
交通场景的多视觉特征图像分割方法
2015-12-22 11:35邓燕子卢朝阳
西安电子科技大学学报 2015年6期
邓燕子,卢朝阳,李 静
(西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西西安 710071)
交通场景的多视觉特征图像分割方法
邓燕子,卢朝阳,李 静
(西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西西安 710071)
针对场景分割中基于像素分类计算较为复杂,使用特征类别较少难以提高分类精度的缺点,提出一种新的基于超像素多种视觉特征来学习场景几何结构类别的模型.首先,在图像超像素基础上进行多视觉特征提取;然后,利用这些特征对超像素进行分类,再计算相邻超像素视觉特征的差异,推断相邻超像素类别的一致性;最后,用初始分类和一致性分类结果构造基于马尔科夫随机场模型的能量函数,使用基于图割的优化方法确定超像素的类别.实验结果表明,该方法对特征的选择以及分类优化算法能够有效提高分类的精度,对交通场景能够实现较好的分割效果.
场景分割算法;超像素;多视觉特征提取;随机森林回归;马尔科夫随机场
交通场景理解是实现图像检索、智能监控、智能路障检测和无人车导航等应用的关键技术之一,交通场景图像分割是将图像中的物体分割出来并判断其种类,也称为图像解析[1].与普通的图像分割[2]不同,场景分割算法的目的是将图像转化为有利于目标表达更抽象的表现形式,简化场景的表示方式,使高层的场景理解和分析变得容易.交通场景分割的困难在于自然环境的光照不均匀、场景结构不均匀和内容复杂多变等因素.文中研究场景的空间结构分割方法,即将图像标记成不同的几何结构类别.文献[3]最早对自然场景图像的空间几何结构进行阐述,通常将其分为天空、地面和地面上的各类垂直物[3];对交通场景空间几何结构的分割也是将图像分成天空、地面和垂直物,重建图像的表面布局.
近年来,学者们提出了很多场景分割算法.传统方法一般是基于像素的[4-6],用分类器逐像素进行分类后,使用马尔科夫随机场(Markov Random Field,MRF)或条件随机场(Conditional Random Field,CRF)将所有类别组合在一起;该方法的缺点是需要对每类进行训练,对每个像素进行分类是比较复杂和耗时的过程,无法做到实时.目前比较流行的是基于超像素的方法[3,7-9].超像素是图像中具有相同视觉特性的连续区域,使用超像素特征对其进行分类,可以解决逐像素进行操作造成运算复杂的缺点,不仅能够提高分割算法的计算效率,且能够提供较好的空间结构支持[1].
选择正确的特征来表示超像素能够提高分类精度,笔者主要的思想是基于超像素的表面特征来学习这些几何结构类别的模型;创新点是提出适用于交通场景分割的多视觉特征提取表示方法以及基于MRF模型的分类结果优化方法.首先,在图像的超像素基础上进行多视觉特征提取;然后,利用这些特征对超像素进行分类,并利用相邻超像素视觉特征的差异计算相邻超像素类别的一致性;最后,用初始分类和一致性分类结果构造MRF模型的能量函数,使用图割的优化方法确定超像素的类别,实现场景空间结构分割.实验结果表明,笔者提出的方法对交通场景的空间几何结构能进行较好的分割.
1 超像素的多视觉特征提取
使用超像素来表示图像,可通过对超像素进行分类实现场景的分割.超像素分割是一种过分割方法,能够将图像划分成连续均匀的小块区域.用超像素表示图像的优点很多,如图像超像素数量远远小于像素个数,可极大减少分类的计算量,但图像中像边缘和物体轮廓等这些重要特性仍能较好地保留.文中采用文献[10]的方法进行超像素分割,若使用这种方法参数设置的不当,则很难捕获真实的物体边界,分的过粗会丢失小的物体,分的过细许多超像素的特征则难以区分.具体参数的设置:σ=0.8,K=100,M=100,一幅800×600大小的交通场景图像通常分割出大约500个超像素.图1是图像进行超像素分割后的结果.
图像中不同物体具有不同的视觉特性,常用于描述物体的视觉特征有颜色、纹理、位置和形状等.由于交通场景具有复杂性,包含的物体种类很多,一些较大的物体如天空、建筑物、树木等没有固定的形状,而较小的物体如行人和车辆等,形状比较固定,但颜色和纹理等都各不相同[11].为实现对超像素的正确分类,需要用多种特征来表示超像素.在采用颜色、纹理和位置形状的基础上,为更好地描述交通场景各类物体的几何结构,加入了结构信息特征.目前很多场景理解方法[12-13]通过结构信息对物体进行分类.结构信息可通过一些光照不变性特征来描述,如尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)[14]和方向梯度直方图(Histogram of Oriented Gradient,HOG)特征[15].
这里两种结构信息特征都采用稠密的提取方式,对图像的每个点根据周围的邻域信息计算特征向量,超像素的特征向量是其中所有像素特征向量的均值,得到超像素的SIFT特性向量为128维,HOG特性向量为31维.表1列出了用于描述超像素的视觉特征,包含颜色(C1~C4)、纹理(T1,T2)、结构信息(S1,S2)和位置形状(L1~L5)这4类特征,最终构成211维的特征描述符.超像素的特征向量fs=[C1,…,C4,T1,T2,S1,S2,L1,…,L5]∈R211.
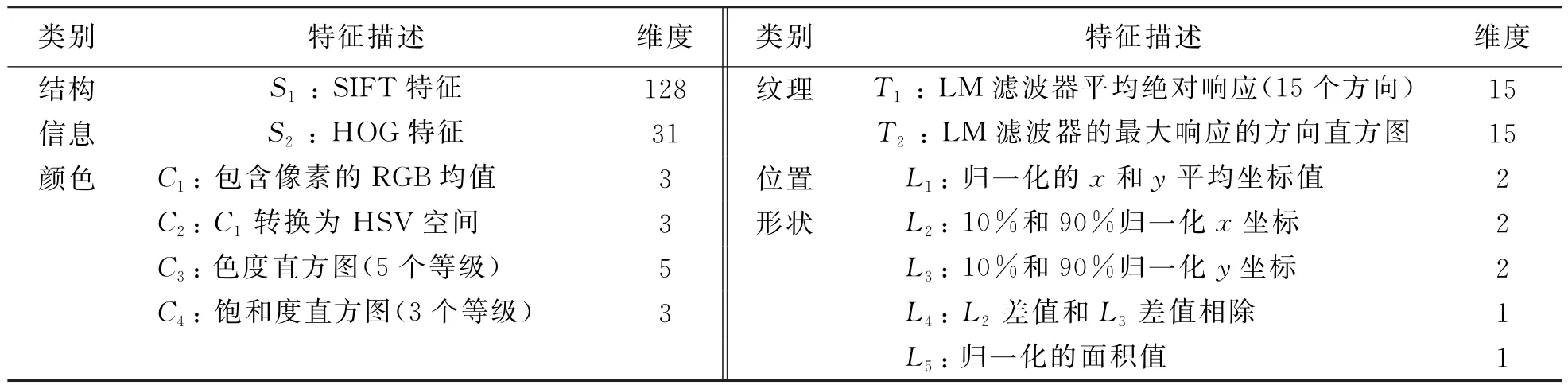
表1 描述超像素的视觉特征
2 超像素分类
在得到图像所有的超像素并提取多视觉特征后,利用超像素的特征对其进行分类,得到每个超像素的几何结构类别.传统的分类方法通常给分类器输入正负样本,输出是代表某一类别的离散值,比如常见的0和1二值输出.由于实验中采用所有训练图像的超像素多视觉特征作为训练样本,采用传统方法既无法保证每幅测试图像的超像素都能被正确分类,也无法保证所有测试图像的分类结果都有稳定的正确率.为此,文中训练了随机森林回归器[16],其优点是效率较高且能够输出连续的标签值,代表和真实值的接近程度;之后,使用这些“软标签”作为待优化的能量函数的数据项,将超像素分成天空、地面和垂直物3类,因此,需要训练3个回归器,用于估计超像素属于这3种类别的程度,所有的训练过程都使用相同的特征.训练方法以“天空”类别为例,将所有训练图像的超像素特征分成两类,属于天空的特征集合Fsky和非天空的特征集合Fnonsky,并赋予标签值1和-1,训练得到回归器Hsky.测试时输入超像素特征fs,对应的输出值是介于-1到 1之间的实数,Hsky(fs)∈[-1,1].用同样的训练方法得到另外两个回归器Hvertical和Hground.

图1 交通场景的超像素分割
利用超像素的多视觉特征进行分类,只考虑了超像素本身的属性,忽略了它们之间的关系.在进行超像素分割时,一些相同属性类别的物体会被分成多个超像素.这些相邻的同类超像素的特征具有相似性,而相邻的不同类别的超像素之间特征差异很大.如图1所示,街道上相邻的超像素看上去一样,而街道和两边墙壁相邻的超像素看上去差别很大.当初始分类结果不能判断超像素的类别时,希望能通过相邻的超像素之间的关系来确定其类别,因此,需要训练分类器来推断相邻超像素类别的一致性.这里设计了相邻超像素的对比特征来训练这种一致性分类器.对比特征定义为相邻超像素视觉特征的差异,设两个相邻超像素si和sj的视觉特征分别为和,g表示对比特征,对比特征.由于视觉特征包含4类不同特征,需要采用不同方法计算差异.采用文献[3]中的计算方法,对颜色均值、LM滤波器响应、SIFT和HOG特征,计算两个特征向量x1和x2的绝对差值,即

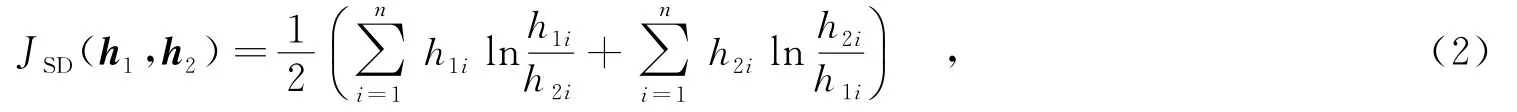
其中,h1和h2代表两个直方图,h1i和h2i分别是向量h1和h2中的元素,n是h1和h2向量中元素的个数.
计算两个超像素特征差异后得到一个188维的向量,用其训练一致性分类器Hsame,训练方法和前面所用的随机森林回归器相同.对训练集的所有图像,统计所有相邻的超像素对,并计算对比特征.超像素对属同一类时的对比特征为正样本,属不同类别时的特征为负样本,标签分别为1和-1.一致性分类器输出也是连续值Hsame(g(si,sj))∈[-1,1],代表相邻的超像素是否一致的程度.
得到初始分类和一致性分类结果后,希望用其计算超像素最终的分类结果,为此,文中提出了基于MRF能量函数最小化的分类结果优化方法.将分类问题表示成能量函数的最小化,在像素级类别标记问题中应用非常广泛.通常给定一组像素和标签集合,找到这些像素最佳的标签,使设计的能量函数值最小.能量函数一般包含数据项和平滑项,分别是标签变量的一元和二元函数,数据项体现真实值和观测值的一致程度,平滑项体现图像的局部空间内平滑特性[17].
对超像素进行分类时采用MRF能量函数最小化方法,对一幅输入图像,设超像素集合Sp={sk},类别标签的集合L={G,V,S},G、V、S分别表示标签“地面”、“垂直物”、“天空”,目的是为每个超像素找到最佳标签,使MRF能量函数最小,函数定义为
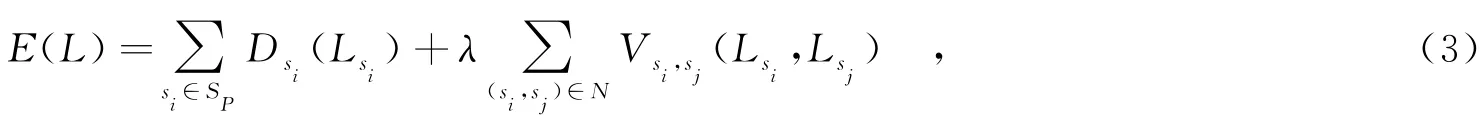
其中,N是所有相邻超像素对的集合,系数λ≥0用于调节数据项和平滑项的比重,数据项函数Ds(·)表示将超像素si标记为某个类别的代价,平滑项函数Vsi,sj(·)表示将相邻超像素对标记为两个类别时的代价.这里采用potts模型[18]作为平滑项代价函数,平滑项函数的定义为
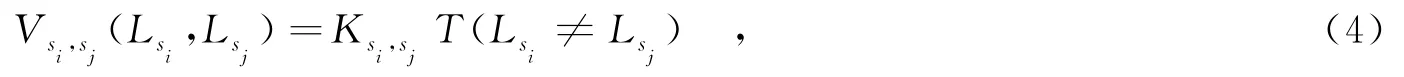
其中,权值K是非负常数,其取值和两个超像素的特征相关,函数T(·)中的条件表达式为真时,函数值为1;反之,其值为0.相邻的超像素取不同标签时得到不同的代价值,能够起到保持边缘的作用[18].由于平滑项是非凸函数,能量函数的优化求解比较困难,文中使用图割算法[19]对能量函数最小化问题进行求解.通过初始分类和一致性分类,可得到每个超像素属于3个类别的程度值,以及相邻超像素对属于同一类别的程度值,将它们分别作为能量函数的数据项和平滑项的权值.上述分类结果取值范围都是[-1,1],图割算法中的数据项和平滑项都需要是正数,需要把这些数值变为正值,具体设置为
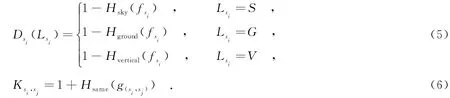
整个能量函数构造完成后,采用a-expansion算法[19]对最小化问题进行求解,得到超像素最终的分类标签.
当所施加外应力值介于最后一级荷载和长期强度值之间时,将岩石试样根据常规三轴压缩时,计算出强度参数C和φ值代入α和k的函数中,然后代入式(4)中,得
整个分类及优化算法的步骤如下:
(1)输入图像进行过分割得到超像素块,提取它的多视觉特征,并同时计算相邻超像素对的对比特征.
(2)将多视觉特征输入到3种属性(地面、垂直物和天空)分类器,得到初始分类结果;利用对比特征计算出一致性分类结果.
(3)构建图模型,所有超像素为普通节点,3个类别为顶点;利用相邻的超像素之间的连接以及所有超像素到3个顶点的连接,构成边集合;所有相邻的超像素对构成图的邻域结构.
(4)将初始分类结果作为数据项,一致性分类结果作为平滑项的权值,并代入能量函数.
(5)执行基于a-expansion的图割算法.
(6)输出所有超像素的类别标签.
3 实验及分析
文中算法在Hoiem[3]提供的数据库上进行实验,计算机的配置为Intel E7400/2G RAM,MatlabR2012a,在混合编程情况下完成.Hoiem 3-类几何上下文(3-class GC)数据库中每幅图像的超像素都标记了真值,从中挑选空间结构比较完整的100幅交通场景图像作为实验数据,其中,训练图像60幅,测试图像40幅.实验部分将和现有的基于区域分割方法进行比较,为了说明加入特征的有效性,将这两种情况下训练出来的分类器的性能进行对比.评价方法采用受试者工作特征(Receiver Operation Characteristics,ROC)曲线法,3种属性分类器的ROC曲线如图2所示.
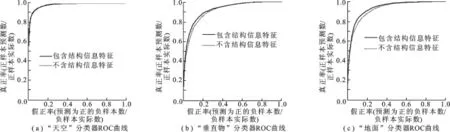
图2 不同特征训练的3种属性分类器ROC曲线
对3种分类器分别比较不同特征的ROC曲线,可以看到,“天空”分类器在两种情况下的性能没有明显变化,而“地面”和“垂直物”分类器在使用结构信息特征后性能均得到提升.这是因为大部分图像天空区域较均匀,结构信息并不丰富,而不同环境下地面和垂直物区域图像的内容比较复杂,含有较多的纹理结构信息.说明笔者对特征的选择对场景的分类是有效的.
将文中提出的分类优化方法与文献[3]的方法进行比较,评价方法与文献[3]相同,使用混淆矩阵和正确率,其中,正确率定义为测试图像正确分类的像素占所有像素的百分比.图3所示是文中方法和文献[3]方法分类结果的混淆矩阵,从图3中可以看出,文中方法对3类几何结构分类的效果比文献[3]的都有提升.
为了验证文中方法对普通室外场景分割的有效性,将方法在3-class GC数据库[3]上的总体分类正确率与文献[3,7]进行对比,比较结果如表2所示.可以看到,文中方法在分类精度上优于文献[3,7]的方法.
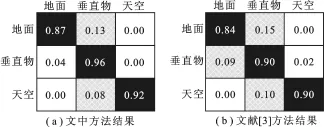
图3 文中方法和文献[3]方法分类的混淆矩阵

表2 文中方法和文献[3,7]方法正确率的对比
文中方法的部分实验结果如图4所示.天空、地面和垂直物3种类别分别用黑、白、灰3种颜色标记.从图4中可以看出,文中方法的分类结果和真实值非常接近,但有些细节部分出现错误,如树枝中间的天空标记成了垂直物,天空区域中的电线等较细的结构没有标记成垂直物.对图像交通场景中细微物体的处理应该是下一步需要改进的地方.从图4可以看到,文中采用的图像空间结构比较完整,即3种几何类别在图像中所占比例较均匀.而实验发现若场景结构比较复杂,如图像大部分路面被车辆遮挡时,分类效果较差.因此,文中方法对这种空间结构较完整的图像分割效果较好.

图4 文中方法分割的结果
4 结束语
笔者提出一种新的交通场景空间几何结构分割方法,输入图像在分割出的超像素基础上提取多视觉特征,包括颜色、纹理、结构信息和位置形状这4类特征,用特征训练3种几何结构分类器对超像素进行初始分类;再计算相邻超像素的对比特征,用于训练一致性分类器来推断相邻超像素之间的关系;最后,用初始分类和一致性分类结果构造基于MRF模型的能量函数,使用图割的优化方法确定超像素的类别.实验结果表明,笔者对特征的选择以及提出的分类优化方法能够有效提高分类的精度,能够有效用于空间结构较完整的交通场景图像分割.
[1]Tighe J,Lazebnik S.Superparsing:Scalable Nonparametric Image Parsing with Superpixels[J].International Journal ofComputer Vision,2013,101(2):329-349.
[2] 王卫卫,杨塨鹏,吕畅,等.一种新的水平集图像分割模型[J].西安电子科技大学学报,2013,40(6):39-45. Wang Weiwei,Yang Gongpeng,LüChang,et al.New Image Segmentation Model Based on the Level Set Method[J]. Journal of Xidian University,2013,40(6):39-45.
[3]Hoiem D,Efros A A,Hebert M.Recovering Surface Layout from an Image[J].International Journal of Computer Vision,2007,75(1):151-172.
[4]LadickýL’,Russell C,Kohli P,et al.Inference Methods for CRFs with Co-occurrence Statistics[J].International Journal of Computer Vision,2013,103(2):213-225.
[5]Shotton J,Johnson M,Cipolla R.Semantic Texton Forests for Image Categorization and Segmentation[C]//Proceedings of 26th IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2008:1-8.
[6]He X,Zemel R S,Carreira-Perpindn MA.Multiscale Conditional Random Fields for Image Labeling[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Los Alamitos:IEEE Computer Society,2004:Ⅱ-695-702.
[7]Gould S,Fulton R,Koller D.Decomposing a Scene into Geometric and Semantically Consistent Regions[C]// Proceedings of the IEEE Conference on Computer Vision.Piscataway:IEEE,2009:1-8.
[8]Galleguillos C,McFee B,Belongie S,et al.Multi-class Object Localization by Combining Local Contextual Interactions [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2010:113-120.
[9]Socher R,Lin C C,Manning C D,et al.Parsing Natural Scenes and Natural Language with Recursive Neural Networks [C]//Proceedings of the 28th International Conference on Machine Learning.New York:ACM,2011:129-136.
[10]Felzenszwalb P F,Huttenlocher D P.Efficient Graph-based Image Segmentation[J].International Journal of Computer Vision,2004,59(2):167-181.
[11]Tighe J,Lazebnik S.Finding Things:Image Parsing with Regions and Per-exemplar Detectors[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Washington:IEEE Computer Society,2013:3001-3008. [12]Geiger A,Lauer M,Wojek C,et al.3D Traffic Scene Understanding from Movable Platforms[J].Pattern Analysis and Machine Intelligence,2014,36(5):1012-1025.
[13]Zhao P,Fang T,Xiao J X,et al.Rectilinear Parsing of Architecture in Urban Environment[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2010:342-349.
[14]Lowe D G.Distinctive Image Features from Scale-invariant Key Points[J].International Journal of Computer Vision,2004,60(2):91-110.
[15]Dalal N,Triggs B.Histograms of Oriented Gradients for Human Detection[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Los Alamitos:IEEE Computer Society,2005:886-893.
[16]Moosmann F,Triggs B,Jurie F.Fast Discriminative Visual Codebooks Using Randomized Clustering Forests[C]// Advances in Neural Information Processing Systems.Canada:NIPS,2007:985-992.
[17]Wang C,Komodakis N,Paragios N.Markov Random Field Modeling,Inference&Learning in Computer Vision& Image Understanding:a Survey[J].Computer Vision and Image Understanding,2013,117(11):1610-1627.
[18]Gridchyn I,Kolmogorov V.Potts Model,Parametric Max-flow and k-sub-modular Functions[C]//Proceedings of the IEEE Conference on Computer Vision.Piscataway:IEEE,2013:2320-2327.
[19]Boykov Y,Veksler O,Zabih R.Fast Approximate Energy Minimization via Graph Cuts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2001,23(11):1222-1239.
(编辑:齐淑娟)
Segmentation of the image with multi-visual features for a traffic scene
DENG Yanzi,LU Zhaoyang,LI Jing
(State Key Lab.of Integrated Service Networks,Xidian Univ.,Xi’an 710071,China)
Scene segmentations based on the pixel classifying calculation are complicated,and they use insufficient features,thus resulting in a low accuracy,so a new model is proposed to overcome these shortcomings,which is to learn these geometric classes based on multi-visual features of super-pixels.First,various features are extracted from the super-pixels of an input image.These features are used for classifying the super-pixels.Then the difference between the adjacent super-pixels is calculated to predict their consistency.The initial classification result and the consistency are synthesized to the Markov Random Field energy function,which is then minimized based on the graph-cuts algorithm to get the final labels of the super-pixels.Experimental results prove the effectiveness of the multi-visual features and the optimization method proposed,with superior performance achieved for traffic scenes.
scene segmentation algorithm;super-pixels;multi-visual feature extraction;random forest regression;Markov random fields
TP391
A
1001-2400(2015)06-0011-06
10.3969/j.issn.1001-2400.2015.06.003
2014-11-24
时间:2015-03-13
中央高校基本科研业务费专项资金资助项目(K50510010007)
邓燕子(1983-),女,西安电子科技大学博士研究生,E-mail:dyzamour@163.com.
http://www.cnki.net/kcms/detail/61.1076.TN.20150313.1719.003.html
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
民族古籍研究(2018年1期)2018-05-21
中国与非洲(法文版)(2017年10期)2017-11-23
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
西夏学(2016年2期)2016-10-26
CHIP新电脑(2016年3期)2016-03-10
浙江大学学报(工学版)(2015年1期)2015-03-01
航天返回与遥感(2014年5期)2014-07-31
