
基于稀疏表示的人脸姿态估计研究
2015-10-13 01:03:13廖海斌邱益鸣陈庆虎
电视技术 2015年13期
廖海斌,邱益鸣,陈庆虎
(1.湖北科技学院 计算机科学与技术学院,湖北 咸宁 437100;2.武汉大学 电子信息学院,湖北 武汉 430072)
基于稀疏表示的人脸姿态估计研究
廖海斌1,邱益鸣2,陈庆虎2
(1.湖北科技学院 计算机科学与技术学院,湖北 咸宁 437100;2.武汉大学 电子信息学院,湖北 武汉 430072)
针对人脸光照、遮挡、身份、表情等因素变化的人脸姿态估计难题,结合稀疏表示分类(SRC)方法的优秀识别性能,对SRC理论进行了深入分析,并将其应用于人脸姿态分类。为了解决姿态估计中人脸光照、噪声和遮挡变化问题,将人脸姿态离散化为不同的子空间,每个子空间对应一个类别,据此,提出基于字典学习与稀疏约束的人脸姿态识别方法。通过在公开的XJTU和PIE人脸库上实验表明:所研究的方法对人脸光照、噪声和遮挡变化具有鲁棒性。
人脸姿态估计;稀疏表示;子空间学习;人脸识别
人脸识别研究经历半个多世纪的发展,理论研究也接近成熟。目前人们逐渐将研究目光转向人脸分析(人脸姿态、表情、性别和年龄分析等)研究。其中,人脸姿态估计就是根据图像确定人脸在三维空间中姿态参数的过程。人脸姿态估计在智能视频分析、人脸识别、人机交互和虚拟现实领域具有巨大的应用前景。
可以将现有的人脸姿态估计算法大概分为三类:子空间分析方法、3D方法、其他类特殊方法。第一类方法通过对人脸纹理信息进行子空间分析获取具有鉴别性的低维特征向量,然后采用成熟的分类器(距离分类器,支持向量机等)进行分类识别。因此,此类方法的重点与关键在于特征的提取与降维。其中,比较典型的有主成份分析(PCA)[1],线性判别(LDA)[2],独立子空间分析方法[3]等。由于PCA是一种线性降维方法,而人脸的光照、表情、年龄和个体的变化导致人脸姿态呈现出非线性变化。因此,研究者们又提出使用核主成份分析(KPCA)[4],流型学习方法[5]等解决这种非线性变化问题。不尽人意的是,核方法和流型学习方法相对复杂,同时随着人脸训练样本增加,其分类能力将变弱。综上,第一类方法具有处理速度快和容易实现的特点。但同时需要通过大量样本的训练,对人脸的光照、表情等变化较为敏感。
第二类方法试图利用三维人脸结构空间信息进行人脸姿态估计。这类方法往往需要利用三维重建技术或是使用三维扫描仪器获取三维人脸模型,然后利用3D模型的任意旋转性在三维空间实现人脸姿态估计[6-8]。此类方法由于充分利用了人脸3D模型,更接近于现实中头部本质。因此,取得了不错的准确率。但是,这类方法往往对图像的大小、数量和质量要求很高,并且实时和实用性不高。特别地,视频监控中的超低分辨率和遮挡人脸图像效果将急骤下降。
光照、噪声、遮挡、分辨率、身份、表情等因素的变化都会对姿态估计的准确性产生巨大的影响,如何消除这些因素的影响是目前亟需解决的问题。针对以上问题,本文提出基于稀疏表示的人脸姿态估计方法,解决人脸姿态估计中的光照、噪声和遮挡等问题。
1 基于稀疏表示的人脸姿态分类
实验表明:基于稀疏表示的分类方法(SRC)具有很强的鉴别能力,特别是在人脸识别领域[12- 13]。但是这种方法存在的一个最大问题是对人脸姿态变化非常敏感[14]。这是因为:1)SRC方法是基于线性组合的思想,线性组合要求基底对象之间是稠密对应关系,而人脸的姿态变化会导致人脸之间形成错位的现象;2)研究学者们发现,来自不同人的两幅人脸图像之间的相似度比来自同一个人的不同姿态条件下的两幅人脸图像之间的相似度还要大。
以上两点原因分别从SRC本质和人脸图像本质上分析了姿态变化对基于SRC的人脸识别的影响。如图1所示,待测正脸由其相对应类别样本的线性组合表示(图中矩形框),根据其非0组合系数可以对待测人脸进行正确分类。但是当待测样本是有姿态变化的侧脸时,其非0系数就可能会分布在与待测人脸具有相同姿态的样本中(见图2矩形框)。因此,图2所示情况为进行人脸姿态估计提供了理论支持,也就是说只要将人脸姿态离散化后,采集每个姿态空间下足够多的人脸图像作为完备字典,然后通过稀疏约束的方法就能进行姿态的正确估计。

图1 基于稀疏表示的正脸识别示例

图2 基于稀疏表示的侧脸识别示例
SRC在本质上等价于“全局分解”和“局部重构”的结合利用。即一方面从“全局分解”过程中得到样本的稀疏表示;另一方面又根据“局部重构”误差对测试样本进行分类。然而,一个潜在的困难在于,实现中很难获取“足够多”的训练样本。因此,SRC常常面临着“小样本”问题,影响其分类性能。而基于SRC的姿态分类方法却能克服“小样本”问题。因为如果将人脸姿态离散化为19类,每类包含100个人脸图像样本,总共也只需1 900个样本,这在现实中很容易满足。因此,基于SRC的姿态分类不构成“小样本”问题。
1.1 人脸姿态稀疏表示
首先,将人脸姿态以10°(角度可以根据需要设定)偏转为间隔进行离散化,把人脸姿态化分为19种视点(以人脸左右偏转为例);然后,将第i(i=1,2,…,19)类姿态训练样本用特征向量矩阵表示为:Ai=[Si,1,Si,2,…,Si,ni]∈Rm×ni。其中,Si,1是第i类姿态中第1个人脸的特征向量;ni表示第i类姿态样本数目;m表示样本维数。根据线性组合原理,如果第i类姿态样本足够多,那么来自此类的测试样本y可以由第i类姿态样本的线性组合表示
y=ai,1Si,1+ai,2Si,2+…+ai,niSi,ni
(1)
其中,ai为线性组合系数。由于测试样本y所属的姿态类别未知,因此定义一个由19类训练样本集组成的完备字典A
A=[A1,A2,…,A19]=[S1,1,S1,2,…,S19,n19]
(2)
那么测试样本y可以重写成完备字典A的线性组合
y=Ax∈Rm
(3)
其中,x=[0,…0,ai,1,ai,2,…,ai,ni,0,…,0]∈Rn是一个非常稀疏的系数向量。理论上,如果y属于第i类姿态,那么x的非0项全部集中在第i项。因此,根据x可以得到测试样本y的姿态类别。其识别情况如图3所示。

图3 基于SRC人脸姿态分类识别
1.2 人脸姿态识别
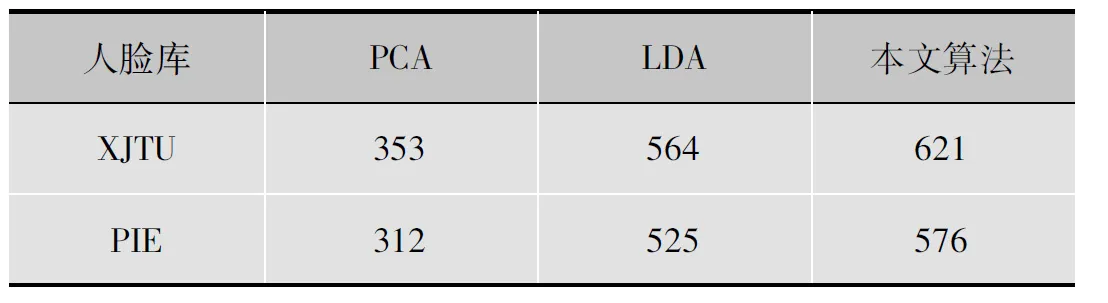
从上节可以看出,系数向量x隐含着待测样本y的姿态信息。因此,人脸姿态估计问题变成了y=Ax的求解问题。如果m>n,方程组将是over-determined,x有唯一的解或无解。如果m (4) 针对式(4)的最优化求解目前有许多成熟方案可供选择。 (5) 上节从理论上分析了基于稀疏表示的姿态分类方法的可行性并论述了整个姿态估计流程,本节将利用XJTU[16]与PIE[17]人脸库验证本文提出的人脸姿态估计算法的有效性。 XJTU人脸库:本文从XJTU上挑选相同光照条件下130人的姿态图像进行实验,其中100人用作训练,剩下30人用作测试,每人包括9幅不同姿态图像(从19张视点图像中间隔选取),图4为实验人脸数据库图例。 图4 XJTU人脸库像示例 同时,对测试图像进行加噪声和遮挡的操作,以比较各方法对图像噪声和遮挡的鲁棒性,图像加0均值的加性高斯噪声,噪声强度分别为σ=0.01和σ=0.03像素。图5为人脸图像加噪和遮挡的示例样本。 PIE人脸数据库:该数据库在沿y轴上将人脸按左右旋转分为9个不姿态类别,变化范围为-90°~90°,如图6所示。由于该数据库每种姿态都有光照变化,因此,本文使用该人脸姿态库验证算法对光照的鲁棒性。 图5 人脸图像噪声和遮挡示例样本 图6 PIE人脸库示例 为了比较各方法对人脸图像光照、噪声和遮挡的鲁棒性,本文首先对所有训练图像进行手动对齐归一化处理;然后在有光照、噪声和遮挡的待测图像上进行人脸姿态判别,分别统计不同姿态的识别准确率,得到的实验结果见图7~11。实验时,每类姿态进行10次实验,所有实验均重复10次,统计其平均识别率。 图7 基于XJTU的不同姿态分类方法比较(无噪声) 图8 基于XJTU的不同姿态分类方法比较(有噪声σ=0.01) 图9 基于XJTU的不同姿态分类方法比较(有噪声σ=0.03) 图10 基于XJTU的不同姿态分类方法比较(有遮挡) 图11 基于PIE的不同姿态分类方法比较(有光照变化) 从图7可以看出:图像无光照、噪声和遮挡变化时,3种方法都能得到很好的效果。但是当图像有光照、噪声和遮挡的情况后,尤其是图像有遮挡以后,基于 PCA 和 LDA 的姿态判别方法性能下降很快(见图10)。从图8,9,10和11可以看出:SRC的方法受人脸图像噪声、遮挡和光照的影响较小,能够达到比较好的姿态判别结果。因此,本文提出的SRC人脸姿态估计方法对人脸光照、噪声和遮挡变化具有鲁棒性。 为了进一步说明本文算法的性能,表1给出了几种算法的平均运行时间比较结果(配置为:HP Core i3 M330 2.13 GHz/内存2 Gbyte, MATLAB 7.0)。 表1 运行时间比较 ms 从表1中可以看出:虽然本文算法的运行时间多于线性子空间方法,但并不影响其在应用中的实时性。但是,本文算法对人脸遮挡和光照变化的鲁棒性是线性子空间方法所不能比拟的。 经过研究发现,人脸姿态分类和人脸识别具有“异曲同工”之妙,为此,本文提出基于稀疏表示的人脸姿态分类方法。本方法不但具有稀疏表示人脸识别方法(SRC)中对光照和遮挡的鲁棒性,同时还能克服SRC中的“小样本”问题和“稠密对应”问题。因此,相比于人脸识别问题,基于稀疏表示的分类方法更适合于姿态识别问题。 [1] SRINIVASAN S, BOYER K L. Head pose estimation using view based eigenspaces [C]// Proc. 16th International Conference on Pattern Recognition. [S.l.]:IEEE Press,2002:302-305. [2] 王华青.基于局部几何结构的人脸图像姿态估计[D].西安:西安电子科技大学,2013. [3] LIS Z. Learning multi-view face subspaces and facial pose estimation using independent component analysis [J]. IEEE Trans. Image Process,2005,14(6):705-712. [4] WU J, TRIVEDI M M. A two-stage head pose estimation framework and valuation [J]. Pattern Recognition,2008,41(5):1138-1158. [5] CHEN L, ZHANG L, HU Y M, et al. Head pose estimation using fisher manifold learning [C]// Proc. IEEE International Workshop on Analysis and Modeling of Faces and Gestures. [S.l.]:IEEE Press,2003: 203-207. [6] JIMÉNEZ P, NUEVO J, BERGASA L, et al. Face tracking and pose estimation with automatic three-dimensional model construction [J]. IET Computer Vision,2009,3(2): 93-102. [7] VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features [C]//Proc.CVPR.Hawaii:IEEE Press,2001:511-517. [8] JIMÉNEZ P, BERGASA L M, NUEVO J, et al. Face pose estimation with automatic 3D model creation in challenging scenarios [J]. Image and Vision Computing,2012,30(9):589-602. [10] NUEVO J, BERGASA L M, JIMéNEZ P. RSMAT:robust simultaneous modeling and tracking [J]. Pattern Recognition Letters,2010,31(16):2455-2463. [11] 陈振学,常发亮,刘春生, 等. 基于Adaboost算法和人脸特征三角形的姿态参数估计[J].武汉大学学报:信息科学版,2011,36(10):1164-1167. [12] WRIGHT J, MA Y, MAIRAL J, et al. Sparse representation for computer vision and pattern recognition [J]. Proceedings of the IEEE,2010,98(6):1031-1044. [13] WRIGHT J, YANG A Y, GANESH A. Robust face recognition via sparse representation [J]. IEEE Trans. Pattern Analysis and Machine Intelligence, 2009, 31( 2): 210-227. [14] RIGAMONTI R, BROWN M A, LEPETIT V. Are sparse representations really relevant for image classification [C]//Proc.CVPR. [S.l.]:IEEE Press,2011: 1545-1552. [15] TIBSHIRANI R. Regression shrinkage and selection via the lasso [J]. Journal of the Royal Statistical Society,Series B (Methodological),1996,58(1): 267-288. [16] AI & R institute of artificial intelligence and robotics Xi’an Jiaotong University. oriental face database[EB/OL].[2014-10-20]. http://www.aiar.xjtu.edu.cn/groups/face/Chinese/Homepage.html. [17] CMU PIE database. [EB/OL].[2014-10-20].http://www.ri.cmu.edu/projects/project_418.html. 廖海斌(1982— ),博士,讲师,主研图像处理与智能识别、三维重建等; 丘益鸣(1974— ),博士生,主研图像处理与模式识别; 陈庆虎(1957— ),教授,博士生导师,主研视频处理与智能识别。 责任编辑:闫雯雯 Face Poses Estimation Based on Sparse Representation LIAO Haibin1,QIU Yiming2,CHEN Qinghu2 (1.SchoolofComputerScienceandTechnology,HubeiUniversityofScienceandTechnology,HubeiXianning437100,China;2.SchoolofElectronicInformation,WuhanUniversity,Wuhan430072,China) According to the challenges in face pose estimation under different illuminations, occlusions, identity, expressions, and so on,combining with the excellent classification performance of sparse representation classification (SRC), a deep analysis on the theory of SRC and its application in face pose classification are made. In order to handle challenges such as variation of face illumination, noises and occlusion, a robust face pose estimation method based on dictionary learning and sparse representation is presented. In which face poses are discrete into different subspaces, each subspace corresponding to a class. Several experiments are performed on XJTU and PIE databases. Recognition results show that the proposed method is suitable for efficient face pose recognition under illumination, noises and occlusion variations. face pose estimation; sparse representation; subspace learning; face recognition 【本文献信息】廖海斌,邱益鸣,陈庆虎.基于稀疏表示的人脸姿态估计研究[J].电视技术,2015,39(13). 国家自然科学基金项目(61271256);河南省重大科技攻关项目(072SGZS38042);湖北科技学院博士启动基金项目(BK1418) TP391 A 10.16280/j.videoe.2015.13.009 2014-10-21

2 实验与分析








3 总结
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
学生天地(2020年31期)2020-06-01 02:32:06
农业机械学报(2020年2期)2020-03-09 07:35:30
中华建设(2019年7期)2019-08-27 00:50:18
动漫星空(2018年9期)2018-10-26 01:17:14
项目管理技术(2016年12期)2016-06-15 20:29:33
西南交通大学学报(2016年6期)2016-05-04 04:13:11
计算机工程(2015年8期)2015-07-03 12:19:07
发明与创新(2015年33期)2015-02-27 10:40:09
