
基于案例分析金字塔模型的主动运维案例体系建设
2015-11-26 01:08曹逸峰尚鸿斌包妍苹陈晓伟
计算机与现代化 2015年3期
曹逸峰,尚鸿斌,陈 杰,包妍苹,沈 璟,刘 旭,陈晓伟
(中国农业银行股份有限公司数据中心,上海 200131)
0 引言
随着信息化的快速普及与发展,现代企业对信息系统依赖程度逐渐提高,对运维管理的投入也不断加大。目前,国内很多企业通过了ISO20000 IT 服务管理体系认证,同时也建立了自己信息系统运维管理方面的案例库,但这些案例基本都停留在案例展示阶段,尚未涉及基于已有案例的风险预测、应急决策等分析功能,也没有形成有效的案例教学模式进行经验交流与共享[1]。ISO20000 服务体系强调事件和问题等13 个流程的日常管理,但对于主动性运维方式缺乏足够的延伸。面对现代企业信息系统生产运维压力的急剧增加,以及类似故障重复发生、处置差异较大的严峻形势,迫切需要开展新的生产运行案例建设研究。
尽管运维自动化程度在不断提高,但在案例自动生成方面,还没有十分有效的智能处理方式自动生成运维人员需要的案例。同时,在故障预测方面,基本全靠运维经验和被动应付,缺乏有效的预测方法。另外,在事中决策支持领域,缺乏实际可行的方案,基于案例的推理(Case Based Reasoning,CBR)是一种新兴的机器学习和推理方法,其核心思想是重用过去人们解决问题的经验解决新问题[2],目前,国外已有很多成功的应用,但国内在实际系统中应用CBR 的成功例子还较少,有待进一步发展。
针对以上情况,本文提出一种主动运维案例体系建设思路:一方面研究采用智能化方式构建生产运维案例库;另一方面探索基于该案例库的多个相关应用,如预测预警、辅助决策和案例教学,最终利用统一的工具平台实现并整合各模块,以达到有效降低事件重复发生频率,提高事中定位与处置能力,充分共享经验教训的效果。首先,案例库建设采用向量化解析和改进的KNN 文本分类技术[3],实现运维服务台事件单信息中案例知识素材的自动获取。其次,采用密度预测和关系预测的方法[4],实现事件事前预警预测。同时,在现有案例推理“4R”模型[5]的基础上,通过增加案例的重新划分形成一种“5R”案例推理模型,实现事中处置的辅助决策机制。另外,在经验共享方面,提出一种改进“4S”运维案例教学模式[6],收录异常案例,为事后共享经验教训提供手段。
1 主动运维案例体系整体结构
本文针对传统案例建设存在的弊端,提出一种可行且高效的主动生产运维案例体系。该体系采用了向量化解析和知识分层提取的方式构建案例分析金字塔模型,同时基于此模型研究多个相关应用,如事件的趋势及预测预警分析、基于CBR 的辅助决策机制和“4S”案例教学模式,最终利用统一的工具平台实现以上所有功能。整体结构如图1 所示,体系主要由案例库建设、相关应用和工具平台建设3 个部分组成。
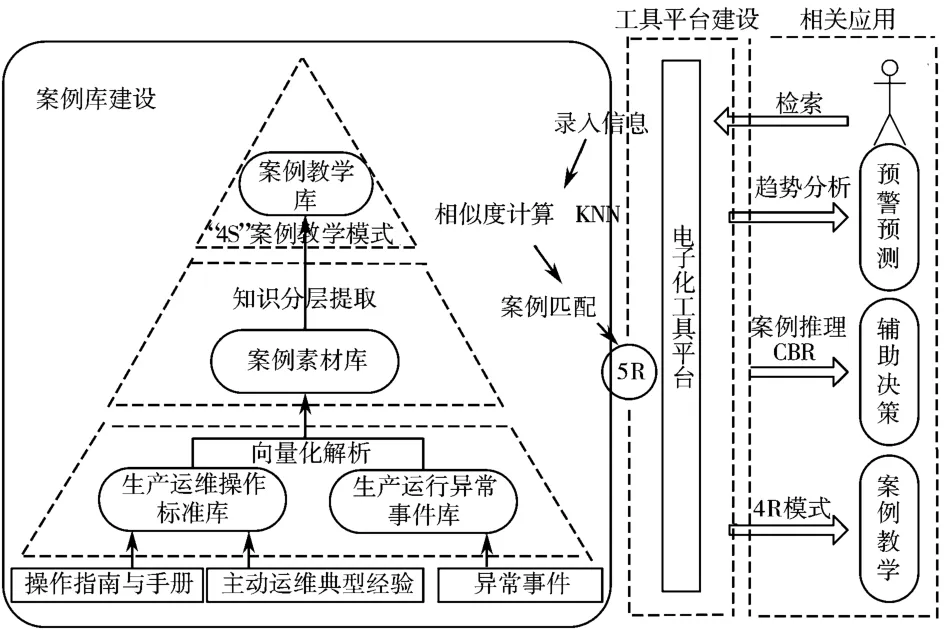
图1 生产运维案例体系整体结构图
案例库建设模块由三层结构的金字塔模型构成,金字塔结构的最底层是生产运维操作标准库和生产运行异常事件库,操作标准库来源于日常的操作指南与手册以及主动运维典型经验,异常事件库则是信息系统运维服务台上的异常事件信息收录汇总。第二层是案例素材库,主要包括组成案例的素材元素、零散知识点等,并通过向量化解析和知识分层提取,起到承接上下层的作用。最顶层是案例教学库,是由案例素材和知识模块组成的精华案例,可以用于案例宣讲与教学、事中处置参考、在线学习等。
相关应用主要包括辅助决策、预警预测和案例教学。运维人员通过关键字检索或建立事件单时,系统就会将输入信息与现有案例进行相似度计算匹配,将最相近的案例(包括故障原因和最佳处置方案)推荐给工作人员。系统通过对运维服务台大量已有事件按照不同维度进行统计分析,得到事件集中领域分布情况和未来可能性趋势,从而实现预警预测的功能。利用改进的“4S”模型完善企业的运维团队、管理流程和质量标准实现线上线下的案例教学与经验共享机制。
最后就是电子化工具平台建设,将案例库建设及相关应用与现有运维操作管理平台进行功能整合及改造,实现对运维案例的电子化管理与操作。
2 主动运维案例体系建设
2.1 案例分析金字塔模型
案例分析金字塔模型是整个主动运维案例体系建设的基础与核心。本文在现有案例研究的基础上,结合运维管理中事件、问题处理的特点提出了一种三层结构的案例分析金字塔模型,如图2 所示:最底层通过制定统一、易操作的异常事件分类以及运维操作标准,将生产运行事件及运维操作从响应、定位、处置、动作、方法等方面进行结构化拆分,形成异常现象、原因、处置方案、标准动作以及操作方法等结构化要素,建立生产运行事件库以及运维操作标准库。中间层通过机器学习和文本处理技术,将结构化后的大量事件数据信息进行原子化的拆分与标准化归置,并对元数据进行了分类比较,筛选出适用于案例分析的典型事件素材信息。最顶层遵循案例编制科学流程,结合案例研究团队专家组织对筛选出的典型事件素材进行案例分析,形成案例教学与宣讲相关材料。
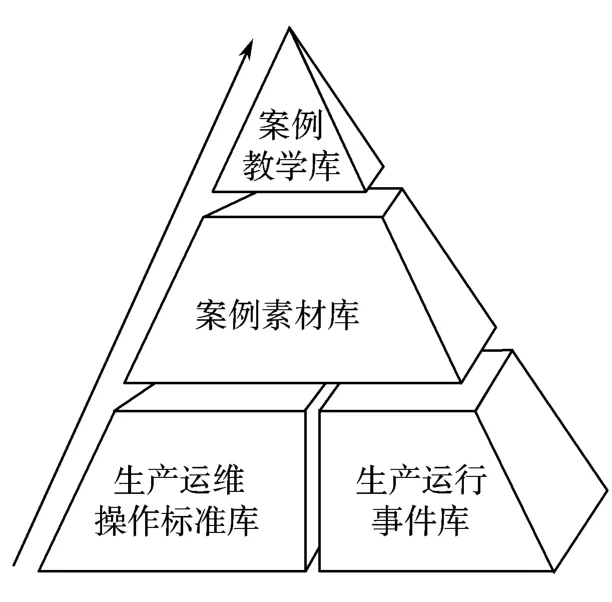
图2 案例分析金字塔模型
2.1.1 生产运维操作标准库和生产运行事件库
生产运维操作标准库和生产运行事件库位于案例分析金字塔模型的最底层,是案例分析的基础。其中,生产运维操作方法标准库是通过日常运维经验和知识的累积并在反复实践的基础上形成的运维操作基本规范。生产运行异常事件库则是收录信息系统异常事件信息,一般的事件信息主要记录于运维服务台事件工单中。
在生产运维操作标准库中按照硬件设施(环境)、系统、应用、网络等分类将各个领域异常处置动作标准化形成操作规范汇总,并通过索引实现快速检索。以EMC NAS 存储异常断电故障处置为例,其最佳处置标准如表1 所示,整个处置流程由一系列标准动作及其索引组成。
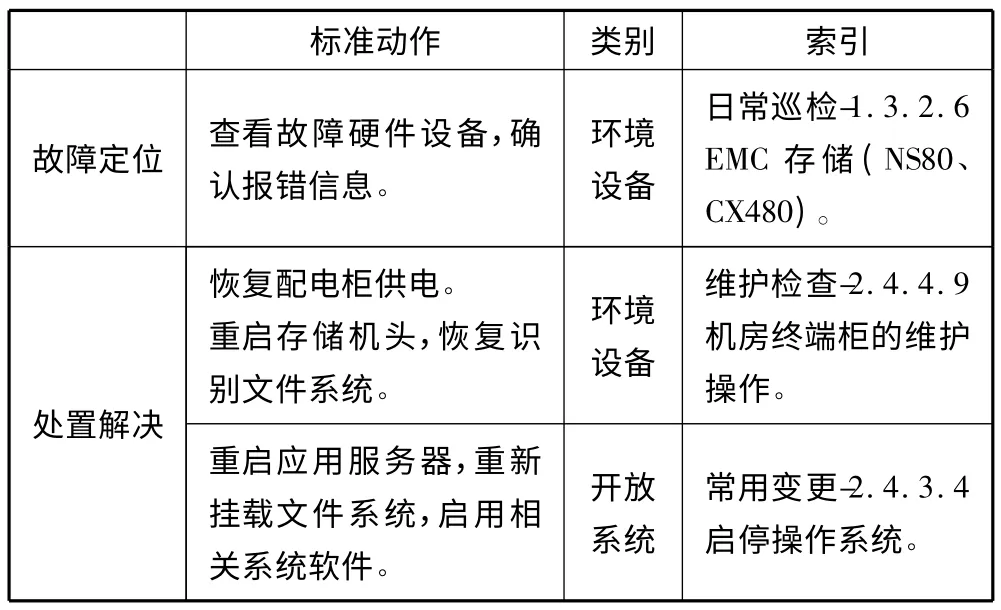
表1 EMC NAS 存储故障处置标准操作方法
生产运行异常事件库中每件事件信息都可以拆分成“问题现象”、“原因分析”、“处置过程”3 个短文本要素。其中,问题短文本包括异常描述、事件编号、发生日期、事发单位、监控渠道等信息;原因短文本包括原因分析、所属领域、故障类型、故障设施/部件、供应方等信息;处置短文本包括处置措施、后续计划、故障持续时间、业务影响时间、影响范围等信息。
2.1.2 案例素材库
案例素材库作为案例分析金字塔模型的中间层起到承上启下的作用,它需要从底层的异常事件信息中获取各种知识素材,同时为顶层的案例教学库提供组成案例和分析案例的支撑信息。本文在案例素材生成方面,提出了一种面向非结构化事件短文本信息的自动分层提取模型,改变了传统案例库单纯依靠人工收录整理的方式。在生产运维操作标准库的基础上通过该模型实现对生产运行异常事件库中的生产运维相关知识素材的自动提取,模型结构如图3 所示。
分层提取模型由4 层构成,从下往上依次为原始数据层、向量空间层、领域规则层和知识实体层。其中,最底层是原始数据层,主要指生产运维相关的异常事件信息,包括服务台事件工单和异常事件库等;第二层是向量空间层,是将原始数据层经过一系列向量化处理得到的向量空间集,以便于机器识别和处理;第三层是领域规则层,主要功能是将向量空间集进行分类处理并按主题规则保存处理后的数据,包括分类器[7]、主题类别、训练集等;最顶层则是知识实体层,它是按照领域规则提取得到的知识模块并对各个模块打上属性标签便于知识的快速检索。当新的生产运维事件发生时,事件信息经过分层模型处理,便可自动提取得到有价值的案例知识素材。
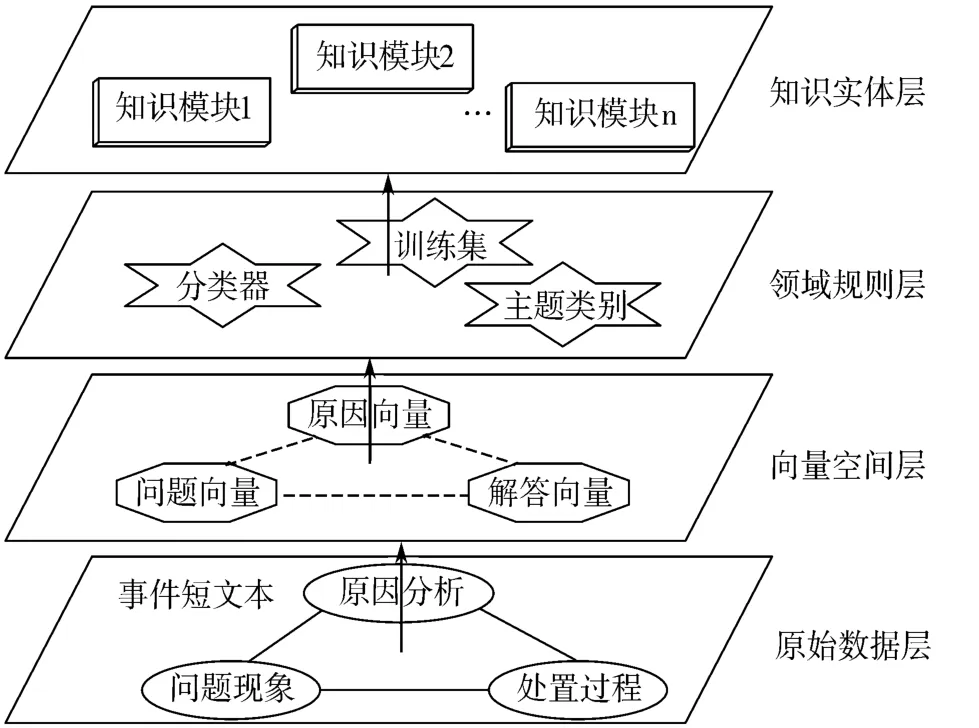
图3 案例素材分层构建模型
整个分层模型的核心是向量化和文本分类,向量化的作用是便于自动化处理,文本分类是为了结果筛选和知识发现。
生产运行异常事件库中的信息都是以短文本形式保存的非结构化数据,为了能进行机器自动分类处理,必须对其进行预处理以便计算机能识别。利用基于向量空间模型[8]的文本表示方法,对事件文本进行分词[9]、去禁用词[10]、特征向量表示和特征扩展处理,便可形成异常事件的向量化空间集。
文本分类的思想是按照预先定义的主题类别,为文档集合中每个文档确定一个类别,事件短文本的分类与传统的文本分类类似,也包括训练和分类2 个过程。采用KNN 算法构造分类器并对已有事件短文本进行分类训练形成若干训练集类别,若有新事件文本加入,分类器按照算法规则自动将其归类。分类后的信息按照预先设定的规则进行筛选从而达到知识发现的目的,同时根据知识特点给短文本信息打上不同的属性标签,方便知识的检索。
向量化表示中的特征词扩展和事件短文本分类的主题类别都可以依据现有的生产运维操作标准库进行扩展和预先定义。
2.1.3 案例教学库
案例教学库包括系统自动生成组装的最佳处置案例和人工运维经验总结提炼的案例。
系统生成的案例,是经过分类统计并按照一定筛选规则得到同一类事件可能原因分布、处置耗时等,然后根据这些要素组装成一个完整的最优案例。其中筛选规则的设定可以根据生产运维的需要进行灵活设置,例如事件短文本中针对异常现象相近的“问题现象”短文本,对其相应的“原因分析”短文本进行分类,并按次数多少进行排序,排在前面的就是最可能的故障原因。同理对原因相近的“处置过程”短文本,分类后按处置时间长短排序即可得到效率最高的处置方案。
人工总结案例又可以分为主动运维案例和异常处置案例。主动运维案例是对生产运行中以预防风险、提升运维质量为目的,实施并取得良好效果的主动运维工作成果和经验的归纳提炼。包括微码升级案例、机房搬迁案例、应急演练案例等。异常处置案例则是对生产运行中发生的典型事件的基本信息、处置过程的回顾总结和处置经验或教训的归纳。
2.2 生产运行事件预测模型
2.2.1 分布规律
在信息系统运维过程中发生的异常事件信息,短期看似乎无规律可循,但是从长期统计的数据分析发现里面蕴藏很多有价值的信息,能够清晰地反映目前的运维状况并指导以后的运维工作。尤其是故障原因分布、处置时间分布、发生趋势等都呈现明显的规律。以小型机设备故障为例,统计其近2 年设备故障处置时间,并利用SPSS 统计软件分析发现小型机设备故障处置时间近似呈正态分布(落点与斜线吻合),如图4 所示。类似分析其他类型故障处置时间也大致呈正态分布、偏态分布、指数分布等规律。

图4 小型机故障处置时间SPSS 正态分布Q-Q 图
通过这些分布规律,可以对某类事件进行初步的预测,判断其大概处置时间(峰值附近)。同样还可以分析得到某一类异常事件常见原因、趋势特点等特性,从而分析发现故障异常的根本原因所在,以及发生的常见时点和概率,以便提前做好事前防御保障等工作。
2.2.2 事件分析与预测方法
分布规律只能做初步预测,具体还需要采用一定的预测方法来完善预测模型。常用的预测分析方法有密度预测和关系预测。预测模块首先需要从事件库中提取事件信息,标准的事件信息以如下形式表达(类型,区域,时间,特征1,特征2,……),其中类型、区域、时间及特征向量等要素可以通过正则表达式匹配获得。密度预测,用来预测设定区间内的事件密集程度,应用于发生时间、地域规律、类型等规律。关系预测用来分析区间内事件点的“紧密程度”,应用于事件次生规律、辅助判断事件根本原因定位。相关公式如下:
1)密度预测公式。
利用查找聚集和基于距离的规则,采用修改过的BIRCH 聚集算法[11],该算法是基于已知规则的预测方法:

该算法基本实现方法为:
假设已知d 是影响Cx(某一类事件)的已知规则(如温度)或规则合集(如温度和湿度):①将大范围内已发生的C 类事件以d 特征向量(或合集)进行收缩投影,形成以d 为x 轴、以时间(或区域等其他特征向量)为y 轴的二维点状图形,其中的每个点代表一个真实的C 类事件;②设定初始计算阈值为do,在图形中计算以do 为边长的矩形中点(真实事件)的个数,并逐步将do 进行缩减计算;③对以do 为边长的矩形进行点数统计排序,当某一块或某几块相同面积的矩形中点数较其他矩形点数超过一定比例时,判断此类矩形的x、y 的特征集合为C 类事件的高发特性;④当出现或预计出现x、y 的特征集合现象时,预测出现C 类事件的概率较大(可量化)。
实际预测中,可对以d 为x 轴、以时间为y 轴、以区域为z 轴的三维(甚至多维)点状图形,实现更精细、精准的多维度密度预测[12]。
2)关系预测公式。
利用多维空间内距离量度的规则,采用欧几里得距离或Manhattan 算法[13],是对看似无规则事件之间关联关系的发掘与预测的方法:
记S[X]为N 个元组t1,t2,..,tN在属性集X 上的投影,则S[X]的直径:

该算法的基本实现方法为:
①计算X 属性集中各类属性之间的t1,t2,..,tN事件之间的距离;②将t1,t2,..,tN事件以X 属性集的S[X]直径进行全量投影,形成一个事件的多维分布图[14];③利用改进为多维的密度预测方法,对分布图内固定容积空间(或多维空间)内具体属性T 的S[X]距离进行正态分布投影计算;④当出现某类T 属性的S[X]距离的投影分布密度较大时,则认为T 属性是影响t1,t2,..,tN事件的重要因素,可再利用密度预测方法基于T 属性进行预测。
2.3 基于CBR 的主动运维辅助决策机制
基于案例的推理一般包括4 个主要步骤即传统的“4R”模型,具体如下。1)检索(Retrieve):采用一定的相似度算法,当用户检索时,计算当前案例与案例库中案例的相似度值,比较并找出与当前问题最相似的案例。2)重用(Reuse):直接采用最相似案例的处置方案,或部分采用相似案例的处置方案。3)修正(Revise):实际情况下,检索得到的案例处置方案不一定符合当时的工作需求。因此,需要采用一定的修正方法,根据具体的操作环境,对案例处置方案进行调整优化,才能重用到目标案例上。4)保持(Retain):修正后的案例作为一个新的案例保存到案例库中,若碰到类似问题以便重用。这样案例库的覆盖面越来越广,检索到相似案例的几率也随之提高。

图5 案例推理“5R”模型
从以上流程不难发现,传统的案例推理从案例库中检索得到的案例的解往往只是建议解[15],通常不能直接用到当前问题中。因此,必须对现有案例进行修正,然而案例修正也是案例推理的难点,人工修订和机器学习效果都不理想。本文在现有案例推理研究的基础上利用案例分解的思路提出了一种基于案例推理的“5R”模型,如图5 所示。改进后的“5R”模型在原有的流程基础上增加了案例分解Resolve 部分,将案例按照问题向量和解答向量划分,以提高检索的效率和修正的准确性,保证案例的高可用性。
案例库中每一个案例都可以向量化拆分成“问题向量”和“解答向量”,而每一个事件信息则是由“现象”、“原因”、“处置”3 个基本向量构成的向量集。在异常事件发生时需要用最短的时间处置恢复服务,此时往往只知道异常现象,原因未知,也可能现象、原因都已知。在这里系统可以将事件向量集的现象向量与原因向量合并,然后对新向量与案例库中案例的问题向量进行相似度计算,找出最相近的几个案例并将处置方案推荐给运维人员,辅助处置正在发生的异常事件。其中相似度公式可以采用常用的向量夹角余弦值[16]计算即可。
当运维人员接到故障报警后,“5R”模型会自动分析提交事件的标题,在案例库中查找统计,并通过相似度计算分析,将最可能贴近的处置方案推荐给支持人员,从而达到事中辅助决策的目的。新的问题与原有分解的案例组合并通过修正形成新的案例供后续学习,依次循环,不断提升案例库的丰富性和实用性,从而保证主动运维辅助决策机制的顺利运行。
2.4 4S 案例教学模式
日常的运维实践中,在处理突发事件或例行维护时形成的成功处置经验或者失误教训都可以形成经典案例供运维人员参考学习,但往往由于缺乏有效的共享机制,导致教学效果并不理想。本文在管理案例库建设“4S”模式的基础上探索出适合信息系统生产运维的“4S”案例教学模式,如图6 所示。此模式由4部分组成:研究团队、科学流程、质量标准和成果共享[17],即组织研究团队(Study Team),通过科学的流程(Scientific Processes),建设符合质量标准(Standard Qualities)的生产运维案例库,并实现成果共享(Sharing Productions)。

图6 案例教学“4S”模型
研究团队包括管理部门、建设工作小组、技术专家、案例撰写人员、维护和推广人员。管理部门负责制定案例管理的制度、规范,建立健全案例管理工作机制,统一组织、协调、指导生产运行案例管理工作。建设工作小组负责案例模板的编制,案例的初步审核及组织专家后续评审。技术专家负责案例内容的把关、技术指导及案例的评审。案例撰写人员主要指一线、二线运维人员及技术骨干,负责生产运维案例的撰写。推广和维护人员主要负责案例宣讲的组织及案例库的维护。
科学流程包括案例撰写、审核申报、受理评审和案例发布。一般在主动运维工作实施完毕和异常事件处置完毕后实施效果良好,处置得当,值得借鉴学习和共享,或者生产运行突发事件的现象或原因为首次发生或尚未纳入案例库的就可以开展案例撰写工作。案例撰写完毕提交案例建设工作小组进行审核与申报,相关的案例审核员对生产运行案例内容的准确性、完整性及合规性进行审核。审核通过的案例申报给技术专家进行受理评审,相关领域IT 专家对案例的适用性、可借鉴性等方面进行评审,并提出评审意见。审核通过的案例及专家评审通过的案例将纳入案例库统一管理,并通过在线案例平台进行发布。发布范围方面,审核通过的案例允许在部门内部发布,而由专家评审通过的案例则整个企业内部可见。
质量标准包括单个案例的标准和整个案例库的标准。对于单个案例要保证其真实性、目的性、深刻性、典型性和完整性。主动运维案例的内容应包括案例实施背景,案例实施方案、经验与收获以及案例有效期等;异常处置案例的内容应包括异常事件的异常现象、处置过程、原因分析、系统版本与架构等案例背景、相关处置或管理上存在的问题、改进措施以及案例有效期等。对于整个案例则要保证数量充足、类别齐全、及时更新和符合实际。数量充足以保证教学的需要,类别齐全以覆盖到所有运维领域,及时更新保证了案例的时效性可用性,符合实际保证了案例内容的合理高效。
案例成果共享通过3 个途径实现:案例汇编、案例宣讲和在线案例库。案例汇编是将生产运维经典案例汇编成书,分发给各类运维人员学习。案例宣讲是组织各个领域的IT 专家对本领域常见典型案例按年度进行现场授课交流。在线案例库是通过电子化工具平台建立共享机制,将案例信息在运维服务台展示发布,运维人员登录系统便可查阅各种案例信息,进行在线学习。通过以上3 种方式深入企业员工内部,实现案例的线上线下共享学习,使案例库的建设不再流于形式,真正实现运维案例应有的价值。
3 应用情况及效益
中国农业银行数据中心从2011 年开始启动主动运维案例库体系建设研究,整个体系在总分行层面得到推广应用。通过3 年多的实践,整个农行的生产运行质量和效率都较以前有较大改善,尤其是事件问题管理成效显著提升。相关指标包括同类事件占比(所有事件中,属于同一类型反复发生的事件占总数的比重)、事件按时响应率(按时响应的事件数量/事件总数)、事件按时解决率(按时解决的事件数量/事件总数),近3 年数据如表2 所示。从表中数据分析发现2011-2014 年上半年全行同类事件发生比率逐年降低,事件响应时间和处置时间都明显缩短。

表2 2011-2014 年上半年数据中心事件各项指标对比
在同类事件处置方面,以存储类故障为例,将近3 年的存储故障类事件按处置时间的长短进行统计分析如图7 所示。横轴代表时间段,竖轴表示事件处置时间落在不同时间段区间内的事件数占比。通过分析发现该类事件处置时间向左偏移并集中于T4 附近时间段内,即同类事件处置时间呈现缩短趋同趋势。

图7 存储故障类事件处置时间趋势图
另外,通过“4S”案例教学模式,在农银大学对全行科技人员展开集中培训。对涉及近年较典型的全行异常事件案例,以综合案例的全员宣讲和专业案例的分班培训的形式进行推广学习。“4S”教学模式的推广不仅提高了运维人员的技能,而且增加了大家互相交流沟通的机会。生产运行案例教学模式的建立,为特大型商业银行着力提升信息系统安全运行保障能力,做了良好的研究与探索。
4 结束语
本文提出了以事件和问题管理为核心的主动性生产运维案例管理理念,建立了生产运行事件事前主动防御、事中决策参考、事后经验共享的运行机制。通过主动运维案例体系在企业IT 运维部门的推广,同类事件发生比率降低,同类事件解决时间缩短趋同,事件响应时间和处置时间都明显缩短,同时运维人员的技能水平得到显著提高,提升了信息系统安全运行保障能力,生产运维服务质量大幅提升。另一方面,本文的相关研究也是对智能化运维领域的积极探索和尝试,对其他企业的信息系统运维案例库管理,运行风险主动防控具有很好的示范作用和借鉴意义,应用前景广阔。但值得注意的是,在案例生产方面,利用知识分层提取模型自动从异常事件库中抽取案例素材后采用的是分类归纳的方法得到最优案例,还不是严格意义上的案例自动化组装,教学案例大部分还依赖人工筛选整理。另外,基于案例的推理目前只是用于辅助决策参考,真正实现智能化决策还有待进一步研究。相信,随着科技的快速发展,运维自动化水平和智能化程度的不断提高,以上问题将会迎刃而解。
[1]谢新洲,夏晨曦.网络事件案例库建设与案例数据分析[J].情报学报,2012,31(1):72-81.
[2]杨健,赵秦怡.基于案例的推理技术研究进展及应用[J].计算机工程与设计,2008,29(3):710-712.
[3]王伟.基于粗糙集的Web 文本KNN 分类方法及在金融中的应用研究[D].重庆:西南大学,2013.
[4]李广川,刘善存,邱菀华.交易量持续期的模型选择:密度预测方法[J].中国管理科学,2008,16(1):131-141.
[5]张贤坤.基于案例推理的应急决策方法研究[D].天津:天津大学,2012.
[6]徐拥军,宋扬.管理案例库建设的“4S”模式研究[J].东北农业大学学报(社会科学版),2009,7(2):7-11.
[7]石国强.基于规则的组合分类器的研究[D].郑州:郑州大学,2010.
[8]唐明伟,卞艺杰,陶飞飞.基于领域本体的语义向量空间模型[J].情报学报,2011,30(9):951-955.
[9]陈亚峰,郭一帆,王峥.基于主题词语义分词与距离的去重算法[J].中国科技纵横,2014(15):28,30.
[10]朱靖波,王会珍,张希娟.面向文本分类的混淆类判别技术[J].软件学报,2008,19(3):630-639.
[11]韦相.基于密度的改进BIRCH 聚类算法[J].计算机工程与应用,2013,49(10):201-205.
[12]张玉鹏,王茜.基于数据驱动平滑检验的密度预测评估方法——以香港恒生指数、上证综指和台湾加权指数为例[J].中国管理科学,2014,22(3):130-140.
[13]杜家杰,段会川.混合值差度量在MDS 算法中的应用[J].计算机工程与应用,2011,47(34):152-154.
[14]王晋疆,陈阳,田庆国,等.一种基于点签名的散乱点云特征点检测方法[J].计算机工程,2014,40(7):174-178.
[15]董磊,任章,李清东.基于模型和案例推理的混合故障诊断方法[J].系统工程与电子技术,2012,34(11):2339-2343.
[16]黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.
[17]徐卫红.运用4S 模式建设地方文献数据库刍议——以天津市南开区图书馆为例[J].图书馆工作与研究,2010(5):91-95.
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
水上消防(2021年4期)2021-11-05
少先队活动(2021年2期)2021-03-29
内蒙古教育(2021年2期)2021-02-12
中国交通信息化(2019年5期)2019-08-30
中学生数理化(高中版.高二数学)(2019年6期)2019-06-24
能源(2018年8期)2018-09-21
能源(2017年11期)2017-12-13
韩国语教学与研究(2017年1期)2017-11-12
中国公路(2017年7期)2017-07-24
