
基于超像素和SVM 的交互式联合分割算法研究
2015-09-19 03:42:10乔琪珑王继业
电视技术 2015年22期
乔琪珑,王继业,杨 舒
(1.中央民族大学 信息工程学院,北京100081;2.北京理工大学 信息与电子学院,北京100081)
联合分割的概念由Rother[1]在2006 年提出,其目的是处理多幅前景相似的图片,将前景目标提取出来。联合分割技术可应用于对象驱动的图像检索、视频中特定目标的检测和跟踪、交互式图像编辑,以及图像相似性度量等。随着近年来存储设备和通信相关技术的提高,这类针对图像集的处理算法更适应于图像大数据的发展。
按照训练方式不同,联合分割算法可被分为3 类:完全监督学习[2],半监督学习[3-4]和非监督学习方式[5-6]。大多数非监督学习的方式是使用前景之间的直方图一致性来实现分割,这类方法对图像数量很敏感,例如Jose C[5]的方法就需要同时处理至少两幅图像。同时,非监督学习的方式不能很好地处理前背景相似的情况。而以交互式分割为基础的监督和半监督学习方式能很好地克服这样的缺陷。
一方面,自联合分割的概念被提出,研究人员做了很多工作使其在精确度和分割效率上均有提高,但依然存在图像数量限制,交互工作量大等问题;另一方面,超像素、机器学习等算法在图像处理中展现优势,基于此本文提出了一种基于超像素和支持向量机SVM 的联合分割算法。通过将种子图像预分割成多个超像素来建立图割[7]模型,并在最终的联合分割中使用Grabcut[8]算法来提高分割精确度。在本文方法中,由于分类器的输入即这些超像素的特征,图像分割问题被转化为分类问题,使用分类器SVM 来将超像素最终分为前景和背景两类。
本文只使用一幅种子图像进行交互式分割,并采用对SVM 中的样本抽取的方式来平衡正负样本数。相比于其他算法,本文方法更加灵活,可以同时处理任意张图片,用户交互量小,并且能够实现很好的分割效果。本文的主要贡献包括:
1)提出了一种基于机器学习的联合分割算法框架,使用二分类的分类器来实现,并使用迭代算法拓展到半监督学习的方式来训练分类器。
2)通过只选取一幅图像作为种子图像,由用户手动赋予前背景标签,以此减少用户工作量,同时提出了一种样本抽样的方法来平衡正负样本数量。
3)引入Tf-idf 加权算法来优化特征,解决了前背景特征相似的情况。
1 基于超像素和SVM 的联合分割
联合分割问题可以视为超像素的二分类问题,在本章中,图1 展示了本文算法的框架,基于这个框架,本文从3 个部分描述算法的细节:种子图像交互式分割、特征词典和SVM 的训练、联合分割测试。
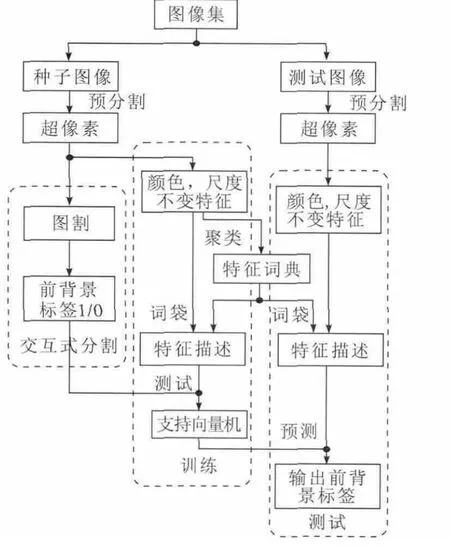
1 基于超像素和SVM 的联合分割算法框架
1.1 种子图像交互式分割
通过使用SLIC 算法[9]将每幅图像过分割成800 个左右超像素,得到具有相似大小的块,并很好地保留了目标的边界。用超像素作为节点构建图割模型,为节点之间的边赋权值,得到能量方程。本文改进的能量方程同样分为区域项与边界项两部分,其中区域项与lazy snapping[10]中相同,用来衡量每个节点与前背景模型的相似程度。边界项如式(1)所示,用来衡量相邻超像素之间的相似程度,公式描述如下其中,fi是超像素的前背景标签;使用位置数据(xi,yi)和(xj,yj)来计算两个超像素中心的距离;‖Ci-Cj‖是在CIELAB 空间中的颜色数据(li,ai,bi)和(lj,aj,bj)之间的欧氏距离。常数β 用来使高对比度区域趋于平滑。
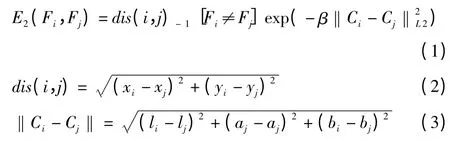
进行交互式分割之后,可以获得超像素的前背景标签,这些标签将被用于分类器的训练。
1.2 训练分类器
1.2.1 加权改进的BOF 特征提取
要通过分类器的方法实现联合分割,关键是要使用合适的特征来表示图像,得到目标之间的相似性,本文使用词袋算法来做特征提取。首先,使用k-means 算法对种子图像中的颜色RGB 值聚类,得到颜色特征词典。K 取200,也就是说颜色词典Dc 中包含200 个单词,然后使用同样的方法得到Dense-SIFT(DSIFT)词典Dd(包含800 个单词)。DSIFT 特征是对传统的尺度不变特征SIFT 省略了关键点提取的过程,是采用固定间隔采样(本文中间隔2 个像素采样)的方式获取特征点,从而得到稠密的特征。相比于传统的SIFT 局部特征,DSIFT 可以保证每个超像素中至少含有一个特征点,更有利于超像素的特征描述,但同时也忽略了尺度空间。因此可以从3 个层次计算DSIFT 特征,取扫描块大小分别为4×4,8×8 和16×16,以此弥补DSIFT 在尺度上的缺陷。
计算超像素中的特征(在Dc 或Dd 中对应的单词)出现在超像素中的频数,即BOF 算法的思路。但是,当同一类特征(某个单词)同时出现在前景和背景中时会存在干扰。很明显,这个单词并不能作为区分前背景的有力依据,因此需要降低这类特征对分类器的影响作用。在本文的算法中引入Tf-idf 算法如式(4)所示。Tf-idf 是在文本分类中常用的方法,用来调节特征对分类器的影响力。在式(4)中,ti表示第d 个超像素中的第i 个特征,nid是单词i 出现在超像素d 中的次数,而nd是超像素d 中出现的所有特征的个数。值得注意的是,对于颜色特征,nd是超像素块的面积,而在DSIFT 中是超像素块中特征点个数。遍历整幅图像,其中ni个超像素块中出现了特征i,用ni除N 得到的结果作为第i 个特征的权系数,这里的N 指整幅图像中的超像素个数。

最后对于每个超像素,遍历它的邻域特征,用这些特征的平均值作为该超像素块的上下文特征。在本文中,上下文特征有200+800=1 000 维。如式(5)所示,TEXi是超像素d 的上下文特征的第i 位数值,集合V 是其邻域超像素集合,这个信息是在预分割图像时得到的,tij是邻域超像素j 的特征描述,nj是邻域超像素的面积(对于DSIFT 是特征点数)。

1.2.2 训练数据平衡化
当训练SVM 时,通过将属于前景超像素块的标号和特征作为正样本,属于背景的特征和标号作为负样本。由于只有一幅种子图像被用户标记,因此训练数据很有限,为正负样本共800 个左右。实验表明,当种子图像中的前景面积远远小于背景面积的时候,得到的分类器不理想。
针对不同种子图像的情况不同,通过抽取前背景中的超像素来平衡训练数据的数量,抽样步长由前景面积和背景面积的比例决定。实验结果表明,这种方法在种子图像中的前景很小时,可以有效地提高联合分割的准确率,同时,对于前景面积大的图像也不会有负面影响。
1.3 测试图像联合分割
将种子图像之外的图像均作为测试图像,使用SLIC 方法[9]进行预分割,并使用加权改进的BOF 特征提取得到的特征词典来描述这些超像素的特征。然后将包括颜色、DSIFT和上下文的特征送入训练好的SVM 中。SVM 的输出(0、1)表示该超像素块是否是目标的一部分。SVM 给出的标号是基于超像素属于前景的概率所得。使用从0~255 的灰度值表示概率值从-1~+1,得到图2 所示的前景概率图谱。

图2 超像素属于前景概率图谱
最后,使用Grabcut[8]来优化分割结果,将分类器SVM 输出的结果作为可能的前背景标签,建立像素级的Grabcut 模型来纠正分类错误,处理独立碎块问题,以及优化边界。实验结果表明,这种像素级优化可以有效提高分割精确度,另一方面,由于有分类器输出作为预标记,Grabcut 的迭代收敛过程明显加快,因此不会造成计算效率的损失。
1.4 半监督学习方式拓展
本算法可以从两个方面拓展到半监督学习的方式,分别是种子图像的选取和SVM 的训练。
为同时解决颜色特征不够丰富的问题,提出了一种智能的种子图选取方法。首先,由用户手动或随机选取一幅以上的图像作为待选种子图像和颜色特征训练集。使用这些图像中的所有像素点作为颜色特征词典的训练数据,使用与训练分类器相同的聚类方法得到特征词典。与用一幅图像生成特征词典相比,用多幅图像聚类训练数据更丰富,聚类效果更好。然后得到这些待选种子图像的颜色特征,统计颜色丰富度,选择颜色最丰富的图像作为种子图像推荐给用户进行交互式分割。同时使用这幅图像提取DSIFT 特征词典,因为金字塔DSIFT 已经可以表示不同尺度的目标,一幅图像中已经含有丰富的DSIFT 特征。
通过引入一种改进的协同训练算法来优化分类器。首先将上文中选中并手动分割的种子图像作为原始训练样本,使用重采样得到3 组训练数据,分别选用线性、多项式、径向基RBF 核函数的分类器,得到3 个SVM。未被选中为种子图像的待选种子图像进行特征提取后,作为未标记的训练数据送入SVM。
与完全监督不同,通过使用2 个SVM 来预测新的样本标号,如果得到的结果相同,这个样本就被认为具有较高的标记置信度,而作为新的训练数据加入到第三个分类器的训练集中,这样就完成了其中一个分类器的更新。接着,使用这个分类器和一个分类器来预测测试数据,用同样的方法,使用结果相同的样本来更新另一个分类器。直到3 个分类器都被更新了,称作一次半监督学习,因为在这个学习过程中是没有用户介入的。其中,每次学习中使用的测试样本是待选种子图像的全部样本,拥有较高标记置信度的样本并不会离开测试集。
经过2 次半监督学习,将得到的3 个SVM 中的任意一个作为最终的分类器,来完成联合分割。选用径向基RBF 核函数的SVM 作为联合分割的分类器。
2 实验结果与讨论
2.1 联合分割实验结果
通过使用iCoSeg[2]数据集来评估本文算法。这个图像集包含38 类图像,被广泛应用于联合分割算法的测试评估中。对于每一类图像,选择一幅种子图像,交互式的方法提取前景,同时得到该类图像的颜色和DSIFT 特征词典以及SVM。然后对剩下的图像进行联合分割,最后得到的结果如图3 所示,其中第1 列是使用交互式图割分割的种子图像;第2~5 列是使用SVM 的输出进行Grabcut 的联合分割结果。

图3 联合分割实验结果
在图3 所示的分割结果中,从图3a 中可以看出,本文的算法得到了很好的分割效果。当前背景中存在相似的特征时,例如图3b 中的“棕熊”,本文的算法依然得到很好的结果。在图3c 中“飞机”的结果表明对SVM 中训练数据进行抽取的方式可以有效解决“小目标”图像问题。
2.2 结果对比
表1 使用“交集除以并集”评分标准,将本文的算法和Joulin A[4]与S. Vicente[11]的算法做比较,其中Joulin A[4]算法是近几年来大多数联合分割算法用来作为基准比较的算法,具有很好的代表性。结果表明,本文算法在大多数测试图像组中有更好的表现,且平均精确度比Joulin A[4]高4.4%。
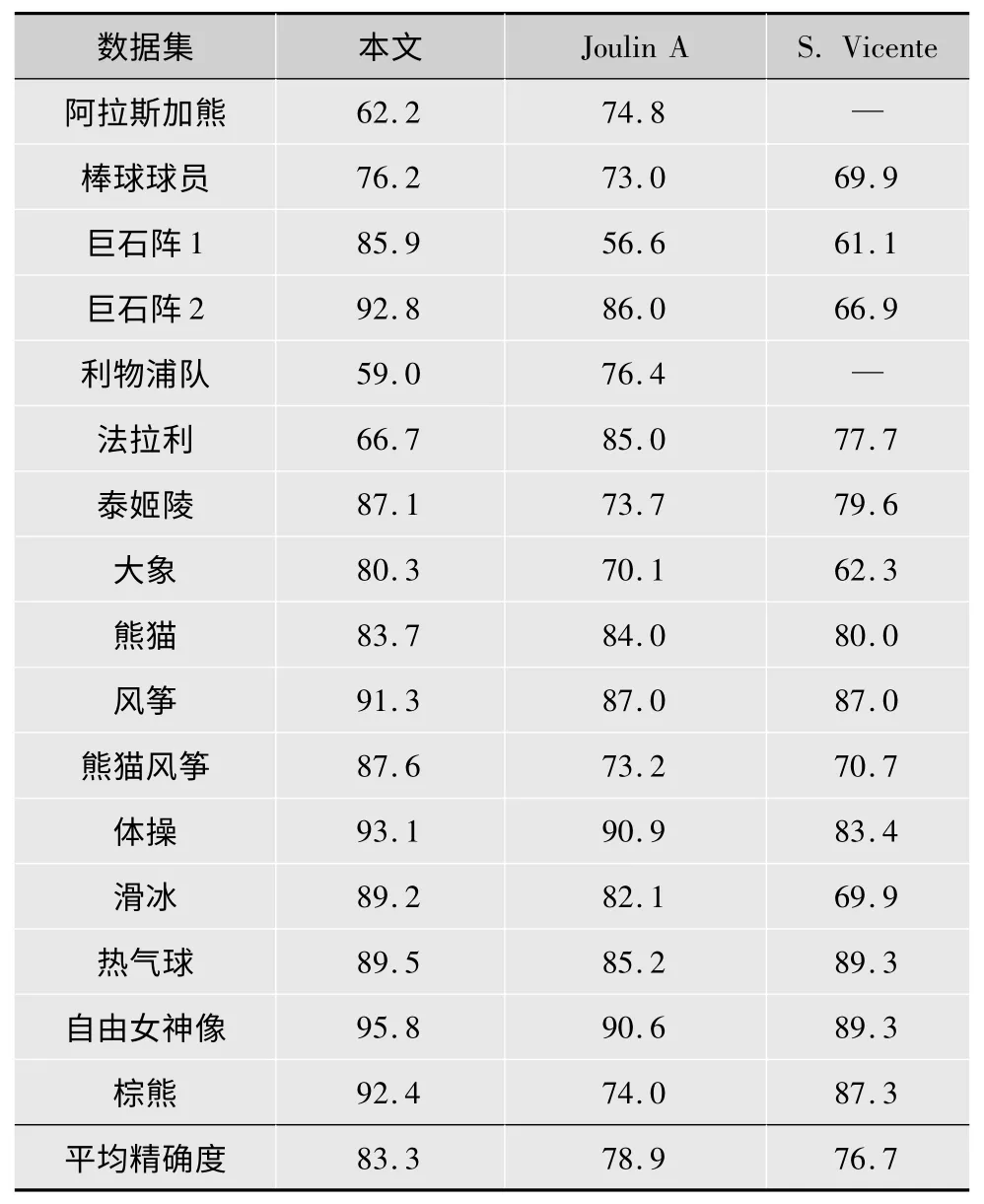
表1 各种联合分割算法分割精度比较%
2.3 半监督学习结果对比
将本文算法拓展到半监督学习的方式,使用未标记的图像训练分类器。通过将一幅测试图像加入到训练过程中,这些被SVM 标记的超像素会作为新的训练数据来训练SVM。使用原始数据和新的数据来更新分类器,然后使用更新后的分类器完成联合分割。将拓展后的半监督算法与WANG Z[12]的算法进行比较,如表2 所示。

表2 半监督方式算法分割精度比较 %
3 小结
综上所述,本文实现了一种新的联合分割算法,通过使用改进的词袋BOF 特征和样本抽取的方式优化算法,解决了“小目标”和“前背景中含有相似特征”的问题。相比于传统联合分割算法,本算法减少了用户工作量,并且能够得到更高的分割精确度。
[1]ROTHER C,MINKA T,BLAKE A,et al. Cosegmentation of image pairs by histogram matching-incorporating a global constraint into MRFs[C]//Proc. IEEE Conf. Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2006:993-1000.
[2]BATRA D,KOWDLE A,PARIKH D,et al.icoseg:Interactive cosegmentation with intelligent scribble guidance[C]//Proc. IEEE Conf.Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2010:3169-3176.
[3]MA T,LATECKI L J. Graph transduction learning with connectivity constraints with application to multiple foreground cosegmentation[C]//Proc. IEEE Conf. Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2013:1955-1962.
[4]JOULIN A,BACH F,PONCE J. Discriminative clustering for image co-segmentation[C]//Proc.IEEE Conf.Computer Vision and Pattern Recognition(CVPR).[S.l.]:IEEE Press,2010:1943-1950.
[5]RUBIO J C,SERRAT J,LóPEZ A,et al. Unsupervised co-segmentation through region matching[C]//Proc. IEEE Conf. Computer Vision and Pattern Recognition(CVPR). [S.l.]:IEEE Press,2012:749-756.
[6]LI H,MENG F,WU Q,et al. Unsupervised multi-class region co-segmentation via ensemble clustering and energy minimization[J].IEEE Trans.Circuits and Systems for Video Technology,2014(24):789-801.
[7]BOYKOV Y Y,JOLLY M P. Interactive graph cuts for optimal boundary&region segmentation of objects in ND images[C]//Proc.IEEE Conf.International Conference on Computer Vision(ICCV).[S.l.]:IEEE Press,2001:105-112.
[8]ROTHER C,KOLMOGOROV V,BLAKE A. Grabcut:Interactive foreground extraction using iterated graph cuts[C]//Proc. ACM Transactions on Graphics.[S.l.]:IEEE Press,2004:307-312.
[9]ACHANTA R,SHAJI A,SMITH K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].IEEE Trans.Pattern Analysis and Machine Intelligence,2012,34(11):2274-2282.
[10]LI Y,SUN J,TANG C K,et al. Lazy snapping[J]. ACM Trans.Graphics(ToG),2004,23(3):303-308.
[11]VICENTE S,KOLMOGOROV V,ROTHER C. Cosegmentation revisited:models and optimization[C]//Proc. IEEE Conf. ECCV.[S.l.]:IEEE Press,2010:465-479.
[12]WANG Z,LIU R.Semi-supervised learning for large scale image cosegmentation[C]//Proc. IEEE Conf. Computer Vision(ICCV).[S.l.]:IEEE Press,2013:393-400.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
汽车工程师(2021年12期)2022-01-17 02:29:54
当代陕西(2020年14期)2021-01-08 09:30:42
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子测试(2018年1期)2018-04-18 11:52:35
贵州师范学院学报(2016年4期)2016-12-01 03:54:07
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
CHIP新电脑(2016年3期)2016-03-10 14:22:03
