
支配性VN1N2结构中动词语义指向的机器定位研究
2015-10-14 04:58傅成宏
阜阳师范大学学报(社会科学版) 2015年4期
傅成宏
支配性VN1N2结构中动词语义指向的机器定位研究
傅成宏1*
(阜阳师范学院 文学院,安徽 阜阳 236032)
对现代汉语VN1N2序列的结构进行了分类并统计出各小类在语料中所占的比例。使用规则与统计相结合的方法,让计算机自动定位支配型VN1N2结构中V的语义指向。具体方法是:先根据N1与N2的是否属于相同语义类,把支配型VN1N2结构分成两类;再分别使用规则和统计模型对两种类型的VN1N2结构进行不同的处理;最终设计出相应的计算机软件开发算法并画出了程序设计的流程图。
VN1N2结构,语义指向,机器定位
1 引言
众所周知,“语义指向”是汉语语法研究的一大特色,汉语语言学本体的研究在此方面已经取得了丰硕的成果,这里不再赘述。中文信息处理领域对“语义指向”的研究尚不多见,赫琳[1]对现代汉语副词语义指向的计算机识别问题做出了深入的研究。陆俭明[2]认为,从句法成分的性质上说,语义指向有两大类,其中一类为动词和名词的语义指向关系。我们尝试对现代汉语动词语义指向的自动识别进行探讨,本文选择动词结构的一个小类“支配性VN1N2结构”,对其中动词V语义指向的机器定位问题做出初步的分析。
我们对北京大学开发的1998年1月《人民日报》(192万字,50551句)带标语料库[3]49-64进行检索,共得到VN1N2序列11529条。这11529条中,并不全是支配性VN1N2结构,具体分布情况如下图1:
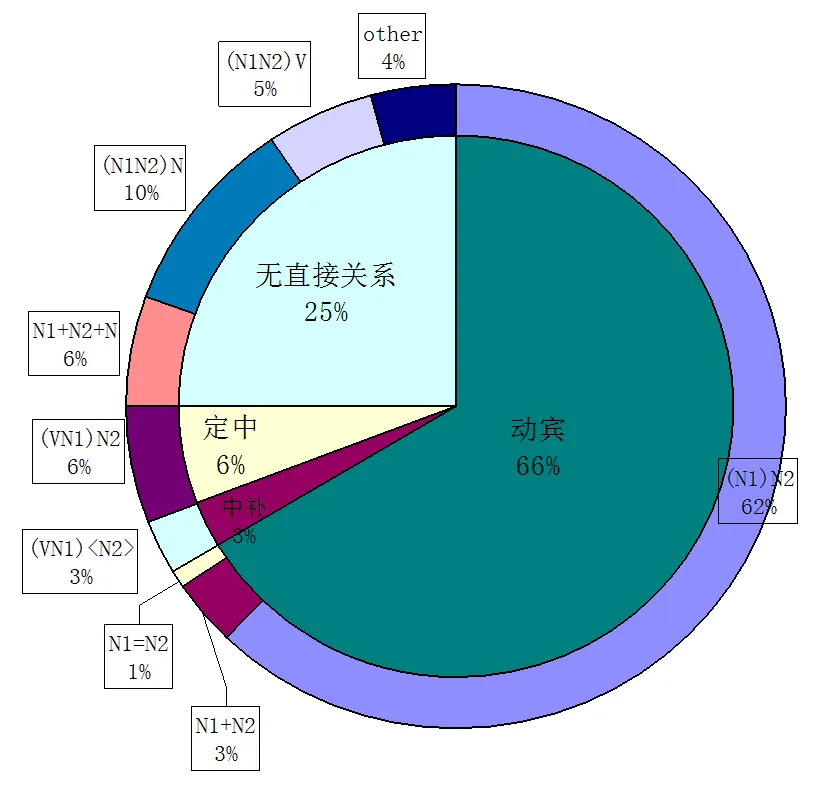
图1 VN1N2词性序列语法结构分布图
从上图可见,我们所观察到的VN1N2序列的语法结构共有4大类:
A.动宾结构,N1N2作V的宾语,其中有3种情况:
(1)N1与N2为定中关系,图中标示为(N1)N2;
(2)N1与N2为并列关系,图中标示为N1+N2;
(3)N1与N2为同位关系,图中标示为N1=N2;
B.中补结构,N2作动词短语VN1的补语,图中标示为(VN1)
C.定中结构,VN1作N2的定语,图中标示为(VN1)N2;
D.N1、N2与V无直接关系,其中有4种情况:
(1)N1、N2与后面的其他名词性结构构成并列关系,图中标示为N1+N2+N;
(2)N1、N2与后面的其他名词性结构构成定中关系,图中标示为(N1N2)N;
(3)N1、N2与后面的其他动词性结构构成主谓关系,图中标示为(N1N2)V;
(4)其它,较(1)(2)(3)更为复杂,关系多样。
在B类和C类中,V的语义指向皆为N1,D类中N1、N2与V无直接关系,所以,我们更须要关注的是A类,即动宾结构中V的语义指向问题,这一类也是在整个VN1N2序列结构中所占比例最大的。而当N1与N2为并列关系时,V同时指向N1与N2,当N1与N2为同位关系时,V同时指向N1和N2,不会造成歧义。当N1与N2为定中关系时,V可能指向N1,也可能指向N2,并有可能造成歧义。所以,本文的研究的“支配性VN1N2结构”为上图中的动宾结构,并以“N1与N2为定中关系”为重点研究内容。
关于研究方法,我们采用规则与统计相结合的方法。从语言学本体研究的成果语义类中提取相应的定位规则,使用统计计算的两个模型计算并比较动词V和名词N1、N2在语义上结合的紧密程度,据此衡量语义指向可能性的大小。
2 机器定位的方法
2.1由语言知识构建的定位规则
如前所述,当N1与N2属于相同语义类时,我们须要使用一定的语言知识来构建定位规则。本文须要用到的语言知识主要是语义学中的语义类知识,语言学本体研究中的相关成果也比较多,我们选用比较新的《现代汉语分类词典》[4]和董振东 “知网(How Net)”[5]中的语义分类方法。
我们的定位策略是比较语义范围的大小,可以分为两种情况分别处理:
第一种情况:VN1N2序列之前的分句中有与N1、N2相同语义类的名词性结构N,此时N1与N2中比N的语义范围小的是V的语义指向所在。如:
例1 面包/n 吃/v 得/u 不/d 多/a ,/w 只/d 吃/v 了/u 一/m 块/q 面包/n
例2 食物/n 没/d 吃/v 什么/r ,/w 只/d 吃/v 了/u 一/m 块/q 面包/w
这两个例子中都出现了“只吃了一块面包”,其中“一块”和“面包”属于相同语义类,但“吃”的语义指向不同。例1中,前文出现“面包”,与后面的“一块”和“面包”属于相同语义类,且语义范围大于“一块”,所以,“吃”的语义指向为“一块”,同样分析可以得出例2中“吃”的语义指向为“面包”。
第二种情况:VN1N2序列之前的分句中没有与N1、N2相同语义类的名词性结构N,N1与N2中语义范围小的是V的语义指向所在。如:
例3 攻读/v 硕士/n 学位/n
例4 呼吁/v 全国/n 人民/n 团结/v 起来/v
例3中,“硕士”和“学位”属于相同语义类,前者的语义范围小于后者,所以确定“攻读”的语义指向为“硕士”。例4中,“全国”和“人民”属于相同语义类,前者语义范围大于后者,所以确定“呼吁”的语义指向为“人民”。
2.2 语义指向定位的统计学模型
支配性VN1N2结构中N1和N2不属于同一个语义类的情况在语料库中出现得非常多,我们很难利用语言学知识制定规则来进行V的语义指向的定位,只能采用统计的方法。如:
例5 建造/v 农民/n 新村/n → *建造/v 农民/n 建造/v 新村/n
例6 切/v 萝卜/n 丝/n →切/v 萝卜/n 切/v 丝/n
“建造”的语义指向为“新村”,“切”的语义指向可以为“萝卜”和“丝”。对于这种N1与N2属不同语义类的情况,我们的定位策略是:首先使用曲维光[6]提出的相对词序比RRWR对V的两个候选语义指向对象做初步评估与筛选,再使用互信息模型做最终的确定。
(1)相对词序比RRWR
首先建造全集词汇表(WORDS)和子集词汇表(words)。WORDS的建造方法为:在全部语料(下文简称为E)中抽取所有的词形,按其在E中出现的频率降序排列,形成WORDS。words的建造方法为:从E中抽取所有VN1N2序列,构成子集语料(下文简称为e),从e中抽取所有的词形,按其在e中出现频率的降序排列,形成该动词的words。为右侧出现N1N2的所有的动词建造不同的words。
其次是RRWR的计算。如某个名词n,在WORDS中的序号为i,在某个动词v的words中的序号为j,则该n相对于动词v的相对词序比为:
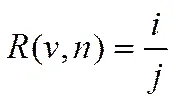
n1、n2在WORDS中的序号分别为i1、i2,在words中的序号分别为j1、j2。若i1≈i2,则反映出n1、n2在E中出现机率相近,这时须考虑它们在e中的出现情况,即j1、j2,若j1<j2,则反映出n1比n2更多出现在e中,根据公式①此时R(v,n1) >R(v,n2),因此可以判断v指向 n1的可能性大于n2;相反,若j1≈j2,则反映出n1、n2在e中出现机率相近,这时须考虑它们在E中的出现情况,即i1、i2,若i1>i2,则反映出n1比n2更少出现在E中,根据公式①此时R(v,n1)>R(v,n2),因此可以判断v指向 n1的可能性大于n2;如果R(v,n1)≈R(v,n2),则可以判断v指向 n1、n2的可能性均等。则我们还须要设定一个阈值M1,只有当R(v,n1)、R(v,n2)均大于该阈值M1时,才考虑n1、n2是否被v指向并进入下一步的计算。
(2)搭配互信息
Church[7]指出:可以用两个词的互信息值来度量它们之间关系紧密程度,即:
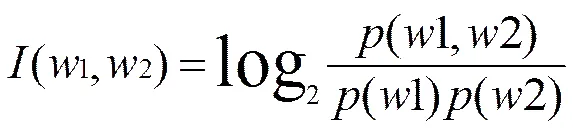
Smadja[8]、孙茂松等[9]、曲维光[6]等人将互信息用于衡量两个词的搭配力度,并将搭配窗口设置为[-5,+5],因此,对公式②做出改进:
③
但实际上公式③对公式②的改进仅仅在于设定了窗口宽度,二者的计算在本质上是完全一样的,没有考虑到搭配词的位置因素。我们须要考虑的是动词V在语义上是指向紧邻其后(右侧)的第一个名词n1还是第二个名词n2,或是同时指向二者,即须要分别计算V和n1、n2的关系紧密程度。因此我们无须设置窗口宽度,但须设置搭配词(被指向者)的位置,直接使用公式②即可,即:
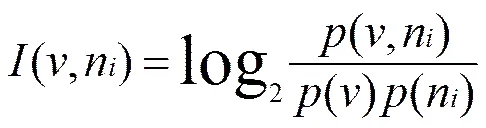
设语料库的规模为N词次,则④式推导为:
⑤
其中,r(v)表示动词v在语料库中出现的频次;当i=1时,r(v, n1)表示语料库中名词n1在动词v右侧第一个位置出现的频次,当i=2时,r(v, n2)表示语料库中名词n2在动词v右侧第二个位置出现的频次。我们还须设定一个阈值M2,根据公式⑤的计算结果,I(v, ni)的两个值均小于该阈值时,计算机会认为n1、n2均不被V指向;否则最终确定V的语义指向为I(v, ni)中数值大者,但如果两个数值非常接近,则认为V同时指向n1、n2。
为降低计算的复杂程度,在得到R(v, n)和I(v, n)的计算结果之后,我们须要将二者结合起来形成一个调和结果Co,并设定一个调和阈值M,这样,只要在Co1、Co2和M之间进行比较就可以了。此外,在实验过程中,我们须要不断调整M值和|Co1-Co2|值(即Co1与Co2的差值),以期得到较高的识别率与正确率。Co的计算方法为:
Co= R(v, n)*0.3+I(v, n)*0.7 ⑥
综上,我们可以得到支配性VN1N2结构中动词语义指向定位的主要流程,见图2。
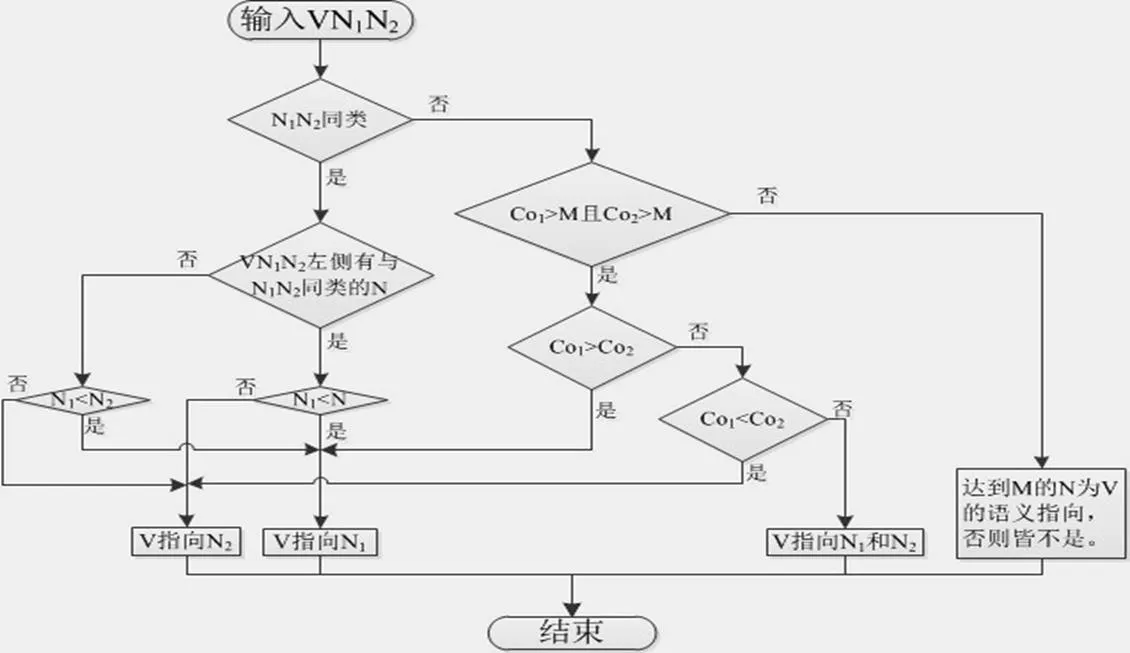
图2 支配性VN1N2结构中动词语义指向的机器定位主流程图
3 结语
本文尝试从中文信息处理的角度对现代汉语动词语义指向的机器自动定位问题进行探讨,并结合动词结构的一个小类“支配性VN1N2结构”做出了初步分析。对“支配性VN1N2结构”做出简单地分类,针对不同类别提出了不同的语义指向定位策略。
下一步的研究工作:
(1)编译出计算机程序,通过精确的数据来验证本方法的可行程度;
(2)在(1)的基础上,不断调整得到最佳|Co1-Co2|值及M值,得到最佳的Co计算方法,以便尽可能地提高识别率与正确率;
(3)本文所涉及到的N,在语料库中实际上有多种表现形式,如名词性数量短语、名词性的代词等,这些词语如果连续出现在动词的后面,也应该纳入到VN1N2结构中去;
(4)本文所用的语言学知识,其提出的初衷并非直接为中文信息处理服务的,未必能很好地适用于本项研究任务,因此我们须寻找甚至自己构建更理想的能适应本任务的语言学知识。
参考文献:
[1]赫琳.现代汉语副词语义指向及其计算机识别研究[M].北京: 中国社会科学出版社,2009.
[2]陆俭明.汉语和汉语研究十五讲[M].北京:北京大学出版社,2003:318.
[3]俞士汶,段慧明,等.北京大学现代汉语语料库基本加工规范[J].中文信息学报,2002,(5).
[4]苏新春.现代汉语分类词典[M].北京: 商务印书馆,2013.
[5]董振东.知网[CP/OL].http://www.keenage.com.
[6]曲维光.基于框架的词语搭配自动抽取方法[J].计算机工程,2004,(12): 22-24, 195.
[7]Church K, Hanks P. Word Association Norms, Mutual Information, and Lexicography[c]. Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics, 1989:76-83.
[8]Smadja F. Retrieving Collocations from Text: Xtract [J]. Computational Linguistics, 1993, 19(1):143- 177.
[9]孙茂松, 黄昌宁, 方捷.汉语搭配定量分析初探[J].中国语文,1997, (1):29-38.
ComputerPositioningof Semantic Orientation of Verb in the Verb Dominating Structure of VN1N2
FU Cheng-hong
(School of Chinese Language and Literature, Fuyang Normal University, Fuyang 236032, Anhui)
We classified the structure of VN1N2 in the modern Chinese, and calculated the proportion of each small class in the corpus. Based on rules and statistics, the computer can find the location of V’s semantic orientation in the verb dominating structure of VN1N2 automatically. The specific method is: first, divide the verb dominating structure of VN1N2 into two categories according to whether the N1 and N2 belong to the same semantic category; and then analyze the two different categories by using the rules and statistical method; in the end, design corresponding algorithm of the computer software and draw its flow chart.
structure of VN1N2, semantic orientation, computer positioning
TP391
A
1004-4310(2015)04-0053-04
10.14096/j.cnki.cn34-1044/c.2015.04.013
2015-05-03
2011年度教育部人文社会科学研究青年基金项目“基于词性标注的现代汉语兼语式自动识别研究”(11YJCZH035);阜阳师范学院人文社会科学研究重点项目“现代汉语兼语结构的机器探测”(2010FSSK02ZD)。
傅成宏(1971-),男,安徽明光人,讲师,研究方向: 计算语言学及现代汉语语法。
猜你喜欢
中学生数理化(高中版.高考数学)(2021年6期)2021-07-28
意林(2021年9期)2021-05-28
汉字汉语研究(2020年3期)2020-12-14
时代英语·高一(2019年1期)2019-03-13
疯狂英语(双语世界)(2017年3期)2018-01-19
传媒评论(2017年8期)2017-11-08
自动化学报(2017年2期)2017-04-04
Coco薇(2016年8期)2016-10-09
国际汉语学报(2016年2期)2016-05-17
汉语国际传播研究(2013年1期)2013-08-07
