
基于LDA主题模型的标签推荐方法研究
2016-02-15 07:07张亮
现代情报 2016年2期
张 亮
(武汉工程大学管理学院,湖北武汉430205)
基于LDA主题模型的标签推荐方法研究
张 亮
(武汉工程大学管理学院,湖北武汉430205)
针对现有的标签推荐方法存在的推荐准确率不高与效果不理想等问题,本文提出了基于LDA主题模型的社会化标签推荐方法。该方法利用LDA主题建模技术将传统的基于对象间关系的推荐方法扩展到融合对象间关系与资源内容特征的统一推荐。实验结果表明,该方法取得了理想的预期效果,能够显著提高标签推荐的质量与效果。
标签推荐;LDA主题模型;推荐方法
标签作为Web2.0时代信息分类与索引的重要组织方式,其主要原因在于Web2.0强调以用户为中心、用户参与的互联网开放式架构理念,网络信息的产生、发布从传统的网站管理者转移到普通的网络用户身上;但由于普通用户对专业的信息分类体系缺乏了解,基于传统的固定分类体系的信息组织方法难以适应Web2.0时代的信息发布与组织模式。标签系统作为传统分类方法的替代,其随意、灵活、无等级划分的特征使得用户能够很容易利用该系统进行Web2.0上的信息分类与组织,成为Web2.0时代网络信息的重要组织方式[1]。随着社会化标注系统的快速发展,用户在使用这类系统进行资源标注时,通常会选择其他用户或自己已使用过的标签进行资源推荐,而由于社会化标签创建的随意性和个性化,难以保证标签的准确性和可用性,且随着用户数量和资源规模的增长,标签数量也随之增多,致使标签系统中存在大量模糊的、可信度低的标签。为解决这些问题,目前的研究主要集中在标签推荐领域,即利用高效的标签推荐方法提升资源所附带标签的质量[2]。现有的标签推荐方法主要分为3类:
(1)基于资源内容的标签推荐方法。基于资源内容的标签推荐方法从标注资源所具备的属性特征出发,通过提取描述资源内容的关键词作为标签推荐的依据。由于该方法在处理过程中仅仅利用了资源本身的信息,没有兼顾相似资源、邻居用户等信息,无法发挥标签的社会化特性,在实际运用过程中的准确率与效率并不理想[3]。
(2)基于协同过滤的标签推荐方法。基于协同过滤的标签推荐方法利用协同过滤技术获取相似资源、邻居用户等标签信息,实现对目标资源的推荐,如Hotho等[4]提出的FolkRank方法利用社会化标注系统中用户、标签、资源三者之间存在的关联信息对标签进行排序,根据排序结果进行协同推荐;Mishne[5]提出的AutoTag方法利用相似度计算获取与目标资源内容相似的资源,并将相似资源的标签进行聚类、排序,根据排序结果实现协同推荐。这类方法的关键是准确获取相似资源的标签信息,然后从已有的标签库中查找到相似标签进行推荐,故该方法的推荐效果会受到候选标签库规模、标签相似度计算方法准确度的影响[6]。
(3)基于标签语义的标签推荐方法。基于标签语义的标签推荐方法利用用户、标签、资源三者之间蕴含的语义关系获取推荐标签所需的知识并运用到推荐任务中,提高标签推荐的准确性与推荐效果,如Adrian[7]提出的ConTag方法将本体思想运用到标签推荐之中,通过将用户、标签、资源三者之间的关系表达成RDF格式进行文档主题建模,实现基于语义主题的标签推荐;Marchetti等[8]提出的Semkey方法将语义网与协同过滤技术相结合进行基于语义协作的标签推荐。
这些标签推荐方法在一定程度上提高了标签推荐的准确性与效率,改善了社会化标签系统的质量和效果。但这些方法主要利用对象间关系进行标签推荐,忽略了资源本身的特征信息,当用户、标签、资源之间的关系比较稀疏时,会严重制约标签推荐的准确度与效果。针对这些问题,本文研究和设计了一种基于LDA(Latent Dirichlet Allocation,LDA)主题模型的标签推荐方法。该方法综合考虑用户、标签、资源之间的潜在关系及资源内容特性,利用LDA主题模型将用户、标签、资源及资源内容进行关联,实现标签系统中对象间关系与资源内容的融合分析与综合推荐。
1 LDA主题模型原理
LDA主题模型是一个以“文档-主题-关键词”为层次结构、通过加入Dirichlet先验分布来解决PLSA主题模型中存在的过拟合现象的三层贝叶斯概率模型,其基本思想是[9]假设任何文本都可以表示成一系列主题的混合分布,记为P(z);同时任意主题都是关键词列表中所有单词的概率分布,记为P(w z),则一个文本中每个关键词的概念分布为:
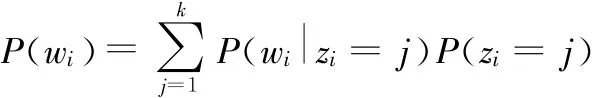
LDA主题模型认为文档是若干关键词的集合,在构建主题模型过程中不考虑任何语法或词语出现的顺序关系,利用该模型产生文档的贝叶斯网络图如图1所示。

图1 LDA的贝叶斯网络图
图1 中,随机变量θ表示目标文档中的主题分布向量,隐含变量z表示目标文档分配在每个关键词上的N维主题向量,用来体现文档与关键词之间的潜在关系,w表示目标文档中关键词的向量表示,α、β分别表示文档和关键词满足相应的Dirichlet分布时的参数。
利用LDA模型进行文档主题建模时的核心问题是估计隐含变量的概率分布情况,即获取目标文档中隐含主题分布和各隐含主题的关键词分布,其处理过程描述如下:
(1)获取文档d中每个主题发生的概率θd,即抽取服从Dirichlet(α)分布的θd值,其中α是Dirichlet分布的参数;
(2)获取文档d中每个关键词wi的抽样主题zi,即从θd的多项式分布中抽取满足条件的zi:P(ziα);
(3)获取文档d中所有关键词的向量表示wi,即从zj的多项式分布中抽取满足条件的wi:P(wizj,β)。
上述处理过程中,β主要用来描述特定主题条件下生成的某个关键词的概率,是以主题数目K和特征关键词V组成的二维向量空间为表现形式,即β=K×V,且βij=P(wj=1zi=1)。对于给定的语料库D,LDA主题建模过程就是通过z和θ的值获取使得P(Dα,β)极大化时参数α和β的值,通过这些参数值得到文档的主题分布情况以及所有关键词所属的主题类别。由于z和θ均为潜在变量,通过直接计算是无法得到的,常用的方法是通过吉布斯抽样、变分贝叶斯、最大似然估计等方法进行参数估计[10]。
2 基于LDA主题模型的标签推荐方法
将LDA主题模型运用到社会化标签推荐方法中的典型研究包括Harvey等[11]提出的基于LDA主题建模的TTM方法,该方法将标签系统中的用户、标签、资源分别构建相应的主题模型,使其可以估计用户与资源的主题分布情况以及标签关键词的主题分布;Subram等[12]将资源的相似性视为依条件概率的随机过程,并将其融入到标签主题的建模中,在此基础上提出了基于Regularized LDA主题建模的标签推荐方法,验证了LDA主题模型在标签推荐方面具有很好的可扩展性。本文在这些研究的基础上,将LDA主题模型融入社会化标签推荐方法之中,研究和设计了基于LDA主题模型的社会化标签推荐方法。本文方法与这些已有方法的区别主要体现在本文方法将社会化标注系统中的用户、标签、资源及资源内容特征进行融合分析,构建统一的LDA主题模型,使标签推荐从传统的分析对象间关系扩展到融合关系与资源内容特征的综合分析,实现基于关系与内容特征的主题建模与推荐,该方法的贝叶斯网络图如图2所示。

图2 基于LDA主题模型的标签推荐贝叶斯网络图
图2 中,D表示文档资源的总数,N表示文档资源中资源内容特征关键词的总数,M表示资源标签中关键词的总数,K表示所有文档资源中包含的主题总数,L表示所有标签中包含的主题总数。利用该模型进行主题建模的过程如下:
(1)针对任意文档资源di,抽取服从Dirichlet(α)分布的θci和θti,其中,θci表示文档资源di中主题为k的概率,主要针对文档资源本身内容特征获取主题;θti表示文档资源di的标签中关键词的主题为l的概率,主要针对文档资源标签中的关键词获取主题;
(2)针对文档资源本身内容特征,选取服从Dirichlet(β)分布的δk,其中,δk表示对于给定的主题k,所能得到的所有资源特征关键词的概率;针对文档资源标签中的关键词,选择服从Dirichlet(β)分布的φl,其中,φl表示对于给定的主题l,所能得到的所有标签关键词的概率;
(3)针对文档资源di中的所有内容特征关键词,根据抽取的θci得到相应的主题zc,再根据δzc选择主题词wc;针对文档资源di标签中的所有标签关键词,根据抽取的θti得到相应的主题zt,再根据φzt选择主题词wt。
针对上述过程中出现的参数,本文采用吉布斯抽样方法[13]进行参数学习,并通过将文档资源内容和资源标签进行分割成独立的文档单元实现参数估计,相应的参数估计方法为:
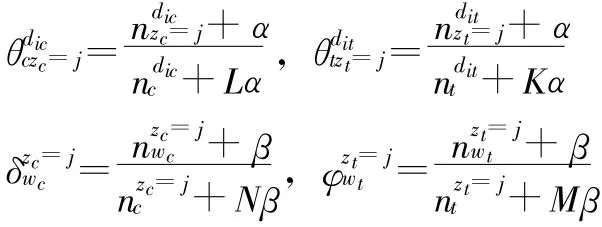
上述公式中各变量的含义如表1所示:

表1 参数估计方法中各变量含义
利用上述方法进行主题建模和参数估计后,则对于任意文档资源di被用户u*创作的概率可以表示为:
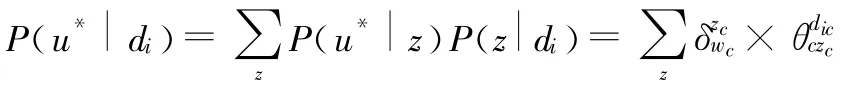
对于文档资源di中标签t出现的概率可以表示为:

则综合文档资源内容和标签关键词的统一推荐可以表示为:
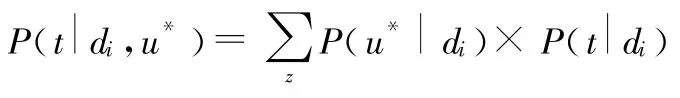
3 实验与结果分析
本文采用对比实验法来检验所提出的基于LDA主题模型的标签推荐方法的准确性与效果。
3.1 实验数据来源
实验数据选自美国Minnesota大学计算机科学与工程学院的GroupLens项目组收集的MovieLens10M100K数据集[14]。该数据集含有movies.dat、ratings.dat、tags.dat 3个文件,其中,movies.dat文件主要存储电影的编号ID、名称Title和类别Genres信息,ragings.dat文件主要存储用户对电影的评分Rating和评分时间Timestamp信息,tags.dat文件主要存储用户对电影标记的标签Tag和标记时间Timestamp信息。
3.2 实验环境与测评指标
实验环境为处理器为Inter(R)Core(TM)4CPU 4400 2.0GHz,内存4G,硬盘500G,操作系统为Windows 7,编程语言为Java(JDK 1.6.2)。实验测评指标选择标签推荐领域常用的推荐准确率(Precision,P)、推荐召回率(Recall,R)、F1值,其计算方法为:
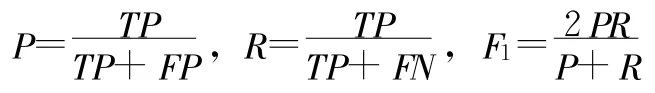
其中,TP表示推荐结果与人工评价都认为应该具有的标签数量,FP表示推荐结果具有但人工评价认为不该具有的标签数量,FN表示推荐结果没有但人工评价认为应该具有的标签数量。
3.3 实验过程与结果
本文选择标签推荐领域常用的FolkRank方法、Hosvd-Direct方法、TTM方法作为参照方法进行对比实验。实验结果如表2所示。

表2 实验结果
3.4 实验结果分析
通过上述实验结果可以看出,本文提出的基于LDA主题模型的标签推荐方法在推荐准确率、推荐召回率、F1值等测评指标上的结果值明显优于现有的标签推荐方法,能够在实际运用过程中提供更好的标签推荐服务。其主要原因在于本文方法综合运用用户、标签、资源及资源内容特征进行统一主题建模,能够在传统的基于对象关系分析的推荐方法的基础上融入资源内容特征,实现基于对象关系和内容特征的综合推荐,故能够取得比传统推荐方法更好的实验效果。
通过将每个主题下的标签按照概率进行降序排列,同时记录各主题下的标签集,可以得到该主题的直观标签表示,表3给出了其中5个主题的前8个推荐标签。
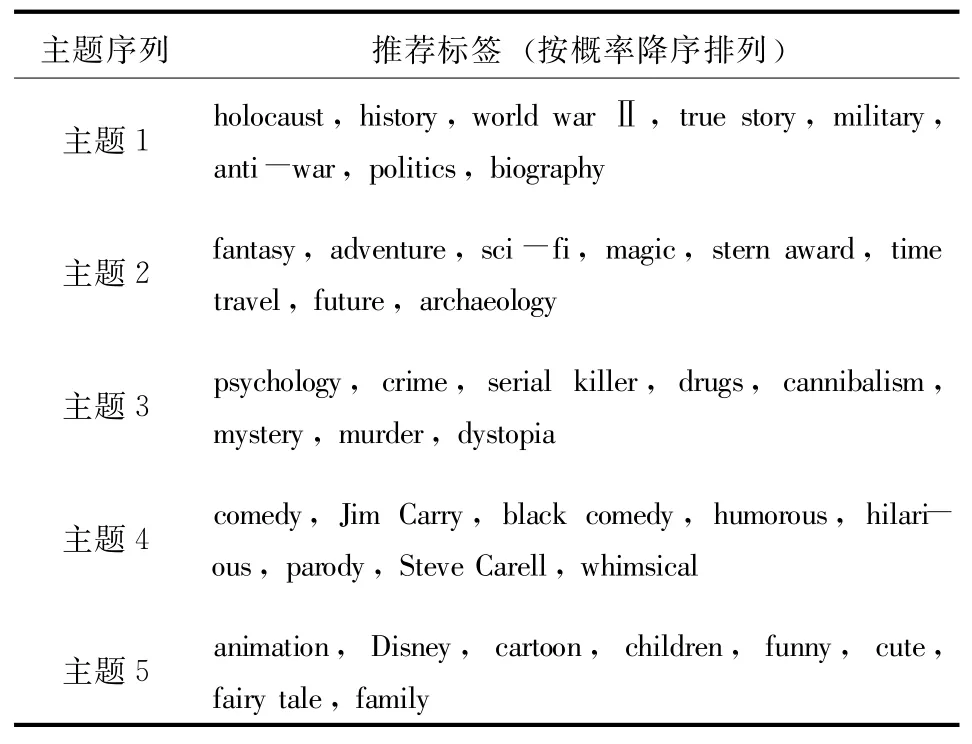
表3 部分主题与推荐标签
4 结束语
标签是Web2.0时代信息分类与组织的重要方式,是以用户为中心、用户参与创建互联网内容的主要表现形式。本文针对现有的标签推荐方法存在的推荐准确性不高和推荐效果不理想等问题,提出了基于LDA主题模型的社会化标签推荐方法。该方法利用LDA主题建模技术将社会化标注系统中的用户、标签、资源及资源内容特征进行统一主题建模,将传统的基于对象间关系的推荐扩展到基于对象间关系和资源内容特征的综合推荐。通过在真实的测试数据集上进行实验后表明,融合对象间关系与资源内容特征的推荐方法明显优于现有的标签推荐方法,能够显著地提高标签推荐的质量和效果。
[1]张斌,张引,高克宁,等.融合关系与内容分析的社会标签推荐[J].软件学报,2012,23(3):476-488.
[2]Seitlinger P,Kowald D,Trattner C,et al.Recommending tags with a model of human categorization[C].Proceedings of the 22ndACM international conference on Conference on information&knowledge management.ACM,2013:2381-2386.
[3]王海雷,俞学宁.基于随机游走算法的社会化标签的用户推荐[J].计算机工程与设计,2013,34(7):2388-2391.
[4]Hotho A,Jaschke R,Schmitz C.Information Retrieval in Folksomomies:Search and Ranking[M].Berlin:Springer,2006:411-426.
[5]Mishne G.AutoTag:A Collaborative Approach to Automated Tag Assignment for Weblog Posts[C].Proceedings of the 15thInternational Conference on World Wide Web,2006:953-954.
[6]赵亚楠,董晶,董佳梁.基于社会化标注的博客标签推荐方法[J].计算机工程与设计,2012,33(12):4609-4613.
[7]Adrian B,Sauermann L,Roth-Berghofer T.Contag:A Semantic Tag Recommendation System[J].Journal of University Computer Science,2007,36(7):297-304.
[8]Marchetti A,Tescono M,Ronzano F.SemKey:A Semanitc Collaborative Tagging System[C].Proceedings of the 16thInternational Conference on World Wide Web,2007:8-12.
[9]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3(4-5):993-1022.
[10]唐晓波,王洪艳.基于潜在狄利克雷分配模型的微博主题演化分析[J].情报学报,2013,32(3):281-287.
[11]Harvey M,Baillie M,Ruthven I,et al.Tripartite Hidden Topic Models for Personalized Tag Suggestion[C].Proceedings of the 32ndEuropean Conference on IR Research,2010:432-443.
[12]Subram V,Pandian S C.Topic ontology-based efficient tag recommendation approach for blogs[J].International Journal of Computational Science and Engineering,2014,9(3):177-187.
[13]Heinrich G.Parameter Estimation for Text Analysis[OL].http:∥www.arbylon.net/publications/text-est.pdf,2015-12-10.
[14]GroupLens Research.MovieLens Data Sets[OL].http:∥www.grouplens.org/node/73/,2015-09-15.
(本文责任编辑:孙国雷)
Research on Tagging Recommendation Method Based on LDA Topic Model
Zhang Liang
(School of Management,Wuhan Institute of Technology,Wuhan Hubei 430205,China)
This paper proposes a social tagging recommendation method based on LDA topic model to solve the problems of accuracy and effect in existing tagging recommendation method.This method extends the traditional tagging recommendation method based on the relation of objects to combine analysis of the relation of objects and the content of resource by using of LDA modeling technology.The experiment result shows that this methods gets a good expectant performance and dramatically improve the quality and efficiency of tagging recommendation.
tagging recommendation;LDA topic model;recommendation method
10.3969/j.issn.1008-0821.2016.02.010
G203
A
1008-0821(2016)02-0053-04
2015-12-13
张 亮(1973-),男,讲师,博士,研究方向:语义web与数据挖掘。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
少先队活动(2021年5期)2021-07-22
中国非营利评论(2019年1期)2019-06-18
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
信息安全研究(2016年4期)2016-12-01
公民与法治(2016年10期)2016-05-17
体育科技(2016年2期)2016-02-28
