
关联性在军用信息库中的应用探究
2015-12-31 09:11周大庆
电子测试 2015年4期
周大庆
(92493 部队,辽宁葫芦岛,125000)
0 前言
美日太平洋战争中,美军的情报发挥了不可替代的作用,击毙山本、中途岛海战都可以说是情报战的胜利,而夏威夷战例则可视为美军情报战失败的例子。情报在二战中可以说是决定因素之一。而目前,随着计算机科技的发展,互联网、物联网已经步入了生活当中,现在已经处在信息爆炸的时代,信息不仅与人们的日常生活息息相关,而且作为情报的延伸,与军事范畴的建设及决策支持更是紧密相关。
对信息的处理,数据库建设显然是各种方案的首选。传统关系型数据库(如Oracle,原军用数据库标准)以其强大的关系处理技术及通用性强容易上手等优势在军用信息库建设中占据了较大的份额。但随着信息量的增大,以及军用信息的独特需求,传统关系型数据库并不能完全适应军用信息的要求。因此,本文在传统的关系数据库的基础上,利用信息的关联性建立一个类似中间件的构件来进一步紧密信息的联系,解决各表数据间的关联问题。
1 问题的描述

图1
现以一个实例的简化版本提出本文的问题。在我军执行某任务时,总有其它国家的侦查伴随其中,甚至可能会有电子干扰以及对抗的可能。对于对方某一技术兵器,我方可能会采用多种兵器去应对;且我方采用某种兵器去应对时,往往还需要与此兵器相关的数种兵器配合应用。如果采用传统的数据库技术提供支持,往往采用如下方式:
首先,对敌方兵器及我方兵器分门别类,提取字段,依复杂程度建立诸如侦察机表、卫星表等十数个甚至上百个表;其次,针对各个表,依字段建立数种查询、统计、筛选等功能模块。如图1。
此种方式并非不可行,但存在着如下三个问题。
⑴信息的缺失。
⑵针对某一对方兵器,我方的应对兵器往往可能跨越多个表,而且对方兵器不同,跨越的表也不同,这就给查询方式的提出了很难解决的问题。即便是给出了多表查询的功能,这种功能也只能是固定的,难以适应问题的需要;
⑶建立数据库的人员,往往并不从事兵器专业,即并非本数据库的使用人员;而使用人员对数据库也并非真正了解。这就容易造成数据表字段设计的不合理,而如果进行改动,涉及的不仅是本表相关的内容,还对多表查询的功能造成了影响。
以上问题并不仅仅存在于上述例子当中,在实际数据库建设中,此类问题常常存在,困扰着数据库的设计及代码编制人员。本文即以本例,利用关联方式,尝试解决此类问题。
2 问题的相关定义以及解决问题的基本流程
·聚类(Cluster)的定义:针对研究的对象(Object)集合,将其中具有一定特征(Feature)或相似性(Similar)的有限对象组织在一起,称之为一个聚类 。
·表聚类(tableCluster)的定义:表聚类是一个聚类,其研究对象为数据库中的表。
·泛化表(tableGeneralize)的定义:对于一个表聚类,将其共性提出,泛化为一个表,此表包括此表聚类中的每一个记录,且包含指向每个记录原位置的指针。
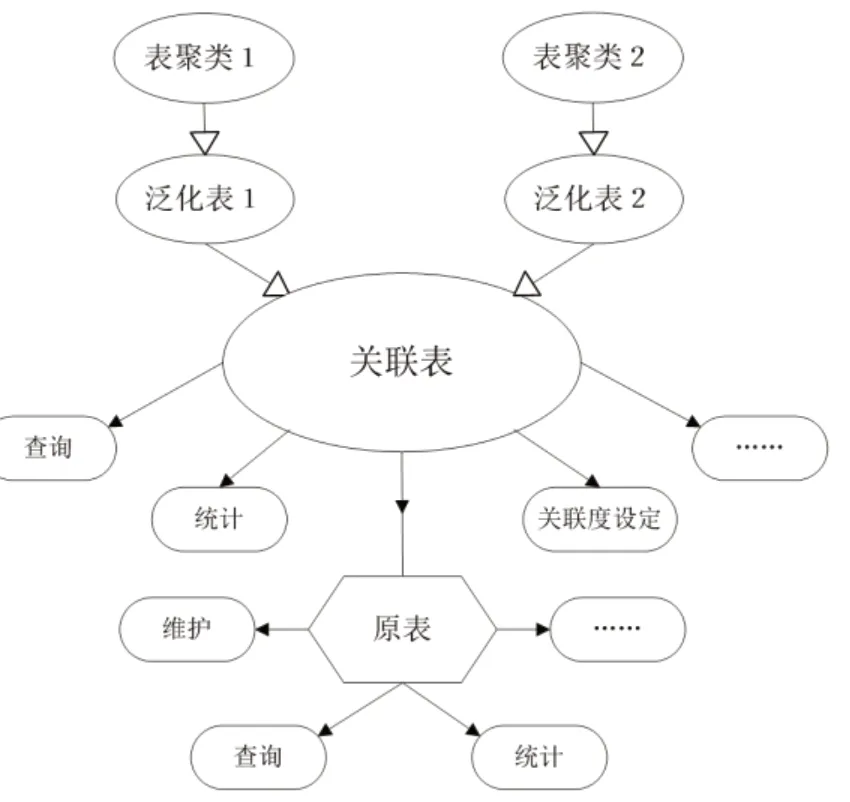
图2
·关联度的定义:关联度是一个二元组,对于两个表A与B,记A i 为表A的第i 个记录,记B j 为表B的第j 个记录,关联度记为R(Ai,Bj),表示Ai 与Bj 的关联密切程度,取值范围为[0,1)。当关联度取值为0时表示二者无关联,而取值越接近1则表示关联越密切。
·自关联度的定义:自关联度也是关联度,只是其关联是同一个表内两个记录的关联,记为R(Ai,Aj),且i ≠j。
·解决方法的流程如图2:
3 相关部分实例
因需要,建立某军用信息库,与本文相关有两个表聚类,一个为我方兵器信息表聚类,另一个为对方兵器信息表聚类。要求针对对方某技术兵器,提供我方采用何种兵器去应对的技术支持。本实例采用如下方法:
首先,对两个表聚类进行泛化,形成两个泛化表,分别为对方兵器信息表与我方兵器信息表,其中泛化表中包含所有表聚类的记录,并包含指向原表记录的指针;
其次,建立对方兵器信息全文表与我方兵器信息全文表,之所以建立此二表,主要原因有二:一是包含全文,可以尽可能的减少信息的缺失;二是全文数据量较大,从检索速度的提高上也需要全文部分单独建表;
第三,建立对方我方兵器关联表,此表为对方兵器信息表与我方兵器信息表的笛卡尔积,包含对方兵器与我方兵器信息的关联度,以及对兵器与我方兵器的指针;
第四,建立我主兵器自关联表,同上,此表为我方兵器信息表的自乘笛卡尔积,包含我方兵器的自关联信息及两个我方兵器的指针;

图3
第五,以关联表为主线,建立三层信息检索体系,第一层为对方我方兵器关联层次;第二层为我方兵器自关联层次;第三层提供对某一具体表的检索。
当得知对方某一技术兵器针对我方采取了行动,即从对方我方兵器关联表入手,找出与对方兵器关联度较高的多种我方兵器,为第一层次;通过人机交互,对于感兴趣的我方兵器,给出与我方兵器相关联的我方兵器集合,为第二层次;针对某一我方兵器集合中的元素,提供针对此元素所在原表的组合检索,为信息库使用人员提供更多的技术支持,此为第三层次。具体流程图如图3:
4 与传统信息库的对比分析
与传统信息库相比,本文方法有优点如下:
⑴信息缺失程度较少,本方法提供信息的全文,当原表的字段设计不能完全满足使用者的需求,使用者可以参阅全文来对其提供支持;
⑵本方法最大的优点,即是通过关联性的设置,能够较好的解决本文提出的问题二,即通过关联方式给出了灵活动态的多表查询模式,解决了如何针对对方某一兵器给出我方应对兵器的技术支持;
⑶当某一具体表出现问题时,并不会影响到此表以外的代码,较好的解决了问题三。
本方法提供了关联度数值在系统使用中的动态调整方法,有一定的客观性。
但本方法也有一定的缺点:
⑴信息冗余度相对较高,在表聚类的基础上建立了泛化表,这本身就是一种冗余;其次在泛化表中还需要包含指向原表的指针。二者都不符合数据库经典范式理论;
⑵对于关联度数值的确定,虽然给出了动态调整方法,但主要还是依照从事人员的经验来判断决定,还没有一个完整的理论体系给予支持,客观性并不充分;
⑶对于两个聚类,本方法使用效果较好,但如果问题涉及多个聚类,本方法使用价值不高。其实现复杂度以指数程度增加。如果勉强使用本文方法,只能是将多个聚类合并为两个聚类,效果如何只能具体问题具体分析了。
5 结论及未来研究方向
通过本文实例的实际使用,本文方法能够有效的解决本文提出的几个问题,能够对相关人员提供一定的决策支持,具有一定的实际意义与推广价值。
未来的研究方向主要集中在本方法的第二个缺点上,即如何给出及调整关联度的值,希望能建立一个较客观、相对完备的体系来评估兵器之间的关联。
[1] Cilibrasi R,Vitányi P M B.Clustering by compression[J].Information Theory,IEEE Transactions on,2005,51(4): 1523-1545.
[2] 孟小峰,周龙骧,王珊.数据库技术发展趋势[J].软件学报,2004,15(12):1822-1836.
[3] 王成良,柳玲,徐玲.数据库技术及应用[M].2011.
[4] 刘炜.关联数据:概念,技术及应用展望[J].大学图书馆学报,2011(2):5-12.
[5] 郑益,毛楚祥.传统数据库技术与信息检索技术的集成[J].计算机时代, 2010(8):1-3.
猜你喜欢
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
新生代(2018年16期)2018-11-13
中成药(2018年1期)2018-02-02
现代兵器(2017年10期)2017-10-14
现代兵器(2017年8期)2017-09-15
电脑知识与技术(2016年31期)2017-02-27
现代兵器(2016年8期)2016-08-15
郑州大学学报(理学版)(2013年2期)2013-03-11
中国烟草学报(2012年4期)2012-04-09
