
一种语义信息网中构建最大相关本体图的新算法
2015-12-02 06:07:58房健赵彦明
河北民族师范学院学报 2015年2期
房健,赵彦明
(河北民族师范学院数学与计算机系,河北承德067000)
一种语义信息网中构建最大相关本体图的新算法
房健,赵彦明
(河北民族师范学院数学与计算机系,河北承德067000)
表示和管理海量语义信息中所隐含领域知识的方法是制约数据挖掘技术发展和信息系统研发的核心问题。通过分析本体图语义项特征和语义项之间的相关性对知识表示的影响,提出一种评价语义项重要度的新标准,建立一套度量语义项之间相关性的新策略,进而提出从语义信息网中构建最大相关本体图的新算法,运用此算法生成的本体图能够更加准确地表示领域知识,并且最小化本体生成过程中的人为交互。
语义项;最大相关性;本体图;算法
1 引言
使用本体(Ontology)[1]来学习语义网页信息中隐含的领域知识起源于本世纪初。2001年,Karlsruhe大学的Maedche和Staab提出了一个构建领域本体的半自动框架构想[2],此框架构想在理论层面上描述了如何导入、提取、剪枝、提纯、以及评价领域本体。在Maedche和Staab工作的指引下,三种具有代表性的领域本体生成引擎被相继提出,它们分别是:Protégé[3],Nto-Edit[4]和Onto-Builder[5]。然而,这些本体生成过程中的人为交互给领域本体的生成带来运行时间过长的问题。为此,香港理工大学James教授于2008年首次提出了采用归纳学习的方式自动学习和构建领域本体的观点,并且以文章本体(Article-ontology),话题本体(Topic-ontology),以及词典本体(Lexicon-ontology)相结合的方式来表示领域知识,最终所提取到的本体被视为是领域本体图的雏形。2009年,James教授给出了领域本体图的完整定义,较之已有的领域本体提取的方法,本体图中的语义项是在通过对大量的语义网页数据学习的基础之上、采用统计词频的方法[6]提取到的,并且详细地描述了两两语义项之间的相关程度以及相关的性质。目前,James教授在其最新著作中,通过大量的仿真实验验证和证实了本体图在语义网页文本分类应用中的优良表现,并详细介绍了领域本体图在商业应用中所取得的巨大突破。然而,基于词频统计以及线性相关度量构建的本体图尚有改进和更新的余地,即通过重要度进行语义项提取以及采用更一般的相关度量标准衡量语义项之间的相关,从而进一步提高和增强领域本体图的准确度和应用范围。
2 传统本体图生成过程中问题分析
目前,通过本体图来表示领域知识以及构建信息系统是解决海量信息管理问题的重要途径。对基于本体图的知识信息系统的构建主要采用通过词频统计的方法从语义网中提取高频语义项(Semantic term)、利用线性相关度量标准来衡量语义项之间的相关程度,在领域本体抽取的过程中通常也是通过人为交互的方法来实现的。这类方法在某些领域内有较好表示,但存在一定欠缺:(1)在传统的本体图生成策略中,主要通过计算各语义项在网页文本信息中出现的频率从而挑选出高频语义项作为本体图的顶点,虽然依据此策略挑选的高频语义项在知识表示时具有一定的代表性,然而,统计词频的方式却忽略了各语义项与网页文本信息主题(Topic)之间的关系。因此,网页的类别有时往往由那些没有被提取到的低频语义项所决定;(2)传统的本体图生成过程仅采用线性相关度量两个语义项之间的相互关系,而事实上在众多的实际应用中,相关通常存在于多个语义项之间,并且它们之间的相关亦多为非线性的;(3)在领域本体图生成的过程中,过多的人为交互需要大量的运行时间,这意味着所生成的本体图将不能够准确地表示领域知识,并且构建的知识信息系统也不能为用户提供即时有效地在线服务。因此,如何利用本体图准确地表示语义信息中所隐含的领域知识、并有效地降低或减少本体图生成过程中的人为交互势必成为语义网页数据挖掘领域的一项重要内容。
3 研究过程
通过分析传统本体图生成过程中存在的问题,本研究试图提出一种准确且智能的本体图提取和生成策略并解决本体图生成过程中的出现的问题。研究步骤如下。
3.1有针对性地收集语义网文本信息

3.2定义提取语义项重要度
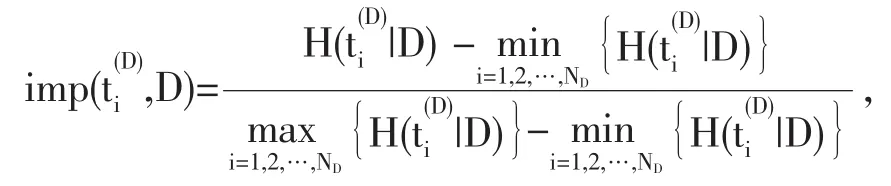
3.3建立新的相关性度量标准衡量不同语义项之间的相关度
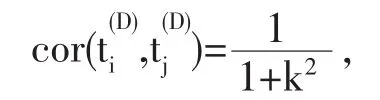
其中,

3.4建立一种构建最大相关本体图的启发式算法

4 结论
综上所述,此项实验研究提出了一种新的度量语义项重要度的标准,通过使用重要度较高的语义项来构建本体图可以替代已有的高频语义项的选取准则,同时建立了新的语义项相关度量准则,使其可以度量语义项之间的非线性相关以及多语义项之间的相关,最终提出了一种最大相关本体图生成的新算法,使顶点语义项与文本主题之间的相关最大化以及顶点语义项之间的连接能够实现最简化,能够更加准确地表示领域知识,最小化本体生成过程中的人为交互。
[1]Buitelaar et al.O ntology Learning and Population:Bridging the G ap Betw een Text and K now ledge[J].IO S Press,2008,V ol.10:70-71.
[2]A edche et al.O ntology Learning for the Semantic W eb [J].IEEE Intelligent Systems,2001,V ol.16:72-79.
[3]F.N oy etal.Creating SemanticW ebContentsw ith Protégé-2000[J].IEEE IntelligentSystems,2001, V ol.16:60-71,.
[4]Y.Sureetal.G uidingO ntologyD evelopmentby M ethodology and Inference[J].Lecture N otes in Computer Science,2002,V ol.2519:1205-1222.
[5]H.Roitman et al.O nto Builder:Fully A utomatic Extraction and Consolidation ofO ntologies from W eb Sources U sing Sequence Semantics[J].Lecture N otes in Computer Science,2006,V ol.4254:573-576.
[6]Y.J.Li et al.TextClustering w ith Feature Selection by U sing Statistical D ata[J].IEEE Transaction on K now ledgeandD ataEngineering,2008,V ol.20:641-652.
[7]黄晓斌.网络信息挖掘[M].北京:电子工业出版社,2005.
On New Algorithm in Building the Most Relevant Ontology Mapping in Semantic Web
FANG Jian,ZHAO Yan-ming
(Hebei Normal University for Nationalities,Chengde,Hebei 067000,China)
The approach of presenting and managing the massive semantic information in implied domain knowledge is the main factor restricting the technical development of data mining and the research on information systems.By analyzing the features of ontology semantic items and the impact of the correlative semantic items on the knowledge representation,this paper puts forward a new standard of evaluating the importance of semantic items,establishes a new strategy of measuring the correlation between semantic items and proposes a new algorithm in building the most relevant ontology mapping in semantic web.The ontology created by this algorithm can represent domain knowledge more accurately and minimize the human interaction.
semantic items;the largest correlation;ontology;algorithm
TP63
A
2095-3763(2015)02-0087-03
2014-10-18
房健(1979-),女,辽宁台安人,河北民族师范学院数学与计算机系讲师,研究方向为计算机教育与网络技术。
2014年度河北省教育厅资助科研项目(Z2014082);2013年度河北民族师范学院科研基金项目(201302)。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
园林科技(2021年3期)2022-01-19 03:17:48
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
摄影之友(影像视觉)(2019年2期)2019-03-05 08:27:20
中国篆刻(2017年5期)2017-07-18 11:09:30
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
