
一种基于TextRank的文本二次聚类算法
2016-02-23 06:28潘晓英胡开开
计算机技术与发展 2016年8期
潘晓英,胡开开,朱 静
(西安邮电大学 计算机学院,陕西 西安 710121)
一种基于TextRank的文本二次聚类算法
潘晓英,胡开开,朱 静
(西安邮电大学 计算机学院,陕西 西安 710121)
针对传统文本聚类技术中存在的聚类精度一般或者运算时间复杂度过高等问题,文中首先介绍了两种较为常用的文本聚类技术:基于划分的K-means和基于主题模型的LDA。在分析各自缺陷的基础上,提出一种基于TextRank的文本二次聚类算法。该算法借鉴主题模型的思想,在传统的聚类过程中引入词聚类,并在关键词提取阶段融合词语的位置与跨度特征,减少了由局部关键词作为全局关键词带来的误差。实验结果表明,改进后的算法在聚类效果上要优于传统的VSM聚类和基于主题模型的LDA算法。
文本聚类;TextRank;
提取;向量空间模型;LDA
1 概 述
随着大数据时代的来临,互联网上的文档数据呈爆炸式增长,如何从这些海量数据中获取有效信息已经成为NLP(Nature Language Processing,自然语言处理)领域的重点[1]。作为数据挖掘领域的重要分支,聚类技术被广泛研究。一种快速、高效的聚类算法能够自动地将看似杂乱无章的文档数据集合组织成少量的有意义的簇,进而以简明、容易访问的方式提交结果[2]。因此,聚类技术在文本挖掘、Web搜索以及新闻推荐系统等领域中发挥着重要作用[3]。
目前针对文本聚类的方法主要分为两类:
第一类是向量空间模型[4](Vector Space Model,VSM)。这类算法以关键词权重信息来构建文档向量,根据所采用的某种相似度度量计算文档之间的“距离”,随后采用K-means进行聚类。VSM中最常见的词加权方式是TF-IDF[5](TermFrequency-InverseDocumentFrequency,词频-逆文档频率),但是该模型的缺陷是模型假设各个词的出现是独立不相关的,导致无法从语义上分析文档内容。马晖男等[6]提出了一种修正的向量空间模型(MVSM)。该模型采用信息短语进行信息表示,对查询索引项进行扩展,并建立了能够自动生成的同义词词典,有效改善了文本信息检索系统的性能。宋丹等[7]借助自然语言理解技术,根据语义特征将文档关键词分为N维向量空间,在每个空间上进行独立的权重和相似度计算,实验结果表明该方法在新闻的话题识别和跟踪技术中要优于传统方法。相比较TF-IDF,图方法更能体现文档关键词之间的结构关系,最具代表性的是TextRank[8],该算法将文本看作是一个由词节点组成的网络,节点之间的链接权重代表了词之间的语义关系。基于TextRank的词权重排序算法同样被研究者广泛关注,其中方康等[9]提出一种基于马尔可夫模型加权TextRank的单文档关键词抽取算法,结果表明准确率有所提高。顾益军等[10]将候选关键词的重要性按照主题影响力和邻接关系进行非均匀传递,并构建新的概率转移矩阵进行词图迭代计算,可以显著改善关键词的抽取效果。
第二类为潜在狄利克雷分布LDA(LatentDirichletAllocation):是一种文档主题生成模型。即一篇文章的每个词都是以一定概率选择了某个主题,并从某个主题中以一定概率选择了某个词。处理过程中可以将数据建模为混合话题,这些话题不仅仅是文档簇,同时也是词的概率分布。该方法具备先验性假设,不易产生过拟合,更加符合实际文档的主题分布,缺点是计算复杂度较高,在大规模数据集上会遇到计算瓶颈[11]。Mimno与McCallum[12]提出一种DirichletCompoundMultinomialLDA(DCM-LDA)算法。DCM利用分布式集群进行训练,集群中的每台机器首先对分发在其上面的语料进行吉布斯采样,各自维护一个局部主题模型(LocalTopicModel),当训练完成时将所有的主题模型融合在一起,在一定程度上能解决复杂度过高的问题。张小平等[13]提出一种基于高斯函数的加权方法,降低了高频词对主题分布的影响,实验结果表明改进后的模型更能清晰地表达文档主题。李文波等[14]提出一种附加类别标签的LDA模型,即在传统LDA模型训练过程中融入文本类别信息,克服了训练过程中强制分配隐含主题的缺陷,可以有效地改进文本分类性能。
文中借鉴主题模型的思想,并充分利用word2vec[15]对于中文文本生成词向量的高效性以及精确性,提出一种基于TextRank的文本二次聚类方法。该方法在传统聚类过程中引入了词聚类,并在关键词提取阶段融合词语的位置与跨度特征,减少了由局部关键词作为全局关键词带来的误差。实验结果表明,该方法在聚类精度以及效率上均有不同程度的提高。
2 文本聚类
传统的文本聚类方法是将原始文本数据集合进行预处理,随后进行向量化并对其进行K-means聚类。具体步骤如下:
2.1 文本预处理
首先对数据进行去噪,包括剔除异常值、图片、视频、音频等记录。随后利用中文分词系统进行中文分词、去除停用词等。
2.2 文本向量化
要对文本进行聚类,首先要对文本进行向量化表示。经典的方法是用TF-IDF和TextRank来表示文本的词权重信息。TF-IDF算法的思想是,如果词在一篇文档中出现的频率高而在其他文档中很少出现,则认为该词具有很好的区分能力。TextRank算法借鉴Google网页排名方法PageRank[16],该算法利用网页之间的相互投票来迭代计算网页的重要度。具体到TextRank,即事先设定一个固定的滑动窗口大小K,将窗口内的词看作是图中的节点,同一窗口内出现的词之间通过边相连,通过不断地向后移动窗口来增加图中的边,随后通过迭代计算词的权重。对于单词i:
(1)TF-IDF的权重信息计算公式为:
(1)
其中,TFi为该词在文本中的出现频率;N为文本总数;DFi为该词出现的文本个数。取对数是为了消除在最终的词权重中TF的影响。
(2)TextRank的权重信息计算公式为:
WS(vi)=(1-d)+d×
(2)
其中,WS(vi)表示节点vi的权重;In(vi)、Out(vj)分别表示指向节点vi的集合以及节点vj所指向的节点集合;Wji表示连接两节点之间的边的权重;d为阻尼系数,取值0.85。
2.3K-means聚类
K-means[17]文本聚类的基本思想是首先从上述向量化后的数据对象中随机抽取K个对象作为初始聚类中心,随后计算剩下的对象到这些聚类中心的距离,将其分配给距离最近的类;然后重新计算每个类中新的聚类中心。重复这一过程,直至测度函数收敛。一般采用误差的平方和作为标准测度函数,其定义为:
(3)
其中,E为数据集中所有对象的误差平方和;k为聚类个数;p为给定的文本对象;Ci为簇i的中心点。
针对文本聚类,一般采用余弦相似度计算文本之间的“距离”。公式如下:
Dist(di,dj)=1-cos(di,dj)=
其中,di,dj分别表示文本i,j;n表示文本向量的维度;Pik和Pjk分别表示i和j的文本向量在第k维上的取值。
由该公式可知,若两个文本相同,则cos(di,dj)=1,即Dist()=0,二者距离最小。反之,若两个文本是“相互独立”的,则cos(di,dj)=0,即Dist()=1,二者距离最大。
基于VSM的K-means文本聚类算法的优点是实现简单,时间复杂度较低,可解释性强。但是,基于VSM的方式对文本进行向量化后无法清晰地表达文本内容,会导致聚类效果不是很好,需要进一步改进。
3 基于TextRank的文本二次聚类
针对上述聚类方法聚类精度不足的缺陷,文中提出一种基于TextRank的文本二次聚类算法,通过减少由局部关键词作为全局关键词带来的误差来增强向量化文本的表达能力。首先,利用开源深度学习工具word2vec对预处理过的文档中的词生成词向量,并进行词聚类[18]。然后,针对每篇文档,计算文档中每个词语的权重值并统计每个词所属聚类,对每一个类别下的所有词进行加权求和,得到该文档的类别特征分布,进而采用K-means算法进行第二次聚类。改进后的算法流程如图1所示。

图1 算法流程图
3.1 预处理
对文本集合进行预处理采用2.1所述的方式。
3.2 词聚类
在Linux环境下,运用word2vec工具对输入的数据进行词聚类。word2vec是Google于2013年开源推出的一个用于获取word vector的工具包,它可以将某种格式的输入文本转化为一个K维向量。这样,就可以通过计算向量之间的相似度来表示文本之间的语义相似度。
3.3 关键词权重计算
考虑到传统的TF-IDF关键词提取技术无法从语义上分析文档,故文中采用当前比较流行的图模型(TextRank)并加以改进来进行文档关键词的提取。直接利用以上公式提取出的关键词会更倾向于局部高频词和无用词,真正能代表文档的关键词却因为权值低而被召回。因此,为了提高结果的准确性和说服力,在计算关键词权值时考虑以下特征:
(1)位置。
如果文档中某候选关键词出现在了该文档的标题中,那么很明显该词作为关键词的概率要大于那些文档中未出现在标题中的词。所以,在计算词语权重时需要将位置信息考虑进来。具体计算公式为:
(5)
(2)词跨度。
在TextRank算法中,由于滑动窗口的设定,在同一窗口内会经常有若干相同词的情况,这样就会导致算法的提取结果是局部关键词而非全局关键词。为了消除这种由于词的出现范围而带来的计算误差,可将词的跨度特征也引入到关键词权重计算中。其值为该词在文档中第一次出现与最后一次出现的位置之差。如果该值较大,说明其作为全局关键词的可能较越大,从而避免了一些局部关键词被误作为全局关键词。
通过以上两个特征的引入,候选关键词i的计算公式如下:
(6)
其中,WSi是i的TextRank值;Loci是i的位置特征值;Spani是i的跨度特征值;Lasti和Firsti分别表示i在该文档中最后一次和第一次出现的位置,考虑到只出现一次词语作为文档关键字的可能性极小,为降低该词权重,文中将每篇文档中词语频度为1的Firsti取值为0,Lasti取值为1;Sum表示文档的词语总数。
按照上述权值计算过程,选取文档中的前N个词作为文档的特征关键词,将每篇文档表示成如下形式:
dj=〈〈word1j,weight1j〉,〈word2j,weight2j〉,…,〈wordNj,weightNj〉〉
3.4 统计文本类别分布
在2.2和2.3的基础上,统计文本在各个类别下的分布。具体做法如下:首先在每篇文档中选取N个词,统计每个词所属类别。然后对同一个类下的所有关键字进行加权求和并做归一化处理。得到的每篇文档的分布特征如下:
dj=〈〈C1,wj1〉,〈C2,wj2〉,…,〈Ck,wjk〉〉
其中,k为类别数目;wjk表示文档dj在Ck上归一化处理之后的权值。
3.5 二次聚类
将每篇文档按照上述方法表示成向量形式,并构建“文档-类别分布”矩阵:
其中,m为总的文档数;k为类别数量。
随后利用K-means算法对所有的文档向量进行二次聚类,得到最终的聚类结果。
4 实 验
4.1 实验语料
实验语料从搜狗文本语料库中下载,共涉及经济、军事、旅游、体育、文化和医疗六个子集,去噪后的每个子集大概包含300篇新闻文档,共计1 998篇。
4.2 评测指标
实验采用F值来衡量聚类效果。F值是一种综合平衡准确率和召回率的评价指标。一般F值越高,说明聚类的效果越好。准确率、召回率与F值的计算公式如下:
(7)
8)
(9)
(10)
其中,nij为聚类后类别为j中实际类别为i的文档数目;nj为聚类类别j的文档总数目;ni为实际类别为i的文档总数目。
4.3 实验结果
实验运行环境为Ubuntu14.04操作系统,CPU为Intel(R) Core(TM)i3-4150 3.50 GHz,4 GB内存,编程工具为Eclipse4.4.0,算法实现语言为Java,中文分词采用Ansj中文分词系统,词聚类的实现借助word2vec。
在式(5)和式(6)计算关键词权重过程中,词语位置特征权重m取值为3。为了体现该词语权重计算方法的有效性,文中将其与另外两种方法得到的关键词结果作对比。评价指标仍以K-means聚类结果的F值为准,如图2所示。
由图2可知,文中方法在关键词抽取数量为50时效果最好,且采用该计算方法聚类效果明显优于另外两种方法。原因是该方法相当于综合考虑了文档的结构和语义信息。

图2 不同关键词数量下的三种算法聚类效果
在LDA建模阶段,利用实验来确定最优的主题数N,最终结果以最高F值时的主题个数为准。参数估计采用Gibbs抽样算法[19],超参数分别取值50/N,0.01,迭代次数设置为2 000次。同样,采用实验的方法来确定词聚类过程中最优的词聚类类别数量。该过程中的具体参数设置如表1所示。由图3可知,当主题数目N=80、词聚类类别数量为100时,聚类效果分别达到最优。

表1 word2vec参数设置情况
以F值为评价标准,得到LDA的最优主题数N及word2vec生成词聚类过程中的最优词类别数量。
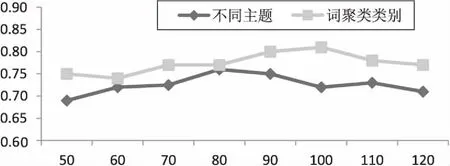
图3 不同主题/词类别的聚类效果
在上述确定最优主题数N和最优词聚类类别数量的同时,文中对两者的算法执行时间进行了对比。结果如表2所示。

表2 两种算法执行时间比较 s
由表2可知,文中方法的效率明显优于LDA。原因是LDA在训练过程中需要模拟Dirichlet过程并且不断进行参数的调整,导致算法复杂度过高。而文中算法无需训练,并且在利用word2vec进行词聚类的过程中,由于采用了哈弗曼树编码、高频词亚采样等方法,减少了算法执行时间。
实验中为了消除K-means的不稳定性带来的误差影响,将文中提出的算法与传统的基于VSM的K-means聚类算法(TF-IDF,TextRank)分别运行10次,结果取平均值,比较结果如图4所示。
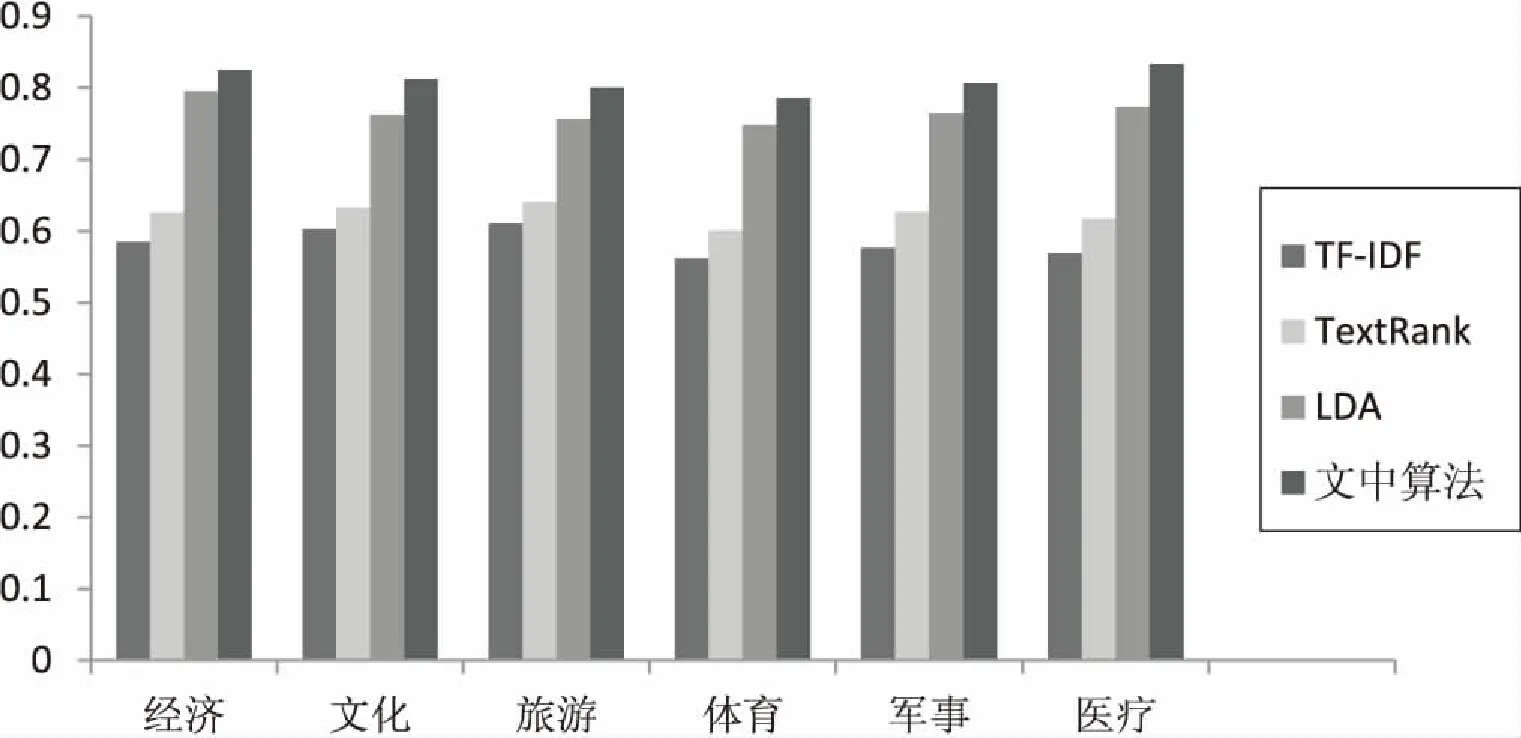
图4 四种方法比较结果
4.4 实验分析
从图4中可以看出,文中算法的全局F值相对前三种分别提高了22%,18%,5%,主要原因是文中首先充分利用了word2vec这一工具的有效性,对词进行聚类,最大程度上将语义相关的词划分到同一个类簇中,随后再进行二次聚类时融入了文档的关键词位置和跨度特征,相当于综合考虑了文档的结构和语义信息。基于VSM的方法没有考虑文档的语义信息,所以效果一般。LDA与文中算法的结果虽然相差不大,但是在算法效率有明显差距。
5 结束语
针对传统中文文本聚类算法的不足,并借鉴主体模型的思想,文中提出一种基于TextRank的文本二次聚类算法。首次聚类充分利用Google开源深度学习工具word2vec的高效性和有效性,得到词聚类集合。随后在利用图模型TextRank算法提取文档特征词阶段融入词的位置和跨度特征,使文本得到了更合理的表示,进而得到文本在词聚类类别上的混合分布,即“文档-类别”分布矩阵。二次聚类采用经典的基于划分的K-means。实验结果表明,改进算法在聚类效果和运行效率上均有所提高。
[1] 王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138.
[2] 范 明,孟晓峰.数据挖掘概念与技术[M].北京:机械工业出版社,2012.
[3] 孟宪军.互联网文本聚类与检索技术研究[D].哈尔滨:哈尔滨工业大学,2009.
[4] 姚清耘,刘功申,李 翔.基于向量空间模型的文本聚类算法[J].计算机工程,2008,34(18):39-41.
[5] 黄承慧,印 鉴,侯 昉.一种结合词语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.
[6] 马晖男,吴江宁,潘东华.一种修正的向量空间模型在信息检索中的应用[J].哈尔滨工业大学学报,2008,40(4):666-669.
[7] 宋 丹,王卫东,陈 英.基于改进向量空间模型的话题识别与跟踪[J].计算机技术与发展,2006,16(9):62-64.
[8]MihalceaR,TarauP.TextRank:bringingorderintotexts[C]//ProceedingofEMNLP.[s.l.]:[s.n.],2004.
[9] 方 康,韩立新.基于HMM的加权TextRank单文档的关键词抽取算法[J].信息技术,2015,39(4):114-116.
[10] 顾益军,夏 天.融合LDA与TextRank的关键词抽取研究[J].现代图书情报技术,2014(7):41-47.
[11] 刘知远.基于文档主题结构的关键词抽取方法研究[D].北京:清华大学,2011.
[12]MimnoDM,McCallumA.OrganizingtheOCA:learningfacetedsubjectsfromalibraryofdigitalbooks[C]//ProcofACM/IEEEjointconferenceondigitallibraries.[s.l.]:IEEE,2007:376-385.
[13] 张小平,周雪忠,黄厚宽,等.一种改进的LDA主题模型[J].北京交通大学学报:自然科学版,2010,34(2):111-114.
[14] 李文波,孙 乐,张大鲲.基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008,31(4):620-627.
[15] 周 练.word2vec工作原理及应用探究[J].科技情报开发与经济,2015,25(2):145-148.
[16]PageL,BrinS,MotwaniR,etal.ThePageRankcitationranking:bringingordertotheweb[R].[s.l.]:StanfordDigitalLibraryTechnologiesProject,1998.
[17] 孙吉贵,刘 杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61.
[18] 郑文超,徐 鹏.利用word2vec对中文词进行聚类的研究[J].软件,2013,34(12):160-162.
[19] 尤 芳.Gibbs抽样在正态混合模型中的参数估计[J].统计与决策,2013(15):150-151.
A Secondary Text Clustering Algorithm Based on TextRank
PAN Xiao-ying,HU Kai-kai,ZHU Jing
(School of Computer,Xi’an University of Posts & Telecommunications,Xi’an 710121,China)
In view of the existing problems in the traditional text clustering technology,such as the general accuracy or the higher time complexity,two kinds of the commonly used text clustering technology are introduced at first,includingK-meansbasedonthedivisionandLDAbasedonthetheme.Onthebasisoftheanalysisoftheirrespectivedefects,asecondarytextclusteringalgorithmbasedontheTextRankispresented.Referenceofideaofthememodel,thealgorithmintroducesthewordclusteringintheprocessoftraditionalclustering,andmergesthefuturesoflocationandspaninthe
extractionphase,reducingtheerrorbylocalkeywordsasglobalkeywords.TheexperimentalresultsshowthattheimprovedalgorithmontheclustereffectissuperiortothetraditionalVSMclusteringandLDAalgorithmbasedonthethememodel.
text clustering;TextRank;keyword extraction;VSM;LDA
2015-09-26
2015-12-29
时间:2016-07-29
国家自然科学基金资助项目(61105064,61203311,61373116);陕西省教育专项科研计划(14JK1667);西安邮电大学研究生创新基金项目(CXL2014-23)
潘晓英(1981-),女,博士,副教授,研究方向为数据挖掘、计算智能;胡开开(1989-),男,硕士研究生,研究方向为数据挖掘、推荐系统。
http://www.cnki.net/kcms/detail/61.1450.TP.20160729.1833.014.html
TP
A
1673-629X(2016)08-0007-05
10.3969/j.issn.1673-629X.2016.08.002
猜你喜欢
客联(2022年3期)2022-05-31
心理学报(2022年5期)2022-05-16
陶瓷学报(2021年4期)2021-10-14
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2020年17期)2020-10-28
少儿画王(3-6岁)(2020年4期)2020-09-13
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
电脑爱好者(2017年7期)2017-05-06
