
基于内存云架构的带宽负载均衡算法
2015-12-20 06:52刘建矿英昌甜
计算机工程与设计 2015年11期
刘建矿,于 炯,2+,英昌甜,鲁 亮
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐830046;2.新疆大学 软件学院,新疆 乌鲁木齐830008)
0 引 言
近些年来,以网络搜索、电子商务、社交网络等为代表的在线数据密集型 (on line data Intensive,OLDI)应用逐渐成为工业界和学术界的研究热点。除了传统数据密集型应用的特点外,OLDI应用还具有延迟受限、查询条件多样等特点,对数据访问的性能 (如带宽、延迟等)和数据查询的多样性 (如多属性区间查询、Skyline查询等)提出迫切需求[1]。在现有云计算平台下,虚拟化技术得以普及,CPU 与内存性能优越,但网络带宽和磁盘I/O 却成为制约OLDI应用发展的瓶颈[2]。以Amazon为例,每当其响应一个HTTP 请求而生成一个HTML 页面时,都需要应用服务器做出100~200个内部请求[3],若延迟控制不好,将会在很大程度上影响用户体验。随着内存成本的不断降低和技术的不断成熟,内存云 (RAMCloud)[4]的出现很好地解决了以上问题,它是由大量普通服务器的内存组成的一种新型数据中心存储系统,任何时刻的所有信息都存储在这些动态随机访问存储器 (DRAM,即内存)中,传统硬盘被内存取代,而硬盘只作为备份。由于DRAM 无可比拟的优越性,内存云可以提供比基于磁盘存储的系统大100~1000倍的吞吐量,以及低于100~1000倍的访问延迟 (仅5~10微秒),使内存云架构在处理OLDI应用中优势显著。
RAMCloud将数据中心迁移至服务器的内存上,大量数据在内存中的传输就变得很重要。由于数据相关性[5],数据访问常以顺序串行的形式实现,而内存带宽的发展相对于内存容量的发展较慢,所以内存的带宽是影响RAMCloud服务性能的重要因素[6]。由于在线密集型数据访问频率的差异性[7,8],RAMCloud不同服务器上的数据吞吐量也存在差异,因此服务器的带宽利用率也不相同,RAMCloud集群就出现了带宽负载不均衡的现象。在带宽负载较高的服务器上,单位时间内吞吐的数据量大,服务器剩余的带宽能力减小,数据在被访问时处于等待带宽的状态,服务器的时延增加,导致较差的用户体验[9];而带宽负载低的服务器数据访问量不足,服务器的带宽利用率低,造成带宽资源的浪费,RAMCloud集群的性能降低。
RAMCloud采用段式存储结构[10],在一段时间内服务器的数据访问频率,是服务器所有数据段访问频率的集合。服务器的数据访问频率与服务器上数据段的访问频率存在表现不完全一致性的特点[11],在数据访问频率高,即内存带宽负载高的服务器上也存在访问量很低的数据段,相反在内存带宽负载低的服务器上也存在访问量高的数据段。根据这一特点,本文提出一种数据段交换 (data-segments exchanging,DSE)算法,周期性地选择内存带宽负载不均衡的服务器,在内存带宽负载低服务器上选择访问频率较低的数据段,与内存带宽负载高服务器上的访问频率较高数据段进行交换。通过数据段的交换,降低高带宽负载服务器的数据访问次数,降低服务器的带宽负载从而降低服务器时延;同时提升低带宽负载服务器的数据访问量,提高其带宽利用率,实现服务器集群的带宽负载均衡,提高集群性能。
1 内存云的段式存储结构
在RAMCloud 中,每一个RAMCloud 集群拥有一个Coordinator节点,用来存储每一个文件的Mapping 信息,即运用键值对保存用户所请求的信息在哪一台主服务器上,类似于HDFS (hadoop distributed file system)中的Name-Node节点[12]。Coordinator节点根据用户 (client)发出的请求信息,通过数据中心网络找到所请求服务器,每台服务器都包含两个部分:Master和Backup。Master管理了存储在内存中的数据对象,Backup使用本地的机械硬盘或者固态硬盘保存了其它服务器的数据备份。Coordinator管理了Master和Backup配置信息,但是Coordinator并不涉入数据的读写操作,因此不会降低系统的可扩展性。其整体结构如图1所示。
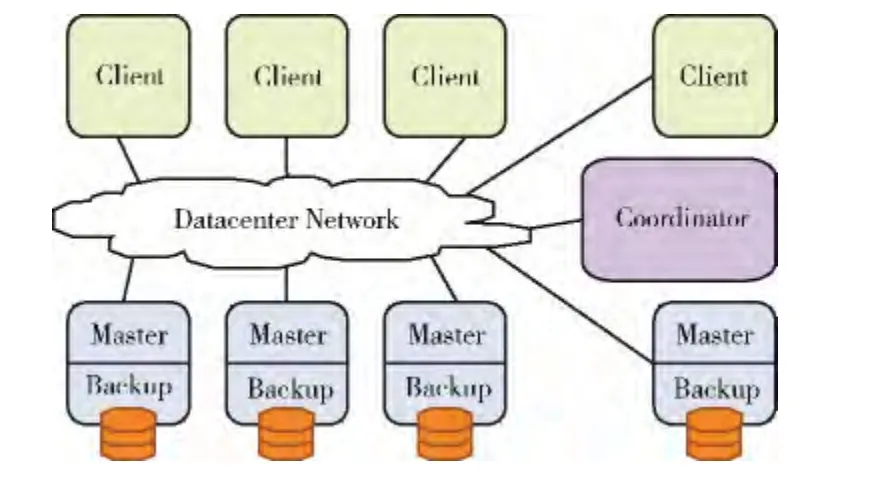
图1 内存云基本结构模型
在RAMCloud集群中,数据采用基于日志结构的存储方式进行存储。文件系统保存的服务器内存信息包括文件数据块、属性 (类型、所有者及权限等)、索引块、目录和所有用来管理文件的其它信息,还包含数据块的地址,一个或多个间接块的地址,每一个间接块包含多块数据块的地址或间接块的地址[13]。文件系统将服务器的内存的信息及改动保存为日志,并切分成段,将每一段分别保存到不同备份服务器的内存缓冲区 (buffer)[14]中,同时通过哈希表进行记录 (如图2所示)。哈希表记录了每一个存储在服务器上数据的表项,它支持数据的快速查找,并给出数据的<table,key>值。每个数据都有一个指针,存储在它的哈希表项中。为了保证数据的持久性,避免服务器崩溃和电源故障,每个主服务器必须保持它的对象的备份副本存储在其它的备份服务器中。每个主服务器都有自己的日志,它将日志分为8 MB 的块称为段 (segments),每个段复制几个备份 (通常是两个或3个)。

图2 内存云段式存储结构
2 RAMCloud的内存带宽模型
2.1 内存带宽模型
内存带宽 (memory bandwidth)是指单位时间内CPU访问内存时内存通道可以传输的最大数据量,单位是GB/s。内存带宽与数据传输通道容量和数据传输的速度有关,内存的数据传输通道容量与传输总线的位数有关,传输总线位数越大传输的数据量越大,内存频率决定数据传输的速度,频率越大内存传输速率越快,单位时间内传输的数据量越大。所以内存带宽与内存的总线位数和内存频率存在计算公式

其中,倍增系数λ 是指一个时钟周期内相对于SDRAM 的数据倍数,目前DDR 的倍增系数是2,DDR2的倍增系数是4,DDR3的倍增系数是8。
吞吐量 (throughput)是指内存在一段时间内所处理的数据量,内存带宽利用率是单位时间内内存的数据吞吐量占用带宽的大小,是衡量内存性能的重要指标。单位时间内内存的数据吞吐量越大,占用的内存带宽越高,则带宽利用率越高。用TP 表示一段时间t内内存访问的数据吞吐量。公式表达为

内存时延表示系统进入数据存取操作就绪状态前等待内存响应的时间。为了进一步研究内存时延与数据吞吐量的关系,本文选用1333 MHz的内存,做一个内存时延随着单位时间内数据吞吐量增加的微基准测试,所得到的内存时延的变化曲线如图3所示。

图3 内存时延的变化曲线
由图3可以看出,内存时延随着内存吞吐量的增加呈现出超线性增加。当内存吞吐量的增加时,内存带宽负载增加,内存的剩余带宽可以通过的数据量减少,数据平均队列的长度增加,内存时延增加。当吞吐量接近内存带宽时,此时内存带宽饱和,无法通过更多的数据,内存时延无限大。内存的时延与内存吞吐的数据量存在关系如下

式中:MemLatency——内存时延,IdleLatency——空闲时延,slope——参数递增系数。
2.2 RAMCloud的内存带宽模型
RAMCloud日志文件结构中的内存信息记录了数据段的大小、访问次数和数据段所在位置等信息。一个RAMCloud集群有m 台服务器,一台服务器由n 个数据段构成,从段的日志中获取内存云服务器一段时间t内的一个文件块的访问次数,用矩阵Fm×n进行存储。服务器数据段的访问次数用 (M[i][j])m×n(1≤i≤m,1≤j≤n)表示,其中i表示服务器号,j表示服务器上的第j 个数据段。t时间内一台服务器的访问次数是n 个段文件块的访问次数的总数,用Mtotal[i]可以表示为

t时间内RAMCloud集群的平均访问次数是集群中m台服务器的访问次数的平均值,用Mavg 表示

式中:Mavg——所有服务器平均在一台服务器上访问次数,反应了集群的平均访问频率。经过统计在t时间内Mavg是常量。
定义1 若一台服务器的访问次数Mtotal[i]满足关系Mtotal[i]>Mavg,则服务器i为高内存带宽负载服务器;若服务器的访问次数Mtotal[i]满足关系Mtotal[i]<Mavg,则服务器i为低内存带宽负载服务器。
定义2 给定一个参数α,用来表示集群带宽负载均衡的范围。若服务器的访问次数Mtotal[i]满足关系Mavg*(1-α)≤Mtotal[i]≤Mavg*(1+α),则服务器i为内存带宽负载均衡服务器。
在RAMCloud上一台服务器的数据吞吐量是一段时间t内,服务器对所有数据段的访问总量,用Size 表示RAMCloud上数据段的大小,公式可表示为

3 内存带宽负载均衡算法
RAMCloud的内存带宽负载均衡算法过程如下,首先由Coordinator节点从集群中所有服务器数据段的访问次数Mtotal[i]中选中的访问次数最少的服务器Mtotal[low],以及访问次数最大的服务器Mtotal[high]的两台服务器,即一台带宽负载最小的服务器low 和一台带宽负载最大的服务器high。在低负载服务器low 上选择一个访问次数最小的数据段,用常量M[low][min]表示;然后在高负载服务器high上选一个数据段,用常量M[high][max]表示,将两个数据段进行交换,低负载服务器low 的访问次数增加了M[high][max]- M[low][min],高负载服务器high的访问次数减少了 M[high][max]- M[low][min],两台服务器上的数据访问量趋于均衡。
两台服务器实现数据段交换的过程是,从文件日志的哈希表中找到两个数据段在服务器中的位置以及在磁盘中的备份位置,然后服务器从磁盘中读取需要交换的另一个数据段信息,覆盖掉原有数据段的信息,并且将交换后的文件内容、磁盘中位置等信息保存到段日志文件中,更新哈希表。数据在哈希表项中的指针能够找到数据的位置,保证了数据访问的连续性。
DSE算法代码如下:

DSE算法每次都根据Mtotal[i]选择一台带宽负载最低的服务器Mtotal[low]和一台带宽负载最高的服务器Mtotal[high]。首先在低内存的带宽负载服务器上选择一个访问次数最小的数据段M[low][min],此时这个数据段所在的服务器还需要Mavg-Mtotal[low]访问次数即可达到均衡,所以交换得到的数据段的访问次数大小不超过M[low][min]+Mtotal-Mtotal[low]。然后在高内存带宽负载服务器上选择一个数据段与已经选择的M[low][min]进行交换,此时高内存带宽负载服务器上还需要减少Mtotal[high]-Mavg个访问次数即可达到均衡,交换后高内存带宽负载服务器得到数据段M[low][min],所以被交换出去的数据段的访问次数不能超过M[low][min]+Mtotal[high]-Mavg。在高内存带宽负载服务器上选择数据段的访问次数既不能超过M[low][min]+Mavg-Mtotal[low],又不能超过M[low][min]+Mtotal[high]-Mavg。为了以最少的数据段交换次数实现负载均衡,在高内存带宽负载服务器上选择数据段时尽可能的选择范围内访问次数最大的数据段。
4 实 验
通过仿真实验,模拟10台以型号为64GB-1333 MHz大小内存作为内存服务器构成内存云集群。利用式 (1),计算出1333 MHz内存的带宽MemBW 为10.664 Gb/s。RAMCloud的数据段大小Size为8M,所以一台64G 内存云服务器中有8192个数据段。某一内存云服务器同时作为其它服务器的备份服务器,需预留一定的存储空间作为备份。在本文实验中,设定一台服务器上有8G 作为服务器的备份空间,所以有60G 作为主服务器数据存储与访问,共计7168个有效数据段。实验通过蒙特卡洛算法随机生成一组10*7168条0-100000的数据组成矩阵,表示在初始阶段时,10台服务器7168个数据段在60分钟内的访问次数。分别根据式 (4)和式 (6)计算出服务器初始状态的访问次数Mavg,以及吞吐量TP[i],再根据式 (2)和式(3),相继计算出服务器初始状态的带宽利用率η以及服务器时延MemLatency。
实验1:DSE 算法的一般性实验。分别设置集群负载均衡因子α为0.1和0.2,访问次数在Mavg*(1±α)时处于负载均衡,根据DSE 算法进服务器的数据块进行交换,调整服务器的吞吐量,达到集群带宽负载均衡状态。然后计算出均衡后服务器的访问次数Mtotal[i],吞吐量TP[i],带宽负载η 以及服务器时延MemLatency,对比服务器初始状态以及DSE 算法执行前后,服务器带宽利用率η和时延变化MemLatency,如图4、图5所示。
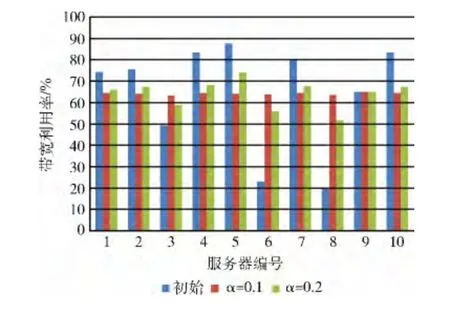
图4 服务器带宽负载变化

图5 服务器时延变化
由图4可以看出整个集群的带宽负载是不均衡的,有3台服务器的带宽利用率低于50%,有4台服务器的带宽利用率超过80%。这3台低负载服务器的带宽利用率远低于集群的带宽利用率 (64.25%),造成了带宽资源的浪费,而由图5可以看出,在高负载服务器上的时延明显高于集群其它服务器。服务器数据吞吐量的差异,导致了集群的性能差异。
DSE算法对服务器的数据段进行交换,集群中每台服务器的数据吞吐量更加均衡,降低了4台高负载服务器的带宽负载,同时也提高了低负载服务器的带宽利用率,使集群的带宽利用率更加均衡。DSE 算法明显地降低了高负载服务器的时延,而低负载服务器的时延只是小幅度增加,最终集群中每台服务器的时延都趋于均衡。α是影响负载均衡的因子,从图中可以看出,当α=0.2时集群带宽利用率和时延的变化幅度都要比α=0.1 时大。由图4 可以看出,通过DSE 算法高负载服务器的时延有了大幅度的下降,α=0.1时集群的时延比初始时延降低了12.61%,α=0.2时集群的时延比初始时延降低了11.77%。
实验2:集群服务器吞吐量低的实验。初始数据段的访问次数较低,服务器的数据吞吐量低,集群带宽负载低。根据DSE算法对服务器的数据块进行交换,然后对比服务器初始状态以及DSE 算法执行前后,服务器带宽利用率η和时延变化MemLatency,如图6、图7所示。

图6 服务器带宽负载变化
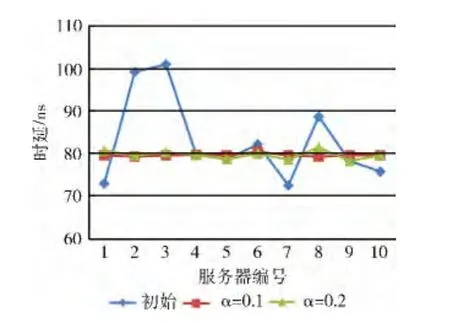
图7 服务器时延变化
可以看出初始状态下,集群的带宽负载是不均衡的,整个集群的带宽利用率都不高,高负载服务器的带宽利用率也不超过80%。经过DSE算法,集群中每台服务器达到了带宽负载均衡。时延方面,带宽负载均衡因子α=0.1与α=0.2时都能使高负载服务器的时延明显降低,α=0.1时,集群的时延比初始降低了3.87%,α=0.2时集群的时延比初始降低了3.56%。显然当集群服务器数据吞吐量较低时,DSE算法在减少服务器时延方面的效果不理想。在低负载服务器上,α的取值只会影响服务器的带宽负载均衡的范围,对降低时延的影响不明显。
实验3:集群服务器吞吐量高的实验。实验初始数据段的访问次数高,服务器的数据吞吐量高,集群带宽负载高。根据DSE算法对服务器的数据块进行交换,然后对比服务器初始状态以及DSE 算法执行前后,服务器带宽利用率η和时延变化MemLatency,如图8、图9所示。

图8 服务器带宽负载变化

图9 服务器时延变化
可以看出初始状态下,集群的带宽负载不均衡,整个集群的带宽利用率很高,甚至有2台服务器的带宽利用率高于90%,同时他们产生了非常高的时延。经过DSE 算法,集群中每台服务器达到了带宽负载均衡。当带宽负载均衡因子α=0.1 时,集群的时延比初始降低了14.21%,α=0.2时集群的时延比初始降低了10.05%。当集群服务器数据吞吐量较高时,DSE 算法可以大幅度的减少集群的时延。在高负载服务器上,α的取值不仅会影响服务器的带宽负载均衡的范围,而且对时延的降低也有显著的影响。
5 结束语
实验验证了在RAMCloud集群上,通过DSE 算法周期性地对进行数据段交换,可以解决由于数据段访问差异性造成的服务器内存带宽负载不均衡的现象,从而达到集群带宽负载均衡降低集群时延的目的。DSE 算法对数据吞吐量低的集群效果不明显,对数据吞吐量高的集群效果显著。集群带宽负载均衡的范围受到负载均衡因子的影响,可以根据用户的需求来动态调整。负载均衡因子的取值在降低集群时延方面也有影响,负载均衡因子的取值越小,集群的时延降低越多。需要注意的是,负载均衡因子的取值,影响算法的时间复杂度,所以对于负载均衡因子的取值根据集群的负载以及用户需求进行设置。
[1]ZHANG Yiming,PENG Yuxing,LI Dongsheng.Survery on distributed storage for on line data intensive applications [EB/OL]. [2013-03-26].http://www.paper.edu.cn/releasepaper/content/201303-838(in Chinese).[张一鸣,彭宇行,李东升.面向在线数据密集型应用的分布式存储研究综述[EB/OL].[2013-03-26].http://www.paper.edu.cn/releasepaper/content/201303-838.]
[2]Armbrust M,Fox A,Griffith R,et al.A view of cloud computing [J].Communications of the ACM,2010,53 (4):50-58.
[3]DeCandia G,Hastorun D,Jampani M,et al.Dynamo:Amazon’s highly available key-value store[C]//Proceedings of the 21st ACM Symposium on Operating Systems Principles.Washington DC:ACM,2007:205-220.
[4]Ousterhout JK,Agrawal P,Erickson D,et al.The case for RAMClouds:Scalable high-performance storage entirely in DRAM [J].ACM SIGOPS Operating Systems Review,2010,43 (4):92-105.
[5]Tinnefeld C,Kossmann D,Boese JH,et al.Parallel join executions in RAMCloud [C]//Proceedings of the 30th International Conference on Data Engineering Workshops,2014:182-190.
[6]Goel B,Titos-Gil R,Negi A,et al.Performance and energy analysis of the restricted transactional memory implementation on haswell[C]//Proceedings of the 28th IEEE International Parallel and Distributed Processing Symposium, 2014:615-624.
[7]Cabarcas F,Rico A,Etsion Y,et al.Interleaving granularity on high bandwidth memory architecture for CMPs[C]//Proceedings of the International Conference on Embedded Computer Systems:Architectures,Modeling and Simulation,2010:250-257.
[8]Tolle KM,Tansley D,Hey AJG.The fourth Paradigm:Data-intensive scientific discovery [J].Proceedings of the IEEE,2011,99 (8):1334-1337.
[9]Bao Y,Chen M,Ruan Y,et al.HMTT:A platform independent full-system memory trace monitoring system [J].ACM SIGMETRICS Performance Evaluation Review,2008,36 (1):229-240.
[10]Rumble SM,Kejriwal A,Ousterhout JK.Log-structured memory for DRAM-based storage [C]//Proceedings of the 12th USENIX Conference on File and Storage Technologies,2014:1-16.
[11]Nakazato H,Nishio M,Fujiwara M.Data allocation method considering server performance and data access frequency with consistent hashing [C]//Proceedings of the 14th Asia-Pacific Network Operations and Management Symposium,2012:1-8.
[12]Shvachko K,Kuang H,Radia S,et al.The Hadoop distributed file system [C]//Proceedings of the IEEE 26th Symposium on Mass Storage Systems and Technologies,2010:1-10.
[13]Chen Lijun,Liu Zhaoyuan,Jia Weiwei.A snapshot system based on cloud storage log-structured block system [C]//Proceedings of the IEEE 11th International Conference on Networking,Sensing and Control,2014:392-398.
[14]NING Xingwang,LIU Peiyu.Log system design in support of linkage analysis of security audit and computer forensics[J].Computer Engineering and Design,2009,30 (24):5580-5583 (in Chinese). [宁兴旺,刘培玉.支持审计 与取证联动的日志系统设计 [J].计算机工程与设计,2009,30(24):5580-5583.]
猜你喜欢
高技术通讯(2021年5期)2021-07-16
当代陕西(2019年13期)2019-08-20
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
集装箱化(2014年2期)2014-03-15
