
基于TMS320DM8168 平台的快速运动目标检测研究
2015-11-26 01:08谢红松董云飞
计算机与现代化 2015年7期
谢红松,董云飞,罗 斌,汤 进
(安徽大学计算机科学与技术学院,安徽 合肥 230601)
0 引言
当前是信息时代,信息的获得、加工、处理以及应用都在飞速发展。而视觉作为人类获取外界信息的主要载体,计算机要实现智能化,需能够处理视频图像;同时随着计算机技术与信息技术、计算机视觉、模式识别的突破性研究,视频智能检测越来越受到人们欢迎,但高清视频是未来发展的重点,也是难点[1]。传统的目标检测采用PC 机为服务器,所有算法在其上运行,对PC 机的硬件配置要求严格,且占用网络带宽高。但随着嵌入式处理器的广泛使用,其集成在前端相机上,对视频进行预处理并编码,不仅降低了网络带宽,更是大大降低了后台服务器的性能要求。另一方面,高清相机的技术不断发展,致使高清相机使用更加普遍,安全监控行业领域对视频的高清晰度和稳定性要求越来越高,D1 和CIF 格式已无法满足正常要求。
目前常用目标检测是利用目标运动的特性,并假定环境亮度变化由运动引起,常用的有帧差法[2]、高斯背景建模和光流法等[3]。帧差法简单快速,但信息量少,只适用于固定背景及其他应用限制;光流法通用,效果好,适应性强,但计算量大,很难达到实时。因此当前的运动检测视频分辨率都比较低。但由于视频分辨率不高,清晰度不够,导致某些细节信息丢失,特别是在安防、医疗等领域要求精度和效率高,无法满足正常要求,迫切需求高清视频。本文采用TI最新的处理器TMS320DM8168 为平台[4],实现高清视频下快速运动目标检测算法的移植及优化,满足当前社会各领域对高清视频处理的要求。
1 系统平台及框架介绍
1.1 系统平台
TMS320DM8168 平台采用TI 目前最新、性能最优越的达芬奇架构,是一款视频处理的片上系统,集成了型号为Cortex-A8 主频1.2 GHz 的ARM、C674x主频1 GHz 的浮点DSP、M3VPSS 和M3Video 的4 个处理器[5],其中ARM 运行Linux 操作系统,具有强大的控制能力,用于整个系统的调度以及各处理器之间的通信,同时扩展各种外围接口如网络、本地存储、IO等;DSP 运行BIOS[6]操作系统,运算快,计算能力强,用于本研究中核心检测算法的处理[7];M3VPSS 用于视频的采集、缩放、去噪、显示等;M3Video 用于视频编解码[8]。
该平台将各功能模块集成在一块芯片上,不仅降低了开发成本、设计复杂度和板级设计,也提高了系统的稳定性,满足应用的需求。
1.2 系统框架
为加快开发TMS320DM8168 平台上算法的移植及优化,TI 第三方提供了强大的MCFW 软件框架来实现芯片内多核之间的通信工作,并同时能支持16路高清视频的采集、传输、编解码和显示等。该多通道视频处理系统包括以下4 个子系统[9]:
1)视频捕获:将多通道视频数据捕获[10]并利用TVP5158 进行相应转码,同时对每帧数据进行相应预处理,包括缩放、去噪、旋转等。
2)视频显示:将解码或处理后的视频数据利用标准视频接口实时显示到显示器上,也可将多通道视频合并同时显示,实现多监控。
3)编解码[11]:为压缩视频存储容量,将视频进行编解码,然后存储到硬盘、SD 卡或实现网络视频流传输。
4)算法处理:即核心视频算法处理,将运动目标检测算法移植到DSP 上。
智能视觉运动目标检测系统一般包括视频采集[12]、视频处理、视频传输等模块。本研究中前端采集的视频像素是1664 ×1200,预处理后将视频流传输到DSP 中进行智能视频分析,分析处理后的视频编解码利用网络传输到后台或利用标准视频接口显示。
2 算法介绍
本文中采用快速运动目标检测算法ViBe[13],该方法相比于传统的背景建模,建立一个背景模型,每一帧图像与模板比较,利用一定策略,能很好地将图像中属于背景的像素点和属于前景的像素点分离。下面具体介绍该方法原理。
2.1 模型初始化
一幅图像的邻近像素之间是具有关联性的,一个像素点和它邻域内的像素点之间的距离往往很小。所以初始化过程是:先建立一个由N 幅图像组成的背景模型,然后将获取的第1 帧图像的每一个像素点(x,y)及其5 ×5 邻域内的像素点组成一个集合,随机从这个集合中取N 个值分别初始化背景模型中的每幅图像对应的像素点(x,y)。初始化过程如图1所示。

图1 初始化示意图
2.2 模型更新
随着时间的推移,实际场景下的背景很容易发生变化,如树叶的抖动。要想得到理想的检测效果,必须要对初始化后的背景模型进行更新。更新过程如图2 所示。
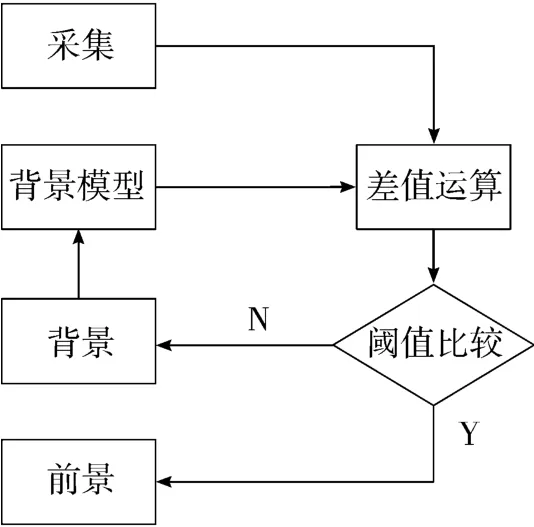
图2 运动目标检测流程图
3 算法移植
在MCFW 框架中,可采用TI 标准的算法接口,初始化中对DSP 的堆内存大小进行分配,设置内存的对齐和属性,CACHE 的配置和DMA 的初始化等。然后根据视频处理要求,连接各子系统的链接节点,节点之间按照ID 号和队列号一一对应[14],视频处理链框图如图3 所示。最后在DSP 的BIOS 中创建主任务,实现算法的循环执行,若有多个算法同时运行时,可使用CCStudio[15]创建多个任务,并指定任务的优先级、堆栈的大小等,创建成功会分配一个ID 号。另外根据算法的需求,设置整个DDR3 的存储空间划分,包括DSP 的数据存储区、程序存储区、ARM 系统Linux 内核运行区等,其中DSP 的数据存储区要大于算法分配的大小,否则内存分配出错。

图3 视频处理链
4 算法优化
4.1 使用编译选项
在编译选项中添加-O2 或-O3[16],能大大提高代码的优化程度,提高算法效率,实验中分别对添加优化选项和不加优化选项进行比较,两者运行时间会有几倍甚至十几倍的差距,另外-O3 的效果比-O2的效果更好,优化程度更深。
4.2 使用restrict 关键字
为最大程度地提高代码效率,编译器会安排指令并行执行。在TMS320DM8168 中,最大支持8 条指令并行执行,但由于数据的相关性,某些无法并行执行,很难充分使用。数据存储单元相关性优化就是最大限度地降低数据相关性,从而达到算法并行优化的效果。
本研究中ViBe 快速检测算法的模型更新为:


另外,定义中也可以使用关键字const,效果等同restrict。
4.3 循环优化
在TMS320DM8168 中,集成了流水线SPLOOP 机制,大大降低多周期指令延时的影响,可深层次提高算法效率。但使用过程中发现Loop Buffer 最多只可存储14 个执行包,而ViBe 的更新指令超过Buffer 的最大存储空间,则无法使用SPLOOP 进行优化。
在ViBe 更新算法中,处理一帧图像的每个像素时,可考虑以下方法:
优化时,可将二层循环改成单循环,同时指定循环次数,即采用:

该指令表明该循环最少执行HEIGHT* WIDTH,最多执行HEIGHT* WIDTH,另外该指令还可添加第3 个参数,为循环次数的整数倍。
实验过程中,添加该指令并结合循环优化以及restrict 关键字,算法时间降低60 ms。
4.4 内联函数优化
在取每一帧图像的像素点时,若一次取一个像素点,则对于1 080P 视频,每一帧需要取200 万次,由于每个像素点的值都是1 个字节,可采用内联函数[17]_amem4_const(input),其中input 为图像数据的首地址,_amem4_const()可一次性连续取4 个像素点的值。
ViBe 算法中,在判断前景背景时,需将每一帧像素的值与样本值比较,可采用_subabs4(value,* sample),其中* sample 为样本值,value 为当前帧的像素,_subabs4()对int 型的4 个字节分别做差取绝对值,每一指令周期可同时实现4 个数字差值。
在ViBe 算法中,样本数为20 个,将差值与阈值比较,对于1 080P 视频,需比较20 ×200 万次,耗时长,可考虑对比较进行优化,采用_cmpgtu4(R,value_t),其中R 为固定阈值,根据不同的情况可预先确定,value_t 为前面的差值。_cmpgtu4()对int 型的4 个字节数据分别做比较,返回结果为int 型的低4 位,若大于阈值,则相应的为0,否则为1,实现一条指令进行4 次比较。
实验过程中,使用内联函数,算法时间降低40 ms。
4.5 内存对齐
在DSP 中做数据读写时,要考虑数据的对齐方式,根据需要可将其设为2 字节、4 字节、8 字节对齐。另外,在前面使用的读写数据的内联函数时也必须要保证读写的缓冲区是4 字节对齐的。因此,在使用时,可按以下步骤设置内存对齐。
Step1开辟对齐内存。
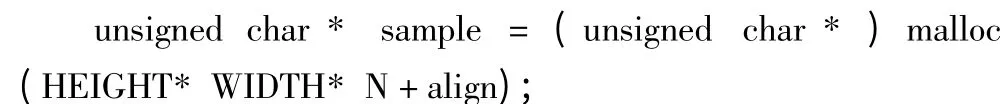
其中HEIGHT* WIDTH* N 为开辟内存的大小,且为unsigned char 类型,align 为偏移量,将缓冲区地址和(~0x03)做与运算即可保证4 字节对齐。也可采用TI 标准的算法接口开辟存储空间。
Step2内存对齐判断。
在读写数据前,需判断内存是否对齐,可采用_nassert(((int)(sample)&0x03)==0),其中sample为读取地址的缓冲区,将其与0x03 做求与运算,若为0,则表明该地址为4 字节对齐。
4.6 使用EDMA
在TMS320DM8168 中有增强的EDMA3,包含64个DMA[18]通道,用户可以根据需要选择通道号。该EDMA3 分为3 种传输类型,分别为一维、二维和三维。一维用于传输一段连续的内存,且最大为64 k;二维可以用于传输非连续内存,且可设置其偏移量,最大为64 k×64 k;三维也可用于传输非连续内存,且设置每一维的偏移量,最大为64 k×64 k×64 k。
使用时需设置源地址、目的地址、传输数据大小,对于二维和三维传输类型,需设置偏移量,同时保证CacheEnable。EDMA_2D_Transfer(chan_num,seg-Mat,input,WIDTH,HEIGHT,0,0);其中chan_num为DMA 通道号,segMat 为源地址,input 为目的地址,WIDTH×HEIGHT 为数据大小,0、0 分别为源地址和目的地址的偏移量。实验中,对于内存拷贝,memcpy(input,segMat,HEIGHT* WIDTH)需耗时10 ms 左右,若采用DMA 实现,耗时几乎可以忽略,大大提高算法性能。
4.7 DSP 超频
TMS320DM8168 平台的型号为C674x 的DSP 最高频率可达1.2 GHz,而目前平台DSP 的主频为800 M 左右,因此可将主频升为1 GHz,使算法在效率上有很大的提升。另外,升频过程中需考虑功耗以及芯片发热量,必要时添加相应的散热装置。
5 实验结果
本研究中前端采用高清1 080P 视频,分辨率为1664 ×1200,在未进行优化时,ViBe 检测算法帧率为5~6 帧,效率差。各种优化方案降低算法的时间和提高的帧率如表1 所示。

表1 优化效果
最终在TMS320DM8168 平台上,实现高清视频的快速运动目标检测,帧率达15~16 帧。
运动目标检测结果如图4 所示。

图4 运动目标检测
6 结束语
本文主要介绍了 TI 最新的达芬奇平台TMS320DM8168 以及开发框架MCFW,并将运动目标检测ViBe 算法移植到DSP 中,实现跨平台运行,同时为提高算法性能进行深层次优化,实现高清1 080P视频的快速运动目标检测,经测试,性能稳定,效率高,可应用于各种工业、医疗领域,具有广阔的应用前景和市场价值。
[1]黄兴.采用DM3730 的高清视频采集与处理系统研究[D].苏州:苏州大学,2013.
[2]刘红,周晓美,张震.一种改进的三帧差分运动目标检测[J].安徽大学学报(自然科学版),2014,38(6):55-59.
[3]江晟.混合交通视频检测关键技术研究[D].长春:吉林大学,2013.
[4]施朝辉.基于DM8168 的列车多媒体播放平台的设计与实现[D].大连:大连理工大学,2013.
[5]Texas Instruments Incorporated.TMS320DM816x DaVinci Video Processors[EB/OL].http://www.ti.com/lit/ds/symlink/tms320dm8168.pdf,2011-10-11.
[6]杨盛武.基于TMS320C64xx DSP 的实时调度平台[J].计算机与现代化,2006(3):110-112.
[7]杨振永,王延杰,孙海江,等.基于TMS320DM8168 的SOC 高清视频处理系统的设计与实现[J].液晶与显示,2013,28(5):764-769.
[8]贾文全,李勇,王军辉.基于TMS320DM8168 硬件平台的智能网络视频监控系统[J].计算机与数字工程,2012,40(9):60-62.
[9]李晓波,孟利民.H.264 多媒体数据在嵌入式系统中的存储机制的设计[J].浙江工业大学学报,2012,40(4):437-440.
[10]唐人财,刘连浩.基于嵌入式Linux 远程图像监控系统的设计[J].计算机与现代化,2010(11):31-34.
[11]李晓辉,胡艳军,翟宗起.视频编码控制策略的研究与实现[J].安徽大学学报(自然科学版),2001,25(1):57-61.
[12]袁新娣,李秋生.基于RT5350 的嵌入式无线视频数据采集系统[J].安徽大学学报(自然科学版),2014,38(6):60-65.
[13]Barnich O,Van Droogenbroeck M,Evs B E,et al.ViBe:A universal background subtraction algorithm for video sequences[J].IEEE Transactions on Image Processing,2011,20(6):1709-1724.
[14]胡志权.基于TMS320DM8168 宽景视频监控系统[D].成都:西南交通大学,2014.
[15]杨珂瑶,张小芳,曾雷杰.基于DSP 的嵌入式软件测试方法[J].计算机与现代化,2014(10):61-65.
[16]朱海.基于DM8168 的视频监控系统的实现[D].成都:电子科技大学,2013.
[17]祝中科.基于DM6467 的车辆轮对磨耗检测算法的优化实现[D].杭州:杭州电子科技大学,2014.
[18]沈克沪.H.264 模式选择新算法研究及其DSP 优化[D].上海:上海师范大学,2009.
猜你喜欢
军事文摘(2022年24期)2022-12-30
销售与市场(营销版)(2021年10期)2021-11-21
现代电子技术(2021年1期)2021-01-17
销售与市场(营销版)(2019年6期)2019-06-21
家庭影院技术(2019年4期)2019-04-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
网络安全技术与应用(2017年9期)2017-09-20
自动化学报(2017年11期)2017-04-04
新媒体研究(2015年7期)2015-12-19
