
基于均衡分类的脑卒中风险预测模型
2015-12-20 06:56曹艳,殷旭
计算机工程与设计 2015年9期
曹 艳,殷 旭
(北京信息科技大学 计算机学院,北京100085)
0 引 言
随着医疗信息量的增长,数据挖掘技术在医疗领域得到广泛应用。决策树C4.5算法因其具有直观、高效和结果易于理解的特点备受 关注。Jinn-Yi Yeh等[1]使 用C4.5 算法得到透析病人是否需要住院治疗和相关症状的关系,以合理安排住院和治疗方案;Zerina Maetic等[2]综合使用自回归 (AR)特征提取模块和C4.5算法检测分离正常和充血性心脏衰竭,分类准确率高达99.77。在对乳腺癌数据分类中,C4.5算法可以较好的控制决策树的规模,规则的可理解性较高[3]。Ture、Tokatli等[4]在对乳腺癌患者的无复发生存期预测实验中发现C4.5在准确度和树结构方面优于CART、CHAID、QUEST 和ID3 算法。上述研究中C4.5都取得了较好效果,但都建立在均衡数据基础之上,为了提高整体分类精确度,可能将某些少数类数据作为可允许误差进行错误分类。不均衡数据处理主要是对数据集进行重构,数据重构通常采用欠采样技术、过采样技术和Chawla等提出的SMOTE (synthetic minority oversampling technique)算法[5]。文献 [6-11]分别是近年针对不均衡数据提出的处理方法。SMOTE 算法与主动学习算法[6]集成使用,在一定程度上避免数据不均衡带来的分类偏倚问题;许丹丹等从数据水平的过抽样角度出发,提出SMOTE 的改进算法ISMOTE算法,更好地提高了不均衡数据的分类性能[7];用阴性免疫算法实现少数类样本空间覆盖,可以避免SMOTE生成的新样本空间代表性不足的问题[8];在SVM 分类偏倚问题研究中,集成使用代价敏感学习、欠采样和 过 采 样 技 术 效 果 明 显[9];Wang 等[10]结 合SMOTE、PSO (particle swarm optimization)和C5.0 算 法 对 不 均 衡的乳腺癌数据分类,发现经SMOTE 处理后分类效果明显提高;孙涛等医学专家也发现SMOTE 算法可以对临床的不均衡数据进行有效纠偏[11]。上述方法主要是针对少数类数据进行的,忽略了多数类数据处理,当两类数据数量相差较大,一味增加少数类数据会造成少数类分类过度拟合,生成虚假关系。
1 SMOTE算法介绍
SMOTE算法[5]是2002年由Chawla等提出的一种针对不均衡数据集的智能型过抽样技术,可以有效改善传统过抽样技术带来的分类过度拟合现象,解决分类结果偏倚问题。
定义1 设样本集合为T,x为集合中的单个样本,k为搜索的少数类最邻近样本的数量,向上采样的倍率为N(N 为可被100整除的数),在k个少数类最邻近样本中随机选取N/100个样本,m1,m2,…,mn,在x与m1(j=1,2,…,n)之间随机线性插入0到1之间的数,形成新的少数类样本qj

SMOTE算法的核心思想是首先寻找每个少数类样本的k个最邻近样本,然后选取其中N/100个,分和少数类样本两两组合,最后在两个样本间进行随机线性插值,构造新的少数类样本。
算法的具体是实现过程是:
输入:训练样本集T,最邻近样本数量k,向上采样倍率N
输出:少数类空间扩大的训练样本集T1
(1)判断N 是否小于100,如果是,则直接对样本进行随机采样;否则计算样本中各决策属性中样本的数量,确定少数类和多数类;
(2)根据k、N 的值和式 (1)合成新的少数类数据;
(3)将新生成的少数类样本加入原数据集中,生成新数据,算法结束。
实验中,在此过程之前,首先应使用随机抽样算法抽取训练集中所有的样本,即对数据进行随机排序,避免数据预处理时排序筛选等操作影响最邻近样本分布的随机性。这样,既可增大少数类数据的规模,又可以避免传统过抽样中完全复制少数类样本带来的过度拟合问题。
2 基于PAM 的K-means算法PAM-means算法介绍
2.1 K-means算法
K-means算法是MacQueen在1967年提出的基于距离的聚类算法,该算法因效率较高得到广泛应用。算法的基本思想是:首先选定聚类数量K 和K 个初始聚类中心Zj,依据距离最小原则将样本nj分配到距离聚类中心最近的类中,分配完后,计算每个类的均值作为新的聚类中心,循环样本分配过程,直到聚类收敛为止。聚类的目标函数如下
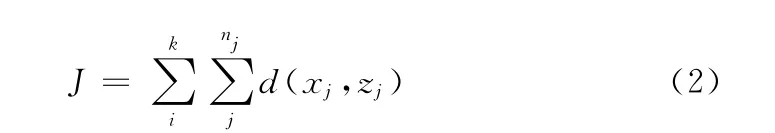
其中,函数d(xj,zj)为欧几里得距离函数,如下

2.2 PAM 算法
PAM (portioning around medoid),是一种围绕中心的划分,试图对N 个对象进行K 个划分。该算法首先为每个类选取一个初始中心点数据,剩余的数据依据到与中心点的距离或相异度分配给相近的中心点所在的类;然后反复地用非代表数据替换代表数据,并使用代价函数进行评估聚类质量,选取当前代表数据最好的代替,提高聚类质量,得到正确的划分。
2.3 PAM-means算法
K-means算法聚类效果相对较好,较为准确,但对孤立点和噪声较为敏感,且需人为指定K 值。而PAM 算法不需要指定聚类数目K,对孤立点和噪声不敏感,且能处理不同类型的数据,但聚类效果相对K-means较差。
为了使聚类效果较好,本文采用PAM-means算法,首先使用PAM 算法得到聚类数量K,然后使用K-means算法对多数类数据进行聚类,将相似度较高的数据聚到一簇,相似度较低的数据分开。这样,对聚类后每个簇进行抽样所得的数据特点基本可代表整个多数类数据的特点,从而避免传统欠抽样造成的信息严重丢失问题。
算法的基本流程如下:
(1)PAM 算法聚类,得到K 值;
(2)任意选取K 个数据对象作为初始聚类中心;
(3)计算样本中所有数据到聚类中心的距离,如式(3)所示,选择距离最小的数据对象,并将该数据对象划分到该聚类中心所在的簇;
(4)计算每个簇中数据对象的均值,作为新的聚类中心;
(5)循环步骤 (3)和步骤 (4),直到聚类中心不再改变;
(6)算法结束。
3 决策树C4.5算法
决策树C4.5算法是JR Quinlan于1993在算法ID3的基础上提出的,相对于ID3算法,C4.5具有更高的分类精确度,并且可以处理连续属性。C4.5算法用信息增益率来选择决策属性,对于连续属性要首先进行离散化,离散化的依据是将连续属性排序后,从中间开始选取可能分裂点,计算各可能分裂点的信息增益率,将信息增益率最大的点作为分裂点。因此在C4.5算法中对于连续属性的分裂是二元分裂。
C4.5算法利用信息熵原理,以信息增益率作为分类属性的选择标准,克服了信息增益选择属性时偏向选择取值多的属性的不足,递归的构造决策树[12]。本文在构造树的过程中使用十折交叉验证和测试集验证对分类树进行剪枝,不断的训练树的结构,以达到最简最可靠有效的分类结果。
算法的具体实现过程是:
输入:训练集T,决策属性C
输出:决策树
(1)以T 为根节点构造分类树;
(2)判断T 的样本的决策属性是否相同,如果相同,那么当前节点即为叶节点,算法结束;否则,计算k个决策类的总信息量;
(3)判断条件属性是连续属性还是离散属性,如果是连续属性,根据连续属性的可能分裂点的信息增益率对该属性进行离散化;
(4)分别计算条件属性基于决策属性的条件信息量和分裂信息;
(5)计算各条件属性的信息增益率,并选择最大的为分裂属性,同时将该属性对应的样本作为子分类样本集;
(6)针对选中的分裂属性,根据分裂信息构建对应的节点,并将对应的样本划分到该节点下;
(7)重复步骤 (2)到步骤 (6),对个训练样本子集进行划分,生成新的决策分支,直到没有可以再分的属性,算法停止。
C4.5算法虽然可以比较准确有效的对连续和离散数据进行分类,但是没有针对数据本身分布不均的特点进行处理,尤其是在遇到普遍存在不均衡性的医学数据时,C4.5算法为了保证整体分类精确度,很容易产生不可预知的偏倚性,将少数类数据误分到多数类中,隐藏少数类数据的信息,造成灵敏度较高,特异度较低的结果。因此合理的对不均衡数据进行均衡处理至关重要。
4 实验及结果分析
本文以脑卒中高危因素筛查和防治项目的调查问卷数据为样本数据,分析与脑卒中相关的因素之间的关系,并预测患脑卒中的风险,为有效干预脑卒中预防提供支持。
4.1 评价标准
提高少数类的分类性能是不均衡数据分类问题的研究重点,表1是3类数据集的混淆矩阵,这3类数据的标号分别为A、B和C,以A 类为例,TA 为A 类正确分类的样本数量,FAB表示A 类样本误分到B类的样本数量,FAC表示A 类样本误分到C类的样本数量。

表1 3类数据集的混淆矩阵
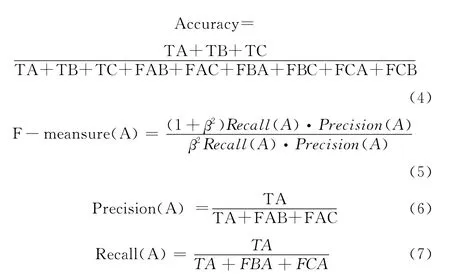
分类模型中常用的评价标准为精确度Accuracy,体现分类的整体性能,但不能合理准确的评价不均衡数据集的分类性能。对于不均衡数据分类评价标准常用F-measure,是查全率Recall和查准率Precision的组合,β通常为1。只有少数类的查全率和查准率都大时,少数类的F-measure才会大,因此他能正确的反应少数类的分类性能。式 (5)、式 (6)和式 (7)分别是类A 的F-measure(A)、查准率Precision (A)和查全率Recall(A),分类的总体Recall在3类数据集分类中为每类查全率的加权均值,权重为各类样本所占比例,整体Precision和F-measure同Recall。
4.2 数据预处理
原始数据集有冗余数据、缺失数据、不确定数据和不一致数据等,导致结果不准确、不全面,甚至得出错误的规则。所以首先对数据进行预处理,消除数据噪声带来的分类问题。
此次调查问卷得到的原数据共有524条记录,100个数据项,其中除了与脑卒中相关的数据项,还有大量的与脑卒中无关的个人统计学信息和医院信息,如姓名,民族,筛查日期等。
首先删除如姓名、筛查日期等无关信息,去除数据项中只包含一两条记录的数据项。其次,整合数据,在医生专家的指导下将某些数据项整合到一起形成新的数据项,如在判断是否是家族遗传脑卒中时,可以将父母、子女、兄弟姐妹中有得脑卒中的情况视为有家族遗传脑卒中;将身高体重合并为身体质量指数 (BMI)作为衡量身体胖瘦程度的标准等。经过这些处理,数据中包含15项数据项,179条数据。最后,统一数据格式,并用出现频率最高的数据填充本数据项中个别的缺失值。最后生成的数据形式见表2。

表2 脑卒中数据
表2中与脑卒中相关的数据项包括决策属性患脑卒中的风险和条件属性年龄、性别、身体质量指数 (BMI)、是否从事轻体劳动、体育锻炼情况、是否有脑卒中史、是否有短暂性脑缺血发作史 (TIA)、是否患有高血压、是否有过房颤或瓣膜性心脏病 (AF/AHD)、是否吸烟、是否饮酒、是否有血脂异常、是否有慢性病史、是否是家族遗传脑卒中。数据中性别项F表示女性,M 表示男性;体育锻炼情况1表示有规律性锻炼,2表示有锻炼但不规律,3表示无体育锻炼;其它数据项中1表示是,2表示否;决策属性有3个取值L、M、H,分别表示低危、中危和高危。
4.3 SMOTE&PAM-means+C4.5算法实现过程介绍
整个实验过程如图1所示,数据预处理后进行均衡判断,首先统计每个类中记录数,找出记录数的最大值max和最小值min,然后对max和min做商,如果max/min<3则判断数据均衡,直接进入C4.5分类器进行分类;否则判断该数据集存在不均衡性,需要先进行均衡处理,然后进入分类模块。
(1)菌种活化分别取适量乳杆菌菌株冻干菌粉接种于10 mL灭苗MRS肉汤培养基中,旋涡混匀于37℃在恒温培养箱中培养24 h得到一代菌悬液。按5%的接种量将一代菌悬液接种于MRS肉汤培养基中,37℃恒温培养24 h得二代菌悬液。重复上述步骤37℃恒湿培养18 h,进行第三次活化得到三代活化菌悬液,4℃冰箱储存备用。

图1 模型实现流程
均衡处理的工作流程如图2所示,生成的是均衡处理后的均衡数据集。整个均衡处理过程包含两个部分,一部分针对少数类数据,首先对整个数据集抽样,抽样方式为不可重复抽样,数量为数据集数量,使各记录随机排序,然后使用SMOTE 生成新的少数类数据。排除预处理时筛选排序等操作对SMOTE 算法的影响,确保SMOTE 得到的数据是随机综合多数类数据和少数类数据得到的,避免SMOTE生成的数据仅来源于少数类数据而造成过度拟合问题。针对多数类数据,主要是进行欠抽样,但考虑到欠抽样带来的信息丢失问题,首先对多数类数据做PAMmeans聚类,然后计算聚类结果中每簇中各个分类属性的样本数量,按比例进行抽样,使最终得到的数据集中每类数据的数量相当。

图2 数据均衡处理流程
4.4 实验结果及分析
原始C4.5算法分类结果的混淆矩阵如表3所示。表3显示样本总量为179,其中P=L 的有104例,P=H 的有66例,而P=M 的只有9例,P=M 相对P=L和P=H 类别属于少数类。混淆矩阵显示P=M 类中只9例样本,只有44.445% 正 确 分 类,有33.333% 偏 向p =L 类,22.222%偏向P=H 类,即大部分少数类数据被误分到其它类别。而P=H 类别中,分类正确的占78.788%,分类偏向P=M 类的7.576%,偏向P=L类的13.636%。对于多数类P=L,只有2例被误分到了P=H 类中。纵向看,P=M 类9例中只有4例来自正确数据,其余都是P=H 类错误分类的结果。综上所述,少数类数据的分类性能极差,结果不能正确体现少数类数据的特点。因此,不均衡的脑卒中数据在C4.5算法分类中存在严重的分类偏倚问题,解决数据不均衡问题是改善分类性能的首要问题。
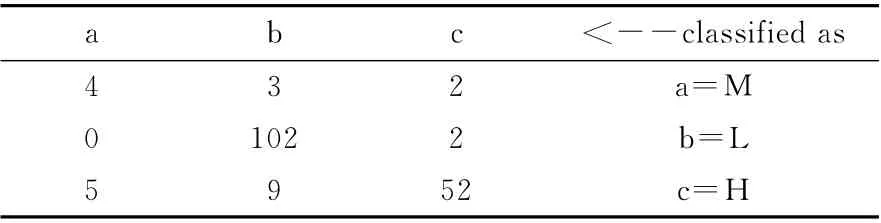
表3 C4.5算法分类混淆矩阵
为了解决分类偏倚问题,实验中分别对原始数据做了不同的均衡处理,包括欠采样、过采样、SMOTE 和SMOTE&PAM-means算法,然后用C4.5 算法进行分类,分类过程中采用十折交叉验证对树进行剪枝。均衡处理过程中,欠采样以少数类样本数量为标准分别对两个多数类进行欠采样,形成新的数据集。SMOTE 算法处理数据,形成的均衡数据集中P=M 含有27例样本。过采样中少数类数据数量与SMOTE 处理结果中P=M 类的样本数量相同,同时从多数类数据中随机取一半数据,以便与SMOTE和原始C4.5算法进行F-measure和验证精确度的对比。由于均衡处理后进入分类器的数据为部分原始数据,所以使用整个原始数据集对生成的规则进行验证,得到验证精确度。
原始C4.5算法、欠采样+C4.5 算法、过采样+C4.5算法、SMOTE+C4.5算法和最终改进的SMOTE&PAMmeans+C4.5算法分类结果对比见表4。

表4 各算法结果对比
表4中显示均衡处理后,分类树的结构有不同程度的简化,树的节点和叶节点数都减少,过采样简化程度相对最小,SMOTE&PAM-means+C4.5 相对最大。从均衡角度分析,原始C4.5算法的F-measure(M)值仅0.394,而整体F-measure值为0.879,相对较大,说明少数类分类性能比较差,而多数类分类性能很好,再次说明原始C4.5算法的分类结果严重偏倚。均衡处理后,少数类的分类性能都有明显提高,但整体F-measure 只有SMOTE&PAMmeans+C4.5算法有明显改善,其它3 种都有不同程度的下降,说明只针对少数类数据进行的均衡会造成多数类数据信息严重丢失,影响整体的分类性能,使得均衡处理得不偿失。而SMOTE&PAM-means+C4.5算法的分类精确度和验证精确度也明显提高。因此,SMOTE&PAM-means+C4.5算法同时对少数类和多数类数据进行处理,可有效增大少数类样本空间的同时需减少多数类样本信息损失量,改善不均衡数据分类偏倚问题,提高分类性能。
SMOTE&PAM-means+C4.5算法生成的树结构如图3所示,对应的规则如下:
规则2:如果慢性病史=1∧脑卒中史=2∧饮酒=1,则风险=H;
规则3:如果慢性病史=1∧脑卒中史=2∧饮酒=2∧年龄>66,则风险=H;
规则4:如果慢性病史=1∧脑卒中史=2∧饮酒=2∧年龄<=66,则风险=M;
规则5:如果慢性病史=2∧脑卒中史=1,则风险=H;
规则6:如果慢性病史=2∧脑卒中史=2∧血脂异常=2,则风险=L;
规则7:如果慢性病史=2∧脑卒中史=2∧血脂异常=1∧高血压=1,则风险=H;
规则8:如果慢性病史=2∧脑卒中史=2∧血脂异常=1∧高血压=2,则风险=L。
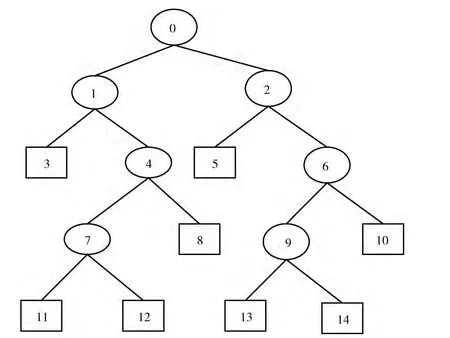
图3 SMOTE&PAM-means+C4.5算法生成的树结构
实验结果显示,在没有慢性病史的情况下,脑卒中史或血脂异常、高血压都会增大病人患脑卒中的概率,使病人处于高危患病人群。而在有慢性病史的情况下,脑卒中史仍是导致病人患脑卒中的关键因素;同时,对于没有脑卒中史的人,饮酒和年龄大于66岁是两个导致脑卒中发病的关键因素。因此,此预测模型有助于人们尤其是老年人及时了解自身健康情况,准确预测脑卒中发病风险,并根据自身情况,寻求更适合自己远离脑卒中的预防措施,最终达到有效干预脑卒中预防治疗的效果。
5 结束语
基于均衡分类的脑卒中风险预测模型中SMOTE&PAM-means+C4.5算法对少数类数据进行了处理,通过少数类数据和少数类最邻近的样本生成新的少数类数据,一定程度增大少数类数据规模。同时对多数类进行PAM-means聚类,然后按比例对每簇样本进行随机抽样,达到少数类和多数类数据均衡的效果。通过实验可知,均衡后有效解决了分类结果偏倚问题,并且分类精确度和树的结构也得到了改善。此模型生成了8条脑卒中风险预测规则,为人们及时准确的预测脑卒中风险提供依据。在以后的工作中我们将进一步研究如何更有效解决不均衡数据分类问题,提高最终准确度的分类,简化树的结构,为疾病的有效预防治疗等提供数据支持。
[1]Jinn-Yi Yeh,Tai-Hsi Wu,Chuan-Wei Tsao.Using data mining techniques to predict hospitalization of hemodialysis patients [J].Decision Support Systems,2011,50 (1):439-448.
[2]Zerina Masˇetic,Abdulhamit Subasi.Detection of congestive heart failure using C4.5decision [J].Southeast Europe Journal of Soft Computing,2013,2 (2):74-77.
[3]LI Zhi,LI Guolin.Comparative study of C4.5and CART algorithm in medical data mining [J].Electronic Technology &Software Engineering,2013,10 (3):47-48 (in Chinese).[李治,李国琳.C4.5 和CART 算法在医学数据挖掘中的对比研究 [J].电子技术与软件工程,2013,10 (3):47-48.]
[4]MevlutTure,FusunTokatli,Imran Kurt.Using Kaplan-Meier analysis together with decision tree methods(CART,CHAID, QUEST,C4.5and ID3)indetermining recurrence-free survi-val of breast cancer patients [J].Expert Systems with Applications,2009,36 (2):2017-2026.
[5]Chawla NV,Bowyer K,Hall L,et al.SMOTE:Synthetic minority over-sampling technique[J].Journal of Artificial Intelligence Research,2002,16 (1):321-357.
[6]ZHANG Yong,LI Zhuoran,LIU Xiaodan.Active learning SMOTE based imbalanced data classification [J].Computer Application and Software,2012,29 (3):91-94 (in Chinese).[张永,李卓然,刘晓丹.基于主动学习SMOTE 的非均衡 数 据 分 类 [J].计 算 机 应 用 软 件,2012,29 (3):91-94.]
[7]XU Dandan,WANG Yong,CAI Lijun.ISMOTE algorithm for imbalanced data set[J].Journal of Computer Application,2011,30 (9):2399-2401 (in Chinese).[许丹丹,王勇,蔡立军.面向不均衡数据集的ISMOTE 算法 [J].计算机应用,2011,30 (9):2399-2401.]
[8]TAO Xinmin,XU Jing,TONG Zhijing,et al.Over-sampling algorithm based on negative immune in imbalanced data sets learning [J].Control and Decision,2010,25 (6):1-7(in Chinese).[陶新民,徐晶,童志靖,等.不均衡数据下基于阴性免疫的过抽样新算法[J].控制与决策,2010,25 (6):1-7.]
[9]Tang Y,Zhang YQ,Chawla NV,et a1.SVMs modeling for highly imbalanced classifications [J].IEEE Transaction on Systems,Man,and Cybernetics,Part B:Cybernetics,2009,39 (1):281-288.
[10]Wang K J,Makond B,Chen KH,et al.A hybrid classifier combining SMOTE with PSO to estimate 5-year survivability of breast cancer patients [J].Applied Soft Computing,2014,20 (3):15-24.
[11]SUN Tao,WU Haifeng,LIANG Zhigang,et al.SMOTE algorithm in the application of imbalanced data [J].Beijing Biomedical Engineering,2012,31 (5):528-530 (in Chinese).[孙涛,吴海丰,梁志刚,等.SMOTE算法在不平衡数据中的应用 [J].北京生物医学工程,2012,31 (5):528-530.]
[12]Zhong L,Wang B,Wang Z,et al.Research and application of massive data processing technology [C]//8th International Conference on Computer Science & Education.IEEE,2013:829-833.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
甘肃科技(2020年19期)2020-03-11
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
电子测试(2017年15期)2017-12-18
初中生世界·七年级(2017年9期)2017-10-13
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
