
一种新的融合情景的美食推荐算法
2015-11-26 01:08赵雪美郭林锋卞雪雯
计算机与现代化 2015年7期
赵雪美,郭林锋,卞雪雯
(1.南京理工大学计算机科学与工程学院,江苏 南京 210094;2.上海理工大学环境与建筑学院,上海 200093)
0 引言
随着信息化的快速发展,餐饮业的发展也加快了脚步。利用信息化技术来提高餐饮业的发展成为研究的一个重要方向。人们的生活与美食有着最直接和紧密的联系,尤其是当前快速的生活节奏使得人们需要更加高效地选择合适的美食,缩短浪费在抉择过程中的时间。与此同时,餐饮企业为了吸引顾客,不断推出有特色的新美食,使美食的种类变得越来越多。顾客面对大量供选的美食,如何快速地选择自己最喜爱的美食成为当前亟待解决的问题之一。
推荐系统最主要的目标是找出最适合用户的资源项目,并将结果返回。其中,协同过滤算法是应用最广泛、最成功的推荐算法之一[1]。将推荐系统应用到餐饮企业,能够让用户快速地选择自己最喜爱的美食,对人们的生活有较大的帮助,但美食推荐比传统推荐更加复杂。首先,用户选择何种美食跟季节、时间等情景信息相关,不同的情景用户选择的美食套餐也大不相同。其次,推荐算法主要根据用户之前的反馈数据进行推荐,而直接获取到用户对美食的反馈数据通常比较难。最后,传统的推荐项目有较长的存在周期,而美食行业为了能吸引顾客一直不停地设计新套餐,使得美食套餐更新的速度非常快。由于这些问题的存在,使得美食推荐这种融合情景的推荐算法比传统的推荐算法更加复杂。因此,融合情景的推荐算法因其自身的特点,不能完全地套用传统的推荐算法。
为了解决上面所呈现的问题,本文设计一个融合情景信息的美食推荐算法(Favourite Meal,FMeal)。与传统推荐算法不同,首先,FMeal 将情景信息作为一个重要维度加入到原始的用户项目评分中,建立用户-项目-情景(User-Interest-Context,U-I-C)兴趣模型,其中情景是由情景的各个属性维度所组成的一个向量。根据情景对每个用户创建子用户与该情景对应,该用户-项目-情景模型进一步转化为将情景作为一个条件来研究的新用户-项目的评分矩阵模型,多维模型简化成二维模型,进而拥有传统二维评分矩阵模型简单有效的优点。针对创建子用户后存在的数据稀疏问题,本文还提出了有效的填充方法。此外,本算法重点考虑了用户在选择项目指标时的偏好相似性,对用户相似度公式进行了改进,从而根据改进相似度公式提出了FMeal 推荐算法。最后,通过实验验证该算法的有效性。
1 情景与兴趣模型的融合分析
将情景融入到兴趣模型中,主要采用2 种方法:
1)将所有情景属性维度作为新维度,并将新维度添加到兴趣模型中,如Yu Zhiwen 等人提出的方法[2];
2)将所有的情景属性维度整合成一个维度,并将该维度添加到兴趣模型中,如Wolfgang Woerndl 等人提出的方法[3]。
Yu zhiwen 等人在建立融合情景的推荐模型时,将情景分为用户偏好情景、周围环境情景和能力情景这3 大类。将每种情景下的属性作为完全独立的维度添加到模型中,进而提出通用的N ×M 维兴趣模型,形式化的表示如式(1):

这种方法比较直接,在数据比较丰富的情况下,对用户兴趣的预测质量较高。但是,这种方法使得模型的维度较高,容易造成数据稀疏,给相似度计算增加了难度。
另外,Wolfgang Woerndl 等人认为情景是动态的,不应该直接将所有的属性添加到兴趣模型中。该推荐模型不仅在评分矩阵中考虑了情景,而且能够降低模型的维度。但是,该模型需要用户在特定情景下的评分信息,使得系统容易产生冷启动问题。此外,该模型是根据位置相近和用户具有相似兴趣的原则来推荐的,运用该原则建立的推荐系统是不合理的。
2 融合情景的推荐算法FMeal
为了能给用户提供比较满意的服务,必须准确了解用户的兴趣。只有在充分了解了用户的兴趣之后,才能对即将要推荐的项目做出准确的解释,增加用户的依赖性。因此,推荐算法中的首要问题是合理地构建兴趣模型,并基于该兴趣模型设计高效的推荐算法。
2.1 情景兴趣模型
本文设计的融合情景U-I-C 兴趣模型,其中C 是指由多个属性维度组成的情景向量。该模型将情景向量作为一个维度添加到用户项目评分矩阵中。但是情景作为先决条件,将用户项目的评分矩阵作为实际的兴趣抽取模型。由于同一用户在不同情景下的消费行为一般是不同的,因此提出将每个用户按照情景重新创建多个子用户与情景一一对应,然后考虑在某一特定情景下对该情景下的子用户对项目的评分信息进行分析。注意,此时分析的兴趣模型已经转换成用户-项目(U-I)二维评分矩阵。
1)选择情景的属性。
本文所指的情景信息主要从用户消费项目的日期、时间、季节及同伴信息这4 个方面考虑,将其定义为如下向量:
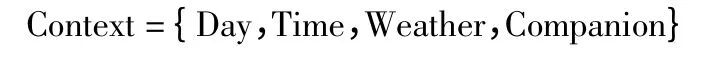
其中,Day 表示用户消费项目所处的日期,Time 表示用户所处的具体时间,Weather 表示所处的季节,Companion 表示同伴信息。
在实际应用中,不限于上述几种属性信息,根据影响选择项目的主要因素进行实际的选择即可。
2)创建子用户。
一般情况下,用户在不同情景下的偏好是不同的。根据各种不同情景下的用户行为,创建基于目标用户的多个子用户,并且每个子用户仅与一种情景相对应[4]。通过采用这种方法,分析每一种情景下用户-项目的评分矩阵,由此将模型的维度降低至二维。
假设当前分析的系统中共存在m 种情景,针对每一个用户Ui,并结合这m 种情景重新定义m 个新子用户Ui1,Ui2,…,Uim,其中每个新子用户Uij都与一种情景j 相对应。为了研究在某一特定情景j 下的推荐模型,仅与该情景j 相对应的子用户Uij的评分数据进行分析,进而使融入情景的多维模型转变为在某一特定情景下的U-I 二维模型。
更深一步地研究分析,如果用户Ui在情景Contexts、Contextg和Contextc下有相似的行为模式,那么将这些情景聚合标记为Contextout-L(1 <L <m),进而将该用户定义为一个新用户Ui-L,新用户Ui-L与聚合后的情景Contextout-L相对应,整体结构如图1 所示。由于在Contextout-L中不同情景下的用户Ui与用户Ui-L是等价的,所以采用这种方法可以减少重新创建新用户数。若一个用户在m 种情景下都有相似的行为模式,则可以减少创建m-1 个子用户。由此看出,若在不同情景下具有相似行为的用户数量较多时,采用该方法能够大大减少创建子用户数,大幅度降低计算的规模。

图1 不同情景下新产生的多个子用户
3)数据填充。
步骤2)说明了在创建子用户的过程中,如果不同情景下的同一用户的行为方式相似时,可以对这几种情景进行聚类,同时只创建一个子用户与该合成情景相对应。但是,在特定情景下的用户评分信息往往是很稀疏的,一种可行的解决方案是利用已有的数据预测填充未知的数据。
在文献[5]中,SlopeOne 算法是根据当前用户对其它项目的评分以及其他用户对当前项目的评分来预测用户对当前项目的评分信息。但是,该算法没有考虑相关项目的评分次数对预测结果的影响,致使评价次数较多的相关项目与评价很少的相关项目对当前项目的贡献值相同,这是不合理的。因此,本文将评价次数作为权值添加到原有的评分预测公式中(将该算法记为W-SlopeOne 算法),用于解决上述数据预测并进行填充的问题。
假设数据集为Γ,将用户u 对项目i,j 的评分分别记为ui,uj,用I(u)表示用户u 评过分的项目集合,同时用Fij(Γ)表示已对项目i 和j 评过分的用户集合,将用户集合中元素的个数记为num(Fij(Γ))。在已知所有用户u 对项目i 的评分ui,以及其他用户对项目j 的评分的条件下,预测uj的步骤如下:
Step1计算项目i 与j 之间的平均偏差devij,如公式(2):
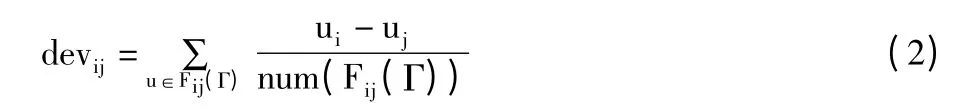
Step2求解与项目j 相关的项目集合Qj,如公式(3):

Step3计算考虑评价次数后的预测评分值,如公式(4):
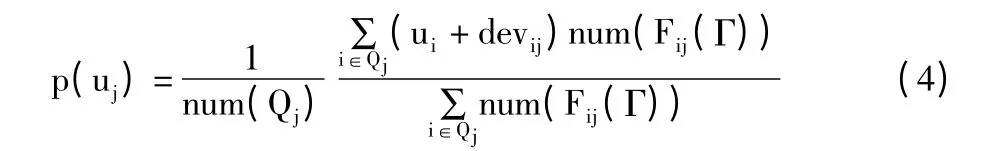
Step4用户u,对于项目i 的评分值如公式(5):

经过上述过程,可以预测几乎所有的未知评分。
4)情景聚类。
对于情景的聚类过程,本文采用经常应用于推荐系统的自组织映射网络技术。在自组织网络中,每一个输入向量对应一种特定的情景状态。输入向量的维数由项目的个数决定,若项目的个数为P,则输入的向量必须是一个P 维空间向量。该向量在各维上的数值是用户对各项目的评价得分值。具体的聚类过程见文献[6]。
5)兴趣模型的构建。
利用上述步骤产生新用户之后,就可以研究在某一特定情景下新用户的评分矩阵,即多维的评分模型,如公式(6);转化成二维的评分矩阵,如公式(7)。假设在某一情景C 下,用户U 对项目I 的效用函数定义如下所示:

其中,P(u,i,c)表示在情景c∈Context 时,u 对i 的偏好。
在当前情景C 下,传统的效用函数被重新定义如公式(8):

其中,U'为新用户数据集,I 为项目集合,Ratings'为新评价数据集。同样,对于标记为Contextout-L的新用户Ci-L,其对项目Ij的评价等级也可以采用聚合的方法得到,比如在进行聚合计算时可以使用简单的求和平均得到新的评价分值。
2.2 推荐算法FMeal
FMeal 算法是基于U-I-C 兴趣模型的用户近邻推荐算法,与传统基于用户的算法不同。本文算法在选择相邻用户时:1)根据模型输出矩阵,利用相似度公式计算出邻居用户;2)通过用户在选择项目时所关注的指标信息,找到对关注指标有相似偏好的用户。通过上述两者的加权组合计算更加准确的邻居用户。算法的详细流程如图2 所示。

图2 FMeal 推荐算法流程图
FMeal 算法主要分为6 个步骤:
1)根据U-I-C 兴趣模型训练新U-I 评分矩阵。
利用2.1 节介绍的兴趣模型构建方法构建U-I-C兴趣模型,推导出在特定情景下的新U-I 评分矩阵。
2)传统相似度计算。
利用传统相似度公式计算用户i 和j 之间的相似度如公式(9)[7]:

其中,Ric表示用户i 对项目c 的评分,Ri表示用户i对所有项目的评分均值,Iij表示用户i 和j 共同评分过的项目集合。
3)利用层次分析法计算用户在选择服务的关注点上的相似度计算。
如何判断在选择服务中所关注的指标是否相似。一般来说,用户对美食的选择会根据各种指标,如:口味、价格、销量等。针对当前存在的选择指标数目过多,用户对每个指标的偏好程度不同,不能直接判断用户之间的偏好相似度问题,本文利用层次分析法得到综合的评价得分。解决步骤如下:
1)构造由各指标组成的判断矩阵。值为比较两两指标之间的重要程度,参照表1 给出具体的值。表1 是1~9 标度表,巧妙地将感性思维进行量化表示,从而便于进行实际的计算[8]。

表1 1~9 标度表
2)计算判断矩阵¯A 的特征向量,该值为某一用户对所有指标的权值。
3)一致性检验。得到的特征向量为各属性的权值,为了说明权值的合理性,需要进行一致性检验。
具体的Matlab 实现算法如下:

4)加权相似度计算。根据用户-指标权重矩阵,利用相似度计算公式(9)得到指标关注偏好相似的用户。总的相似度计算如公式(10):

其中,i,j,k 分别表示用户、项目、指标。权重因子η为可变化的平衡因子。
根据上述相似度公式可对用户进行聚类,从而求解邻居用户簇。
5)对用户进行聚类。利用前面得到的新U-I 评分数据作为输入数据,结合相似度计算公式(10),对用户进行聚类。
6)预测评分并生成TOP-N 推荐。根据步骤5)产生的近邻用户块,利用公式(11)进行预测评分。

根据预测评分结果大小排序情况,产生TOP-K推荐项目。
3 实验结果分析
本实验采用的数据集包括在不同情景下,700 个有效用户对400 种食物进行评估数据。数据集是通过在网上做测试调查,邀请大量的真实用户进行评分收集到的。实验评估是在离线状态下进行,将收集的数据集的80%作为训练集、20%作为测试集。
构建的兴趣模型将用户和项目作为主要的维度,而日期、时间、天气和同伴作为情景维度。在测试过程中,本文仅考虑非空的情景记录。使用训练数据集作为输入,用真实数据进行预测,选择F1 和MAE 作为排序推荐的评估标准。
F1:衡量方法综合了Recall 和Precision 的结果。

MAE:平均绝对误差,MAE 越小,推荐质量越高。

其中,CountT 为所有用户的评分总数,ru,y为预测的评分值,为用户u 对项目y 的真实评分。
实验1 FMeal 与传统的没有考虑情景的推荐算法的效果比较。
FMeal 算法在对情景进行聚类的过程中,采用自组织映射网络的方法,因此,自组织网络的每个输入向量是一种情景状态,即输入向量个数是由各种情景属性所构成的情景类别的个数。将输入向量定义为一个p 维空间,p 为项目数量,向量的值为评分值。由于这种情景聚类的过程是对同一个用户进行的,因此情景聚类可看做是某一用户下的多维空间过滤聚类,这与传统的基于用户项目的二维空间聚类推荐是不同的。
下面对多维推荐算法FMeal 和传统的基于二维空间聚类推荐算法的效果进行比较。计算Average F1 的结果如图3 所示。

图3 2 种算法在选择不同TOP 值时的Average F1
融合情景的推荐算法在聚类块大小不同的情况下,与传统的不考虑情景的基于用户的推荐算法进行预测准确度比较,实验分析结果如图4 所示。
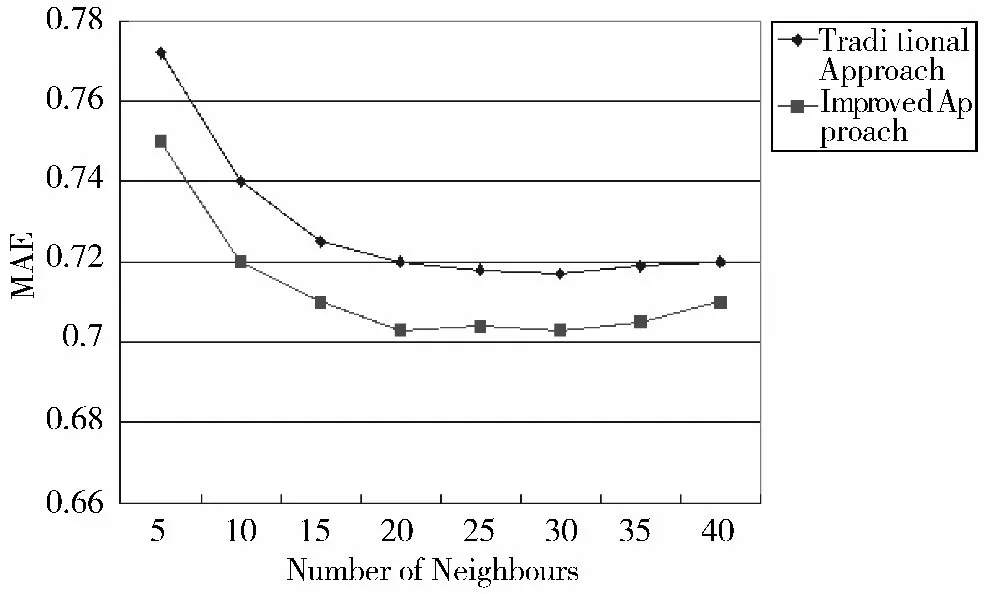
图4 不同邻居个数下2 种算法的MAE 比较
从图4 可以发现,改进后的融合情景推荐算法FMeal 的MAE 值更小,说明改进后的算法预测的准确度更高,推荐的效果更好。
实验2 对综合相似度公式中影响因子η 的取值效果分析。
由于η 值是衡量每种因素的权值,因此η 大小决定着是否对两者的偏重程度合理。为了找到最佳的组合效果,对该值大小进行调整,观察利用该综合相似度公式的预测值和准确值之间的偏差变化。分析结果如图5 所示。
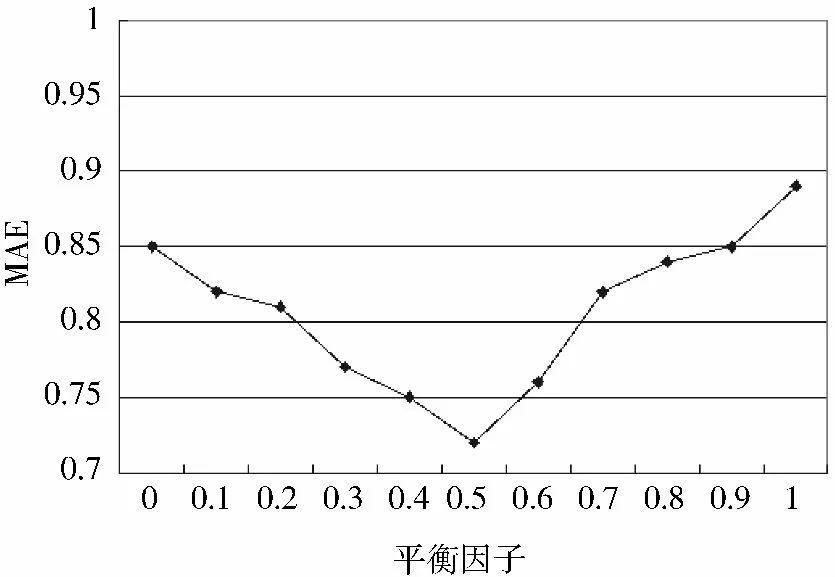
图5 平衡因子η 对MAE 的影响
从图5 可以发现,在η 值取0.5 时,MAE 的值最小,推荐的准确率最高。因此在算法中将η 值设定为0.5。
4 结束语
本文主要设计了一种融合情景的美食推荐算法。情景信息是用户使用项目时所处的环境信息,尤其在目前移动智能设备比较盛行的时代,情景信息和用户行为息息相关,某些方面甚至起到行为决策的作用。本文将情景信息融入到传统的用户评分数据中,提出了从高维向低维转换的方法,起到了传统协同过滤和移动性相结合的作用。除此之外,)本文提出的算法还考虑了用户在选择项目时,对某些指标的偏好程度不同,提出了指标权重的概念。将用户的指标权重相似性加入到传统的相似度计算公式中,进一步提高了邻居用户选择的质量。
[1]Linden G,Smith B,York J.Amazon.com recommendations:Item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[2]Yu Zhiwen,Zhou Xingshe,Zhang Daqing.An adaptive invehiele multimedia recommender for group users[C]//Proeeedings of the 2005 IEEE 61st Vehicular Technology Conference.2005,5:2800-2804.
[3]Wolfgang Woerndl,Christian Schueller,Rolf Wojtech.A hybrid recommender system for context-aware recommendations of mobile applications[C]// IEEE the 23rd International Conference on Data Engineering Workshop.2007:871-878.
[4]Maryam Hosseini-Pozveh,Mohamadali Nematbakhsh,Naser Movahhedinia.A multidimensional approach for contextaware recommendation in mobile commerce[J].International Journal of Computer Science and Information Security,2009,3(1):1-6.
[5]Li Jiyun,Feng Pengcheng,Lv Juntao.An improved slope one algorithm for collaborative filtering[C]// The 9th International Conference on Natural Computation(ICNC).2013:1118-1125.
[6]吴春旭,鲍满园,苟清龙.自组织映射聚类算法在电信客户细分中的应用[J].计算机系统应用,2010,19(8):168-172.
[7]尹航,常桂然,王兴伟.采用聚类算法优化的K 近邻协同过滤算法[J].小型微型计算机系统,2013,34(4):806-809.
[8]胡国祥,聂国平,伍振志.层次分析法在工程评标中的应用[J].安徽建筑,2003(4):110-112.
猜你喜欢
疯狂英语·初中天地(2022年2期)2022-07-07
劳动保护(2019年3期)2019-05-16
电子测试(2017年15期)2017-12-18
Coco薇(2017年6期)2017-06-24
小天使·一年级语数英综合(2017年3期)2017-04-25
雷达学报(2017年6期)2017-03-26
爆笑show(2015年10期)2015-11-18
小天使·一年级语数英综合(2015年8期)2015-07-06
电子设计工程(2015年6期)2015-02-27
爆笑show(2014年5期)2014-06-23
