
基于深度神经网络与主题模型的文本情感分析
——以上海迪斯尼景区游客满意度调查为例
2016-02-13 05:57何愉卫陈泉陆钰华
统计科学与实践 2016年12期
何愉、卫陈泉、陆钰华
(国家统计局上海调查总队,上海 200003)
基于深度神经网络与主题模型的文本情感分析
——以上海迪斯尼景区游客满意度调查为例
何愉、卫陈泉、陆钰华
(国家统计局上海调查总队,上海 200003)
本文尝试以上海迪斯尼景区的网络评价数据为例,通过深度神经网络和主题模型开展文本情感分析。在完成网络数据爬取、基于隐马尔可夫(HMM)模型的中文分词、向量空间(VSM)模型将文本转向量等一系列数据源和数据预处理工作后,通过机器学习中的多层感知器(MLP)神经网络进行建模,并构建主题模型。本文将大数据的开发与当前的统计调查有机结合,探索一条对社会各领域评价调查具有可复制可推广的大数据调查模式。
文本挖掘;神经网络;主题模型;情感分析;VSM模型
随着社会和科技的发展,尤其是在当前大数据研究应用的背景下,传统调查受限于时间和空间,调查效率相对偏低,调查数据质量控制难度和成本不断增加,调查数据的时效性相对偏弱等不足进一步显现。大数据时代的来临,为我们提供了全新的获取数据的渠道,也为我们创新调查方式,更加快捷、高效、科学地评估用户满意度水平提供了一种可能。
本文尝试以上海迪斯尼景区的网络文本评价为例,通过深度神经网络和主题模型开展文本情感分析。当前传统的满意度调查主要通过问卷调查的方式开展,通过浏览网站不难发现,网络评价分为定量评价(如打分、标星)和定性评价(如文字描述)两种。然而面对大数据,我们也会心生疑惑和忐忑,大数据的内部结构难以全面把握甚至不得而知,大数据的数据质量参差不齐也无从考究,大数据的应用结果缺乏验证和评估,因此如何应用好大数据,挖掘出纷繁复杂,杂乱无章的大数据背后暗藏的规律,如何将大数据的开发与当前的统计调查有机结合,成为有益的补充和替代;探索一条对社会各领域评价调查具有可复制可推广的大数据调查模式,是我们研究的初衷和出发点。
课题研究将通过完成以下三大目标,实现建模初衷。1.综合运用HMM分词模型、VSM模型、MLP神经网络以及LDA主题模型,创新满意度调查方式;2.将定性文字转为定量评价,提高文本数据的挖掘分析能力;3.加深对大数据内部维度结构的认知,更加细化对文本数据的挖掘等方面,开展积极地尝试和探索。
一、研究路径
(一)数据获取
运用网络爬虫技术,从携程网、大众点评、猫途鹰等旅游网站上获得游客对香港迪斯尼、上海迪斯尼等景点的网络评价,包括评论时间、文本评论、满意度评价及相关用户信息。
(二)数据预处理
经过文本预处理,建立只有评论内容的文本数据库;基于隐马尔可夫模型(HMM),通过公共词库、停用词词库和自定义词库进行中文分词,经过多次迭代和词库更新,形成最终分词结果。最后通过向量空间模型(VSM),将分词完毕的文本,转化为文本向量,存入文本向量库。
(三)建模(模型训练和比较)
首先MLP建模。通过机器学习中的多层感知器神经网络(MLP)进行建模并评估结果,不断的调整预测模型,直到预测结果达到预期准确率。基于向量空间模型中的三种转换方法,运用多层感知器神经网络中的逻辑回归(LR)和支持向量机(SVM)两种算法进行比较分析。其次构建主题模型。通过LDA主题模型,对文本进行潜语义分析,对潜在主题分类的相关特征的分析和甄别,确定相关主题。
(四)知识获取
以上海迪斯尼景区的网络评论满意度为主要研究对象,比对世界各地迪斯尼景区,从整体满意度水平、二级评价主题差异和分项满意度差异、满意度随时间趋势变化等多角度进行挖掘,加强对网络评论文本的深度解读,从而能够更有针对性地对评论对象提出意见建议。
二、数据来源和预处理
(一)软件说明:python语言
本课题运用python语言编写预处理和建模程序。
(二)数据来源:爬虫获取网络评价
运用网络爬虫技术,从携程网、大众点评、猫途鹰等旅游网站上成功获得逾六万条游客对香港迪斯尼、上海迪斯尼等景点的网络评价,包括评论时间、文本评论、满意度评价以及用户信息。其中部分文本评论用于神经网络建模的训练和测试;另外一部分文本评论用于模型机器打分(见表1)。进行文本预处理,纯化文本内容,去除HTML标记,形成只有评论内容的纯文本,并存入评论文本数据库。

表1 课题数据源信息表
(三)训练语料评估:德尔菲法确定语料噪音比例
随机抽样选取一定比例的训练语料,进行人工背靠背打分,将打分结果和原始满意度分值进行比较,确定“噪点”(主客观偏差较大的数据)比例。若比例过高,则前期需增加对“噪点”语料的筛选和剔除;若比例较低,“噪点”语料不会影响后期机器学习效果,可直接运用于下阶段分析使用。通过背靠背打分,发现原始语料噪点比例为0.5%,可直接使用。
(四)文本分词:运用“隐马尔可夫模型”对文本评价分词
第一阶段:初步分词,运用公用词库和自定义词库对评论文档进行分词;
第二阶段:去停用词,停用词主要为副词和标点等,去除一些在文本中常用的词语,比如“的”“吗”等;合并数字和人名等词汇;数字或者人名等词汇在具体的分析过程中一般不会起到非常大的作用,人工将其去除;
第三阶段:自定义词库更新,将每次分词发现的新词不断加入自定义词库。经过多次的迭代和词库的更新,形成最终的分词结果(限于篇幅,此处省略)。
(五)向量空间(VSM):文本转换为向量
情感分析利用神经网络,将一条条分词完毕的文本评价转换为向量,这样计算机才能够读取和学习。在转换的过程中,列指标即特征向量。特征提取指选取能够表征目标结构的一种表示方法,进而拥有分类和判决。本课题运用VSM模型将一条分词完毕的评论转换为向量,具体分PVDM(Distributed Memory Model of Paragraph Vectors)和PV-DBOW(Distributed Bag of Words version of Paragraph Vector)两种算法(见图1)。相较于CBOW(从上下文推本词)和skip-gram(从本文推上下文),VSM的方法在前者基础上加入了段落标志,从而能够达到更好的分词效果。DBOW、DM等向量空间模型,分词中只需解决未登录词,无需删除大量停用词以及预先导入同义词库,大大简化了分词的难度。
具体操作:
步骤一:将每条分词完毕的评论运用PV-DM方法转换为[1*200]的向量;
步骤二:将每条分词完毕的评论运用PV-DBOW方法转换为[1*200]的向量;
步骤三:将上述两种转换方法得到的向量合并,构造得出[1*400]的向量。
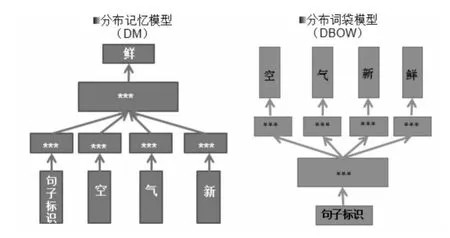
图1 DM和DBOW的说明
三、机器学习建模与模型比较分析
(一)思路框架
在建立模型的时候,本课题选用监督式机器学习的算法。将模型预测结果与“训练数据”的实际结果进行比较,不断的调整模型,直到模型的预测结果达到一个预期的准确率。本课题尝试探索应用多层感知器神经网络,并使用多种目标函数(逻辑回归和支持向量机等)开展比较研究。
(二)主要步骤
1.数据建模
在前期文本转换为向量的基础上(dov2vec),运用机器学习神经网络(MLP)算法,构建模型。在评分标准方面,二分法虽较简化,机器学习的判别也更简单,但也损失了部分信息。基于此,课题组通过五分法,使机器学习能够获取更多信息,文本情绪层次进一步得到细化,输出结果可解读性更强。
2.模型验证
采用随机交叉验证。在所有用于训练神经网络的评论中,80%用于建模(含训练和评估),20%用来测试模型效果。在80%用于建模的评论中,采用随机交叉验证法,其中80%用于训练模型,20%用于评估模型每一次迭代训练的收敛效果。
3.运用两种目标函数(逻辑回归和支持向量机)
神经网络的目标函数,选择逻辑回归(categorical crossentropy)和支持向量机(hinge loss)进行比较分析。
(三)神经网络建模的结果
在建模中分别使用逻辑回归和支持向量机输出的总体满意度得分和预测准确率见表2。两种目标函数分别对应分布词袋模型(DBOW)、分布记忆模型(DM)以及两种方式的结合(DBOW+DM)等三种向量空间模型,进行建模。从整体满意度看,两种方法得到的评分水平比较相近;在预测准确率方面,逻辑回归略高于支持向量机,其中基于分布词袋模型(DBOW)的逻辑回归的准确率最高,达0.489。
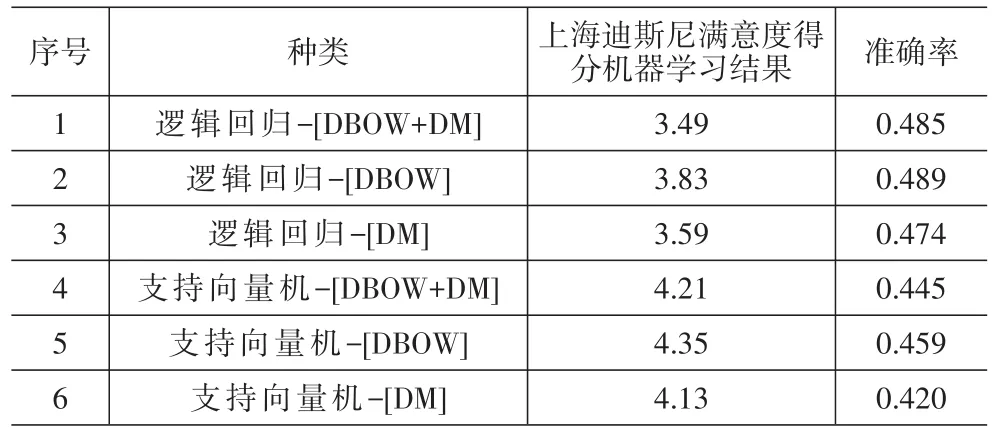
表2 两种目标函数建模结果比较
四、LDA主题模型
(一)LDA原理
由于神经网络模型输出结果仅能反映整体评价情况,不能提供细致的深入发现和认知,因此进一步引入LDA主题模型,挖掘文档集合中的重要主题。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。LDA可以找到产生文本的最佳主题和词汇,最大程度地表示文本中所蕴含的含义,信息丢失较少,能够较好地解决词汇、主题和文本之间的语义关联问题。
该模型假设:每个文本包含一定数量的隐含主题,每个主题包含特定的词;文本和词汇间的关系通过隐含主题体现;文本到主题服从狄利克雷(Dirichlet)分布,主题到词服从多项式分布。
(二)建模过程
对上海迪斯尼的评价文本按照标点符号进行分句,再进行分词处理,将得到的文档输入LDA模型。模型共设置20个分类,并在各分类中选取20个出现概率最高的关键词,自迭代500次(限于篇幅,此处省略LDA主题分类和关键词提取的输出结果表)。
(三)建模结果
通过关键词的解读,分析该项分类的具体特征,确定相对应的主题分类。在20个分类中,最终确定了15个分类,归入餐饮、排队时间、游玩设施、服务管理、游玩项目、交通、趣味性、园内演出和购物等9个主题;另外5个分类没有明显的含义,故未归入任何主题。并通过神经网络对上述9个主题进行文本情绪分析,即获得相应的满意度水平(见图2)。
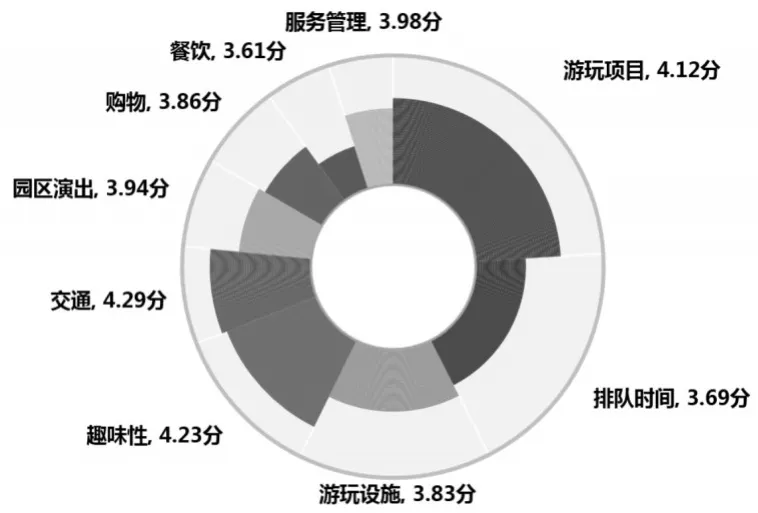
图2 逻辑回归(DBOW)分项主题评分结果
五、实证结论
(一)模型选择
比较分别采用支持向量机和逻辑回归作为目标函数的神经网络模型输出结果,分析其总体满意度和分项主题满意度打分的匹配度,我们可以发现,采用逻辑回归(DBOW)的方法得到的总体满意度为3.83分,而分项主题的加权平均满意度为3.96分,两者差异(0.13分)最小。其他5种方法的各分项满意度加权值均高于总体满意度,差异介于0.19-0.47分之间,相对较大(见表3)。由此可见,在神经网络建模过程中采用DBOW向量空间模型和逻辑回归目标函数,输出结果中总体和分项的匹配度更高,输出结果更为合理。
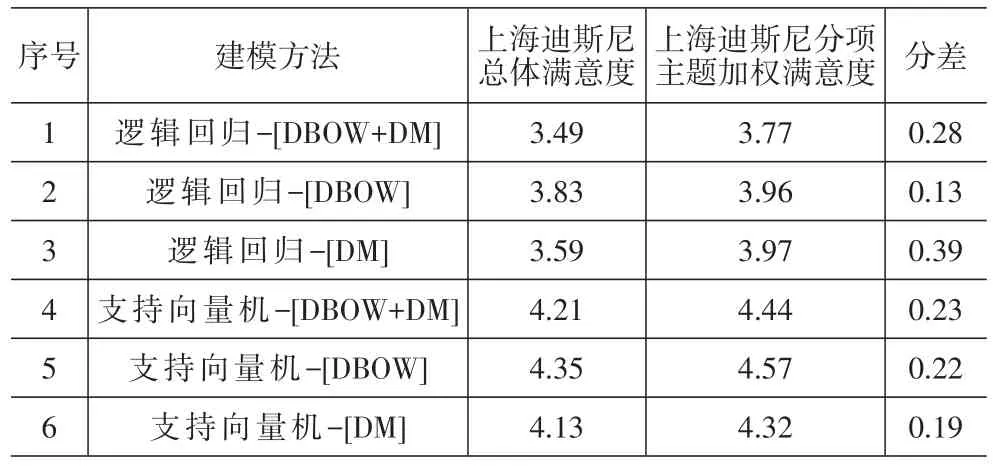
表3 两种目标函数建模结果比较
(二)主题模型实证结论
通过主题模型和神经网络模型,分别对上海、香港、东京等迪士尼乐园的相关主题分项进行满意度打分(见表4)。

表4 分项主题满意度评分结果
三大迪斯尼景区的游客对“趣味性”的满意度水平较高,均列前三位;而游客对“餐饮”的满意度水平普遍较低,上海和东京垫底,香港倒数第二。与香港和东京迪斯尼横向比较,上海迪斯尼尽管在“交通”、“趣味性”和“游乐项目”等方面的满意度水平较高,但仍存在以下薄弱环节:一是“餐饮”,游客对园区餐饮的价格、菜品以及用餐环境等方面的满意度较低;二是“排队时间”,入园排队以及项目排队时间较长对游客满意度影响较大;三是“游玩设施”,尤其是在园区试运行和开园次月中,游客对游玩设施的频繁故障维修、设备检修未及时告知等问题产生一定的不满情绪。因此,园区可集中针对上述当前较为突出的三方面问题,进一步加以重视和改善,从而更有针对性、更快速地提升游客满意度。
六、课题研究创新之处
(一)可量化:将定性文字转为满意度定量评价
多层神经网络建模能够对景点的文本评论进行情绪分析,从而客观打分。通过不断地加入新增的文字评论(即语料),机器学习的能力将不断增强,建模效果将不断提升。机器学习将定性文字评价转变为定量评估,从而更易于纵向和横向比较,不断深化数据挖掘和分析。以迪斯尼为例,基于大众点评、携程网等旅游网站关于香港迪斯尼乐园和上海迪斯尼乐园的文本评价,得到上海迪斯尼的满意度得分为3.83分,香港迪斯尼的满意度得分为4.23分。
(二)可洞察:运用主题模型认知对象维度结构
为了挖掘文档集合中的重要主题,LDA主题模型被引入进来。将5000多条有关上海迪斯尼的文本评价构建出9大主题,并获得相对应的满意度水平。课题研究分析表明,市民对游玩项目的关注度最高;对园区交通、趣味性的整体满意度较高;对餐饮、排队时间和游玩设施的满意度相对偏低,有待改善。
(三)可时点化:突破调查时间和空间上的局限
课题研究除了能同时掌握上海、香港和东京等不同地区迪斯尼同一时间段内的满意度水平,还能掌握景区在不同时间段内的满意度水平变化。以上海迪斯尼为例,保留了评论时间这一数据标签,课题组以“周”作为时间划分段,计算上海迪斯尼一段时间内的时点数据。通过数据发现,上海迪斯尼在试运行期间的满意度呈现下降态势;随着园区正式开园,满意度呈波动上行态势;但开园次月后,满意度呈现下降走势。
进一步分析分项主题满意度的走势(见图3),可以发现游客对“交通”、“趣味性”等的满意度评价较好且呈不断上升趋势,对“餐饮”等的满意度较低且基本呈下降趋势。对于“排队时间”、“购物”的满意度虽然较低,但是开园次月的满意度比试运行期和开园首月已有明显改善;对“游玩项目”的满意度虽较高,但开园次月的满意度却有一定下降。通过分项主题满意度走势分析,园区能够更为精准地发现影响整体满意度水平变化的主要因素、对某方面的改进措施是否起效、仍有待改进的方面在何处等问题。
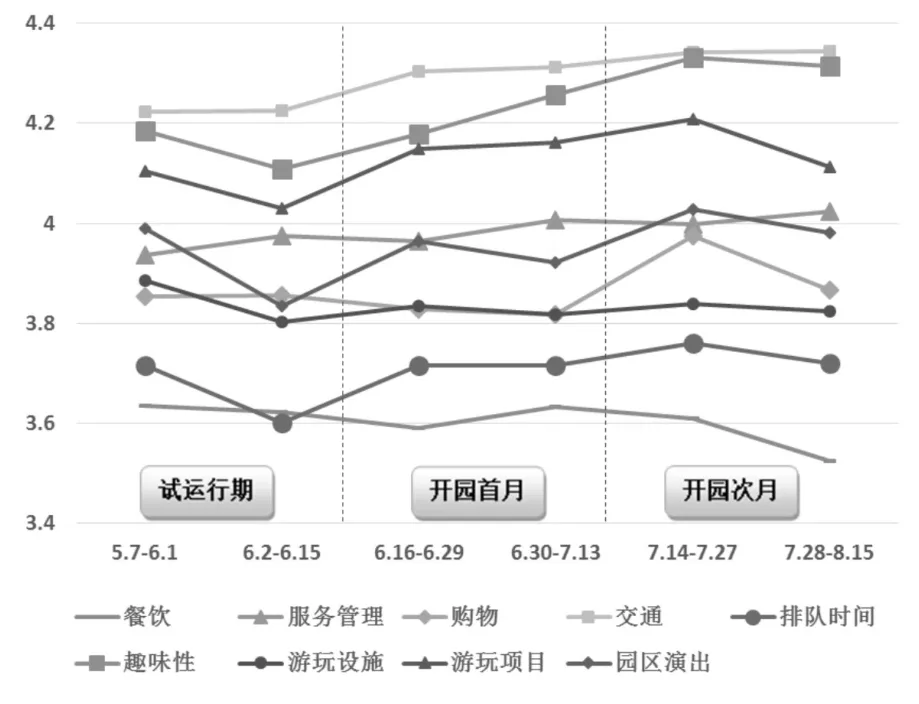
图3 上海迪斯尼分项主题游客满意度水平走势图
七、课题研究价值与改进方向
(一)课题研究价值
1.在调查时间和空间上突破传统调查局限性
传统调查时,需要在一段时期中开展不间断调查,往往耗费大量的人财物,所以往往在有限的经费预算情况下,采取抽样调查的方法,了解在这个时点上的调查结果。本课题突破了这种局限性,能在连续的时间并且在不同的空间中完成调查任务,达成传统调查难以完成的效果。
2.成为传统统计调查的有益补充甚至替代
通过机器学习加强对大数据的挖掘,尤其是对文本数据的挖掘和开发,是对传统的入户调查、拦截调查、电话调查等调查方式的一种有效补充,能够相互验证和评估。简而言之,大数据的数据导向方式与问卷调研的立论导向方式能够更好地配合,从而协助我们对研究问题更客观的理解和对研究结果更科学的评估。不断加深对机器学习技术的掌握,不但是提高统计效能的“利器”,甚至可成为传统统计调查的有益补充和替代。
3.对社会各领域的评价调查具有可复制、可推广性
本课题对文本数据的挖掘与开发模式,可进一步在其他旅游景点评价调查中加以复制推广,并可以延伸至公共服务评价、舆情监测、政策反馈等社会各领域中,尤其是同时涉及用户文字评价和打分的相关调查和研究。课题组在后续的研究中已将课题成果应用于上海市A级旅游景点调查和创建国家食品安全城市满意度评价调查,并将网络文本挖掘结果与传统调查结果进行比较分析。
(二)课题改进方向
一是数据源有待进一步拓展丰富,除了专门的评分类网站数据之外,可考虑纳入微信、微博等各类个人社交网络的评论、新闻评论、论坛帖子等相关文本。二是建模的效果受VSM、MLP等机器学习算法的参数值影响,如向量大小、神经网络各层的节点数、训练速率、迭代次数等。三是对文本情绪进行判别时,本文采用了神经网络+逻辑函数和神经网络+支持向量机两种方法,可考虑采用随机森林等其他模型进一步进行验证和优化。
(责任编辑:曹家乐)
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
