
改进Apriori算法对试车台监测数据的关联挖掘
2015-11-15 07:35:18刘自然王律强李爱民张跃春颜丙生甄守乐
中国测试 2015年4期
刘自然,王律强,李爱民,张跃春,颜丙生,甄守乐,熊 伟
(1.河南工业大学机电工程学院,河南 郑州 450007;2.河南工业大学工程训练中心,河南 郑州 450007;3.中航工业湖南南方宇航高精传动有限公司,湖南 株洲 412002)
0 引 言
航空发动机传动附件作为航空发动机的关键部件,在装机前需采用试车监视系统进行试验,试车过程中得到的数据存储在传动附件试车台监测软件中。然而,这些数据只用于一般的查询或统计处理,没有进行深刻的分析理解;如何从这些数据中找出(或发现)对试车工作有指导意义的规则(或知识)非常有工程应用价值。将关联规则技术应用于航空发动机传动附件的试车监测数据挖掘[1]中,可以有效地发现航空发动机传动附件各变量间的关联规则,监测试车台状态的变化,以便更好地管理试车台。针对原有Apriori算法对数据集扫描次数过多,产生候选集多导致效率不高的问题,提出了一种改进的Apriori算法,并应用于某试车台监测数据的关联规则挖掘中。
1 关联规则技术的原理及方法
假设 I={i1,i2,…,im}是 m 项的集合,即数据库中属性的集合。事务 t也是项的集合,即 ti⊂I,i=1,2,3,…,m。T 为事务的集合,即 T={t1,t2,…,tm},ti⊂I。设 X是一个项集,其中含有k个项的项集称之为k-项集。当且仅当X⊆Ii时,事务ti包含X。事务集T中项集X的支持度Sup(X)是集合T中包含X的事务的频率,即 Sup(X)=P(X)。若 Sup(X)≥min-sup,其中min-sup是给定的最小支持度,则称X为频繁项集[2]。设Y是I中另一个项集,则关联规则就是形如X⇒Y的表达式,其中X⊆I,Y⊆I,并且X∩Y=Φ。关联规则X⇒Y在事务集T中的置信度conf(X⇒Y)是T中同时包括X和Y的事务的频率,即conf(X⇒Y)=P(Y|X)。
因此,关联规则挖掘可以分以下两步完成:
1)通过事先设定的min-sup,找出所有的频繁项集,即找出支持度大于或等于给定的最小支持度阈值的所有项集,从而递归查找1到k的频繁项集。
2)由频繁项集产生强关联规则,即找到满足最小支持度(min-sup)和最小置信度(min-conf)的关联规则。步骤2)实现简单,关联规则挖掘算法的性能主要集中在步骤1)上,大多数算法都集中在怎样高效发现频繁项集[2-3]。
在众多的现成关联规则挖掘算法中,由R.AGRAWAL等首先提出的Apriori算法是一种有效的频繁项集挖掘算法,之后的算法基本是在其基础上的改进。该算法是利用递归迭代方法来完成频繁项集的挖掘工作,即利用k-项集来生成(k+l)-项集,用候选项集Ck找频繁项集Lk。首先,找到频繁1-项集的集合,记作L1。然后用Ll去找频繁2-项集的集合L2,得到的L2用于找L3,如此递归,直到k足够大以至不能找到频繁k-项集。找到每个Lk需要进行一次数据库扫描。从事务集T中找出频繁项集后,再根据最小置信度直接产生强关联规则。经典Apriori算法的缺陷[4]是:可能需要产生大量的候选项集和重复地扫描数据库,需要检查一个很大的候选集合。
2 Apriori算法的改进
2.1 Apriori算法改进思路
提高经典Apriori算法的效率,关键在于减少候选集的产生。基于这种思路,提出了减少事务的改进Apriori算法,其目标是减少用于未来扫描的事务集的大小。改进算法的基本原理是不包含任何k-项集的事务不可能包含任何(k+1)-项集,因而在产生j-项集(j>k)时,可以不再扫描这些事务。这样,其后在考察这种事务时,可以直接删除。
改进的 Apriori算法思路是:首先,对数据库进行一次全面扫描,确定记录数量并对记录进行排序,然后在生成候选集C1的同时,删除事务集中不支持L1的事务以及事务中的项目;第3步是对数据库中项目集进行二进制编码,编码的长度为记录数量,项目在事务集的某个记录中出现时用“1”表示,没有出现时则用“0”表示;第4步是将得到的编码表进行转置,生成关于项集编码的表格,并对关于项集Ii编码中“1”的个数进行累加计数,由给定的最小支持度与“1”的计数进行比较,若count(1)≥min-sup,则得到的为频繁1-项集;第5步是将频繁(k-1)-项集中的项编码进行“与”运算。在产生的新编码中统计“1”的个数,如果count(1)≥min-sup,则产生频繁k-项集。最后重复第5步,直到找到需要的频繁项集L。
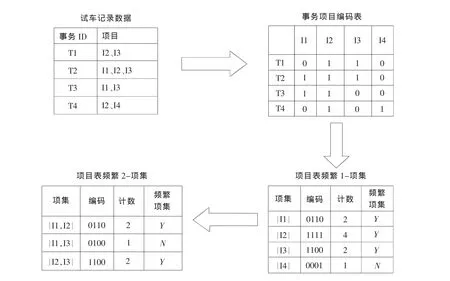
图1 改进Apriori算法举例示意图
2.2 改进后的Apriori算法举例
为更好说明改进算法的工作过程,以4个项集,4个事务为集合进行关联规则挖掘说明。假定最小支持度为2,根据改进后的Apriori算法,具体的过程如图1所示。首先扫描数据库,对事务集中的项目进行编码,由事务项目编码表在垂直方向的项转置成项集一个二维表,表中的编码是项在事务表中每条记录中是否出现的编码序列,“1”代表出现,“0”代表不出现。根据项目表计算频繁1-项集,统计编码中“1”的个数,由于I4的编码计数为1,小于最小支持度2,所以进行项目压缩,删除项目I4,由频繁1-项集的项目编码进行与运算,最终得到频繁2-项集。
从上述分析可以看出,改进的算法在第1步扫描数据库并对每个项目编码,后续的过程都是针对编码进行“与”运算,不需要对数据库进行重复扫描。同时由于删除了小于最小支持度的项以及含有该项目的事务,可以有效地减小系统的开销,从而提高挖掘效率。
3 监测数据关联规则的数据挖掘
在试车台监测系统中,考虑成本和可行性,分为两大系统:以Wincc为平台组建的监测压力、流量、温度等低频参变量的监控系统和以LabVIEW为平台搭建的测量振幅的振动测试系统。两套系统在物理上相互独立,其隐藏的参量关联必须通过关联规则进行挖掘。同时,因为LabVIEW和Wincc自身并没有自带数据挖掘功能,必须将其所存储的数据进行转换,亦即数据预处理,才能在统一的专业挖掘软件进行挖掘。图2为用改进的Apriori算法挖掘监测系统关联规则的技术路线图。在某试车台试验过程中采集到一周左右的压力、流量、温度等参量记录,原始数据形式如表1所示。

图2 关联规则挖掘技术路线图

表1 试车台系统监测记录
3.1 数据选择和属性编码
考虑到数据挖掘时样本规模及计算机的计算能力,没有必要将监测得到的所有数据都用于挖掘,有些数据对象和数据属性对建立模型的作用可能是重复的,这些数据的引入对挖掘效率会产生较大的影响,甚至还可能导致挖掘结果的偏差。因此,选择有效的数据很有必要。数据选择包括属性选择和数据抽样。由于传动附件试车台系统中振动系统自成一体,振动这一属性必须予以考虑。在监控系统中,齿轮箱出口压力与油箱压力基本一致,若将其考虑进来,得到的关联规则基本是与这个参量相关的强规则,导致较大偏差,应该予以删除。而电机功率以及输出转速是通过输入转速、传动比、扭矩计算出来的,本身就存在函数关系,在挖掘时,不予考虑。基于此,最终选择了试车数据压力、流量等28个对挖掘有用的参数进行挖掘。参照文献[5]对各个属性进行编码,如表2所示。

表2 属性编码表

表3 转换后的事务数据片段表
3.2 空缺值处理
试车过程中数据也不总是完整的,有时在某些记录的属性上可能出现空缺值。在数据的采集过程中,无论传感器还是采集系统某个部分的故障均有可能导致空缺值的出现。对于空缺值的处理比较简单,可以采取忽略、人工填写空缺值、使用属性的平均值填充等方法[6]进行处理。由于试车过程中,温度是缓变的,若温度出现空缺值,使用人工填写较为合适。对于像振幅这样的高频参量,可以使用振幅的平均值来补充空缺值。
3.3 数据离散化
挖掘关联规则的关键在于将连续型数值合理离散化,然后将其转化为布尔关联规则进行处理,常见的属性离散化方法有等宽离散法、等频离散法、基于距离划分法[7]。从监控系统中导出的如流量、压力、温度等由于是缓变信号,可以采用等宽离散法进行离散。而对于从振动系统中导出的振幅数据,则采用等频离散法[8]更为合适。经数据预处理后的数据,形成以振幅、温度、流量、压力等为项目集的事务数据集,如表3所示。将所得到的事务数据集项目根据改进后的Apriori算法进行编码,分别用yes和no来表示相应代号出现、不出现,这样初步完成数据的预处理。

表4 监测数据挖掘产生的部分关联规则
3.4 改进算法的关联规则挖掘
采用Weka3.7.0分别运行原Apriori算法及改进的Apriori算法,选用试车台一周左右的试车数据。经反复试验并参考文献[9]设置两种算法,设置关联规则的支持度均为0.8,置信度均为0.9,得到了按置信度排序的前30条规则,选取部分有效的关联规则,如表4所示。
在系统中,增压出口1温度与增压出口1流量有较高的关联性,置信度为100%。振动幅值与增压出口有一定的负相关性,振动值低的时候温度反而高,由此可见增压出口1温度在后续的试车过程中应予以重视。齿轮箱入口压力与温度关联度很高,置信度为100%,在试车台子系统齿轮箱润滑系统中,这两个参数在再次试车时也应重点关注。
用改进的算法进行挖掘,得到的规则支持度与置信度相同,但运行时间减少,改进前后所运行的时间如表5所示。可以看出,支持度小时,两者相差的时间较大;支持度大时,两者相差的时间较少。这是因为支持度小的时候,产生的候选集多,而改进的算法使候选集减少最终减少了运行的时间。由于两种算法的支持度和置信度均一样,可以看出改进后的算法降低了运算时间,节约了系统开销。
4 结束语
针对某试车台监测系统监测数据进行了关联规则的挖掘,引进Apriori算法,得到具有单独特征量监测不到的规则,这些规则为后续的安全试车提供了重要参考。提出了Apriori改进算法,用采集的数据进行实验,采用相同的支持度和置信度,挖掘结果表明,改进的算法可以减少候选集从而降低运算时间。

表5 改进算法与改进算法运算时间比较
[1]彭兴慧.WS9发动机试车数据库数据挖掘技术研究[D].西安:西北工业大学,2005.
[2]陈文庆,许棠.关联规则挖掘Apriori算法的改进与实现[J].微机发展,2005,15(8):155-157.
[3]高海洋,沈强,张轩溢,等.一种基于数据压缩的Apriori算法[J].计算机工程与应用,2013,49(14):117-120.
[4]龙冰莹,陈小惠.改进Apriori算法在医院监护中心的研究与应用[J].计算机技术与发展,2013,23(8):137-140.
[5]Kusiak A,Verma A.A data-mining approach to monitoring wind turbines[J].IEEE Transactions on sustainable energy,2012,3(1):150-157.
[6]李峰,姜丽莉.关联规则挖掘在煤矿安全监测中应用[J].软件,2011,32(2):85-86.
[7]龚舒.桥吊动态性能参数的统计特征分析及关联规则挖掘[D].上海:上海海事大学,2005.
[8]王志欣.岸桥机械动态特征信息的数据挖掘与状态识别[D].上海:上海交通大学,2008.
[9]李瑶,陈佳,陈罗峰.改进的Apriori算法在服装营销中的知识发现研究[J].信息技术,2013(3):100-104.
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
铁路通信信号工程技术(2019年6期)2019-01-17 18:56:14
计算机应用(2018年5期)2018-07-25 07:41:26
经营者·汽车商业评论(2016年12期)2017-03-08 02:31:39
太空探索(2016年9期)2016-07-12 09:59:51
轴承(2015年2期)2015-07-25 03:51:04
发明与创新(2015年37期)2015-02-27 10:40:26
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电讯技术(2011年11期)2011-04-02 14:00:37
