
MongoDB分页技术改进与优化
2015-12-31 17:20王振辉王振铎王静婷
计算技术与自动化 2015年3期
王振辉 王振铎 王静婷
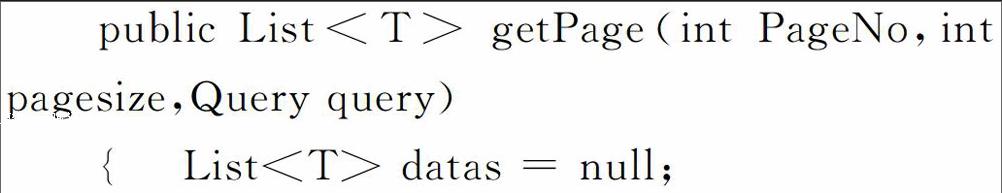


摘要:随着数据量的不断增加,使用MongoDB数据库内置的skip和limit组合分页算法效率低下,成为影响数据库访问性能提升的重要问题。从分析影响分页查询速度的关键因素入手,提出细粒度查询改进算法和where-limit算法。通过理论推导和与原算法的实验结果的比较,分析了两种新算法使用场景和优缺点。将两种算法应用于实际Web2.0日志系统应用中,取得了较好的效果。最后,对影响数据分页的其它因素进行了探讨,以更好的提高Web应用性能。
关键词:MongoDB;数据分页;索引;查询
中图分类号:TP311.13 文献标识码:A
1引言
互联网时代实际上是数据的时代,构建web2.0应用必然要涉及到海量数据的显示,数据分页显示技术也是开发过程中经常使用的数据显示方法,数据分页效率也是系统性能好坏的重要评价指标。MongoDB由于具有快速、可扩展性,丰富的编程接口及运维方便等特点,使其在大数据时代异军突起,为web2.0应用提供可扩展的高性能数据存储解决方案。MongoDB中使用limit函数限制返回的结果数,使用skip函数跳过指定条数的记录,所以使用limit并结合skip能够方便的实现数据分页显示。此种方法当数据量和并发访问量较小时,这样做分页完全没有问题。但是当数据量很大时,skip操作会变的很慢,所以有必要对MongoDB分页技术进行改进和优化,使得其在大数据查询和显示方面表现的更好。
目前,国内外对MongoDB分页技术改进方法主要有以下几种:一是限定结果集的页数,类似于搜索引擎结果分页策略,如:百度、谷歌的方法。虽然,显示找到的结果巨大,但用户能查看的只能是前60-70页的数据,这种方法由于限定结果记录在万条以下,所以,获取页面数据速度快,但显示的数据不全。第二种方法是把所有符合条件数据放在数组中,由于也是一次查询数据库,且放在内存中,所以,提高了数据分页的速度。但是,随着结果集数据的增大,对主机内存要求过大,容易造成内存溢出,Web应用稳定性受到影响,同时一次性返回所有记录,网络数据通信量较大,系统首次查询速度过慢。
2细粒度查询改进算法
2.1设计原理
MongoDB的查询优化方式简单直接,以查询模式为单位并行执行多种查询计划,选取速度最快的。查询模式的分类是按照查询的条件和排序涉及的字段及顺序进行划分的。其中排序字段的升序和降序对应的是不同的查询模式,选取的查询计划也不同,通常是相反的索引。MongoDB的查询模式分类仅考虑查询条件find和排序sort,并不考虑skip和limit函数。当执行查询结果分页显示时,需要使用skip函数跳过一部分数据。在海量数据下,当实际要读取的数据在sort排序的数据集后面时,skip的数量会很大,有时可以达到几万、十几万。遇到这样skip数量的查询,仍使用原sort排序的索引,速度会很慢。当MongoDB检测到该查询计划速度变慢时,会重新执行查询计划选取,若检测使用的查询也是skip很大的,会导致选取错误的索引,造成该查询模式正常查询的速度变慢。
针对上述问题,本文提出细粒度查询改进算法:使用count函数计算总记录数,并计算数据页数,在分析查询语句时,若有skip和limit操作,先计算跳过记录offset在整个查询结果集总数recno中占的百分比rate,若rate超过50%,则将该查询语句划分到反序的查询模式,转换为等价的反序的查询,这样就可以减少skip的数量,从而提高提高数据分页显示效率。算法改进流程图如下图1所示。
下面的代码给出了显示数据的后台核心代码:
2.2实验分析
为验证细粒度查询改进算法的效果,本文以Web日志系统为例,在结果集记录数recno分别为10万,30万,50万,比率rate分别为50%,55%,60%,80%的情况下,测试算法优化前后的页面数据显示在浏览器页面的速度,每个查询测10次,取平均值,结果如下表1所示:
由结果可知,数据量越大、Skip在总数据量中占的百分比越大,算法改进前后的速度差异越明显,效果越好。细粒度查询模式分类方法的确取得了较好的性能。
3Where-Limit优化算法
3.1设计原理
Where-Limit算法核心不是计算数据偏移量,而是传上一页的数据标记或关键词,根据where条件来查询实现分页,这种模式必须有一个连续的索引,才能通过直接指定位置,查找到要显示页的起始数据标记。方法是在程序启动时将所有数据关键词读取到数组中,需要分页的时候通过页码记录和数组下标的对应关系去查询页码首记录的数据标记,这样分页算法也体现了以空间换时间的思想。如果数据本身没有主键的,可以用MongoDB自带的ObjectId来查,由于基于索引,速度很快。算法原理图如下图2所示。
下面的代码给出了显示数据的后台核心代码:
3.2实验分析
为验证Where-limit算法的效果,本文同样以Web日志系统为例,在结果集记录数在10万,30万,50万的情况下查询最后一页的效率,测试算法优化前后的页面数据显示在浏览器页面的速度,每个查询测10次,取平均值,结果如下表2所示:
由结果可知,Where-limit方案由于每次只返回特定页面的数据,网络数据传输小,同时不再使用Skip函数,不仅比内置skip-limit,同样与细粒度查询改进算法比较,分页速度快且稳定可靠。唯一的缺点是关键词数组的大小会对服务器内存要求较高,但可以使用分割数组的方法解决。
4其它分页因素优化
为提高Web2.0数据分页响应速度,就要尽量节约带宽和提高查询速度。节约带宽,即不需要传输的数据就不要传输,已经查询的数据可以使用Ajax局部刷新技术,减少传输的数据,相当于节约了带宽。
查询速度提高,即在查询数据库时,不需要的字段和记录不返回,只回传需要的数据,因为Web页面主要操作都是与数据库打交道,数据库查询速度几乎是一个网站设计好坏的标准。MongoDB基于其提供的类似于关系数据库的索引机制实现复杂查询,数据查询的速度很大程度上取决于索引的使用。根据查询创建索引,必要时创建复合索引,MongoDB的查询优化方式简单直接,在选定了索引之后可以很好地提升性能,但在重复选择索引时会造成一定的开销,导致查询速度变慢。所以若某些应用场景下查询固定地使用一个索引可以达到最好的性能,程序中可以使用MongoDB提供的hint函数指定索引,避免数据库无谓的尝试。同时,使用优化方法使Mongodb数据库负载均匀,也可达到并发访问时优化服务的目的。
5结论
通过实验,可以看出,以上各种技术各有优缺点和适用场合。使用skip和limit适用于数据量比较少的数据分页,但随着数据偏移量变大,分页效率会大大降低。使用细粒度查询改进算法在一定程度上可以改进大数据情况下排序靠后的数据页的数据获取速度,但对获取结果集中间数据性能提高不大。Where-limit算法较细粒度查询改进算法通用性更好,其使用数组存取跳转页开始的关键词数据,使用条件和limit进行精确定位,无在结果中进行记录遍历情况,效率大大提高,但关键值数组在记录较大时对内存容量要求高,可以使用分割数组来进行优化,其次,对于大数据下的分页,各种方法必须建立索引,所以对增加和修改记录多的应用会造成一定性能影响。
