
集群风电场出力统计指标建模与应用
2015-09-21 10:07卞海红郑维高林章岁徐青山
电力自动化设备 2015年12期
卞海红,郑维高,林章岁,徐青山,张 乐
(1.南京工程学院 电力工程学院,江苏 南京 211167;2.东南大学 电气工程学院,江苏 南京 210096;3.国网江苏省电力公司检修分公司南京分部,江苏 南京 211102;4.国网福建省电力有限公司经济技术研究院,福建 福州 350003;5.国网江苏省电力公司南通供电公司,江苏 南通 226006)
0 引言
由于受到自然特性、地理环境、风电场自身条件等因素影响,风电出力表现出随机波动性。随着大规模风电并网,风电集群的波动特性研究对于电力系统运行和规划意义重大,引起了广泛的关注和研究兴趣,国内外针对风电出力特性[1]、调峰特性[2]、并网影响性[3-4]、随优化调度[5]等方面进行了大量研究,并取得了丰硕的成果。同时,风电规划、并网评估、电力市场等相关问题的研究对风电出力数据信息的需求越来越大,尤其是未来集群风电场景出力信息。然而,通过单个风电场出力简单倍乘的方式来获取任意容量集群风电出力容易忽略平滑效应[6]。如何快速准确地构建适应集群风电规模发展的出力概率模型,并通过建立的概率模型模拟生成风电出力数据是一个基础研究环节,具有重要的研究实用价值[7]。
不同时间尺度下的集群风电场出力概率分布特性会存在一定差异性[8],只有在理想的地理空间分布情况下集群风电场出力才近似呈现正态分布,但是在大多数风电场景中发现运用β分布拟合集群风电场出力概率分布要比正态分布更加准确[9],本文在此基础上引入偏度、峰度[10]这2个表征风电波动特性曲线分布形状的统计学指标,提出基于均值、标准差、偏度和峰度这4个统计性指标的皮尔逊族分布建模,涵盖典型常见概率分布模型,如正态分布、β分布、γ分布等Ⅰ型至Ⅶ型7种分布模型。基于指标的皮尔逊族建模可以有效模拟未来风电集群实际出力场景,生成风电出力随机数据,得到风电出力持续曲线,为风电集群运行规划、波动性分析等提供有效分析手段,同时也丰富了风电统计指标体系[11],为定量分析风电出力的波动特性提供了指标基础。
集群风电场出力波动平滑性与风电场间相关系数密切相关,当风电场地理比较靠近、基本处于同一风带时,风电场的出力相关性较强;当风电场地理位置相距较远时,风电场的出力相关性变弱,风电场出力之间波动性相互抵消,使得该区域集群出力波动性减弱[12],随着集群区域规模的扩大和风电场数量的增加,平滑效应表现越显著[13-14]。 文献[15]重点分析了北欧风电集群相关性和地理分散表现出的平滑性,指出了风电场间相关系数与场间距成指数级衰减,进一步说明了不同时间尺度衰减特性存在差异,并给出根据年出力时间序列计算风电场间相关性的方法。文献[16]提出了平滑效应简单量化分析方法,引入了皮尔逊相关系数进行计算,但是只局限于风电场间相关系数计算,未能对相关性进行建模研究。因此本文建立了单个风电场和集群风电场出力的中心矩关系,引入定量分析平滑效应的中心距因子,并依据典型风电场集群历史风电出力数据分析挖掘经验,建立风电场间相关系数与风电场间距离的指数关系方程,给出区域风电场各阶标准差与年平均出力之间的函数关系方程,建立了指标参数估算模型,在保证一定精度的情况下简化了风电场集群区域内风电场间相关系数和各阶标准差的计算。
本文最后根据福建省风电场集群2013年全年出力时间序列数据计算风电场均值、标准差、偏度和峰度4个指标,然后基于4个统计性指标,利用MATLAB的pearsrnd函数实现皮尔逊族分布函数建模,模拟生成风电出力随机数据,并从风电出力累积概率曲线和持续曲线2个角度对比分析皮尔逊族建模的准确性和实用性;通过福建省2010—2012年年度风电历史出力时间序列数据和其典型风电集群地理特征信息的分析计算,应用最小二乘法确定所有待定参数,建立具体估算模型,分别用建模法和直接法计算出标准差、偏度、峰度3个波动性指标,然后对比分析得到的模拟值和测量值结果,验证了指标参数估算模型的准确性。
1 基本原理和数学模型
1.1 高阶中心矩和中心矩因子
风电出力的波动性,可以用波动量均值、相对波动量、波动量标准差等指标来表征,其中波动量均值是描述风电出力时间序列集中趋势的指标,相对波动量、波动量标准差等是描述其离散程度的指标。为了引入描述其分布形状的指标——偏度和峰度,本节给出区域集群风电场与单个风电场出力的二阶中心矩、三阶中心矩、四阶中心矩数学关系表达式[17]。
将区域风电场集群各个风电场出力时间序列看作是彼此相关的随机变量,首先介绍衡量单个风电场出力波动性的标准差,即:
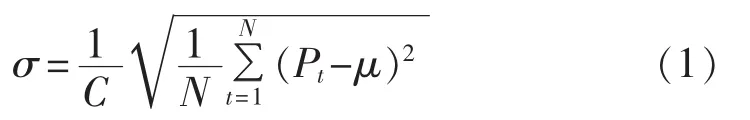
其中,C为风电场的额定安装容量;N为采样时刻总数;Pt为t时刻的采样功率值;μ为风电场出力采样均值。
然后给出区域风电场集群出力相对值P与单个风电场出力相对值Pi的函数关系式:
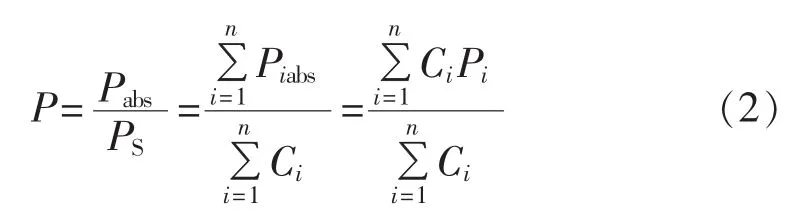
其中,PS为区域风电场集群额定安装容量;Pabs为区域风电场集群出力绝对值;Piabs为单个风电场出力绝对值;Ci为区域单个风电场额定安装容量;n为区域风电集群包含的单个风电场数量。
如果区域单个风电场额定安装容量相同,式(2)可简化为:

式(2)和(3)同样适用于利用单个风电场出力均值计算区域风电场集群出力均值。
为了建立区域集群风电场与单个风电场出力的高阶中心矩关系模型,需要确定各风电场间相关系数,以2个风电场出力时间序列分别作为随机变量X、Y,给出皮尔逊相关系数计算公式[18]:
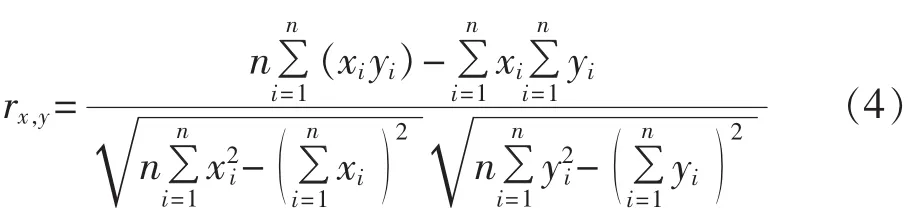
然后定义区域风电场集群出力的二阶中心矩数学表达式:
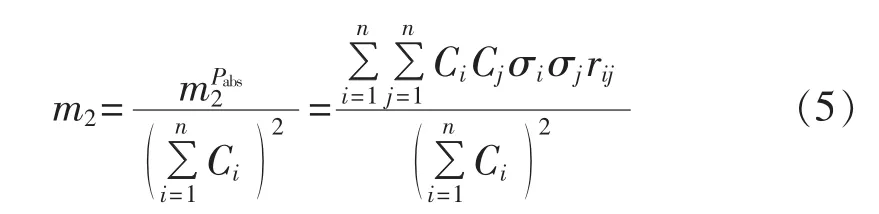
为了便于解耦标准差与相关系数,假设区域风电场集群内各个风电场额定安装容量均相等,标准差均为σ,上式可简化为:
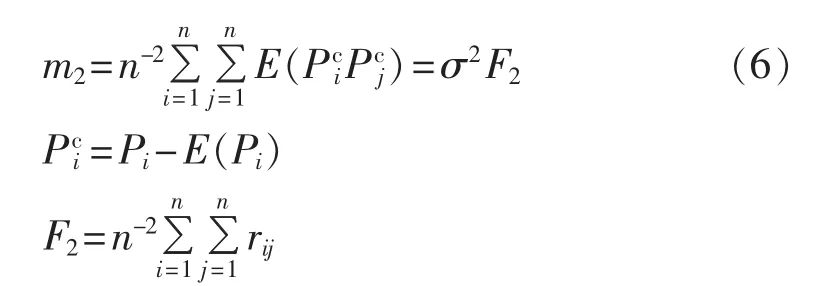
其中,rij为风电场i和风电场j间的互相关系数;Pci为单个风电场出力中心化变量;F2为二阶中心矩因子。当已知标准差σ和F2时,可以求出二阶中心矩m2,这样就得到了区域风电集群波动相对波动值。
同理给出区域风电场集群出力的三阶中心矩和四阶中心矩数学表达式:
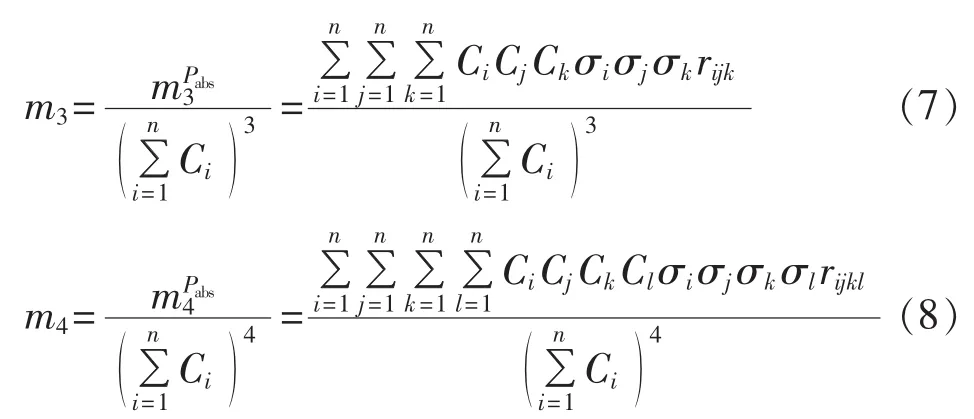
其中,σi为第i个风电场出力的标准差。
同理假设,式(7)、(8)可分别简化为:
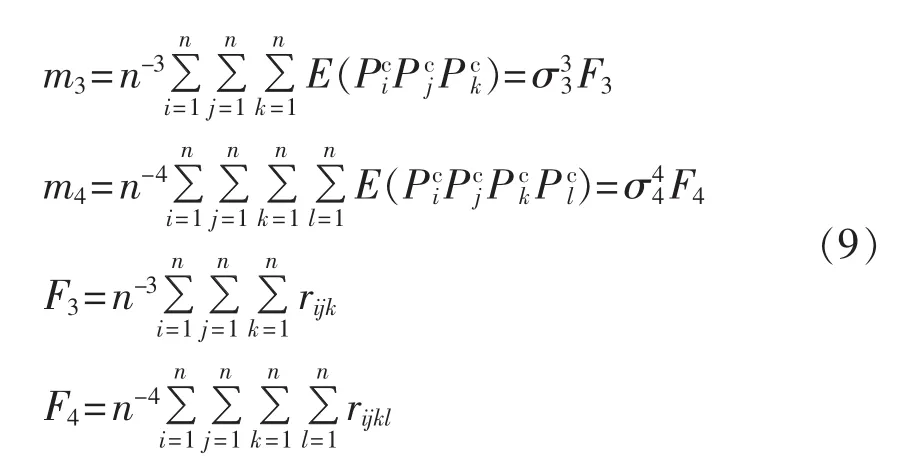
其中,F3、F4分别为三阶中心矩因子和四阶中心矩因子;rijk为 3 次互相关系数,rijkl为 4 次互相关系数[19],这些高阶互相关系数均可以通过相关性分析工具计算得到,进而可以求得中心距;σ3、σ4与标准差σ类似,称为“高阶标准差”,但是具体定义存在差异。
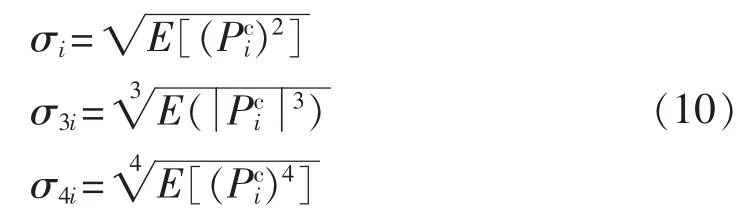
其中,σ3i和σ4i为第i个风电场出力的高阶标准差。
进一步变换式(6)和式(9)可得:
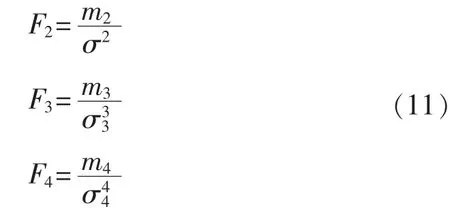
通过式(11)易知,高阶中心矩因子可以作为量化集群风电出力波动性的有效指标。当F2<1时,表征单个风电场集群化后波动性变弱,表现出风电集群的平滑效应,高阶中心矩因子数值越小,说明风电集群波动的平滑效应越强。
1.2 波动性统计指标
根据区域风电场集群的中心矩因子和各阶标准差,可以求出二阶中心矩m2、三阶中心矩m3和四阶中心矩m4,式(12)给出了区域风电集群出力波动性统计指标——标准差αstd、偏度αskew和峰度αkurt的定义表达式:

标准差是表征集群风电场出力平稳性的重要指标,标准差越小表示风电出力越平稳、波动越小,这意味着风电并网对电力系统造成的影响越小。偏度表征集群风电出力波动分布的偏斜度,若其偏度为正,则表示相比标准正态分布,其峰度偏向较小数值方向;偏度为负,则表示相比标准正态分布,其峰度偏向较大数值方向。峰度表征总体离群数据的离群程度,若其峰度值大于3,则表示出力波动分布曲线为尖峰分布;若其峰度值小于3,则表示出力波动分布曲线为平峰分布。偏度和峰度是表征集群风电场出力波动分布的重要指标。
1.3 皮尔逊分布族模型
皮尔逊微分方程依据a、c0、c1和c2不同参数取值可以求解得到不同的概率密度函数,进而构成皮尔逊分布族,具体皮尔逊微分方程表达式为[19]:
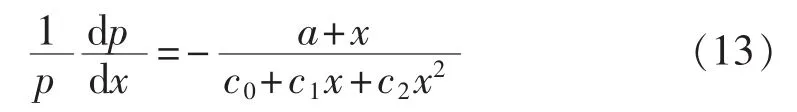
由皮尔逊微分方程建立的分布族包括Ⅰ型至Ⅶ型的7种基本分布,涵盖任意给定均值、标准差、偏度和峰度,共同构成了四参数分布族,包含了常见的基本分布,如正态分布、Student’s t分布、γ分布和β分布,其中β分布属于Ⅰ型分布,γ分布属于Ⅲ型分布,正态分布和t分布属于Ⅶ型分布。皮尔逊分布族能够拟合各种基于一阶、二阶、三阶和四阶刻画的分布形状。具体给出上述3种类型概率分布函数表达 式[20]。
Ⅰ型概率分布函数为:
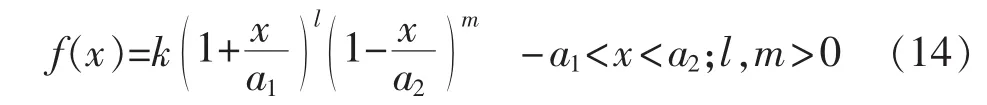
Ⅲ型概率分布函数为:
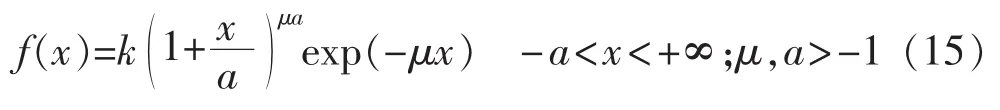
Ⅶ型概率分布函数为:
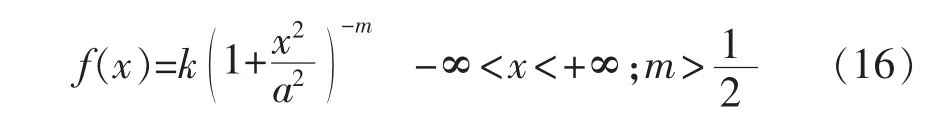
基于均值、标准差、偏度和峰度4个指标参数,可以构建表征集群风电场出力分布的皮尔逊族分布模型,进而能够有效模拟未来风电集群场景出力随机数据,评估区域风电集群发电量。
2 指标参数估算建模
2.1 相关系数与场间距关系建模
第1节给出了区域风电场集群标准差、偏度、峰度定义表达式和皮尔逊分布族模型,为了得出这3个典型指标,根据式(6)、(9)和(12),易知需要求解出中心矩m2、m3和m4,因此求取中间参数中心矩因子F2、F3和F4是关键,所以需要得到区域风电场集群各个风电场自相关系数和互相关系数值。由于区域风电场集群各个风电场风电出力数据存在缺失性和不易获取,以及利用SPSS Statistics 20相关性分析工具计算n2个相关系数的计算量大,为了简化相关系数计算,且不影响计算精度,需要建立相关系数的估算模型。
文献[21]定量分析了风电场地理空间分散的经济性,指出Ontario区域集群风电场间出力相关系数与距离成反比,但仍保持正相关性,并分别应用皮尔逊和Spearman rho相关系数法拟合建立了指数函数关系模型。本文依据典型风电场集群历史出力数据,计算风电场间的互相关系数,作出风电场间互相关系数与场间距(2个风电场间的中心距离)的散布图,利用Sigmaplot 13.0非线性回归对离散点作函数曲线拟合,如图1所示。其中关于相关系数计算所用风电场出力数据为各个风电场年平均出力时间序列,计算出的相关系数具有代表性,满足了计算精度要求,减少了不同时间尺度风电出力时序数据计算得到的相关系数的差异性。
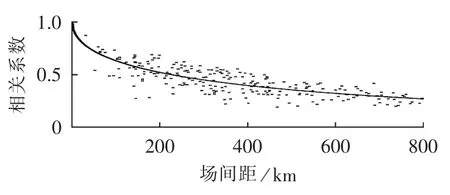
图1 相关系数与风电场间距关系散点图Fig.1 Scatter plot of correlation coefficientvs.distance between wind farms
通过非线性回归拟合关系,分析发现典型风电场集群出力相关系数与场间距离成指数衰减关系,因而经验建立了指数函数关系表达式:
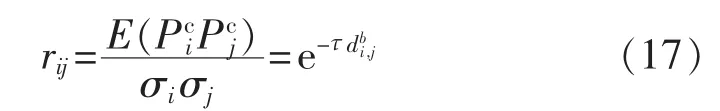
其中,自变量di,j为风电场i与风电场j的场间距;τ为指数函数表达式的衰减常数,b为指数函数表达式的拉伸指数,这2个参数均可通过最小二乘法求得。
同理可推得:
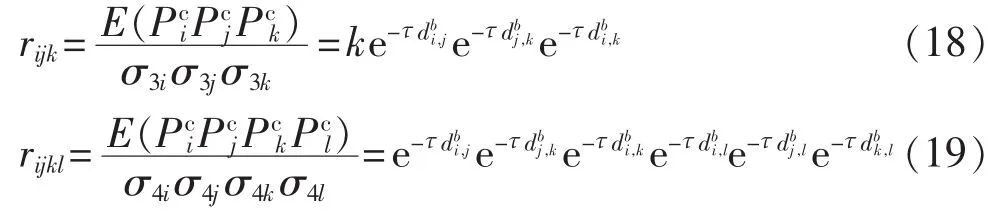
当场间矩为0时,互相关系数为1,即互相关系数变为自相关系数;当场间距趋向于无穷大时,互相关系数趋向于0。由于σ3定义时取得绝对值,所以当所有场间距均为0时,rijk不等于1,而等于系数k(0<k<1)。
通过经验建立的相关系数与场间距指数关系模型,若已知风电场间距离,可以估算得到相关系数,将所有相关系数求和得到中心矩因子。相比通过风电场出力时间序列数据运用相关性分析工具求解相关系数法,简化了计算量和复杂性,同时满足要求的计算准确度。
2.2 各阶标准差与风电场年出力均值关系建模
根据式(6)和(9),接着需要求出各阶标准差 σ2、σ33和 σ44,表达式(10)定义给出了各阶标准差的计算方法,但考虑到计算复杂性以及计算量较大,因而为了简化各阶标准差计算,而又不影响计算精度,建立各阶标准差的估算模型。根据典型风电场集群出力时间序列数据分析,作出各阶标准差与风电场年出力均值(标幺值,采用的基准值为风电场额定装机容量)的散点图,利用Sigmaplot 13.0作非线性回归的函数曲线拟合,年平均出力如图2所示。
通过非线性回归拟合,分析发现区域风电场集群出力时间序列的各阶标准差与年平均出力近似成多项式关系,经验给出两者多项式函数关系表达式:
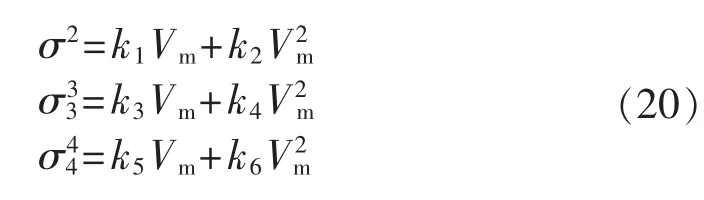
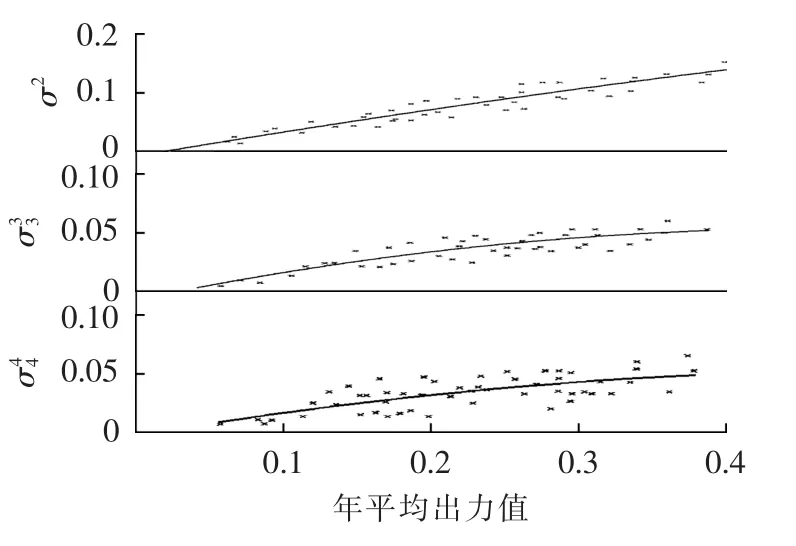
图2 各阶标准差与年平均出力关系散点图Fig.2 Scatter plot of standard deviation vs.annual average output for different orders
其中,ki(i=1,2,…,6)为多项式系数,Vm为年平均出力(折算为各自额定容量的标幺值),ki和Vm均通过最小二乘法求得。经验建立的各阶标准差与年平均出力关系的多项式模型大幅简化了各阶标准差的计算,当已知区域典型风电场集群的年平均出力值时就可以估算出各阶标准差,年平均出力值近似可由区域风电场年平均利用小时数估算得到。
3 风电场集群指标建模与算例分析
3.1 典型区域风电场集群介绍
研究对象是以福建省20个非理想均匀地理分布的风电场作为区域典型风电场集群进行研究,选取由福建省经济研究院提供的2010—2013这4个年度的集群风电场出力时序数据和风电场位置、场面积等相关地理特征信息。此外,由于福建省地处低纬度,气候受太阳辐射、台湾海峡及两侧山地地形影响和季风环流的制约,同时受海洋的调节,具有典型的亚热带海洋性季风气候特征,所以典型区域内风资源具有相似性,集群内各个风电场出力具有正相关性。其中区域风电集群中有13个风电场分布在福州、泉州、莆田等沿海地区,其相关性相比7个近内陆风电场较为显著。
3.2 区域风电场集群指标建模分析
首先通过福建省风电场集群2013年全年出力时间序列数据计算风电场均值、标准差、偏度和峰度4个指标,然后基于4个统计性指标,利用MATLAB的pearsrnd函数实现皮尔逊族分布函数建模,模拟生成风电出力随机数据,并从风电出力累积概率曲线和持续曲线2个角度对比分析皮尔逊族建模的准确性和实用性,直观展现了单个-集群风电场出力波动特性。
然后根据2010—2012年典型福建省风电场集群风电历史出力时间序列数据和地理特征信息的分析计算,应用最小二乘法确定所有待定参数,建立具体估算模型,然后将建立的估算模型用于分析典型福建省风电场集群2013年全年出力时间序列,计算得到区域风电场集群3个指标结果,称为建模结果值(简称建模值);然后通过直接法(定义法)对典型福建省风电场集群出力时间序列进行定义计算,得到区域风电集群3个指标结果,称为测量结果值(简称测量值);最后将2种不同方法得到的2组指标值进行对比分析,比较分析估算结果,验证指标参数估算模型的准确性。
根据区域风电场间距离和年平均出力(给定区域额定安装容量和总发电量),综上给出基于简化估算指标的集群风电场出力建模分析流程图,如图3所示。
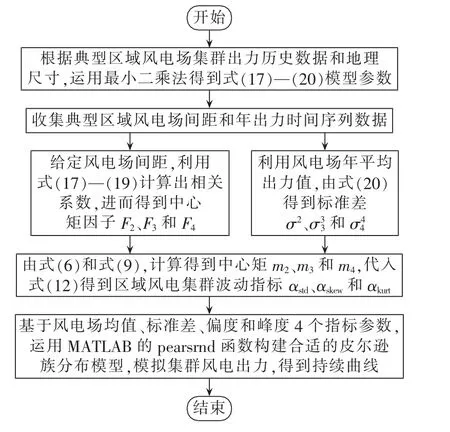
图3 典型风电场集群指标建模流程Fig.3 Flowchart of typical wind cluster index modeling
3.2.1 基于指标的皮尔逊族建模应用分析
为了效验基于均值、标准差、偏度和峰度4个指标构建的皮尔逊族分布模型的准确性和实用性,依托2013年度单个-集群风电场出力时间序列进行4个统计性指标计算,并基于得到的4个指标建模,建立了皮尔逊族I型分布——β分布,具体皮尔逊微分方程参数如表1所示。
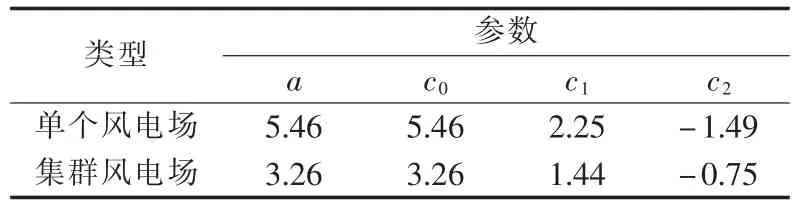
表1 皮尔逊族微分方程建模参数Table 1 Modeling parameters of Pearson family differential equations
为了进一步探究所建模型在模拟生成满足对应概率随机数据时的准确性,本文从单个风电与集群风电、实测与建模2组角度分别给出了单个-集群风电出力累积概率分布曲线和出力持续曲线,具体分别如图4和图5所示。
观察图4、5可知,无论是单个风电场还是集群风电场,基于指标建立的皮尔逊族分布模型均能较好地模拟实际风电场出力概率分布特性和出力持续曲线,并且一定程度上对比表征了单个风电和集群风电出力波动性的强弱[14]。
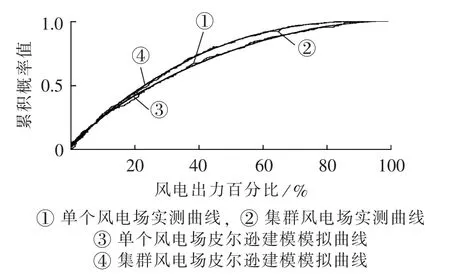
图4 单个-集群风电出力累积概率分布曲线Fig.4 Cumulative probability distribution curves of single wind farm output and wind farm cluster output
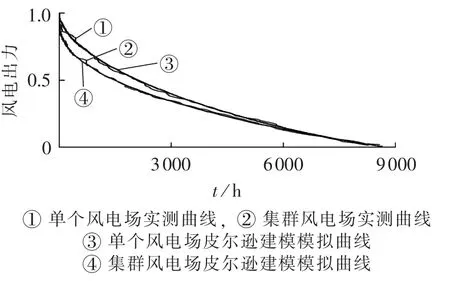
图5 单个-集群风电出力曲线Fig.5 Curves of power output vs.duration for single wind farm and wind farm cluster
3.2.2 估算指标结果准确性分析
依据典型福建省风电场集群2010—2012这3年风电出力时间序列数据分析和地理特征信息,应用最小二乘法,计算得到模型的相关待定系数,如表2所示。
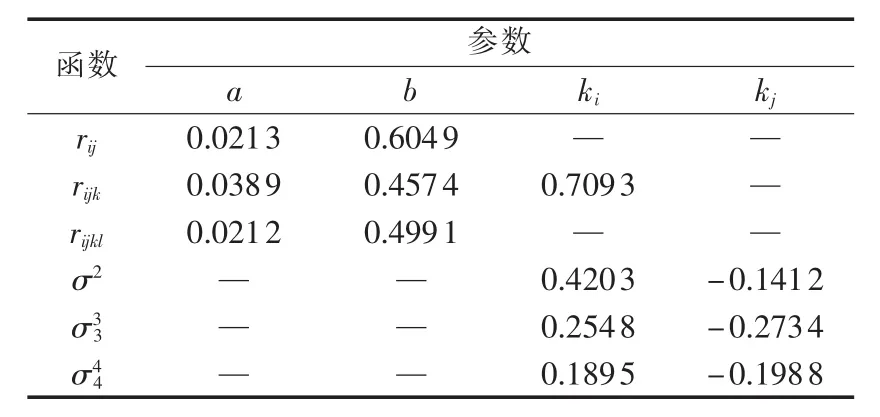
表2 模型方程的待定系数Table 2 Calculated data for undetermined coefficients of model equations
通过上述建立的具体波动性模型方程,分析福建省2013全年风电出力时间序列,得到福建集群风电场的3个波动性指标标准差、偏度、峰度的建模值,同时运用直接法求解得到这3个波动性指标测量值,如表3所示。表中,测量值×100%,偏度值是样本偏度值,峰度值是样本峰度值。
将2组指标计算结果进行对比发现,标准差建模值和测量值近似相等,误差仅为测量值的3.78%,表明指标估算法在估算集群风电场出力标准差时具有较高的准确度。但是对于偏度和峰度指标,估算准确度相对较低,误差分别为测量值的13.77%和15.38%,此时指标参数估算模型可以为估算未来风电集群出力场景的偏度和峰度指标提供指导性依据。
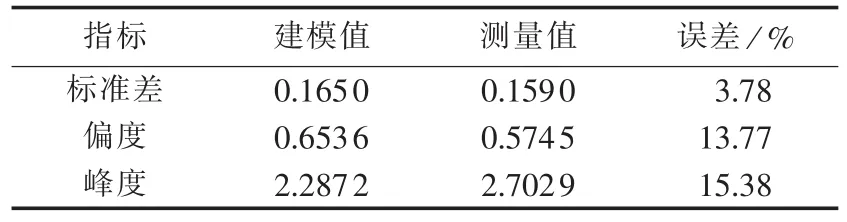
表3 2种方法对典型福建省风电集群的计算结果Table 3 Calculative results by two methods for typical Fujian wind farm cluster
4 结论
本文首先基于概率统计理论,建立单个风电场与集群风电场出力的高阶中心矩关系模型,给出2个描述风电出力“分布形状”的统计学指标——偏度和峰度。然后依托集群风电出力均值、标准差、偏度和峰度4个指标,构建表征集群风电出力概率分布的皮尔逊族模型,模拟生成集群风电场出力随机数据。根据2013年度典型区域的单个-集群风电场出力时间序列数据,进行4个统计性指标计算,并基于得到的4个指标建模,建立了皮尔逊族I型分布,接着从单个风电与集群风电、实测与建模2个角度分别给出了单个-集群风电出力累积概率分布曲线和出力持续曲线验证,对比分析表明基于指标的皮尔逊族分布建模具有较高准确性和实用性。
然后考虑历史出力数据获取的困难性,为适应未来场景的集群风电出力评估,依据典型风电场集群历史数据分析,经验建立风电场间相关系数与风电场间距的指数关系模型,并给出区域风电场各阶标准差与年平均出力之间的多项式关系模型,接着通过典型福建省风电场集群实例,对比分析了建模法和直接法得到指标计算结果,发现估算模型对于标准差的计算具有较高准确度。通过基于均值、标准差、偏度和峰度4个指标的皮尔逊族分布建模有利于模拟生成集群风电场出力数据,构建风电出力持续曲线,以及定量分析集群风电出力的波动性,为电网的风电运行规划、并网评估等提供有力支撑。
猜你喜欢
昆明医科大学学报(2021年4期)2021-07-23
初中生世界(2020年43期)2020-12-18
初中生世界·九年级(2020年11期)2020-12-02
国际放射医学核医学杂志(2020年4期)2020-07-27
教育教学论坛(2019年7期)2019-03-18
科学与财富(2018年16期)2018-08-10
雷达学报(2018年3期)2018-07-18
电测与仪表(2016年23期)2016-04-12
罕少疾病杂志(2016年5期)2016-03-11
河南电力(2016年5期)2016-02-06
