
基于多特征提取的中文微博舆情分类研究
2016-02-21 00:56林伟
中国人民公安大学学报(自然科学版) 2016年4期
林 伟
(福建警察学院侦查系, 福建福州 350007)
基于多特征提取的中文微博舆情分类研究
林 伟
(福建警察学院侦查系, 福建福州 350007)
对微博情感分类,及时掌握微博上发布信息状态是网络舆情监控的重要研究内容。为能有效提取微博样本的特征,结合微博书写时口语化、时代化、含表情等特点,提出基于改进N-Gram的微博的多特征项提取算法,并给出基于聚类的KNN分类模型。实验结果表明,本文提出的算法能够有效提高微博舆情分类性能。
多特征; 微博舆情; 特征选择; KNN
0 引言
随着互联网技术和移动通信技术的快速发展,微博作为一种新的社交方式具有传播速度快、交互性强、发布方便等特点而深受广大网民欢迎。然而,微博在便于人们获取信息的同时,也为负面信息的快速传播提供了便利条件。在现实生活中,群体性事件发生时有些恶意分子往往会在微博平台上同时发布大量虚假信息,通过不知情的用户及粉丝不断转发,借此煽动人们的情绪,使事态进一步恶化。如“郭美美事件”“毒胶囊事件”等公共舆情事件,往往借力微博的传播速度和广度导致重大负面影响[1]。
为此,通过对微博的情感进行分类,及时掌握微博上发布信息的动态,对一些带有煽动、恶意的负面信息的进行舆情监控为网监部门提供参考。目前微博舆情分类的方法有很多。其中采用机器学习算法对微博的情感性进行分类,是微博舆情分类的有效方法之一[2]。
基于机器学习的中文微博情感性分类方法一般先用中文切词算法提取微博样本中的特征选项,然后用向量空间模型(Vector Space Model,简称VSM)对微博样本形式化描述。常用的中文切词分词算法有基于统计的切词分词算法和基于词典的切词分词算法。对于基于词典的切词分词算法,由于微博的书写偏口语化、时代化(如坑爹、童鞋)的特点,并且微博作者常常用表情符号以表达自己的情感倾向,比如说发布“”表情符号往往表示一种正向的情感倾向。因此,此类算法应用到微博情感性分类中,会因词典的覆盖有限而无法有效提取出微博样本中的特征选项。对于基于统计的切词分词算法的典型代表算法——N-Gram切分算法,由于避免了在切词分词过程中对词典的依赖搜索,允许中文微博书写过程中口语化、随意化等噪声数据,更适用于对微博的情感性分类。
本文在分析中文微博书写特点的基础上提出一种多特征的微博特征项提取算法,实验结果表明,该方法能够有效提高微博舆情分类的性能。
1 微博预处理
1.1 N-Gram切分算法
N-Gram切分算法的思路是:假设有字符串S,那么S的N-Gram项就表示按一个字符进行窗口移动且长度N切分原词得到的词段,也就是S串中所有长度为N的子串。以汉字为例,对于句子“元芳,你怎么看”,如果n=1,该句子(去掉标点符号)的N-Gram切分为“元”“芳”“你”“怎”“么”“看”,简称“unigram”。如果n=2,则该句子的N-Gram项为“元芳”、“芳你”、“你怎”、“怎么”、“么看”5个语言单元,简称“bigram”。由于现代汉语中75%为双字词,如果将长度超过两字的词划分为两字词并不会损失太多的信息量[3],因此,在本研究中我们取N-Gram项为两字词bigram。
1.2 多特征提取算法(Multi-N-Gram)
N-Gram切分算法应用到微博情感性分类中,由于微博书写的时代化[4],中文微博短文本中甚至可能还含有英文单词,如“asshole,我恨死你了,748,”,按照bigram的机械划分,对于英文单词“asshole”、表情符号“”及数字串“748”均无法有效提取,而这3个特征选项在表达微博的情感倾向时有较大的贡献,如对英文单词“asshole”进行bigram机械划分为“assh,ssho,shol,hole”,会因与本意相差较大而损失较大的信息量,直接影响情感性分类效果。为能够有效提取出中文微博中可能含有的英文单词、数字串、表情符号甚至其他语言类型的文字符号,我们在N-Gram切分算法的基础上对算法进行改进。
改进的基本思路是对微博字符流每次按一个字节的字符进行窗口滑动,在滑动的过程中判断字符的编码,对于英文单词和数字串我们用汉字、标点符号、停用词做分界符提取,对于表情符号我们以左、右方括号([、])作为分界符进行提取,对于汉字编码则采用bigram方法进行提取。同样,对于其他类型的语言,只要能够判断其编码的类型,按照其成词规律进行切词,算法可做到与语言无关性。具体如算法1所示:
算法1.
Input:微博信息流
Output:特征集
Begin: 初始化参数Bow,Tvsm,Lastchar //Bow为候选特征项临时存放区,Tvsm特征向量存放区
以一个字节为单位读取字符U //Lastchar为上一个字符类型
If U为ASCII码
If U为字母或数字
If Bow长度>0 && Lastchar=’汉字’
Bow加入向量表Tvsm中,并清空Bow
End
If U为表情分隔符‘[’
将表情符号加入特征向量Tvsm中,置Lastchar=‘表情’
esle
将字符放入Bow,置Lastchar=‘英文’
Endif
Endif
Endif
If U为汉字编码
If Bow长度>0 && Lastchar!=‘汉字’
Bow加入向量表中,并清空Bow
Endif
进行bigram切分,并将Bow加入向量表中
Endif
If U 为其他编码 //算法可扩展性、语言无关性
……
Endif
1.3 特征选择
由以上切分算法分出来的特征候选项构成的微博向量空间往往会因特征维数过大而造成特征冗余,特征冗余不仅会增加计算量还会影响微博情感性分类度,因此需要选取一定的特征选择算法对维数进行压缩。常用的特征选择算法有互信息(MI)、信息增益(IG)、文档频率(DF)、期望值交叉算熵等[5]。本研究中采用互信息(MI)做为特征选择算法,特征项wi与情感类别C之间的互信息量定义为:
(1)
其中P(wi)表示特征在所有微博中出现的概率,P(C)表示所有微博中属于C类微博的概率,P(wi,C)表示具有特征wi且类别为C的微博在所有微博中的概率。为了减少互信息量值偏于低频特征,互信息量计算公式通常变形为:
(2)
其中,P(wi|C)表示具有特征wi且类别为C的微博概率。由于微博情感性分类为二元分类,特征wi的互信息量为:
MI(wi)=|MI(wi,C=1)-MI(wi,C=0)|
(3)
即wi分别与正向(C=1,positive)情感微博和负向(C=0,negative)情感微博的互信息量之差的绝对值。对候选特征集中所有特征,计算其互信息量,选择MI值最大的n个特征构成特征向量空间T(w1,w2,…,wn)。
2 分类模型
2.1KNN分类算法
KNN算法是文本分类中简单而经典的方法之一,其基本思想是:对待分情感类别的微博使用向量空间模型描述为:Mj=〈w1,w2,w3,…,wn〉,假设特征项〈w1,w2,w3,…,wn〉间相互独立[6]。微博舆情分类的任务就是利用向量夹角余弦公式:
(4)
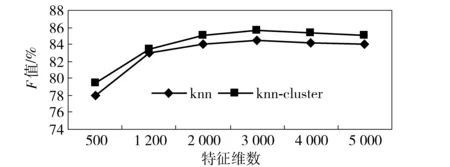
来计算待分类微博Mj与微博训练集所有样本Mi的情感相似度,从微博训练集中找出与待分类微博Mj最相似的K个微博样本Ms=〈w1,w2,w3,…,wn〉 (0 (5) 其中p(Mj,c)为Mj与情感性类别c的相似度,Mj在类别c中出现(Mj,c)为1,否则为0,微博Mj的情感性类别决策为: CMj=arg max (p(Mj,c)) (6) 基于KNN的微博情感性分类的具体流程如图1所示。 图1 基于KNN微博情感性分类流程 2.2 KNN-Cluster分类算法 虽然KNN算法是一种经典的文本分类算法,但随着训练文本的数据增加,待分类微博样本需要计算每个样本的相似度,其极大地影响分类速度及性能。因此,当训练微博数量达到一定量级时,我们首先对训练微博样本集先进行聚类,通过对训练微博样本集聚类,使微博样本组(簇)内微博具有相关性,而簇之间的微博不相关,从每簇中选取与簇中心相关性大于阈值ε的样本,从而达到对样本裁剪的目的。算法描述如下: 1)从样本集中选取样本m为初始化一个簇; 2)用公式(4)计算剩余样本Mi与m的相似度; 3)如果sim(m,Mi)大于阈值σ,则将Mi加入当前簇,否则创建新簇; 4)重复上述过程,将原始样本在给定相关阈值σ内划分各个簇; 5)使用算术平均法计算各个簇中心,利用公式(4)取与簇中心相似度大于阈值ε的微博样本为训练样本; 6) 根据公式(4)计算待分类样本Mj与裁剪后训练样本的相似度,然后根据公式(5)、(6)确定微博的情感性类别。 3.1 实验设置 3.1.1 实验基础 本实验所使用的数据集来源于新浪开放平台公开API抓取的中文微博样本集[7],从中随机选取8 000个微博样本集进行人工标注,实验结果采取10次交叉验证方法,结果取平均值。 3.1.2 评价指标 为了有效评价微博情感分类性能的好坏,常用评价指标:SP(负向情感微博识别的准确率Precision)和SR(负向情感微博识别的召回率Recall)[8]。 (7) npositive→positive为正确识别出的负向情感微博数,npositive→negative为正向情感微博被误识别为负向情感微博数。 (8) npositive为样本微博中负向情感微博数的总数。 我们选取F-SCORE 作为性能评测指标 ,公式(8)为F-SCORE的公式 (9) 3.2 实验结果分析 3.2.1 Multi-N-Gram与BIGRAM、词典分词比较分析 实验中,我们用Multi-N-Gram与Bigram、中科院NLPIR汉语分词系统(2013版)进行比较实验。在不同特征数下的F值结果如图1所示,从图中可以看出,在同样的特征数下,Multi-N-Gram算法的F值较其他两种提出算法的F值均有不同程度的提高。当特征数为2 000左右时,Multi-N-Gram算法的F值达到最高0.875。随后继续增加特征数F值并无多大变化,当特征数达到4 000以上时,F值甚至还出现了下降。实验结果表明:1、使用Multi-N-Gram切分算法对微博进行切分时因考虑中文微博书写中可能含有的英文单词、数字串、表情符号等特点,能够更有效提取中文微博的特征项,从而提高微博情感性分类的性能。2、当特征数达到一定数量时,增加特征数不仅会增加分类计算的复杂性,还会因为噪声特征项的增加影响分类性能。 图2 3种特征提取算法的分类性能比较 3.2.2 KNN与KNN-Cluster比较分析 实验中,我们对KNN与KNN-Cluster分类模型进行比较实验。在不同特征数下的F值结果如图2所示,从图中可以看出,在不同特征数下分类算法的整体走势与上面实验类似,在特征数为3 000左右时F值达到峰值,进一步说明上述实验结果第二点所反映的现象。而在相同的特征数时,KNN-Cluster分类算法在大部份情况下的F值较KNN分类算法的F值有所提高,实验结果表明:使用聚类算法对微博样本进行裁剪,在减少分类计算的情况下,分类性能还能够得到一定的提高。 图3 KNN与KNN-Cluster算法的性能比较 对微博情感性分类,掌握微博动态对微博舆情监控具有重要的现实意义。本文结合微博书写时口语化、时代化、含表情等特点,分析N-Gram基于词典切分算法在微博情感性分类中提取特征项存在的缺陷,提出一种在微博字符滑动的过程中通过对字符编码的判断,提取英文单词、数字串、bigram、表情符号等多特征微博候选项提取算法,从而提高微博情感性分类性能。还进一步分析了KNN分类算法存在的一些缺陷,给出一种基于聚类的KNN分类模型,通过聚类,减少训练样本数量,取得较好的效果。 [1] 谢丽星,周明,孙茂松.基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1):73-82. [2] 单月光.基于微博的网络舆情关键技术的研究与实现[D].成都:电子科技大学,2013. [3] ZHOU S,GUAN J. Chinese documents classification based on N-grams[C]∥International Conference on Intelligent Text Processing and Computational Linguistics. Berlin: Springer Berlin Heidelberg, 2002:405-414. [4] 周鹏,蔡淑琴,石双元.微博危机事件的用户中心化研究[J].情报杂志,2013(3):2-10. [5] YANG Y, PEDERSEN J. A Comparative Study on Feature Selection in Text Lategorization[C]∥Proceedings of the Fourteenth International Conference on Machine Learning. Burlington: Morgan Kaufmann Publishers, 1997:412-420. [6] 基于机器学习的中文博感分类实证研究[J].计算机工程与应用,2012,48(1):1-4. [7] 基于表情符号的中文微博多维情感分类的研究[J].合肥工业大学学报,2014,37(7):803-807. [8] 张志琳,宗成庆.基于多样化特征的中文微博情感分类方法[J].中文信息学报,2015,29(4):134-143. (责任编辑 于瑞华) 国家自然科学基金(61472329)、福建省教育厅基金(JAT160561)、福建警察学院院级课题(YJ1411) 林伟(1983—),男,汉族,福建警察学院讲师,硕士,研究方向为网络安全、数据挖掘、信息化侦查。 D918.2
3 实验分析

4 结语
猜你喜欢
消费电子(2022年6期)2022-08-25
疯狂英语·新阅版(2020年11期)2020-12-21
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
考试周刊(2016年91期)2016-12-08
成才之路(2016年26期)2016-10-08
大作文(2016年7期)2016-05-14
Coco薇(2015年10期)2015-10-19
