
结合GSC与相干滤波器的二元麦克风阵列语音增强算法①
2015-10-19 07:17张正文汤敏慎
湖北大学学报(自然科学版) 2015年2期
张正文,汤敏慎
(湖北工业大学电气与电子工程学院,湖北武汉 430068)
0 引言
随着通信系统对目标信号质量的要求越来越高,语音增强变得越来越重要[1].相较于传统的语音增强技术,麦克风阵列语音增强技术可以获更高质量的目标语音输出.但消噪能力往往依赖于麦克风阵列的阵元数.在设备小型化的发展趋势下,电子设备的体积、运算能力和成本受到严格的限制.二元麦克风阵列以其结构紧凑、符合设备小型化的趋势被广泛应用于免提系统[2]、助听器[3]以及耳蜗植入系统中[4-5].
在诸多二元阵列增强算法中,广义旁瓣相消器(generalized sidelobe canceller,GSC)和相干滤波器(coherent filter)是较为常用的算法.GSC算法依靠阵元间语音的时域和空域信息抑制噪声干扰,相干滤波器则利用信号的语谱和相关性对噪声进行抑制,但均未充分利用阵元间的信息.而二元麦克风阵列阵元数少、空间区分度小.要取得更好的语音增强效果,有赖于充分的利用阵元间蕴含的信息.
本文中提出一种基于相干滤波器与广义旁瓣相消器结合的二元麦克风阵列语音增强算法.与经典的结合方式[6-7]不同,该算法没有将相干滤波器放在广义旁瓣相消器的非自适应支路中,而是将相干滤波器作为广义旁瓣相消器的后置滤波器.这有两个好处,第一突破了传统结合模式[6-7]下只能使用消噪能力较弱的经典相干滤波器的限制,算法对基于迭代噪声谱估计的相干滤波器[1]进行改进,使之与广义旁瓣相消器联合消噪,第二既利用了阵元间信号相关性和语谱信息进行噪音抑制,也充分利用了阵列空域和时域信息进行噪音抑制,最大限度地滤除噪声干扰.仿真实验表明,该算法对各类噪声有良好的抑制能力.
1 算法描述
图1为GSC与相干滤波器结合算法原理图,假设目标信号由00角入射,则图1中两个麦克风接收到的信号可表示为:
其中s(n)表示声源信号,h1(n)和h2(n)表示声源到两个麦克风间之间的冲击响应,v1(n)和v2(n)为两个麦克风接收到环境噪声.由图1可知,算法整体结构由4部分组成,分别是固定波束形成器(fixed beam former,FBF)、阻塞矩阵(blockingmatrix,BM)、自适应干扰抵消器(adaptive interference canceler,AIC)以及相干滤波器.同广义旁瓣相消器算法结构相比,改进的算法多了一个相干滤波处理.带噪语音信号经广义旁瓣相消器增强后被送入相干滤波器,实现语音的再次增强,最终获取目标信号的估计值s'(n).

图1 GSC与相干滤波器结合算法原理图
1.1 广义旁瓣相消器算法原理广义旁瓣相消器(GSC)由图1中的固定波束形成器(fixed beam former,FBF)、阻塞矩阵(blockingmatrix,BM)以及自适应干扰抵消器(adaptive interference canceler,AIC)组成.
固定波束形成一般采用延时求和算法,由于算法描述中假设目标信号由00角入射,两个麦克风之间的目标语音保持同步,所以只需进行加权求和便可完成波束形成.加权求和后的信号为:
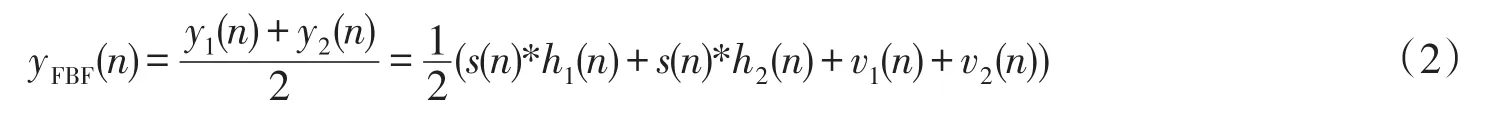
由于两个麦克风相聚很近,故两者间冲击响应的差距可以忽略不计,上式可以简化为:
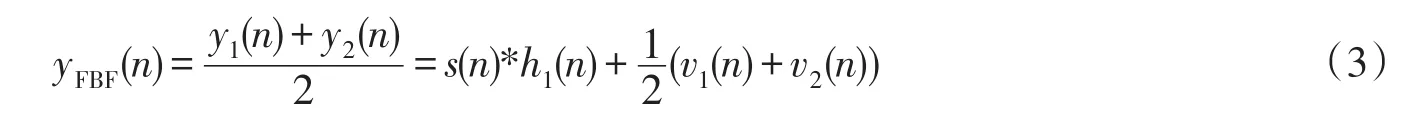
同时阻塞矩阵定义如下:

由此可以得出一个不含目标语音的噪声参考通道:

自适应噪声干扰抵消器在此选用变步长NLMS算法[8],利用噪声参考信号vBM(n)估计出yFBF(n)中的相关噪声信号v'(n),其原理图(图2)及迭代公式如下:

公式(7)中ε为远小于1的正数,以防止归一化值过小,μ(n)为步长变换因子,具体迭代步骤详见文献[8].
1.2改进的相干滤波器设计对GSC输出信号yGSC(n)做短时傅立叶变换得其频域形式:

其中ω表示频率因子,k表示帧号.由此可以得出相干滤波器的传递函数:


图2 自适应噪声干扰抵消器算法原理图
公式(9)中ФYGSC(ω,k)、ФS(ω,k)、ФV(ω,k)分别是带噪语音yGSC(n)、目标语音s(n)以及残余噪声v(n)的功率
谱密度,Rprio(ω,k)表示先验信噪比:

由此可知求出噪声的功率谱密度ФV(ω,k),这是相干滤波器设计的关键.经典的噪声谱估计方法是在基于语音活性判决(voice activity detectors,VAD)基础上[9],仅通过语音的无声段对噪声功率谱进行估计,仅适用于信噪比较高的平稳噪声环境.因为在低信噪比环境下,VAD的准确率较低,仅在无声段估计噪声,因此在非平稳噪声环境下性能会急剧恶化.本文中提出一种单通道噪声谱迭代估计算法,其迭代估计分为两步,第一步通过前一帧相干滤波器传递函数估计出本帧的噪声谱,第二步根据第一步求出的噪声谱计算出本帧的相干滤波器传递函数.
算法迭代过程如下:
1:第一帧.

2 仿真实验
以下3个仿真实验中,采样率为8 kHz,窗函数采用hamming窗,每帧长度为32ms,帧移为50%.麦克风阵列放置于长6m、宽4m、高3m的房间里,RT60=0.4 s,混响仿真环境通过基于Allen和Berkley的图像算法[10]的Habets算法实现.两个麦克风的距离为6 cm,坐标分别位于(2∶1∶1)和(2.00∶1.06∶1.00),目标声源位于(3.00∶1.03∶1.70),噪声源位于(10∶20∶1.5),目标语音为中国科学院的测试语音库,噪声来自于noisex-92 数据库.选取 GSC-wiener[7]以及phase-based[11]算法作为对比算法 .
仿真实验1从语音的时域及频域的角度检验算法的消噪能力.图3为背景噪声为white、SNR=0 dB、RT60=0.4s环境下3类算法处理前后时频图.从图3的时域图中可以看出,本文中算法增强后的语音残余噪声更少,语音信号波形保持的更完整.从图3的语谱图中可以看出,本文中算法增强后的信号在高频段保留了更多信息,对信号信噪比的提升更高.在上述仿真条件下,本文中提出的算法对噪声有更强的抑制能力.

图3 背景噪声为white、SNR=0 dB、RT60=0.4 s环境下3类算法处理前后的时频图
仿真实验2在不同信噪比下验证算法的消噪能力,处理结果如图4所示,由图4可知本文中算法对噪声能量的变换不敏感,各种信噪比下的噪声抑制能力明显强于对比算法.

图4 不同信噪比环境下处理结果比较图
仿真实验3使用babble、飞机引擎声、高频噪声、音乐噪声、轮机噪声、leopard构造不同的噪声场环境.选取 phase-based[11]算法、GSC-wiener[7]算法以及本文中算法在上述6种不同的噪声环境下进行消噪对比实验,信噪比与PESQ的测试结果如表1所示.从表1可以看出,无论在哪种噪声场下,本文中提出的算法对信噪比的提升及语音听觉质量的提升,都取得了更好的测试结果.

表1 不同类型背景噪声环境下信噪比和PESQ测试结果
3 结论
本文中以麦克风小阵列为基础,提出一种基于相干滤波器与广义旁瓣相消器结合的二元麦克风阵列语音增强算法.利用基于迭代的单通道相干滤波器作为广义旁瓣相消器的后置滤波器,进一步滤除残余噪声.两者的结合,既充分利用了阵元蕴含的信息,又实现了算法的优势互补.仿真实验表明,本文中的算法对噪声的类型与能量并不敏感,在6种不同的噪声环境中或低信噪比(0dB以下)的情况下,都能获得比较理想的增强效果.
[1]Rahmani M,Akbari A,Ayad B.An iterative noise cross-PSD estimation for two-microphone speech enhancement[J].Applied Acoustics,2009,70(3):514-521.
[2]Thumchirdchupong H,Tangsangiumvisai N.A two-microphone noise reduction scheme for hands-free telephony in a car environment[C].Electrical Engineering/Electronics,Computer,Telecommunications and Information Technology(ECTICON),Krabi,2013:1-6.
[3]Yousefian N,Loizou PC,Hansen JH L.A coherence-based noise reduction algorithm for binaural hearing aids[J].Speech Communication,2014,58:101-110.
[4]Kallel F,Ghorbel M,Frikha M,etal.A noise cross PSD estimator based on improved minimum statistics method for two microphone speech enhancement dedicated to a bilateral cochlear implant[J].Applied Acoustics,2012,73(3):256-264.
[5]Yousefian N,Loizou PC.A dual-microphone speech enhancement algorithm based on the coherence function[J].Audio,Speech,and Language Processing,IEEE Transactionson,2012,20(2):599-609.
[6] Fischer S,Simmer K U.Beamforming microphone arrays for speech acquisition in noisy environments[J].Speech communication,1996,20(3):215-227.
[7]Comminiello D,Scarpiniti M,Parisi R,et al.Super directive microphone array system for speech enhancement hand-free communication[OL].http://ispacinguniroma1it/scarpiniti/papers/U2pdf.
[8]Huang H C,Lee J.A new variable step-size NLMS algorithm and its performance analysis[J].Signal Processing,IEEE Transactionson,2012,60(4):2055-2060.
[9]Rahmani M,Akbari A,Ayad B,et al.Amodified coherence based method for dual microphone speech enhancement[C].Signal Processingand Communications,Dubai,2007:225-228.
[10]Allen JB,Berkley D A,Blauert J.Multimicrophone signal-processing technique to remove room reverberation from speech signals[J].The Journal of the Acoustical Society of America,1977,62(4):912-915.
[11]Aarabi P,ShiG.Phase-based dual-microphone robust speech enhancement[J].Systems Man and Cybernetics,Part B:Cybernetics,IEEE Transactionson,2004,34(4):1763-1773.
猜你喜欢
电子测试(2022年3期)2023-01-14
舰船科学技术(2022年11期)2022-07-15
数学物理学报(2022年3期)2022-05-25
海军航空大学学报(2020年2期)2020-07-27
中国中医急症(2019年10期)2019-05-21
汉字汉语研究(2018年1期)2018-05-26
电子技术与软件工程(2017年12期)2017-07-05
中国工程咨询(2017年10期)2017-01-31
小学科学(2016年12期)2017-01-06
电脑爱好者(2016年24期)2017-01-05
