
藏语依存树库构建的理论与方法探析
2015-12-14 09:39扎西加多拉
西藏大学学报(自然科学版) 2015年2期
扎西加 多拉
(①西藏大学藏文信息技术研究中心 西藏拉萨850000②西北民族大学中国藏文典籍全文数字化研究所 甘肃兰州730030)
藏语依存树库构建的理论与方法探析
扎西加①多拉②
(①西藏大学藏文信息技术研究中心 西藏拉萨850000②西北民族大学中国藏文典籍全文数字化研究所 甘肃兰州730030)
依存语法又称“从属关系语法”,研究句子各构成成分之间的支配和从属关系。依存结构是指句子中词与词之间的句法结构关系,该结构以树状结构进行描述,被称之为依存结构树库。文章以依存语法的理论框架作为藏语树库构建的理论指导,充分借鉴依存语法的思想精髓,结合藏语语法体系,设立出符合藏语语法体系的句法和语义标注关系体系,设计了判别式的句法分析算法,从而构建了多维视窗的藏语依存树库。具体分析时,首先,对依存语法的由来、定义、依存关系的适用性等背景知识做了简要的阐释;其次,在藏语句子的筛选、藏语依存结构的形式化模型、藏语依存的骨架结构以及藏语依存树的多维关系等方面进行了研究和分析。
依存语法;藏语树库;藏语句法分析;藏语语义分析
引言
依存语法又称“从属关系语法”,研究句子各构成成分之间的支配和从属关系。依存结构是指句子中词语与词语之间的句法结构关系,该结构以树状形式进行描述,被称之为依存结构树。赋有句法和语义结构信息的知识库是自然语言处理的重要资源,同时,计算机要模拟人脑,理解自然语言具有很大的价值。依存树库的构建在近期机器翻译研究领域倍受青睐,原因是其具有结构清晰明了、形式简单了然、句法语义兼顾等优势,逐渐引起学界的重视。
在自然语言理解中,形式模型扮演的角色很重要。形式模型即形式化体系由一系列符号以及一套如何操作这些符号的指令组成。Maxwel l为依存句法分析的智能处理需求,设立了依存关系模型应遵循的
各种依存关系种类,比如,德语设立26种关系,丹麦语设立15种关系,波兰语设立18种关系,孟加拉语设立20种关系,芬兰语设立21种关系,匈牙利语设立21种关系,日语设立20种关系,法语设立21种关系,汉语设立36种关系。为了降低计算机处理自然语言的代价,周明、黄昌宁等人[1]曾将汉语的依存关系数从106种关系减少为44种关系。本文根据藏语语言的结构特点设立了24种句法依存关系和18种语义依存关系。
当前藏文信息处理在词法、句法的研究处于起步阶段,构建藏语依存树库是藏语句法和语义研究必不可少的数据支撑。但目前尚未见到利用依存和配价理论对藏语句法进行研究的相关成果。本文在充分利用现有研究成果基础上,尝试用依存理论开展藏语句法树库的研究,这项工作的开展将在藏语自然语言处理领域发挥重要作用。
1 藏语依存树库的理论框架
1.1 依存语法的由来
在学界有人认为“依存语法的概念可以追溯到公元前4世纪,由印度语言学家Panini创始”[2],但一般视为依存语法理论的创始人是著名的法国语言学家特斯尼耶尔,他的《结构句法基础》中体现了依存语法的理论核心,其著作中首次提出了“结构句法”的一般理论,“结构句法”后来被称之为“依存语法”或“从属关系语法”。为了提出一种通用的语法理论,特斯尼耶尔对古希腊语和古罗马语、罗满族语、斯拉夫语等10几种语言做了大量的对比研究后提出了“结构句法”理论,该语法理论对人类语言进行了深层对比研究,探寻出了不同语言之间的共性,侧重建立跨语言的适用体系,客观地揭示了人类语言中深层普遍的内在句法规律。该理论的提出对语言学的发展做出了重要贡献,意义重大。
1.2 依存语法的定义
句子结构中词与词之间勾勒出层层递进的从属关系,貌似金字塔结构,塔尖是所有从属关系的支配节,被称之为“中心结”。中心结是整个句子的核心、重心和中心,一般情况下大多数中心结为动词,这种用词与词之间的依存关系来描述语言结构的框架称之为依存语法(dependence grammar),也称为从属关系语法(Dependency grammar)。语言学家特斯尼耶尔在《结构句法基础》中虽未对依存语法提出明确的定义,但他在理论与实践验证的过程中循序渐进地提出了依存语法的核心精髓。历来研究依存语法的诸多学者鉴于其理论,提出了各自对依存语法的理解和阐释。周国光对依存语法定义为:“一种结构语法,它主要研究以谓词为中心而构句时由深层语义结构映现为表层句法结构的状况及条件,谓词与体词之间的同现关系,并据此划分谓词的词类。”[3]此定义直观地反映了依存语法的本质内涵。
1.3 依存关系的适用性
依存语法的最小单位是词语,它所关注的对象是词与词之间的从属关系,该关系用来描述句子的深层和表层结构。特斯尼耶尔认为:“关联(eonnexion)、组合(jonetion)和转位(translation)是概括一切结构句法现象的三大核心。”[4]其中,关联指建立词与词之间的依存关系,它是由支配项与从属项联结形成;组合是指词与词之间的并列关系,粗略地说并列关系是一个支配项拥有多个从属项;转位则指一个实词成分在句法上转移成另一个实词成分,或者能够改变词汇元素的句法范畴中所支持其他元素关系的功能词,确切地讲“结构联系建立起词与词之间的依存关系,每一项联系原则上将一个上项和一个下项联结起
来,上项叫支配词,下项叫从属词。一个词可以同时是某个上项词的从属词和另一个下项词的支配词。”[5]句子里的所有词便构成一个真正的分层次的体系。动词是一个句子的中心,支配句中的其他成分。
20世纪70年代,美国语言学家罗宾松(Robinson)首次提出了依存语法的4条公理,“一个句子中只有一个成分是独立的;其他成分直接依存于某一成分;任何一个成分都不能依存于两个或两个以上的成分;如果A成分直接依存于B成分,而C成分在句中位于A和B之间,那么C或者直接依存于A,或者直接依存于B,或者直接依存于A和B之间的某一成分。”[6]
这四条公理保证了依存句法分析时遵循的原则是单一父结点(single headed)、连通(connective)、无环(acycl icity)、可投影(Projective)。对依存语法的形式化描述提供了形式上的约束,为计算语言学中的应用奠定了良好的基础。20世纪80年代,舒贝尔特(K.Schuber t)在多语言机器翻译系统DLT研发中,提出了面向自然语言处理的12条依存语法原则,其中含有上述4条公理,并且拓宽了依存语法的研究领域。20世纪90年代,我国著名学者冯志伟先生将依存语法的理论引进国内自然语言处理研究领域,冯先生根据机器翻译的实践经验,提出了满足依存结构树的5种条件。在藏语自然语之外领域通过描述藏语依存树结构发现,藏语的依存树契合以上所有的条件,并且在句法树和语义树的对应关系方面一致性更强。
2 藏语依存树库构建方法
2.1 藏语句子的筛选原则
在选择研究句子时,综合考虑句型、体裁、时代、语体等,使选择的句子具有代表性和针对性。藏语传统语法理论将藏语句型分为他动句、自动句、依存句、主谓句及述谓句等5种类型,在选择句子时可以以这些基本句型作为依据,对句子分类进行深入研究,使其涵盖藏语的所有句型。
在内容方面,根据藏语实际应用范围,选择典型句子的语料中应包含文学、学术、新闻、历史、传记、宗教等藏语应用领域中的主要体裁。鉴于藏语各种方言的不同和书面文字的差别,拟选择统一的书面表达的句子。同时,在选择句子时还充分考虑时代等特点,使选择的句子具有代表性。按照以上原则从大规模藏文文本中筛选10000个句子,以此形成包括单句、复句、句群等在内的藏语典型句型库。
2.2 树库构建的基本流程
第一步,大规模藏文原始文本作为处理对象,通过藏语句子末端的规则进行筛选句子;对整理完成的文本进行机器自动分词和词性标注,再用人工方法对分词和词性标注的结果进行校对,校对分为一校和二校两步,首先由4名藏语语法学专业的硕士生进行一校,完成一校后,为了保证藏文分词及词性标注的一致性,负责人完成第二校的工作。在分词、词性标注方面主要采用西藏大学制定的“信息处理用现代藏语分词规范”和“信息处理用现代藏语词类标记集规范”,以上两种规范已提交国家信标委藏文信息技术标准工作组。
第二步,分词和词性标注的基础上建立藏语依存树库的标注体系,包括藏语依存关系的层次体系和语义次级体系。根据藏语句子的成分进行分类研究,对精加工过的句子成分进行结构和关联标注,形成较大规模的语法单位句法成分标注库,从而找出其依存关系,形成完整的依存句法树库。最后,依据藏语依存句法的形式化模型,建立藏语依存分析的概率模型,设计分析藏语依存的算法。树库构建的基本流
程见图1。
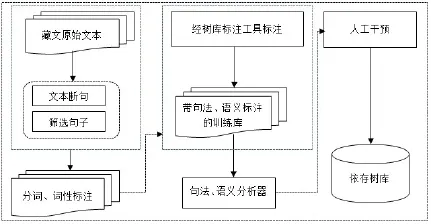
图1 树库构建的基本流程
3 藏语依存结构的形式化模型
语法是剖析语言现象的一种理论,通过自然语言来描述所涉及对象的特性,从而达到理论的精确表达。另外一种有关对象的描述是建立模型,模型是将对象的某些特征提取出来形成的一种人造结构。在语言中,广为使用的一种形式模型是图,图的主要元素是顶点和边,“树”就是一种特殊的图。这样可以更清楚地认识到所谓语言或语法研究的形式化实际上就是用一套标注符号体系来对研究对象进行抽象的方法。换言之,“语句的理解和生成是一个在线性次序(一维)和结构(二维)之间的转换过程。在这个过程中,图式的作用不可忽略,因为它可以抽象的、潜在的概念,形象地表示出来。”[7]为了能够让计算机模仿一维线性串转换为二维树形结构的过程,采用模型及形式化的方法研究语言结构有助于在计算机上实现。也可以说形式化是程序化的基础。
3.1 藏语依存结构分析
依存语法的4公理和5条件均为形式化描述,用来制定藏语依存句法结构的形式约束或其合乎性,其实依存关系指的是词与词之间的支配与从属关系,而藏语中的这种关系是一种具有方向的不对等关系。简单地讲,置于支配及控制地位的成分项被称为支配者,处于被支配及被控制地位的成分项称之为从属者,换句话说,“句子的结构是一种自上而下的,有层级,有等级关系。”[8]一般支配和从属关系被描述为父子结点的关系类型。支配和被支配的关系以带有方向性的有向弧线图来表示;带多标记立体结构的支配和被支配的关系以依存树的图式来表示;格标记和中心词的从属关系以词格标记树形图来表示;在依存投影树中,如从属关系包含着潜在的依存关系时,可以用虚线来表示。
在藏语依存句法分析的过程中,由以图式和符号表示的依存句法结构形式为联接依存语法和依存分析算法的中介。将以形式化的文法规则或形式约束来描述边结点所附带的各种信息。常用藏语依存结构的图式有有向图(见图2)、藏语依存树(见图3)、格标记树形图(见图4)及藏语依存投影树(见图5)4种。
如图2所示的有向关系图中不同标记代表不同的词类,比如:nr代表人名,bo代表施事格标记,nn代表一般名词,ba代表工具格标记,nn代表一般名词,ls代表业格标记,nn代表一般名词,vt代表及物动词,
依存弧线用来表示各词类之间的关系,箭头端为从属词,无箭头端为支配词,这样能够更形象地了解词间依存关系的层次体系。
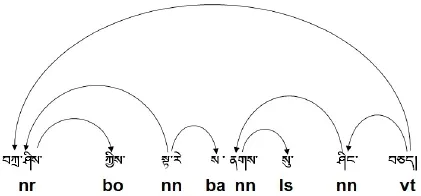
图2 有向图
参照依存骨架分析的结果,形成携带多标记立体结构的依存树的图形表示见图3。
在藏语中,N(名词)和Det(格标记)与之间的依存关系是:N是中心词,Det是从属词,Det处于名词的右侧,该从属关系如图4所示。
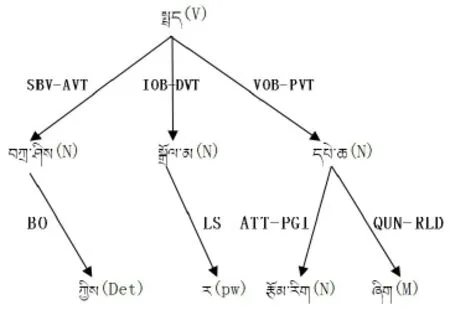
图3 依存树
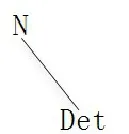
图4 藏语格标记的树形图
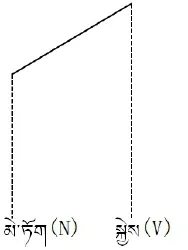
图5 依存投影树
另外,在依存投影树中,从属词与支配词之间的依存关系可以用虚线来表示,这种从属关系还包含着潜在的依存关系(见图5)。
藏语依存树库的建设属于句法分析和语义分析的重要数据支撑。句法分析和语义分析的主要任务是自动剖析句子的表层和深层的结构关系,换言之,将一个线性呈现的句子转换成一个结构化的一颗语法树。本文根据藏语依存关系的形式化体系,确定了藏语句子中词与词之间的依存关系,并且采用4种图式对藏语句法、语义依存骨架结构进行细致入微的分析,并直观地刻画出形式多样的藏语依存关系图式。
3.2 藏语依存树的多维分析
藏语依存树的多维分析采用了判别式的句法分析,以词性判断句法、以句法推到语义的多维递进、互为映照的分析模式,这种分析模式符合藏语句法语义的的推理机制。依存语法本身并未对依存关系进行详细分类,但是为了更加丰富依存结构映射的句法和语义信息,在应用分析时,一般会对依存树的各个边结点赋上不同的标记。边结点可以附带的信息有:藏语词汇本身(Tibetan words),藏文分词标记(Tibetan Segmentation),pos藏语词性标记(Tibetan par t of speechtags),藏语句法(语法)功能(Tibetan syntactic funetions),藏语语义角色(Tibetan semantieroles)等多种信息。具体如图6和图7。
第一层(最底层)表示词性及其序列号,第二层为藏文词汇本身或字符串及其分词标记,第三层为依存句法标记。在依存句法标记中,ADV为状中关系,RAD为后附加,ls为业格,SBV为主谓关系,RAD为后附加,QUN为数量定中关系,VOB为涉事宾语,ic为小句核心,cn为衔接连词,ADV为状中关系,ld为同体格,HED为整句核心。
第一层(最底层)表示词性及其序列号,第二层为藏文词汇本省或字符串及其分词标记,第三层为依存语义标记。在依存语义标记中,LNF为与事对,RLD为范围,ls为业格,ATV为施事,RLD为范围,RLD为范围,PVT涉事对象,ic为小句核心,cn为衔接连词,RLD为谓语同体,ld为同体格,HED为整句核心。

图6 藏语依存句法树

图7 藏语依存语义树
3.3 数据库表示藏语依存关系
对形式化的藏语依存关系,根据树结构的信息可以确定树库的格式,树库采用的格式见表1,此格式便于标注者采用Excel、Access等常用办公软件进行标注。

表1 藏语依存句法树库的格式
上述藏语依存句法形式化模型中,可以获取赋有标注的藏语依存关系树,此树库含有丰富的句法和词汇信息。通过对藏语依存树库的深度学习和统计分析,获取该树库中的词汇依存关系的各种信息,从而构建词汇化概率分析模型,然后引入词汇支配度的概念,再充分利用句子中的结构信息,设计一个分析句子依存关系的算法。用该算法不仅验证提出的形式化的藏文依存关系,同时找出更多的依存关系。
表1中的每一行对应的是藏语句子结构中的一种依存关系,在一个句子中含有n个词时,应有n-1的依存关系。我们利用这种方式逐步分析句子时,如果某种语言中含有m个句子,则可以形成(m×n)-m个依存关系。而这些句子的依存关系集合,可以称之为藏语依存树库。
4 结语
藏语树库是藏语自然语言处理研究中的一项关键环节,也是藏语句法与语义分析衔接的重要桥梁。经过藏语自身的语法特点出发,以依存语法理论与方法为导向,研究和构建适合藏语语言本体的依存树库,重点解决了藏语句法和语义同步分析的策略问题,具体分析中力求从句法形式得到语义的逻辑验证,从语义映射句法形式的结构验证,为藏语句法和语义分析提供了较为理想的形式化描写策略。这种研究对推动藏文信息处理技术的发展有着重要意义,藏语依存树库的构建正是这方面的努力和尝试。
[1]周明,黄昌宁.面向语料库标注的汉语依存体系探讨[J].中文信息学报,1994(3):35-50.
[2]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008:181.
[3]周国光.汉语配价语法论略[J].南京师范大学学报,1994(4):103-106.
[4]刘海涛.依存语法和机器翻译[J].语言文字应用,1997(3):89.
[5]袁毓林.汉语配价语法研究[M].北京:商务印书馆,2010:314.
[6]刘海涛.依存语法和机器翻译[J].语言文字应用,1997,23(3):89.
[7]刘海涛.依存语法的理论与实践[M].北京:科学出版社,2009:120.
[8]明扬.西方语言学名著选读[M].北京:中国人民大学出版社,2011:229.
Theory and M ethod of Tibetan dependency Treebank construction
Tashi-Gyal①Duo-La②
(①Research Centerof Tibetan Information Technology,TibetUniversity,Lhasa 850000,China;②NorthwestUniversity forNationalities,Lanzhou 730030,China)
Dependency grammar also called"subordinate relationship grammar",and it research on the relation⁃ship between the dominantand subordinate constituentsofa sentence.Dependency structure refers to the syntac⁃tic relations between thewords in the sentence and the structure described in a tree structure,called for depen⁃dency treebank.The theoretical framework of dependency grammar as the theoretical guidance for the Tibetan treebank construction,fully drawing ideological essence of dependency grammar and combining with Tibetan grammar system,a syntactic and semantic tagging system in line with the Tibetan grammar system was set up and the discrimination of the syntax analysis algorithm was designed in order to building a Tibetan dependency treebank ofmultidimensionalwindows.In the specific analysis,firstofall,the background knowledgewasbriefly explained in terms of the dependency grammar origin,definition and the applicability of dependency relation⁃ship,secondly,the selection of Tibetan sentences,formalmodelof dependency structure,dependency framework structure andmultidimensional relationship of Tibetan dependency treewere analyzed aswell.
dependency grammar;Tibetan treebank;Tibetan syntactic analysis;Tibetan semantic analysis
10.16249/j.cnki.54-1034/c.2015.02.013
TP391.1
A
1005-5738(2015)02-076-08
2015-05-25
2012年度国家自然科学基金项目“藏语依存树库的构建”(项目号:61163043);2014年度国家哲学社会科学基金重大项目“基于地理信息平台的藏语方言数据库建设”(项目号:14ZDB101);2015年度西藏自治区高校青年教师创新支持计划项目“经典藏文文献标注语料库建设与词汇计量研究”(项目号:QC2015-19);2015年度西藏大学珠峰学者人才发展支持计划主体计划“杰出青年学者”项目阶段性成果。
扎西加,男,藏族,青海海南人,西藏大学藏文信息技术研究中心副教授,主要研究方向为计算语言学、藏文信息处理。
[责任编辑:索郎桑姆]
猜你喜欢
客联(2022年2期)2022-04-29
大连民族大学学报(2021年2期)2021-07-16
西藏研究(2021年1期)2021-06-09
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
西藏研究(2017年3期)2017-09-05
西藏大学学报(自然科学版)(2016年1期)2016-11-15
西藏研究(2016年5期)2016-06-15
