
基于OpenStack的云存储系统的大文件存储方案
2015-12-23 01:07邵珠兴
计算机工程与设计 2015年2期
邵珠兴,陈 彩
(北京工业大学 计算机学院,北京100124)
0 引 言
目前面对海量数据的存储需求,传统的数据存储方案在存储容量、数据的可靠性、存储成本等方向存在很大的不足。云存储[1,2]具有自身独特的优势,可以动态、灵活地进行扩展和配置,使用户可以通过网络按需获得云存储的软硬件资源。OpenStack[3,4]是一个开源的云计算平台,它的对象存储服务Swift[5]可以用来构建冗余的、可扩展的分布式对象存储集群,存储容量可达PB 级,结合OpenStack的身份认证服务Keystone[6],可以提供安全可靠的云存储服务。对象存储服务Swift仍存在某些不足,Swift不能存储任意大小的文件,已有的解决方案为服务器端的解决方案,灵活性和扩展性较差。
本方案充分利用了对象存储服务Swift的优异特性,为了解决大文件存储的不足之处,设计并实现了GB 级大文件的存储方案。本文设计了云存储系统的层次架构,制定了大文件的存储策略,设计了上传和下载的核心流程,并用Java语言实现了本方案,最后通过实验验证了其可行性。本文所述方案为客户端解决方案,便于用户调用,易于扩展,突破了Swift对文件大小的限制,大大提高了文件的上传和下载速度。
1 OpenStack开源云平台
OpenStack是一个开源的云计算平台,通过多个相互联系的服务提供基础设施即服务 (infrastructure as a service,IaaS)类型的解决方案。各个服务之间通过各自的REST风格的API相互联系。根据用户的需求,可以安装Open-Stack的部分或全部服务,建立公有或私有云存储服务[7]。OpenStack主要包含以下几个服务:计算服务 (项目名称为Nova)、对象存储服务 (项目名称为Swift)、镜像服务 (项目名称为Glance)、身份认证服务 (项目名称为Keystone)、网络服务和块存储服务[8]。
Swift是OpenStack开源云计算项目的子项目之一,提供了强大的扩展性、冗余性和持久性。Swift是一个对象存储系统,所有数据以 “对象”的形式组织。本文中,客户端磁盘上的数据实体称为 “文件”,云存储端的数据实体称为 “对象”。Swift主要有3 个组成部分:Proxy Server、Storage Server和Consistency Server。Proxy server 是服务的入口,负责将Swift架构整合起来。Consistency Server负责查找并解决由数据损坏和硬件故障引起的错误。Storage Server提供了磁盘设备上的存储服务。Swift中的数据分三级来组织:账户 (account)、容器 (container)和对象(object)[9],一个账户包含多个容器,一个容器包含多个对象。Swift规定云存储端的一个对象的大小不能超过5GB。Swift已有的大文件解决方案:静态大对象 (static large objects)存储方案和动态大对象 (dynamic large objects)存储方案[10],都是Swift服务端的存储方案,在灵活性、扩展性等方面存在一定的不足。
Keystone主要包含两个功能:管理用户以及用户的权限,提供服务的目录和它们的API。可以通过Keystone和Swift之间的相互协作,完成用户信息的认证和授权,以及每次请求的权限验证。
本文主要关注GB级大文件的存储,应用Swift提供的基本对象存储服务,在客户端解决大于5GB文件的存储问题。
2 大文件存储方案
2.1 云存储的架构设计
为了安全、快速的存储GB 级大文件,本文将云存储的架构和内部模块做如下分层设计,如图1所示。云存储系统主要分两部分:服务器端和客户端,服务器端由原生的对象存储服务Swift和身份认证服务Keystone构成,所有的存储方案在客户端实现。整体结构主要分如下四层:
表示层,与用户交互,可以配置用户的认证信息、线程池的数量等等,为用户提供上传文件和下载文件的同步和异步接口。
逻辑层,为用户提供逻辑和控制功能,包括存储策略、用户的认证和授权、复杂任务的工作流、任务的调度、日志记录等,存储策略是本文的重点研究的内容。
服务层,为上层提供对象存储服务和身份认证服务。最下层为资源层,包括磁盘、网络交换机、路由器,还是其它的一些资源。
2.2 大文件存储策略
简单来说,存储策略是:上传一个大文件时,把一个大文件拆分为一系列小文件,分别上传到云存储端。下载时,再把这些小文件合并为一个大文件。在云存储端,用两种类型的对象来代替一个大的对象:

图1 云存储层次架构
(1)片段对象 (segment object):把一个大文件拆分成小的片段,分别作为一个单独的对象上传这些片段,这些对象称为片段对象。
(2)清单对象 (manifest object):清单对象的功能是记录构成一个大文件的所有片段对象的信息,包括片段对象所在的容器名称 (container name)、片段对象的名字(segment object name)、片 段 对 象 在 大 文 件 中 的 偏 移 量(offset)、片段对象的二进制数据长度 (segment length)。根据这些信息,可以把一个大文件拆分为一组片段,并且可以把一组片段重新合成为原文件。
也就是说,一个大文件在云存储端由唯一的清单对象和一组片段对象构成。片段对象与一般的对象没有任何区别,但是清单对象很特别,它代表了磁盘中的大文件,当下载清单对象时,需要把所有的片段对象连接成一个整体返回给用户;当查询清单对象的信息时,清单对象的元数据代表了大文件的相关属性。为了便于组织信息,把所有的片段对象信息序列化为JSON 格式的字符串,作为清单对象的内容。所以清单对象的内容就是JSON 格式的所有片段对象信息的列表。根据容器名称和片段对象的名称,可以定位云存储端片段对象的位置,根据偏移量和片段大小,可以定位片段对象在原文件中的位置,所以JSON 格式的片段信息列表中,片段信息不需要按照它们在原文件中的顺序排列。例如,一个视频文件为graduate.mp4,其大小为5400 M,假设以片段大小150 M 拆分此文件,则其清单对象的内容为:


文件往往有一些属性需要存储在云存储端,由于清单对象与原文件是一一对应关系,因此可以用清单对象的元数据代表原文件的元数据,即原文件的相关属性。为了便于进行文件的校验和下载,清单对象必须具备以下两个自定义元数据:
(1)X-Object-Meta-Etag,原 始 文 件 的MD5 校 验 值,用于下载文件后对下载文件进行MD5校验;
(2)X-Object-Meta-Length,原始文件的总长度。
对象存储服务Swift定义了对象的很多固有元数据,所有对象,包括片段对象和清单对象,必须具备以下两个元数据:
(1)Content-Type,清单对象的内容类型为JSON 格式,所以其值为application/json;一般对象包括片段对象的值为application/octet-stream。
(2)Etag,作为整体上传的一般对象的Etag值为整个文件的MD5 校验值,片段对象的Etag 值为文件片段的MD5校验值,清单对象的Etag值为JSON 字符串的MD5校验值。上传文件时,在Http Header 中添加Etag 值,Swift会在上传结束后对比服务器端的对象的MD5 值与Etag值,以确保传输前后数据的一致性。
2.3 核心流程设计
为了在上传、下载过程中,保证数据在客户端、服务器端的一致性,上传、下载、查询必须按照一定的流程,遵循一致的协议。上传文件时,需要先根据文件的大小确定是否需要分割上传,如果需要分割,将文件转换为一组片段对象和一个清单对象,其核心流程如图2所示。为了确保数据在客户端和云存储端是一致的,上传整个文件、上传文件片段和上传清单对象时,都要计算数据的MD5校验值,在上传HTTP 请求的Header中加入Etag 键值对,Swift会根据Etag值完成数据的一致性校验。在上传清单对象时,除了计算其JSON 字符串的MD5校验值,还需要计算整个大文件的MD5校验值,作为X-Object-Meta-Etag键值对加入Http Header中。
下载文件的核心流程与上传文件的流程相对应。云存储中的清单对象代表了一个大文件,其记录了组成大文件的片段对象的相关信息,云存储中的一般对象可能代表了一个没有分割上传的文件,也可能代表了一个大文件的一个片段。所以,对于待下载的云端对象,必须先验证此对象是清单对象还是一般对象,然后再分别做不同的处理,其流程如图3所示。图中的两种下载方式的最后都需要比较下载后的文件的MD5 校验值和原文件的MD5 校验值,以确保文件的一致性。如果文件对应一个对象,则文件的MD5校验值为对象的Etag值,如果文件对应一个清单对象和一组片段对象,则文件的MD5 校验值为清单对象的XObject-Meta-Etag值。

图2 上传流程

图3 下载流程
2.4 关键模块设计与实现
当用户调用云存储客户端的上传命令时,会把上传任务转交给UploadHandler,UploadHandler主要有4个方法:预处理任务、处理上传任务、处理后续任务、处理程序异常。预处理任务主要进行文件分段、计算各个片段的MD5值;上传任务包括上传一般的对象 (包括上传片段对象)和上传清单对象。预处理任务和上传任务涉及到读取硬盘、网络通信,可能会导致程序阻塞,因此执行预处理任务和上传任务时,为了提高处理速度,UploadHandler会把任务交给线程池来执行。片段对象和清单对象可以按照任意顺序上传,所以上传任务非常适合由多线程来执行。详细的上传过程如图4所示。

图4 上传文件时序
下载文件功能由DownloadHandler 实现,DownloadHandler和UploadHandler实现了相同的接口,它们具有同样的4个方法:预处理任务、处理任务、处理后续任务、处理程序异常。预处理任务、下载文件、文件的MD5校验这3个过程涉及网络通信和硬盘访问,为了提高执行速度,这3个任务会交给线程池来执行。其主要原理与上传相对应,细节不再详述。下载过程中,所有的片段对象都下载完毕,并 “合并”成一个大文件后才能进行MD5校验,因此需要保证下载片段文件和MD5 校验先后次序正确。片段对象合并成原文件的操作,是在下载的过程中直接进行 “合并”,通过RandomAccessFile,直接依照片段对象的偏移量写入到原文件的指定位置,当所有的片段文件都下载完毕,原文件就完整的下载到了磁盘上了。
3 验证与分析
3.1 实验环境部署
在实验环境中,选用了5台服务器搭建云存储系统:1台服务器作为认证节点,用于运行keystone服务;1 台服务器作为代理节点,用于运行Proxy service;其余3台服务器作为存储节点,用于运行Account service、Container service和Object service[11]。在真实运行环境中,可以添加存储节点以增加存储容量,可以添加代理节点以分散用户的请求。本实验环境可以模拟真实的运行环境,因此实验结果有意义。图5所示为实验环境中的云存储部署结构。
3.2 实验结构及分析
测试本方案的可行性。测试文件大小为5598 M,已经超过了对象存储服务Swift最高存储5GB的限制。作为一个整体直接上传该文件,HTTP 请求返回的状态码为413,返回的错误提示为:Request Entity Too Large,The body of your request was too large for this server。说明直接上传一个超过5GB 的大文件是不成功的。用本方案上传该文件,云存储客户端按照预先设定的片段大小分割文件,将一组片段对象和一个清单对象上传到云存储端,并通过片段对象和清单对象的MD5校验确定了云存储端和客户端是一致。接着,用本方案下载该文件,云存储客户端会根据清单对象,把组成此文件的所有片段下载到客户端并合并成一个文件,通过验证下载的文件的MD5值确定了此文件与上传前的文件是一致的。因此,证明了本方案是可行的,上传和下载过程中都能保证客户端和云存储端数据的一致性,解决了Swift中对象不能超过5G 的限制。

图5 云存储系统部署
测试文件的上传时间。上传GB 级文件时,本文用了两种方式上传并作了对比,一种方式是本文所述方案,即大文件分割上传;第二种是原始的上传方式,即大文件作为一个整体上传,但这种方式只能用于上传小于5G 的文件。这两种方式上传同一个文件的时间对比如图6 所示。可以看到对于同样大小的文件,分割上传比整体上传节省时间。设节省时间比= (整体上传的时间-分割上传的时间)/整体上传的时间,则平均节省时间百分比为10.17。

图6 上传文件时间折线
测试文件的下载时间。在下载实验之前,将GB 级大文件用上文所述的两种方式上传到云存储中,所以同一个文件,一是作为一个整体存储在云存储服务中,二是文件作为片段存储在云存储服务。然后下载两种形式的对象,下载所需要的时间对比如图7所示。从图中可以看出,下载片段形式的对象比下载整体形式的对象更节省时间,其平均节省时间百分比为34.12。
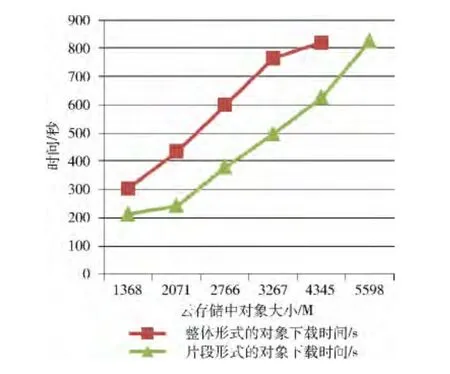
图7 下载文件时间折线
4 结束语
开源云平台OpenStack的对象存储服务Swift具有强大的扩展性、冗余性和持久性等特点,同时在大文件存储方面也有其不足之处。本文为解决GB 级大文件存储问题,设计了云存储系统的层次架构,制定了大文件的上传和下载策略,设计了上传和下载的核心流程,并用Java语言实现了本方案。本方案不同于Swift的静态大对象存储方案和动态大对象存储方案,是一个客户端的大文件存储方案,易于调用,便于扩展。通过实验结果表明了本方案是可行的,成功的存储了大于5GB的文件,并且提高了的GB级大文件的上传速度和下载速度。
[1]ZENG Wenying,ZHAO Yuelong,SHANG Min.Research on cloud computing and cloud storage ecosystem [J].Journal of Computer Research and Development,2011 (S1):234-239(in Chinese).[曾文英,赵跃龙,尚敏.云计算及云存储生态系统研究 [J].计算机研究与发展,2011 (S1):234-239].
[2]Grossman R L,Gu Y H,Sabala M,et al.Compute and storage clouds using wide area high performance networks [J].Future Generation Computer Systems-the International Journal of Grid Computing Theory Methods and Applications,2009,25 (2):179-183.
[3]Wen Xiaolong,Gu Genqiang,Li Qingchun,et al.Comparison of open-source cloud management platforms:OpenStack and OpenNebula[C]//9th International Conference on Fuzzy Systems and Knowledge Discovery,2012:2457-2461.
[4]Von Laszewski Gregor,Diaz Javier,Wang Fugang,et al.Comparison of multiple cloud frameworks[C]//IEEE 5th International Conference on Cloud Computing,2012:734-741.
[5]Swift 1.12.0.113.g076634edocumentation[EB/OL].[2014-02-20].http://docs.openstack.org/developer/swift/.
[6]Keystone 2014.1.dev449.ge2ce639documentation [EB/OL].[2014-02-20].http://docs.openstack.org/developer/keystone/.
[7]Toor Salman,Toebbicke Rainer,Resines Maitane Zotes,et al.Investigating an open source cloud storage infrastructure for CERN-Specific data analysis [C]//IEEE 7th International Confe-rence on Networking,Architecture and Storage,2012:84-88.
[8]Bonner S,Pulley C,Kureshi I,et al.Using OpenStack to improve student experience in an H.E.environment [C]//Science and Information Conference,2013:888-893.
[9]JIANG Yi,SUN Xuetao,YANG Chuan.Swift cloud storage environment based on I/O load balanced reading strategies[J].Computer Engineering and Design,2013,34 (9):3024-3027(in Chinese).[蒋溢,孙雪涛,杨川.Swift云存储环境下基于I/O 负载均衡的读取策略 [J].计算机工程与设计,2013,34 (9):3024-3027.]
[10]OpenStack object storage API v1reference-API v1 [EB/OL].[2014-02-20].http://docs.openstack.org/api/openstack-object-storage/1.0/content/.
[11]OpenStack Installation guide for Ubuntu 12.04(LTS)-havana[EB/OL]. [2014-02-20].http://docs.openstack.org/havana/install-guide/install/apt/content/.
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
传媒评论(2019年5期)2019-08-30
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
意林(2018年3期)2018-03-02
中国铸造装备与技术(2017年6期)2018-01-22
厦门理工学院学报(2016年1期)2016-12-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电测与仪表(2015年1期)2015-04-09
电测与仪表(2015年19期)2015-04-09
