本数。
查准率评价指标公式为:
(8)
查全率评价指标公式为:
(9)
F1测度是对查准率和查全率两个指标进行加权和平均后形成的一个综合指标。公式为:
(10)
4.2 结果与分析
实验首先通过人工标记的方式选取出了17 528篇网页作为实验数据来源。这些网页来源于各大农业网站,其中包含:种植业及制品(2 895篇)、渔业(1 976篇)、园林(2 597篇)、畜牧业(1 589篇)、农业生产资料(2 487)、农业机械(1 892篇)、植物病理(1 934篇)、林业(2 158篇)。将这些网页的70%作为训练样本,30%作为测试样本,如表3所示。
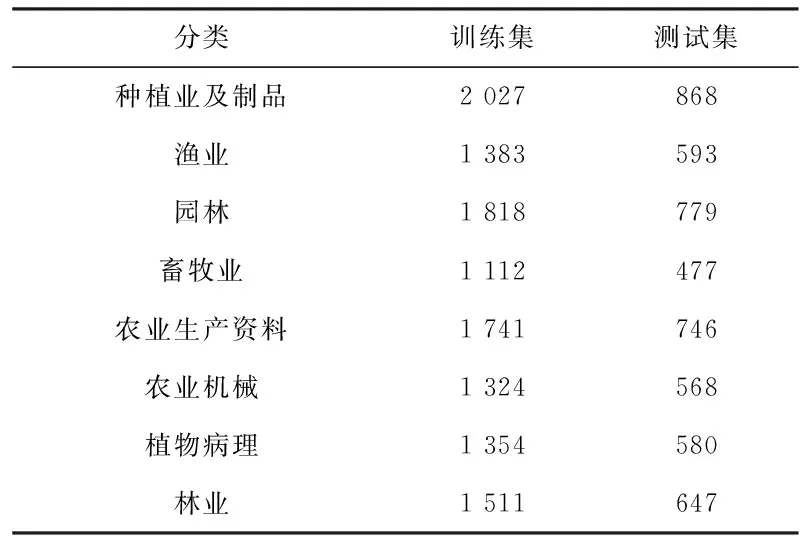
表3 训练集和测试集划分表
分别对基于总和法、均值法、归一化法三种不同的中心向量计算方法的中心法进行测试,测试指标包括:查准率(P)、查全率(R)、F1测度。测试结果如表4~6所示。
每一类文章经过预处理、特征提取、特征加权后会变成一个矩阵,每一行代表一篇文章,每个值代表特征词的重要性。总和法是指将同一类的所有文章特征向量进行求和运算,最后得到的和向量即为该类的中心向量;均值法是在总和法的基础上取得和向量的平均值,由实验结果得出,均值法在查全率、查准率和F1测度上比总和法高出了5%左右;归一化法是为了消除指标之间的量纲影响,由实验结果得出,归一化法在查全率、查准率和F1测度上比总和法高出了10%左右,比均值法高出了5%左右。
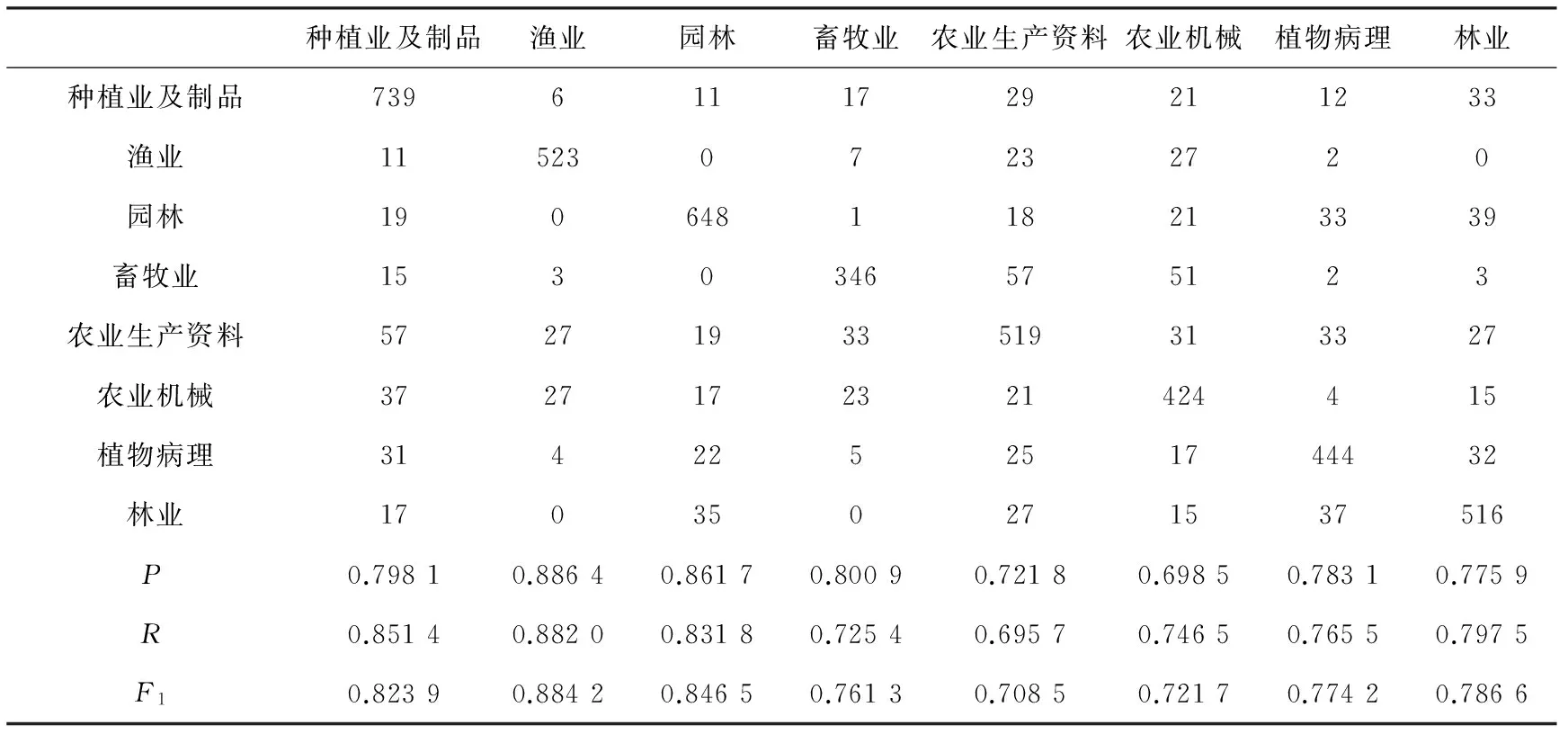
表4 总和法计算中心向量的中心法分类结果

表5 均值法计算中心向量的中心法分类结果

表6 归一化法计算中心向量的中心法分类结果
通过测试结果可以发现,农业生产资料和农业机械分类结果在查全率、查准率和F1测度上表现的都比较差,原因可能是因为这两类与其他类具有一定的关联性,所以导致分类结果与其他相比较低。
实验结果表明,改进后的使用归一化方法计算中心向量的中心法的测试结果优于总和法和均值法,几乎各项指标都达到了80%。由此可以推断出改进中心向量的计算方法对中心法的改良起到了一定的作用,得到的分类结果更好,准确率更高。
5 结束语
文中采用中心法对农业信息网页的分类进行了研究,实验结果表明归一化法计算中心向量对于农业信息网页的分类判别有着较高的准确率。下一步将继续调整中心向量的算法以及相似度算法,从而进一步提高模型在农业信息网页分类中的准确率。与此同时探索其他文本分类方法,并设计对比实验,以获得更佳的农业信息网页分类模型。
[1] 金一宁,王华兵,王德峰.基于KNN及相关链接的中文网页分类研究[J].哈尔滨商业大学学报:自然科学版,2011,27(2):203-207.
[2] 江小平,李成华,向 文,等.云计算环境下朴素贝叶斯文本分类算法的实现[J].计算机应用,2011,31(9):2551-2554.
[3] 李 琼,陈 利.一种改进的支持向量机文本分类方法[J].计算机技术与发展,2015,25(5):78-82.
[4] 胡金有,张 健,游龙勇.我国农业信息网站现状分析[J].农机化研究,2005(6):38-40.
[5] 王 健,甘国辉.多维农业信息分类体系[J].农业工程学报,2004,20(4):152-156.
[6]FengXia,TangXianchao.Animproveddictionary-basedchinesewordsegmentationapproachinLucene[C]//Proceedingsof2010internationalconferenceonservicesscience,managementandengineering.[s.l.]:[s.n.],2010.
[7] 孙殿哲,魏海平,陈 岩.Nutch中庖丁解牛中文分词的实现与评测[J].计算机与现代化,2010(6):187-190.
[8]ZhangQun,ChengYu.ResearchonChinesewordsegmentationalgorithmbasedonspecialidentifiers[C]//Proceedingsofthe2011internationalconferenceoncomputing,informationandcontrol.[s.l.]:IntelligentInformationTechnologyApplicationAssociation,2011.
[9] 王霜霜,张太红,冯向萍,等.农业网站导航页面识别模型研究[J].新疆农业大学学报,2011,34(5):447-453.
[10] 苏金树,张博锋,徐 昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1859.
[11]WangBingkun,HuangYongfeng,YangWanxia,etal.Shorttextclassificationbasedonstrongfeaturethesaurus[J].JournalofZhejiangUniversity-ScienceC(Computers&Electronics),2012(9):649-659.
[12]ZhangYuntao,GongLing,WangYongcheng.AnimprovedTF-IDFapproachfortextclassification[J].JournalofZhejiangUniversityScienceA(ScienceinEngineering),2005,6A(1):49-55.
[13] 张保富,施化吉,马素琴.基于TFIDF文本特征加权方法的改进研究[J].计算机应用与软件,2011,28(2):17-20.
[14] 宋枫溪,高 林.文本分类器性能评估指标[J].计算机工程,2004,30(13):107-109.
Research on Improved Center Vector Algorithm in Agricultural Information Classification
ZHAO Xin-miao,FENG Xiang-ping,LI Yong-ke
(College of Computer and Information Engineering,Xinjiang Agricultural University,Urumqi 830052,China)
Since twenty-first century,the site of agricultural information has increased rapidly.In order to provide the convenience for farmers and agricultural researchers,it is need to classify agricultural information.The classification of agricultural information is favor of acquisition and management of the agricultural information.There are several ways to classify agricultural information,in which the centroid-based classification is simple and effective.In this paper,it uses centroid-based classification to find the more efficient one to improve the accuracy of agricultural information.At present,most of the methods for calculating the center vector of the text are the average value of the text feature vector.This method can’t get a good classification results due to the model deviation for center vector obtained.In order to solve this problem,the sum method,means method and normalization method is used to calculate the center vector and the result of three methods are compared.The results show that the normalization method has better performance in Precision,Recall andF1measure.
agricultural information;classification;centroid-based method;center vector;text feature vector
2015-11-19
2016-03-04
时间:2016-08-01
新疆维吾尔自治区高技术研究发展计划项目(2015X0103)
赵新苗(1990-),女,硕士研究生,研究方向为数据库技术;冯向萍,副教授,研究生导师,通讯作者,研究方向为数据库技术及应用。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0842.020.html
TP
A
1673-629X(2016)08-0146-06
10.3969/j.issn.1673-629X.2016.08.031
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年9期)2021-10-11
成都信息工程大学学报(2021年6期)2021-02-12
少儿画王(3-6岁)(2020年4期)2020-09-13
现代信息科技(2020年18期)2020-02-22
计算机技术与发展(2018年8期)2018-08-21
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
计算机应用与软件(2018年1期)2018-02-27
电子制作(2017年2期)2017-05-17
