
在基于IP的无线网络中提升PM IPv6的跨域切换性能
2016-02-21 06:06:50齐虹袁全庞明宝董维超
河北工业大学学报 2016年3期
齐虹,袁全,庞明宝,董维超
(1.天津电子信息职业技术学院网络技术系,天津300350;2.河北工业大学土木工程学院,天津300401;3.北华航天工业学院研究生部,河北廊坊065000)
在基于IP的无线网络中提升PM IPv6的跨域切换性能
齐虹1,袁全2,庞明宝2,董维超3
(1.天津电子信息职业技术学院网络技术系,天津300350;2.河北工业大学土木工程学院,天津300401;3.北华航天工业学院研究生部,河北廊坊065000)
PM IPv6协议,是一种基于网络的区域移动性管理协议,它是在一个局限的网络访问域中保持对移动终端的移动性支持,但传统的PM IPv6机制不能实现PM IPv6域间无缝切换.本文提出了一个预处理机制,用来管理移动终端的切换过程,保障其在PM IPv6跨网域切换过程中数据传输的连续性.这个机制引入了一种中级全局移动锚点(GLMA)实体,负责协调移动终端的切换及数据流量重定向.并通过做出一系列模拟评估实验,论述这个预处理机制在传统的PM IPv6跨域交接机制中更加有效地实现切换延时、吞吐量、协议信令成本及端到端流量交付延迟等问题.
代理移动IPv6协议;切换协调机制;切换延时;流量重定向
1 PM IPv6传统机制
PM IPv6是一款用于支持域内移动性漫游的协议,其性能及在切换性能方面的扩展性都强于PM IPv6[1-2],其传统跨域切换机制有诺依曼机制和TD机制.
诺依曼机制的提出是为了MH用户在PM IPv6网络中的域间移动时提供移动性支持[3].一旦MH进入PM IPv6访问域,它将在主LMA hLMA域内注册.同时,MH开始通过hLMA访问域获得服务,hLMA为MH域间定位认证发挥作用.而且,它在MH从之前在的当前pLMA漫游到新连接的nLMA的过程中传输MH的数据流量.TD机制意欲通过引进一种被叫做流量分配器TD的新型的网络实体来处理PM IPv6域间移动性相关信令,它负责支持MH域间移动和在PM IPv6访问域之间分配MH的数据流量.
在这2个传统机制中,移动设备切换时仍然出现切换延时长、网络数据丢包失及一些额外的移动性信令问题,这导致了MH漫游性能降低[4],不能保证PM IPv6域间的无缝的切换.
2 提升PM IPv6的跨域切换性能-GLMA机制
本文提出了一种有效的机制来支持无缝快速的MH切换.这个机制介绍了一种叫做中级全局移动锚点(GLMA)实体,主要负责协调MH的切换和保持数据会话的通畅性.GLMA将多个PM IPv6的网络访问域连接在一起并协调MH在各个域的切换工作,从而提供MH跨域移动的无缝切换服务.
GLMA将1台MH在漫游跨域之前,同时执行预域间位置注册和重域间接入认证服务[5].MH连接和从接入点断开的确切时间无法精确计算,但可以通过一些可靠的网络事件通知来反应,从而获得设备的连接状态.当相邻区域的信号强度高于本地信号强度某一给定的值(达到这个给定的值说明目前连接的信号强度将不足以维持MH的数据通信),便会触发切换服务.在这个机制中,为了更好的支持MH跨网域漫游的移动性,GLMA还使用了一种新的列表,叫做LMA缓存接入(LCE),LCE用于监控LMA群在PM IPv6管理域中的注册状态.当任何一台LMA并入或脱离这个群时,其状态会即时上传同步.为保证MH地址不被替换,GLMA在其被事件触发器提醒时预先通过查找缓存内LCE列表,向多个PM IPv6访问域邻居泛洪MH的环境信息文件.PM IPv6访问域邻居将暂时储存这些环境信息.无论何时这些预注册过的移动设备连入任意PM IPv6邻居访问域时,它都会快速收到一个RtrAdv信息,域内的MH便可快速地配置其新连入的端口,恢复通信会话.GLMA还将移动设备的数据流量重定向至其新连入的访问域.而且,为了减少网络丢包,GLMA还会在MH使用带有优化功能的缓冲技术,储存上行流量.
此机制利用额外1比特flag“G”字段加入了2个通知信息:Forward_PBU和Forward_PBAck,以启用前文移动相关性信令流.保障了MH通信会话的连续性,减少了服务的中断,提供了无缝的漫游服务.GLMA机制的信令流如图1所示.
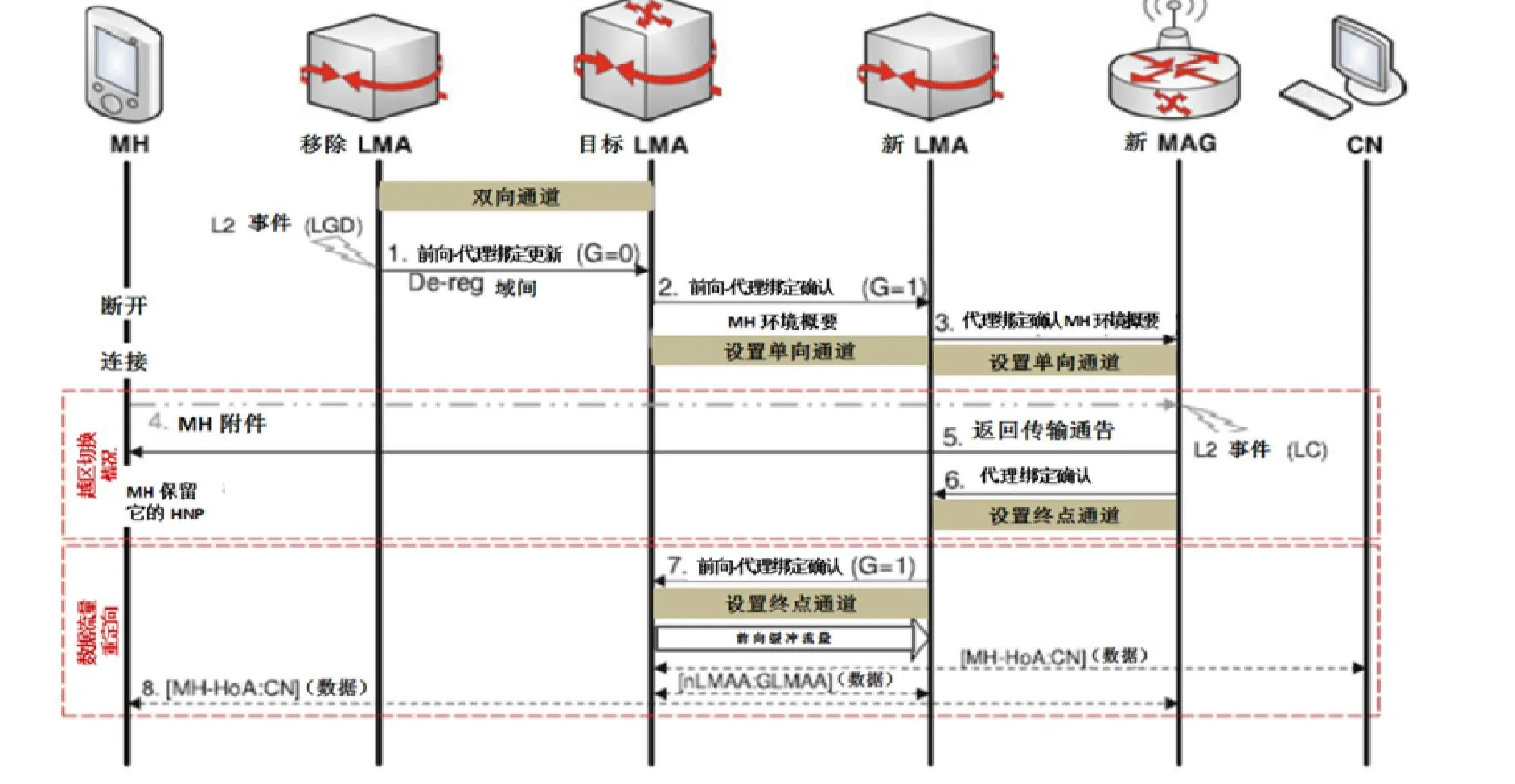
图1 GLMA的机制下的切换序列Fig.1 Handover signaling flow sequenceof theGLMAmechanism
3 新切换机制与传统PM IPv6机制的性能对比
3.1 切换延时
3.1.1 切换延时性能分析
无论何时MH发生切换时,诺依曼机制和TD机制都会频繁地调用MH域位置注册服务,并且还涉及到一些在nLMA和hLMA/pLMA之间的请求-响应信令处理过程,以此来保证MH的地址不会丢失[6].切换延时取决于从MH访问链路到接入认证完成、位置注册、获取MH地址请求-响应信令过程及向MH发送一个RtrAdv信息完成的时间.
GLMA会在MH确实移动到新的访问域之前启动一个预域间注册进程.这个进程同时处理MH的授权问题和向新的域邻居转发MH环境信息的过程.所以,这将允许在MH连入它们的访问域的瞬间启动一个快速路由推送.这样一来,本机制的切换延时将取决于从设备访问链路到一个RtrAdv信息发送至MH的时间.
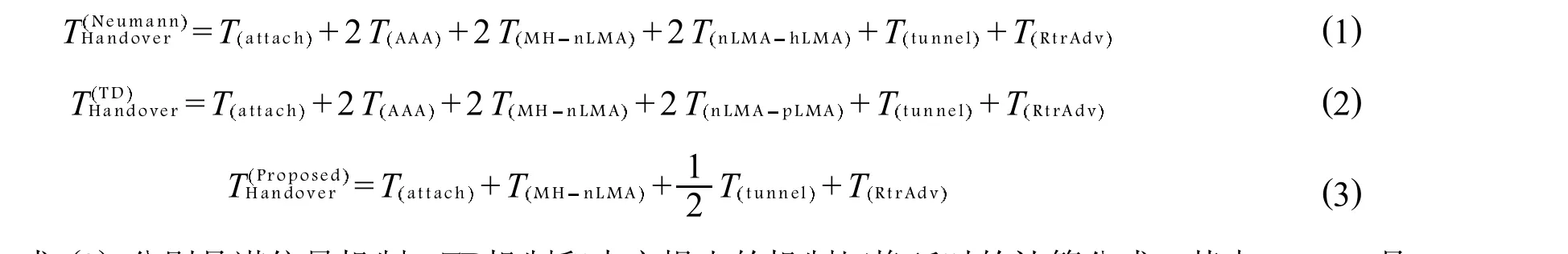
式(1)、式(2)、式(3)分别是诺依曼机制、TD机制和本文提出的机制切换延时的计算公式.其中:Tattach是MH连入新链路的时间;TAAA是MH的接入认证处理过程的时间;TnLMAhLMA和TnLMApLMA分别是为了保证MH地址不丢失,在新的LMA和主LMA及新LMA和当前LMA之间的请求-响应过程的时间;Ttunnel是建立通道的时间;TRtrAdv是收到路由推送的时间.
式(3)解释了本文提出的机制切换处理过程,即同时在GLMA和nLMA之间启动预域间注册信令和MH的环境信息转发(即保证MH地址不丢失),TGLMAnLMA为其所用时间.这个过程避免了像诺依曼机制和TD机制中nLMA与主/当前LMA之间大量的请求-响应信令.此外,nLMA与nMAG之间的接入认证的延时TAAA,建立单项通道时间(12Ttunnel)都不被算在MH的切换延时中.这是因为它们的信令产生时间都在MH漫游至新的访问域之前.同时,当MH连入nLMA链路后,nLMA也只需要一小段时间来为MH进行链路注册TMHnLMA,并建立保留端点通道(12Ttunnel),以完成对MH新的域位置的同步.
对于所有相同的给定网络拓扑,Tattach和TRtrAdv是相等的.所以,本文提出的机制的切换延时TProposedHandover比TD机制的切换延时TTDHandover短.因此,本文提出的切换机制在切换延时上的性能要远远的优于诺依曼机制和TD机制.
3.1.2 切换延时对不同无线链路延迟的影响
无线链路通常不稳定并且主要影响着端到端通信性能[7],本文针对LMA出入链路和MH间传统无线链路延迟的影响,分析PM IPv6跨域切换延时.
当MH与其CN通信时,便会发生从当前域至其它域的跨域切换.各机制下MH的跨域切换状态平均切换延时如图2所示.其中诺依曼机制和TD机制中繁琐的切换处理造成了很大的切换延时,比本文提出的机制要高的多.
一般来说,所有机制都会受到无线链路切换延时的影响,因为它们都会经常用到无线连接.当关注MH与LMA之间无线连接延迟的增加时,将会影响到MH用来接收路由推广以配置其接口地址的时间,以至于当其漫游时切换延时将会大幅增加.然而,本文提出的机制在进入切换状态后利用低级移动性相关信令来完成MH的跨域注册,以提前处理机制显示了其优秀的提升.
3.1.3 切换延时对各种域间延迟的影响
域间延时对切换延时的影响如图3所示.
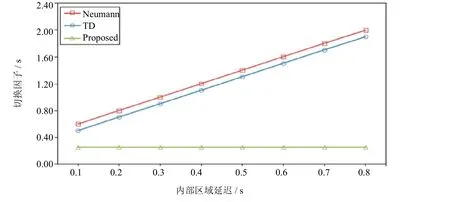
图3 不同内部域下切换延迟的影响Fig.3 Impactof thehandover latency over various inter-domain delays
在诺依曼机制和TD机制中,当主/当前访问域与新访问域之间的跨域延迟越长,切换延时就会越长[8].这是因为切换过程在MH从主/当前访问域断开连接并连入新的访问域之后才进行.此外,诺依曼机制与TD机制中的切换过程依靠的是主/当前访问域与新访问域之间有线链接额外的移动性相关信令.所以,每当域间有线链路的延迟增加时,跨域的切换延时将会更加显著的增加.
相反,本文提出的机制中跨域切换延时将大幅降低.无论域间延迟如何增长,跨域切换延时的减少是不变的,这是因为其中不包含任何主/当前访问域与新访问域之间的移动性相关信令.所以,在这个机制中,域间切换延迟与域间切换延时没有任何关系.
3.2 吞吐量
吞吐量指的是单位时间产生的所有净流量总和[9].计算当MH跨域时在其上接受到突发的吞吐量,研究切换时期对实现吞吐量的影响和MH漫游移动对不同流量源信道利用的影响.
为了得到诺依曼机制、TD机制和本文提出机制的所有吞吐行为,我们计算在MH上当其漫游跨域时对其收到的UDP流量的瞬时吞吐量.一般来说,在MH发生跨域切换时,其吞吐量便会收到相应的制约.这是因为它无法在切换的过程中接收任何数据流量.
切换过程中在MH上收到的瞬时吞吐量在3种机制中的区别如图4所示.
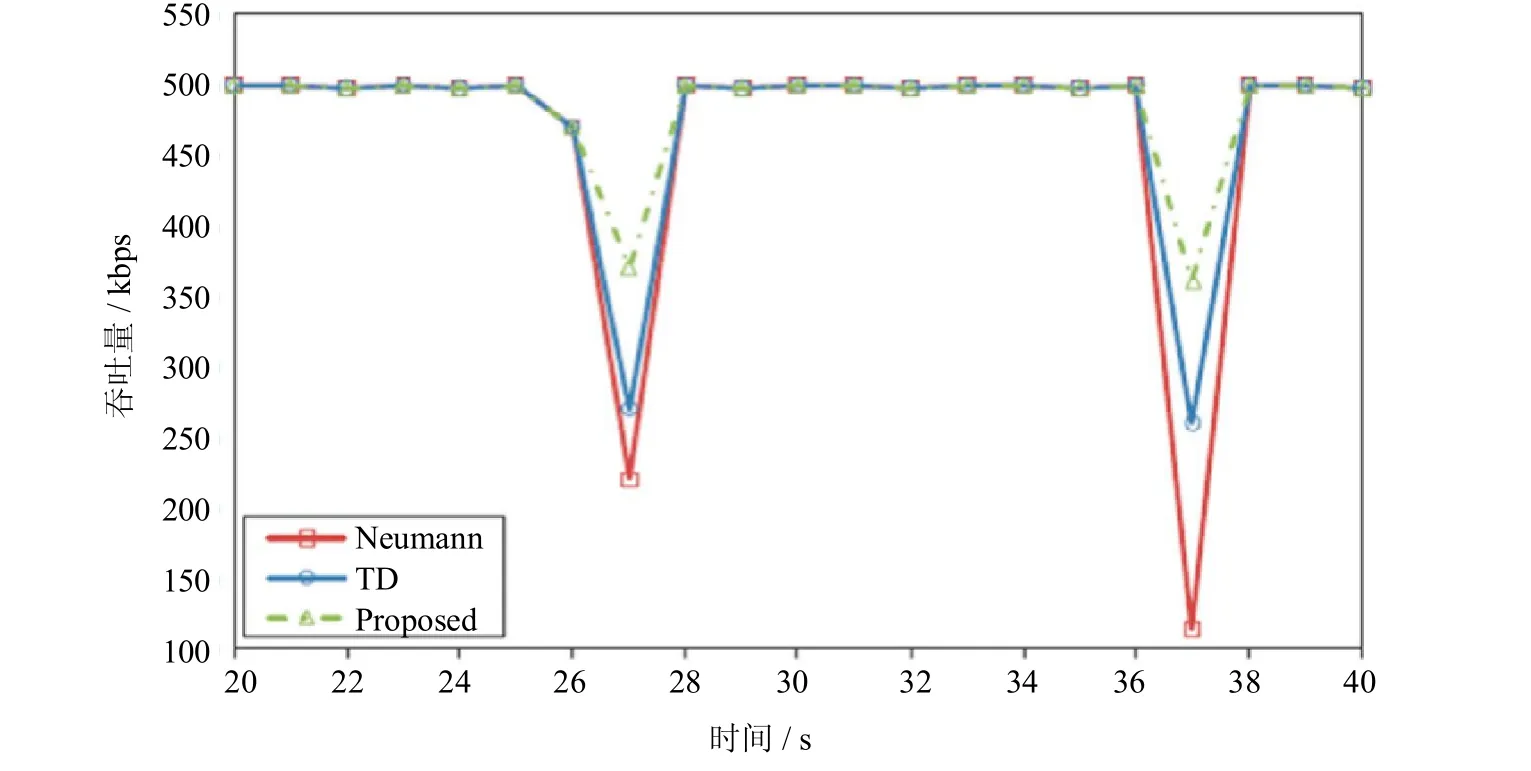
图4 UDP吞吐流量的切换延时Fig.4 Impactof handover latency for UDP throughput
在诺依曼机制和TD机制中,MH在切换过程中的上行流量会有很多丢失,造成了无法恢复的吞吐量降低.这是因为网络需要一些时间来完成一些移动性相关信令处理——MH的跨域注册、接入认证、通道建立、维持MH地址等.然而,本文提出的机制和传统机制不同,吞吐量降低的时间不需要那么长,这是因为大多数的信令在MH进入切换过程之前就已经完成.所以,这将允许MH在造成极少丢包的情况下更快地恢复其通信会话.相比传统的机制,本文提出的机制可以实现更高的吞吐量.
另一方面,如果在GLMA上启动了缓冲机制,则此机制将会在MH切换的过程中保存上行流量数据,并且在MH连入新访问域的同时将其转发.所以,这个机制实现了更低的丢包率.这样一来,它便在没有服务中断的情况下实现了更佳的流量吞吐.此外,尽管在切换过程中造成了瞬时的吞吐量下降,在切换后持续的上传缓冲的流量便有效地解决了这个问题.
3.3 协议信令成本
协议信令成本取决于额外的协议信令流量负载[10].协议信令成本按照Csignalling_cost=number×s×h/t来计算.公式中:number表示协议信令包的数量;s表示协议包的大小;h表示源到目的节点的跳数.然后,取其对时间t的平均值.
为了计算信令成本,需要确定MH跨域切换的概率.设MH在一张拓扑中跨域的概率为p,拓扑中每个访问域都具有相邻访问域的数量并且访问域总数量为N,MH的总数量为n.于是,MH位于nLMA访问域回到其LMA访问域中的概率pnLMAhLMA为p/N,MH从其hLMA访问域移动到nLMA访问域的概率phLMAnLMA为p p/N.诺依曼机制的协议信令消耗包含了对于hLMA访问域的nLMA的绑定同步信令.如式(4)所示,当其侦测到MH的连接访问时,hLMA与nLMA之间便会交换PBU和PBAck信息来完成这个信令.另一方面,TD机制的协议信令消耗包括2个阶段.首先,当MH回到其hLMA时,hLMA会向pLMA发送一个PBU_Forwarding信息并还要向所有TD实体发送一个PBU_Relay_Cancel信息.其次,当MH连接到nLMA访问域时,nLMA会向pLMA发送一个PBU_Forwarding信息并向特定的TD实体发送一个PBU_Relay_Request信息,然后,它会向由pLMA选出的TD实体(非nLMA选出的)发送PBU_Relay_Cancel信息.TD信令成本的计算公式如公式(5).

本文提出的机制协议信令成本计算如公式(6)所示.
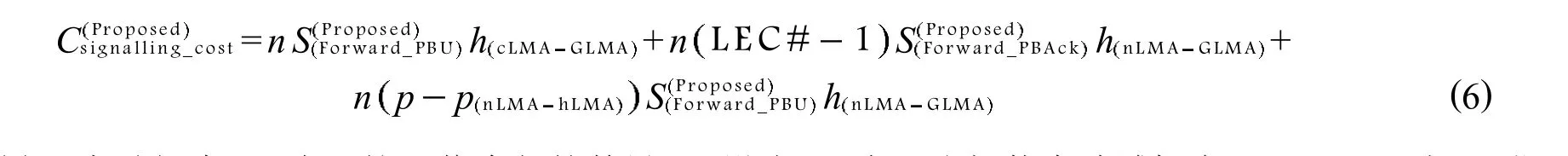
式(4)、式(5)、式(6)中:n表示协议信令包的数量;p设为MH在一张拓扑中跨域概率;pnLMAhLMA为MH位于nLMA访问域回到其LMA访问域中的概率;phLMAhLMAMH从其hLMA访问域移动到nLMA访问域的概率;SPBU表示代理绑定更新协议包大小;SPBACK表示代理绑定确定协议包大小;SPBU_Forwarding表示MH发送一个PBU_Forwarding信息协议包大小;Ack均表示与对应信息包的回应;SPBU_Relay_Request表示nLMA向特定的TD实体发送一个PBU_ Relay_Request信息协议包的大小;SPBU_Relay_cancel表示由pLMA选出的TD实体(非nLMA选出的)发送PBU_Relay_ Cancel信息;SForward_PBU表示cLMA发送一个Forward_PBU信息协议包大小;hnLMAhLMA表示MH从其hLMA访问域移动到nLMA访问域的节点跳数;hnLMATD表示MH从其hLMA访问域移动到TD实体节点跳数;hCLMAGLMA表示MH从其cLMA访问域移动到GLMA访问域的节点跳数;hnLMAGLMA表示MH从其NLMA访问域移动到GLMA访问域的节点跳数;LCE#表示缓存列表号.
在MH从cLMA访问域断开并连入到nLMA访问域中之前,cLMA会向GLMA发送一个Forward_PBU信息(flagG字段置为0).同时,GLMA会基于LCE列表向多个nLMA邻居访问域中发送Forward_PBAck信息(flagG字段置为1).然后,只要当MH连接到nLMA的访问域中,nLMA就会向GLMA发送一个Forward_PBU信息(flagG字段置为1)作为回应,以便完成MH在新访问域中的位置注册.
可以看出,这个机制的信令成本低于TD机制的.这是因为其中的预处理的跨域切换机制和在切换过程中更少的需要被执行的信令信息.
3.4 端到端流量交付延时
网络中的端到端流量交付延时指的是数据流量从源转发到目的地所用的时间.
图5说明了所有机制下的端到端流量交付流.在诺依曼机制中,原来访问域中的hLMA会收到发往MH的全部数据流量.然后它用通向nLMA访问域的通道转发这些数据流量.另一方面,在TD机制中,hLMA与MH的流量转发无关.而且凭借TD实体的帮助,流量可以在pLMA-nLMA访问域之间转发.这在MH切换直到TD选择算法完成为MH建立BCE记录期间将通过一条通道完成.然后,TD将直接把数据流量转发给nLMA[11].
相反,在本文提出的机制下,GLMA支持快速域间切换并在短暂的切换期内维持数据流量连续.这与流量传输中与hLMA、pLMA无关,是充分利用优化的缓存技术把数据流量重定向到nLMA来实现的[12].因此,本文提出的机制中,端到端流量交付延迟大大降低,同时也减少了网络丢包.
式(7)、式(8)分别呈现了诺依曼机制和TD机制中端到端流量交付延时的计算.

图5 端到端的流量交付Fig.5 End-to-end data traffic delivery flows
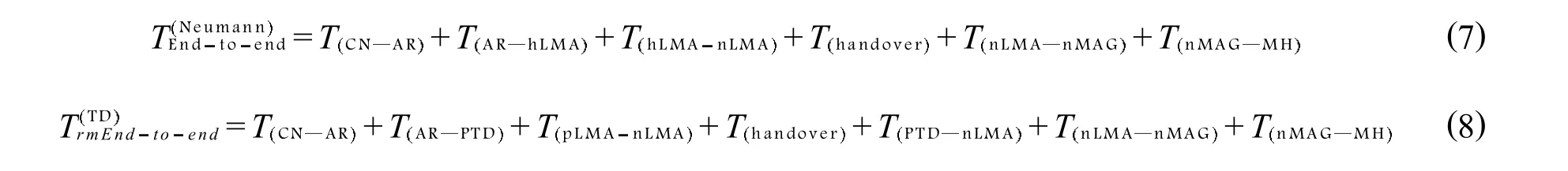
本文提出机制的端到端数据交付延时包括式(9)中呈现的替换部分.

式(7)、(8)、(9)中的T均为各节点之间的流量交付延时,需要特别说明的是其中Tbuffer为缓冲区域流量交付延时,Thandover为MH跨区切换时的流量交付延时.
所有机制中端到端流量交付延时的几个部分中的TCNAR,TnLMAnMAG和TnMAGMH在相同的网络拓扑中,正如图5所示是相等的.此外,式(8)中的TARPTD和TPTDnLMA等于公式(9)中的TARGLMA和TGLMAnLMA,因为它们遵循相同的路由线路.
为了更深入评估端到端流量交付延时,计算诺依曼机制、TD机制和本文提出的机制在单位时间内MH接收数据流量的端到端流量交付延时,如图6所示.
从这个图中能够看出本文提出的机制中平均端到端流量交付延迟会增加,但与诺依曼机制和TD机制相比增长率低很多.
4 结论
本文提出了一个低延迟的PM IPv6跨域切换机制,这个机制明显地支持了无缝的MH跨域漫游.这些都源于利用叫做GLMA的媒介作用实体预先对所有MH进行协调,并且为了无缝和快速的MH跨域切换,GLMA连接了PM IPv6访问域组[13].此外,GLMA利用优化过的流量缓冲技术,在MH跨域切换时存储了MH的上行流量并保持其数据会话通畅.所以,它提供了一个在向新的访问域转发流量时不需要包含主访问域或当前访问域的流量重定向机制.

图6 各种端到端的数据转发路径交付延迟的影响Fig.6 Impactsof the various forwarding pathsoverend-to-end data traffic delivery latency
该机制的好处:
1)支持MH在PM IPv6下跨网域漫游;
2)减少了切换延时和网络丢包;
3)减少了协议信令成本;
4)提供接入认证和MH在全网络域中切换的漫游支持;
5)改善了所有端到端流量交付延时.
因此,该机制可在基于IP的无线网络中提升PM IPv6的跨域切换性能,提高端对端服务效率,对于所有MH端到端的服务质量将很大程度的改善.
[1]GundavelliS,Leung K,DevarapalliV,etal.RFC 5213:Proxymobile IPv6(PM IPv6)[S].Reston VA,USA:InternetSociety.2008.
[2]肖文曙.基于M IPv6的移动位置管理研究[D].北京:中国科学院计算机研究所,2007.
[3]Neumann N,Lei J,Fu X,etal.I-pmip:An inter-domainmobility extension for proxy-mobile IP[J].ACM.2009,1:994-999.
[4]Kempf J.RFC 4830:Problem statement fornetwork-based localizedmobilitymanagement(NETLMM)[S].Reston VA.USA:InternetSociety.2007.
[5]Zhong F,YeoCK,LeeBS.Enabling inter-pmipv6-domainhandoverw ith traffic distributors[J].JournalofNetwork and ComputerApplications.2010,4(33):397-409.
[6]A l-Surmi I,Othman M,A li B.Mobility management for IP-based next generation mobile networks:Review,challenge and perspective[J].Journalof Network and Computer Applications,2012,35(1):295-315.
[7]Ryu S,Choi JW,Park KJ.Performance Evaluation of Improved FastPM IPv6-Based Network Mobility for IntelligentTransportation Systems[J].IEEE Trans,Journalof Communication and Networks,2013,2(15):142-152.
[8]Lee JH,ErnstT,ChilamkurtiN.Performanceanalysisof PM IPv6 based networkmobility for intelligent transportation systems[J].IEEETrans.Veh Technol,2012,1(61):74-85.
[9]CespedesS,Shen X.IPmobilitymanagementforvehicularcommunicationnetworks:Challengesand solutions[J].IEEECommunicationsMagazine,2011,5(49):187-194.
[10]延志伟,基于M IPv6/PM IPv6的移动性支持关键技术研究[D].北京:北京交通大学,2011.
[11]Lee JH,ErnstT.Lightweightnetworkmobilityw ithin PM IPv6 for transportation systems[J].IEEESyst,2011,5(3),352-361.
[12]Perkins C,Johnson D,Arkko J.RFC 6275:Mobility supportin IPv6[S].Reston VA,USA:InternetSociety.2011.
[13]ChoiJI,SeoWK,Cho YZ.Efficientnetworkmobility supportscheme forproxymobile IPv6[J].EURASIPJournalonWirelessCommunications and Networking,2015,1(3),1-13.
[责任编辑 代俊秋]
Enhancing inter-PM IPv6-domain for superiorhandover performanceacross IP-basedw irelessdomain networks
QIHong1,YUAN Quan2,PANGM ingbao2,DONGWeichao3
(1.DepartmentofNetwork Technology,Tianjin Electronic Information College,Tianjin300350,China;2.SchoolofCivilEngineering, HebeiUniversity of Technology,Tianjin300401,China;3.DepartmentofPostgraduate,North China InstituteofAerospaceEngineering, HebeiLangfang 065000,China)
ProxyMobile IPv6(PM IPv6),asanetwork-basedmobilitymanagementprotocol,maintains theMH'smobility roam ing supportw ithin an intra-domain.Butthe traditionalPM IPv6mechanism cannotrealizeseam lesshandoveracross domain of PM IPv6.This paper proposesan effectivemechanism tomanageMH handoverandmaintain its data session continually across inter-PM IPv6 domains.The proposedmechanism introduces an intermediate globalmobility anchor entity,called(GLMA),which is responsible to coordinateMH handoverand redirects its traffic across inter-PM IPv6-domains.In addition,severalsimulation experimentswere conducted to show the superiorperformanceof the proposed mechanism over the conventionalinter-PM IPv6-domain schemesin termsofhandover latency to achieve throughput,protocolsignaling cost,and end-to-end traffic delivery latency.
PM IPv6;handover coordinator;handover latency;traffic redirection
TP393
A
1007-2373(2016)03-0093-07
10.14081/j.cnki.hgdxb.2016.03.016
2016-03-02
河北省自然科学基金(E201502266)
齐虹(1972-),女(汉族),副教授.
猜你喜欢
系统仿真技术(2022年4期)2023-01-17 13:01:44
北京航空航天大学学报(2022年8期)2022-08-31 08:59:18
读报参考(2022年1期)2022-04-25 00:01:16
国际太空(2021年11期)2022-01-19 03:27:06
科学家(2021年24期)2021-04-25 13:25:34
铁路通信信号工程技术(2019年10期)2019-11-06 01:11:00
中国交通信息化(2019年2期)2019-03-25 03:20:22
消费导刊(2017年24期)2018-01-31 01:28:37
互联网天地(2016年2期)2016-05-04 04:03:21
华东理工大学学报(自然科学版)(2015年3期)2015-11-07 09:17:42
