
Community Discovery with Location⁃Interaction Disparity in Mobile Social Networks
2015-10-11 03:13DanmengLiuWeiWeiGuojieSongandPingLu
ZTE Communications 2015年2期
Danmeng Liu,Wei Wei,Guojie Song,and Ping Lu
(1.Peking University,Beijing 100871,China;2.ZTE Corporation,Shenzhen 518057,China)
Community Discovery with Location⁃Interaction Disparity in Mobile Social Networks
Danmeng Liu1,Wei Wei2,Guojie Song1,and Ping Lu2
(1.Peking University,Beijing 100871,China;2.ZTE Corporation,Shenzhen 518057,China)
With the fast⁃growth of mobile social network,people’s inter⁃actions are frequently marked with location information,such as longitude and latitude of visited base station.This boom of data has led to considerable interest in research fields such as user behavior mining,trajectory discovery and social demo⁃graphics.However,there is little research on community dis⁃covery in mobile social networks,and this is the problem this work tackles with.In this work,we take advantage of one sim⁃ple property that people in different locations often belong to different social circles in order to discover communities in these networks.Based on this property,which we referred to as Location⁃Interaction Disparity(LID),we proposed a state network and then define a quality function evaluating commu⁃nity detection results.We also propose a hybrid community⁃detection algorithm using LID for discovering location⁃based communities effectively and efficiently.Experiments on syn⁃thesis networks show that this algorithm can run effectively in time and discover communities with high precision.In real⁃world networks,the method reveals people’s different social circles in different places with high efficiency.
mobile social network;community detection;LID
1 Introduction
Nowadays,mobile social network(MSN)services with location support have become a part of people’s lives.This trend has produced a mass of location data that can be used to study human migration pat⁃ terns and social structure.
Community detection is a field of social network research re⁃lated to the social groups that people belong to.Communities are groups of people in a social network,and the amount of in⁃teraction within these groups is greater than that between dif⁃ferent groups[1].Group information is useful for further study on viral marketing[2],behavior modeling[3],and network vi⁃sualization[4].
Introducing location information into community discovery opens up possibilities for practical application.Advertisers can use location information to push advertisements in specific places and target specific user groups.Friend recommendation for SNS sites can be more location specific when users use so⁃cial networking applications on mobile devices.What’s more,location information of users often contains time information,communities of one user formed in different places are actually communities formed in different time.Thus social relationship of users in different places can help social network miners un⁃derstand users’activity patterns better.
Our fundamental task is to utilize both social relation data and location information to discover communities in MSN.Tra⁃ditionally,community discovery works are on pure networks that do not take contents of networks into consideration[5],[6]. Recently,much research has been done on location⁃based so⁃cial network mining,and the focus of these works is mainly re⁃vealing the relationship between human interactions and loca⁃tion.However,most of these works deal with local properties of a social actor,such as social connection strength[7]and user trajectories[8],and no research is being done on community discovery with location information.In reality,it is common for a person to behave quite differently in different locations.For example,a worker might contact colleagues when at work,talk with family when in a metro station heading home,and interact with close friends at home.Therefore it is natural for one actor in a location⁃marked social network to have multiple communi⁃ties in different places.Taking advantage of these properties can be helpful for community discovery in MSN.
There can be several challenges in integrating location infor⁃mation into community discovery.First,the scale of the prob⁃lem can be several times larger because users can be in multi⁃ple places with social connections in every place.Therefore ef⁃ficient algorithms need to be designed to tackle large datasets. Second,traditional measures of user similarity for community discovery only comprise of social interactions,but no location information is included in the measurement.Finally,a new da⁃ta model needs to be built for both location and social interac⁃tion information.
In this paper,we tackle the problem of finding communities in MSN by establishing a model that integrates location and so⁃cial interaction features.We then design an efficient,high⁃pre⁃cision algorithm for this model.First,we examine and confirm that it is common for users to have different communities when they are in different locations.We name this sort of disparity as Location⁃Interaction Disparity(LID).Then inspired by LIDwe propose a state network model for detecting community structure,where one state denotes one user in a specific loca⁃tion and links represent users interact in different locations. This model can easily describe the phenomenon of people in different locations belonging to different communities.After that,we define a quality function for state model based on mod⁃ularity.Then we propose a community detection algorithm inte⁃grated with LID for effective and efficient community discov⁃ery.This algorithm has a conglomerating step and divisive step and is called a hybrid community detection algorithm.Experi⁃ments on synthesis data set verified the superiority of our pro⁃posed algorithm.We also conduct experiments on real⁃world data,which shows that users can be in different types of com⁃munities indicating different activities.
The primary contributions of this paper are as follows.
1)We propose a state network model for discovering communi⁃ties in MSN with location interaction disparity.
2)We design a quality function based on modularity for state networks communities.
3)We propose an efficient algorithm to discover communities in MSN with state network model and quality function.
4)We present experiments on both synthesis and real⁃world da⁃ta sets to show that our methods are effective and efficient.
2 Model and Problem Definition
2.1 Location-Interaction Disparity
People tend to have different social relations in different places.For example,when people are at work,they tend to con⁃tact their colleagues,and when they are at home,they tend to contact their friends in private circles.This phenomenon,called LID,also happens on virtual spaces such as cyber⁃spac⁃es where different websites tend to provide different services,thus leading to different types of social relations.
We investigate LID in a real⁃world MSN.This network is originally represented as a collection of(ui,li,t,uj,lj,t,t),where(ui,li,t)means that at time t,person uiin location li,tcalls person ujin location lj,t.The location of every user uiis given by Li={li,t|∃(ui,li,t,uj,lj,t,t)∈D}where some communications are made in these locations.We generate a communication feature vector ci,lfor every l∈Li,such that ci,l(j)=|{(ui,l,uj,lj,t,t)}|. These vectors actually record the communication frequency of user uito others in different places.
To simplify the investigation,we take users with marked home and work cells,or O cells and D cells,to show that LID exists widely in human communication networks.Both O and D cells are marked via the methods proposed in[9],and the differences between different locations are measured with Ken⁃dall’sτ[10]to avoid non⁃normality in degree distribution.For every ui,we measure Kendall’s τ between ci,Oiand ci,Diand plot 9τn(n-1)/2(2n+5)(Fig.1).We trans form τ in this way b⁃ecause the distribution of τ is approximated with normal distri⁃ butionN(0,2(2n+5)/9n(n-1).
In Fig.1,most users have negative correlation between their O and D feature vectors.With a confidence level of 95%,we show that 65.2%of all the users show LID between home and work.This result shows that LID phenomenon is common in people’s daily lives.
2.2 State Network
To effectively discover communities in MSNs with LID,we need to make sure that two locations for one person with signifi⁃cant LID are separated.Following this idea we introduce a state network model for discovering communities in MSN.
In our work,a state network has several sets of nodes and links between these nodes.The sets are called entities and the nodes are called states.In a real scenario,an entity represents a single person and a state represents a person location tuple(u,l),when user u appears in l.There is an edge exists be⁃tween two states(u1,l1)and(u2,l2)only if two entities u1and u2interact when they are in l1and l2respectively,or in real scenar⁃io,two people have contacted each other in two different loca⁃tions.For example,if there are two users u1and u2,their home and work places are hu1,wu1and hu2,wu2,respectively.We call<u1,hu1>and<u1,wu1>two states for u1.An edge between<u1,hu1>and<u2,hu2>means that u1and u2made phone calls when u1is in hu1and u2is in hu2.The weights of edges are the number of calls made between two linked states.
To give a formal definition,we define our network as an un⁃directed graph G=<V,Γ,A>,where V is the set of states and Γ is the set of entities which satisfiesV=∪γi∈Γγi,γi≠0 andγi∩γj=0for all 1≤i<j≤|Γ|.A∈R|V|×|V|is the adjace⁃ncy matrix for the state network.We require that Aij=0 if∃γkso that vi,vj∈γk,because there should be no links within a single entity.For convenience,we define sias the entity index of vi,i.e.si=j only if vi∈γj.
Fig.2 shows the configuration of a state network.In this net⁃work,there are four entities,γ1to γ4,marked as ovals in the bottom and for every entity,there are several states,marked as circles.The dotted lines in Fig.2 show the belonging relation⁃ship between states and entities.
With the definition of state network we can give the defini⁃tion of communities.In our network,communities are defined as unoverlapped sets of states.In Fig.2,there are two state communities,one marked with light gray and another is marked with dark gray.States belonging to γ2are divided into two different communities.This overlap is due to the disparity of interaction of γ2between v2,v3and v4,v5.States in γ2with LID are explicitly separated in this model.
However,when two states in one entity do not show signifi⁃cant LID,these two states should not be separated into two communities,which do not show explicitly in our model.
2.3 Modularity for State Network
Now that we have our state network,we need to define a quality function for community division.We use Newman’s modularity to evaluate the quality of community detection in our state network.In[11],Newman’s modularity calculates the difference between the real adjacency matrix and a null model,and the null model is a randomized graph where nodes are reconnected with a property proportional to their degrees and thus community structure is removed.The expression of Newman’s modularity is shown below.
The definition of state network we defined above is actually a multipartite network with no edges between states within the same entity.Given this property,we modify the definition of null model to make sure that no links exist between nodes with⁃in the same state.Note that termkikj/4m2in Newman’s mod⁃ularity in(1)show that in the original null model,the probabili⁃ty that two nodes connect together is proportional to the num⁃ber of stubs(i.e.,half⁃edges)they own respectively.In our mod⁃ification of modularity,we use this idea to define modularity on state networks.Given that number of pairs of stubs is:
and for every pair of nodes viand vj,the number of stubs each node own are kiand kj,we can have our modularity for state net⁃ works defined as:
The multiplier 1⁃δsi,sjmeans that,for states within one enti⁃ty,the probability that two states links is equal to 0.
With the definition of modularity,we can discover communi⁃ties within our state network by maximizing Qb.In addition,we can also discuss the problem in Section 2.2.Given that direct⁃ly bridging LID and modularity is not easy,we turn to solve an alternative problem,which is given as Theorem 1.
Theorem 1.Merging states i and j in a state network with δsi,sjδci,cj=1 does not affect Qb,which means that optimal commu⁃nity division is stable against merge and separation of states.
The proof of this theorem can be simply done by calculating the new modularity value after merging i and j.This theorem guarantees that separating and merging states in one entity within the same community does not change the value of modu⁃larity.That is,multiple states for one entity in the same group do not affect community discovery.
The last step is to show that the problem of maximizingis NP⁃hard.For a random graph,we assume that every node is a single state entity.In this case, Mc=4m2and.As stated by Brandes et al.[12],modularity maximization on undirected network is NP⁃hard,hence maxi⁃ mizing our modified modularity is also NP⁃hard,asis a constant for a fixed graph.
2.4 Problem Definition
We give a formal definition of the problem we need to solve. Suppose that we have a database D with records in vectors like<ui,li,t,uj,lj,t,t>,where<ui,lit>denotes person uiin loca⁃tion li,twhile person ujin location lj,tat specific time t and they communicated.This kind of records appear in a wide scope,from mobile phone calls to check⁃in data from location⁃based social network services.Thus we define a state network as G=<V,Γ,A>,where V={<ui,lj>},γi={<ui,lj>}and Apq=|{t|∃<ui,li,t,uj,lj,t,t>s.t.<ui,li,t>=vpand<uj,lj,t>=vq}|.We need to discover a community division C that maximizes Qbas is de⁃fined in(3).As is stated in Section 2.3,maximizing Qbis an NP⁃hard problem.
3 Algorithm
We first discuss the spectral algorithm for state networks,SASN,then the greedy algorithm for state networks,GASN. We combine these two methods together with integrated LID information to create a hybrid community detection algorithm(HCD).
3.1 Spectral Algorithm for State Networks
SASN is based on Newman’s work[13],which is a popularapproach to calculating optimal community discovery results. In that work,the basic steps of the algorithm is to perform bina⁃ry divisions,while each division step is done by calculating S that maximizes ΔQ=Tr(STB(C)S)and divide given signs of S,where B(C)is the generalized modularity matrix defined as
The method is a spectral method because S is computed via eigen decomposition of Bij(C).
For SASN,we need to calculatefor MSN and then fol⁃ low the framework of the original iterative division framework. Given that existing implementations of the spectral approach,such as the igraph package[14],use Lanczos algorithm to solve eigenvectors of modularity matrices,and in Lanczos algo⁃rithm,all we need to compute eigenvectors of a matrix M is to define a function multiplying M with a random vector S[15],we provide the result of multiplication for Bb(C)S instead of Bb(C)for SASN as follows:
As there is no overlap between states,the complexity to com⁃ puteis O(n).Hence,the total time complexity is O(kn),where k is the number of iterations.
3.2.Greedy Algorithm for State Networks
Given that in SASN,iteration number of k can be quite large,we need to find a faster algorithm.Therefore we propose an algorithm base on FastGreedy algorithm proposed by New⁃man and Girvan[13],which is often used as a fast approach to⁃wards large⁃scale networks.This algorithm initializes every sin⁃gle node as a community and then iteratively merge connected community pairs with maximal value of ΔQCu,Cv=1/2m(euv-auav/2m).This value computes the gain when communities Cuand Cvare merged.In our work,as we use MSN instead of original modularity,ΔQCu,Cvcan be computed as(7).
We improve the performance of this algorithm and derive GASN by exploiting the properties of item DCu,Cv.We notice thatif and only ifWe say that in this case,entity p is shared by Cuand Cv.This property shows that an entity is affected if and only if it is shared by different communities,which give us a way to opti⁃mize the naive algorithm.
We generate an entity clique graph(ECG)to help us comput⁃ing DCu,Cvefficiently.An ECG is a multigraph where every node denotes a community and every edge means that there is one entity shared by two communities.Given this definition,there can be multiple edges between two nodes denoting multiple en⁃tities shared by two communities,each representing one entity. We denote these edges as(u,v,p),meaning that entity p is now shared by Cuand Cv.What’s more,nodes in ECG form a clique when they shared states from one entity.Ifand only if there is an edge(u,v,p)exists for entity γpconnecting nodes representing Cuand Cv.
In many implementations of FastGreedy algorithms,such as Newman and Girvan’s original work[13],Wakita[6]and Schuetz’s optimized version[16],there are two fundamental steps:the update step and the merge step.In the update step,Δ QCu,Cvis updated for every community pair affected by the merge.That is,if one community in a community pair is merged by a community outside the current pair,its Δ Q should be updated for further merges.In our algorithm,an ex⁃tra item,DCu,Cv,is calculated and added to the original ΔQ.The update step is shown in detail in Algorithm 1.
Algorithm 1.Update Step in GASN
In the merge step,two selected communities are merged intoone community.In this step,atandare updated given the merge from Cfto Ct.The merge step for GASN is shown in Al⁃gorithm 2.
Algorithm 2.MERGE_PAIR(vf,vt)
We analyze the efficiency of the algorithm within Newman and Girvan’s original FastGreedy framework(NGFG)because existing derivative works only have difference in time costs in constant multipliers,and it is easy to replace update and merge steps in these algorithms with GASN.In NGFG,only one community pair with maximum Δ QCu,Cvis selected and merged,while all ΔQCu,Cwand ΔQCv,Cwvalues are updated to re⁃flect the merge.The merge continues until Q stops to increase,or there is only one community left.The election of maximum ΔQ takesO(nl ogn)if a max⁃heap is used.
Then we analyze the complexity of update and merge steps,which is based on the dendrogram of merges.The merge depth is defined as the maximal depth of two nodes involved in the merge.It is easy to see that communities never overlap in merg⁃es with same depth,which provide us convenience for the anal⁃ysis of the update step.For update steps in merges with same depth,number of edges updated can be at most 2|E|,as one edge in state network can be updated at most twice.It is the same for ECG.Therefore the time complexity for update steps in merges with the same depth is O(|E| log|E|)+O(|EECG|log|EECG|logn)if efficient lookup data structures are employed.Therefore the total time cost for the update step isO(|E| dlog2n)for the whole algorithm,where d is the depth of dendrogram.For the merge step,the most time⁃consuming step is to calculate,and this can take O(|EECG|log|EECG|)for the whole algorithm.Summing all these up we get the whole computation complexity as O(|E| dlog2n).Given that in a real scenario,|γi|can be rel⁃atively small,|EECG|≤∑1≤p≤|Γ||γp|2≤O(n).Hence the e⁃xpression of complexity can be further simplified to O(|E| dlog2n),which is significantly less than the naive ap⁃proach.
3.3 Hybrid Community Detection
SASN runs quite slowly because there can be a large num⁃ber of iterations before it converges.On the other hand,GASN can be quite biased as it might generate many communities with only one or two members,even if heuristics efforts such as that introduced by Schuetz et al.[16]to balance the merge are taken.We get an applicable method for large networks with high quality.It is common for people to behave differently in different places,which naturally led to different communities. This LID feature can be made use of in our algorithm.
To take advantage of the LID feature,we combine SASN and GASN to create a hybrid community detection algorithm with two stages for the proposed state network.The first stage is called the conglomerating stage,where GASN is used to con⁃glomerate all the states into communities.In this stage,LID in⁃formation is used to stop two communities from merging if these two communities both have states from one entity and show significant disparity in interaction.This guarantees that at the end of the execution of GASN,the network is divided in⁃to several small fragments,not merely one large network.The second stage is called the divisive stage,where SASN is exe⁃cuted on every divided fragment of the network to get refined results.Given that each fragment is significantly smaller than the original network,SASN can run much faster than running on the original data set.The algorithm framework is shown in Algorithm 3.
Algorithm 3.Hybrid Community Detection
1:Initialize every state node as one⁃node communities.
2:Calculate ΔQuvfor every edge(u,v)and push into a heapH.
3:whileH≠∅do.//The conglomerating stage
4:Pop(t,f)with maximal ΔQtf.
5:if(t,f)is inhibited by known LID info then
6:H←H-{(t,f)}
7:continue
8:end if
9:if ΔQtf<0 then break
10: Update Pair(vf,vt)
11: Merge Pair(vf,vt)
12:end while
13:repeat//The divisive stage
14:Get the largest fragment asC
15: (λ,V)=Eigen(Bb(C))
16: ifλ1<0 then break
17: DivideCgiven positiveness of V1
18:until enough number of communities generated
4 Experiments
In this section,we evaluate the efficiency and correction of SASN,GASN,and HCD.Typically,it is not possible for a real⁃world network to provide data on community membership;thus,we first conduct experiment on the synthesis network to evaluate the correctness of these algorithms.Then we turn to real⁃world data to evaluate the efficiency of these algorithms aswell as the features extracted by these algorithms.
4.1 Experiments on Synthesis Data
We build stochastic networks for the experiment.These net⁃works all have 2000 state nodes.These nodes are divided into 10 communities and every community has 200 states.We cre⁃ate links within these communities with probability pi=30% and links between different communities with varying po,which will be shown later.Furthermore,we put all these state nodes into 1400 entities.700 entities have only one state,400 enti⁃ties have two,while the rest have three.The reason for the enti⁃ty sizes is that in real⁃world networks,more users tend to have a few locations of interest,while some users can have many such locations.The state⁃entity relationship is generated ran⁃domly.Finally,we pick state nodes within one entity but as⁃signed to different communities and randomly select 50%of them to form an LID pair set.Normalized mutual information(NMI)[17]is used to measure the clustering performance of al⁃gorithms.The value of NMI ranges between 0 and 1,and a larg⁃er NMI indicates a better clustering result.When NMI=1,two communities are exactly the same.
We vary pofrom 0.0025 to 0.025 with a 0.0025 step to create networks with different density of edges outside the communi⁃ties.For every algorithm and every posetting,we generate and execute our algorithm 50 times to get an average performance. When po=0.0025,the community structure is quite explicit. However,when po=0.025,for communities with 200 nodes,number of expected edges from the same community is close to the number of expected edges from the whole network.Thus the community structure is not so explicit.
Fig.3a shows the clustering performance in terms of NMI. Three lines from top to bottom show the performance for HCD,GASN and SASN,respectively.HCD performs the best,and SASN performs the worst.This can be explained by the power of LID.For GASN the performance is good for small po.Howev⁃er,the result deteriorates to the level of SASN when more noise is added to the network.We investigate the result of com⁃munities generated by GASN and discover that when the net⁃work densifies,FastGreedy became so biased that small com⁃ munities with only one or two members were generated,which hamper the performance.We also mark variance for every data point.HCD is the most stable method of all three algorithms when the network is sparse,which is guaranteed by its divisive step.
Fig.3b shows the running time for these three algorithms. HCD runs slower than GASN,as it needs more computation on division step.But HCD still outperforms SASN in sparse net⁃works,as the fragment to be divided by spectral method is smaller than the original SASN.When the network becomes denser,time cost of HCD grows because more ΔQ on edges need to be updated,and the size of fragments of the network generated by the conglomerate step grow.This leads to slower convergence of divisive step.These results show that HCD out⁃performs other algorithms referred to in our experiment espe⁃cially in sparse networks.As real⁃world networks are mostly sparse,HCD is more competitive than other methods.
4.2 Experiments on Real-World Data
After evaluating our algorithms on synthesis network,we evaluate our algorithm on real⁃world data sets.Our data are collected from cellphone call records in a medium city in Chi⁃na with a population of about 400,000 in 14 days.Different from data used in other researches,phone records in our phone call record contain cell information for both the calling and called people.We also obtained information on virtual phone networks(VPN)users join.These VPNs are user groups estab⁃lished by companies for their employees to enjoy free calls within the company,which provide us another source of valida⁃tion of user belongings.
We first extract telephone calls from the largest four VPNs to conduct our experiments.We define every user as an entity and every user⁃location pair as a state node if the user has made more than five calls in this location.Given that there can be a number of disconnected components in the extracted graph,we take the largest connected component for the subse⁃quent analysis.This component has 5927 state nodes,3364 en⁃tities and 8571 edges.Fig.4a shows that degree distribution of this component observes power law.Therefore this component is a typical complex network.Fig.4b shows the number of states owned by entities.Most of the people only make phone call frequent⁃ly in one single place while some people make phone calls in different places.
We also evaluate the number of links be⁃tween different VPNs and the result is shown in Table 1.We can see that the number of links inside a VPN is larger than the number of links outside a VPN.This means that VPN data in our dataset have some properties as communities,which can be taken advantage of to evaluate our algorithm.

▼Table 1.Links between VPNs
First,we borrow the conception of NMI. Given that traditional definition of NMI by Strehl et al.[17]on⁃ly takes unoverlapped communities into account,we instead propose an extended version of NMI that takes overlaps in our model into account.Given one divisions of state networkand another division of entity network,our extended version of NMI can be calc⁃ ulated as follows:
where
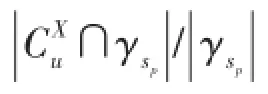
We conduct experiment on this of network by using HCD al⁃ gorithm as we have proved that HCD outper⁃forms other algorithms on synthesis data,and LID set generated from user’s calling behav⁃ior in different locations and selected with Kendall’sτwith 95%confidence.First,we show the correctness of communities generat⁃ed with HCD on state networks.We vary the number of communities to be generated and run traditional spectral algorithm on entity network and HCD on state networks because there is no inhibition information available in entity network.Extended NMI is computed for community number from 50 to 200 be⁃ tween discovered communities and VPN data,and the result is shown in Fig.5a.Communities generated from state network have slightly higher NMI than entity network.Thus HCD on state network is slightly better than original approaches.
Then we investigate the communities owned by users.As is shown in Fig.5b,many users only belong to one single commu⁃nity,and the rest belong to multiple communities.This result shows that many users belong to different communities in dif⁃ferent locations.To illustrate this more explicitly,we investi⁃gate these communities by case study.
We extract phone call records within every community and calculate histograms of these calls for every community and then put these histograms into clusters by cosine distances. From these clusters,we observed two different types of commu⁃nities:daytime,where phone calls are mostly made during the day,and nighttime,where calls are made at night.These two types of communities reveal different activity patterns of peo⁃ple.Given that in our work,one person can belong to multiple communities,it is natural that they might belong to daytime communities and night communities simultaneously.There are 157 people who belong to both daytime clusters and night clus⁃ters.Fig.6 shows two communities of one single user.The his⁃togram on the left is a typical daytime community,while the one on the right is a night community showing that one user have different social circle in different time.
As we generate states by locations,we also analyze the loca⁃tions of these nodes.We have already noted that users have dif⁃ferent contact behavior in different places;thus,people should have different communities in these places.In our result,we see 75.6%O⁃D pairs are separated in different communities in the result of HCD.Fig.7 shows the locations of one single user appeared in a map.According to the method proposed by Huang et al.[9],to mark O and D of users,two locations in the bottom⁃right corner was recognized as O and D of one user. However,in the result generated by HCD,we can see two com⁃munities:C147in the top⁃left corner of the map and C169in the bottom⁃right corner.Two locations in C169recognized as differ⁃ent locations are actually in one community in our result.Look⁃ing up information on the map,we discover that the bottom⁃right corner is a residential area,and the top⁃left corner has apower plant.Phone call record also reveal that time of calls the user made in the bottom⁃right corner varies through all the day,and the time of calls made in the top⁃left corner are all in working hours.This show that locations on the top⁃left corner are more likely to be work locations,while the bottom⁃right to be home locations.This show that community discovery in MSN can discover communities with location properties.
Finally we investigate the scalability of our algorithms.We merge nodes from the largest VPN to the smallest and form 10 networks sizing from 5881 to 88427 and run SASN,GASN and HCD on these networks.In Fig.8,SASN run fastest,while HCD run slower,as it need to split large communities in the di⁃visive stage.SASN run slowest,and its time cost become intol⁃erable as the number of states grow larger than 5×104.The re⁃ sult shows that HCD can run efficiently with higher accuracy and acceptable time cost comparing to GASN.
5 Related Works
There have been many existing works studying the relationship between social links and locations of social actors.Eagle et al.[18]and Li et al.[7]measure user similarities giv⁃en locations or trajectories of users.The Meth⁃od proposed by these authors can achieve sat⁃isfactory results on link prediction.Cho et al.[8]study the differences between trajectories caused by activity patterns of users and trajec⁃tories caused by movements of users,and then create a model of user mobility given link information.However,most of these works are only concerned with local informa⁃tion,i.e.,trajectories and friends of one single user.
Another related field is the modification of modularity to find communities.There have been many attempts to extend modularity in(1)for specific types of graphs.Barber et al.[19]extend modularity from normal graphs to bipartite graphs by restricting links between nodes with different colors in the null model. Mucha et al.[20]make a further step by creating a model for multi⁃slice networks.The author model temporal changes in networks by dividing the network into different slices and cal⁃culate modularity for two types of links,i.e.,links between slic⁃es and links within every slice.However,for networks com⁃bined with location information,the method to divide nodes in⁃to slices is to be studied.
Some researchers pay attention to the combination of link and content to discover communities.Gomez et al.[21]add negative links into network and modify modularity by replac⁃ing the target function with a linear combination of positivemodularity and negative modularity.Yang et al.[22]integrate content model into link analysis,which can be another method for integrating location information.
For community detection algorithms,Lancichinetti et al.[23]give a comprehensive comparison of existing community discovery algorithms.Many existing community discovery algo⁃rithms have computational complexity greater than O(n2),which mean that these algorithms are not applicable for large scale networks.Therefore we select spectral approach and FastGreedy for our work.
6 Conclusion
MSN data are now growing fast,revealing people’s interac⁃tions in different locations.In this work,we propose an ap⁃proach to detecting communities in this type of network.We observe location interaction disparity and define a state model in which states represent user⁃location tuples and entities rep⁃resent users.This model leverages location interaction dispari⁃ty.We extend traditional definition of modularity to our model and formally describe community detection problem for loca⁃tion⁃based social network.Then we modify existing spectral ap⁃proach and FastGreedy algorithm to create SASN and GASN with efficiency optimization.Given the time cost and precision of these two algorithms we propose HCD for higher precision and lower time cost.LID can be easily integrated into this algo⁃rithm as heuristics.
Experiments on synthesis data show that HCD outperforms SASN and GASN in precision.For the aspect of time cost,HCD runs slower than GASN since it uses GASN as the first step,but significantly faster than SASN when the network is sparse.This property holds both on synthesis data and real⁃world data.We show in real world data that many users belong to different communities in different places.In a case study we find that users can be in different types of communities,indi⁃cating different activities for users in different locations.
[1]M.Girvan and M.E.J.Newman,“Community structure in social and biological networks,”Proceedings of the National Academy of Science,vol.99,pp.7821-7826,Jun.2002.
[2]M.Richardson and P.Domingos,“Mining knowledge⁃sharing sites for viral mar⁃keting,”in 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Edmonton,Canada,Jul.2002,pp.61-70.
[3]L.Tang,X.Wang,and H.Liu,“Uncovering groups via heterogeneous interac⁃tion analysis,”in 9th IEEE International Conference on Data Mining,Miami,USA,Dec.2009,pp.503-512.
[4]H.Kang,L.Getoor,and L.Singh,“Visual analysis of dynamic group member⁃ship in temporal social networks,”Sigkdd Explorations,vol.9,no.2,pp.13-21,Dec.2007.doi:10.1145/1345448.1345452.
[5]M.E.J.Newman and M.Girvan,“Finding and evaluating community structure in networks,”Physical Review E,vol.69,026113,2004.doi:10.1103/Phys⁃RevE.69.026113.
[6]K.Wakita and T.Tsurumi,“Finding community structure in mega⁃scale social networks,”in 16th International Conference on World Wide Web,Banff,Canada,2007,pp.1275-1276.doi:10.1145/1242572.1242805.
[7]Q.Li,Y.Zheng,X.Xie,et al.,“Mining user similarity based on location histo⁃ry,”in 16th ACM SIGSPATIAL International Conference on Advances in Geo⁃ graphic Information Systems,Irvine,USA,Nov.2008,no.34.doi:10.1145/ 1463434.1463477.
[8]E.Cho,S.A.Myers,and J.Leskovec,“Friendship and mobility:user movement in mobile social network,”in 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Diego,USA,Aug.2011,pp.1082-1090.
[9]W.Huang,Z.Dong,N.Zhao,et al.,“Anchor points seeking of large urban crowd based on the mobile billing data,”in 6th International Conference on Advanced Data Mining and Applications,Chongqing,China,Nov.2010,pp.346-357.
[10]M.G.Kendall,“A new measure of rank correlation,”Biometrika,vol.30,no.1/ 2,pp.81-93,1938.
[11]M.E.J.Newman,“Detecting community structure in networks,”The European Physical Journal B Condensed Matter,vol.38,no.2,pp.321-330,Mar.2004.
[12]U.Brandes,D.Delling,M.Gaertler,et al.,“On modularity clustering,”IEEE Transactions on Knowledge and Data Engineering,vol.20,no.2,pp.172-188,Feb.2008.
[13]M.E.J.Newman,“Finding community structure in networks using the eigen⁃vectors of matrices,”Physical Review E,vol.74,036104,Sep.2006.doi:10.1103/PhysRevE.74.036104.
[14]G.Csardi and T.Nepusz,“The igraph software package for complex network re⁃search,”Inter Journal Complex Systems,no.1695,2006.
[15]G.H.Golub and C.F.Van Loan,Matrix Computations,3rd ed.Baltimore,USA:Johns Hopkins University Press,1996.
[16]P.Schuetz and A.Caflisch,“Efficient modularity optimization by multistep greedy algorithm and vertex mover refinement,”Physical Review E,vol.77,046112,2008.doi:10.1103/Phys Rev E.77.046112.
[17]A.Strehl and J.Ghosh,“Cluster ensembles— a knowledge reuse framework for combining multiple partitions,”The Journal of Machine Learning Research,vol.3,pp.583-617,Mar.2003.doi:10.1162/153244303321897735.
[18]N.Eagle and A.Pentland,“Eigenbehaviors:identifying structure in routine,”Behavioral Ecology and Sociobiology,vol.63,pp.1057-1066,2009.
[19]M.J.Barber,“Modularity and community detection in bipartite networks,”Physical Review E,vol.76,066102,2007.doi:10.1103/PhysRevE.76.066102.
[20]P.J.Mucha,T.Richardson,K.Macon,et al.,“Community structure in time⁃de⁃pendent,multiscale,and multiplex networks,”Science,vol.328,no.5980,pp. 876-878,May 2010.doi:10.1126/science.1184819.
[21]S.Gomez,P.Jensen,and A.Arenas,“Analysis of community structure in net⁃works of correlated data,”Physical Review E,vol.80,016114,2009.doi:10.1103/PhysRevE.80.016114.
[22]T.Yang,R.Jin,Y.Chi,and S.Zhu,“Combining link and content for communi⁃ty detection:a discriminative approach,”in 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Paris,France,2009,pp. 927-936.doi:10.1145/1557019.1557120.
[23]A.Lancichinetti and S.Fortunato,“Community detection algorithms:a compar⁃ative analysis,”Physical Review E,vol.80,056117,2009.doi:10.1103/Phys⁃RevE.80.056117.
Manuscript received:2015⁃04⁃21
Biographiesphies
Danmeng Liug Liu(liudanmeng@pku.edu.cn)received his Bachelor degree from Wuhan University.He is a Master candidate at school of School of Electronic Engineering and Computing Science,Peking University.His research interests include data min⁃ing and social network analysis.
Wei Weii Wei(wei.wei118.zte.com.cn)received her MS degree in communication and in⁃formation engineering from Chongqing University of Posts and Telecommunications. Her research interests include location technology and business intelligence.
Guojie Song Song(gjsong@pku.edu.cn)is an associate professor of the School of Electron⁃ic Engineering and Computing Science,and vice director of Research Center of In⁃telligent Information Processing,at Peking University.He received the PhD degree from Department of Computer Science,Peking University in 2004.He is currently interested in various techniques of data mining,machine learning,as well as their applications in intelligent traffic system,and social networks etc.
Ping Lung Lu(lu.ping@zte.com.cn)received his ME degree in automatic control theory and applications from South East University.He is the chief executive of the Service Institute of ZTE Corporation.His research interests include augmented reality and multimedia services technologies.
This work is supported by the National High Technology Research and Development Program of China under Grant No.2014AA015103,Beijing Natural Science Foundation under Grant No.4152023,the National Natural Science Foundation of China under Grant No.61473006,and the National Science and Technology Support Plan under Grant No.2014BAG01B02.

- ZTE Communications的其它文章
- Using Artificial Intelligence in the Internet of Things
- I2oT:Advanced Direction of the Internet of Things
- An Instance⁃Learning⁃Based Intrusion⁃Detection System for Wireless Sensor Networks
- Forest Fire Detection Using Artificial Neural Network Algorithm Implemented in Wireless Sensor Networks
- WeWatch:An Application for Watching Video Across Two Mobile Devices
- A Parameter⁃Detection Algorithm for Moving Ships