
基于共享子空间的多标签数据学习模型研究
2015-09-18 02:33北京交通大学计算机与信息技术系北京100044
现代计算机 2015年14期
邹 珊(北京交通大学计算机与信息技术系,北京100044)
基于共享子空间的多标签数据学习模型研究
邹珊
(北京交通大学计算机与信息技术系,北京100044)
在多标签分类问题中,多个标签共享同一个输入空间,而且同一个实例的不同标签之间也存在一定的相关性,所以在研究此类问题的时候,标签之间的关联性研究就显得尤为重要。现有的多标签学习对于标签之间的相关的研究均是在原始数据上进行的,而我们希望对原始数据进行重表示,从原始输入空间中提炼出高层的语义信息将高维的数据映射到一个低维的子空间中,在类标信息作指导的情况下体现类标之间的共享信息的特点。再利用已有的分类方法进行多标签的分类。对多个网页分类任务进行实验,结果表明此种方法在一定程度上提高分类效果。
多标签学习;共享空间;数据重表示
1 问题的提出
在机器学习中,研究最多应用最广泛的监督学习(Traditional Supervised Learning)通过分析训练数据集获得输入特征空间和输出标签空间之间的一个映射函数。该传统方法在待学习对象具有明确的、单一的语义时(即对象标签唯一),已经取得了巨大的成功。然而,真实世界的对象往往具有多义性,即一个样本可能同时属于多个类别。例如,在文档分类问题中[1~2],每篇文档可能属于多个预定义的主题;在图片分类中,每个图片可能含有不同的语义;在生物信息学问题中[3],每个基因可能同时具有多种功能等。
在处理多义性对象时,上述只考虑明确、单一语义对象的传统监督学习方法难以取得好的效果。于是,研究者提出了多标签学习(Multi-label Learning)方法。该方法能够处理具有多个类别标记的对象,其学习目标是将所有适合的类别标记赋予待分析的对象。早期,多标签学习的研究主要集中于文档分类中遇到的多义性问题。经过近十年来的发展,多标签学习技术已在多媒体内容自动标注、生物信息学、Web挖掘、信息检索、个性化推荐等领域得到了广泛的应用。
多标签学习已经得到众多学者的关注[4],最普遍的方法是将该学习问题分解为多个二分类问题求解[4~5],由于此方法效率高且容易实现,在实际应用中得到了广泛的应用。然而,这种方法完全忽略了标签之间的相关性;而随着多标签学习的研究的不断深入,出现了许多基于多标签之间相关性的学习方法[6~7],这些方法直接对原始数据进行处理。然而在实际应用中,原始数据具有高维性,且含有噪声或冗余的特征。因此在多标签分类之前,需要对原始数据进行处理,从而使分类过程更加有效。
数据降维技术是一项常见的数据处理技术[8~9]。数据降维是指通过线性或者非线性映射将高维数据转变成低维数据。数据降维的目标是在保持原始数据的分类和决策能力的前提下去掉数据中的冗余信息。通过数据降维可以消除冗余,去掉高维空间中不相关属性,解决由维度灾难引起的问题,促进高维数据的分类和压缩[10]。目前已经提出了许多降维方法,包括主成分分析(PCA)、典型相关性分析(CCA)等。PCA[11]是一种典型的线性降维方法,通过对原始变量的相关矩阵进行研究,用少数几个综合变量表示原属的多个变量,进而达到降维的目的。CCA研究两组变量之间相关性的一种多元统计分析方法,它将两组变量分别映射到与它们最大限度的相关的低维度的空间中。这种方法虽然同时对两组变量进行降维处理,但在降维的过程中,并没有考虑两组变量之间的相关性。
针对上述问题,我们提出了一个基于多标签共享信息的数据表示学习模型,该模型通过从原始数据信息中提炼出更高层的语义信息,即将高维的原始数据映射到一个低维的子空间中。同时为了充分利用标签信息,模型考虑了标签与低维子空间的关系,该关系有效地展示标签之间共享信息,即分别对标签信息和原始数据信息进行降维处理。在此基础上,还考虑了标签信息与数据属性特征之间的线性相关性。利用上述方法对原始数据进行重表示后,再利用已有的分类方法进行多标签的分类学习。在实际多标签文本数据上的实验结果证明我们所提出的模型对数据进行重表示后,分类效果较原有方法在一定程度上有所提高。
2 算法实现
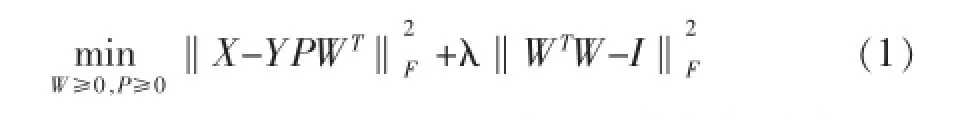
在上述式子中,W∈Rd×r用来表示数据与共享空间r的关系,这里因为用到类别标签的指示矩阵Y,故引入变量P∈Rm×r用来表示类别标签与共享空间的关系。根据此模型学习到数据与共享空间之间的关系W,从而达到将高维的数据映射到低维的共享空间上,然后利用变量W对原始数据进行重表示,再利用已有的分类方法重新进行多标签的分类学习。
3 算法优化
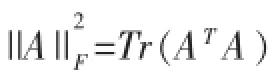
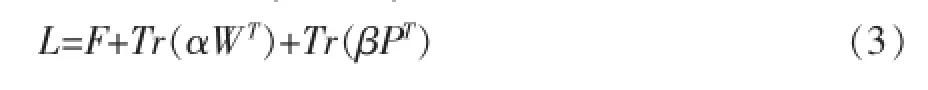
在求解W时,将P看作是已知量,即:
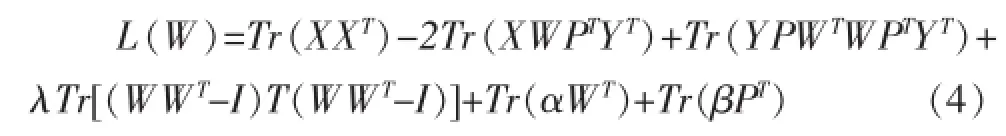
根据上述公式对W求导,并将其置为0可以得到:
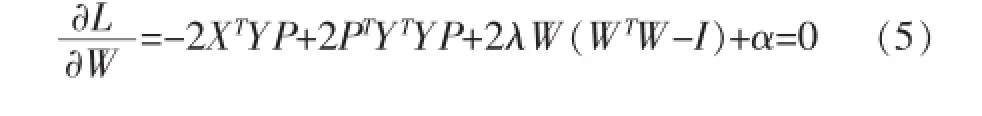
同在求解P时,将W看作是已知量,即:
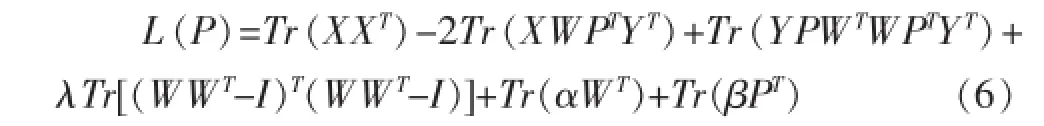
根据上述公式对P求导,并将其置为0可以得到:
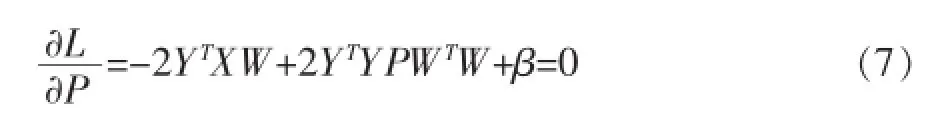
根据等式(5)、(7),利用K-T(Kuhn-Tucker)条件αijwij=0和βijpij=0可以得出对于W,P的更新规则:
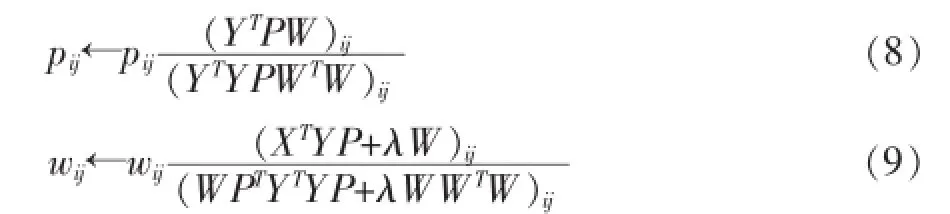
在迭代求解W,P时,涉及到两个关键的问题,W和P的初始值及循环迭代的终止条件。W表示数据与共享空间的关系,在初始化时随机赋给W一个d×r矩阵,根据P所表示的含义,即类别标签与共享空间的关系,在初始化的时候我们将P置为1/r,即认为最初每个类标在共享空间所占比例相同。对于循环终止条件,根据上文提出的模型可以知道,若迭代次数较少,可能导致W,P学习到的值不够理想;而迭代次数过多,不仅使整个实验耗时较长影响实验效率,而且还会影响最终的分类性能。于是,在实验中,采用变量迭代前后两次差值的F-范数大于设定的阈值,这里设置为10-3作为循环迭代的终止条件。
通过上述方法计算出低维度的数据与共享空间的关系W,然后将原始数据映射到共享空间中,即对输入的数据进行重表示,然后再利用已有的分类方法进行分类。对于多标签的分类,目前已经有很多的分类方法[20],例如支持向量机(Support Vector Machine,SVM)、基于多任务的迭代优化模型算法(Alternating Structure Optimization,ASO)等。在本文中,我们分别对现有的几种不同的方法,如ASO、SVM分别进行了实验,从而验证所提出的模型的优越性。
在上述优化算法中,我们可以看出对于W和P的计算是一个反复迭代的过程,由更新规则可以得出,对于P的更新的计算复杂度为O(mnd+m2n+t(3mdr+m2r)),对于W的更新的计算复杂度为O(mnd+m2n+t(3mdr+ m2r+2d2r))。由前面的介绍我们可以知道,r<<d且m<<d,因此,CSI算法整体的计算复杂度为O(nd+t(d2+d)),其中t为迭代次数。
4 实验结果
实验中选用多主题的网页集合[12~14]作为实验数据,这些数据是通过对“yahoo.com”领域的11个顶级集合编译而来。通过删除主题不到100的网页,出现次数少于5次的词,以及没有主题的网页来对数据进行预处理。然后使用TF-IDF编码来表示网页,每个网页都归一化为统一的长度。在本文中我们选取Science和Health两个数据集进行实验验证。在经过上述预处理后,我们通过采用文档频率(Document Frequency,DF)方法对数据进行了特征选择,以减少计算量提高实验效率。这两个数据集的统计如表1所示,其中m、d、N分别表示经过预处理后的标签数、数据维度和总的实例数。
表1:Yahoo数据集合的统计信息,m、d、N分别表示经过预处理后的标签数,数据维度和总的实例数。“MaxNPI/MinNPI”表示每一个标签(label)包含的最大/最小的实例数。

表1
实验中分别采用Science数据集和Health数据集对实验结果进行验证。表2、表3分给出了输入数据为Science数据集和Health数据集时的实验结果。
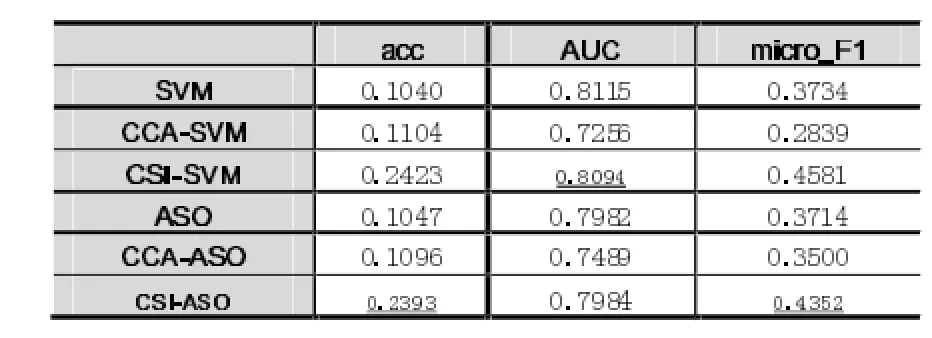
表2 输入数据为Science的实验结果对比
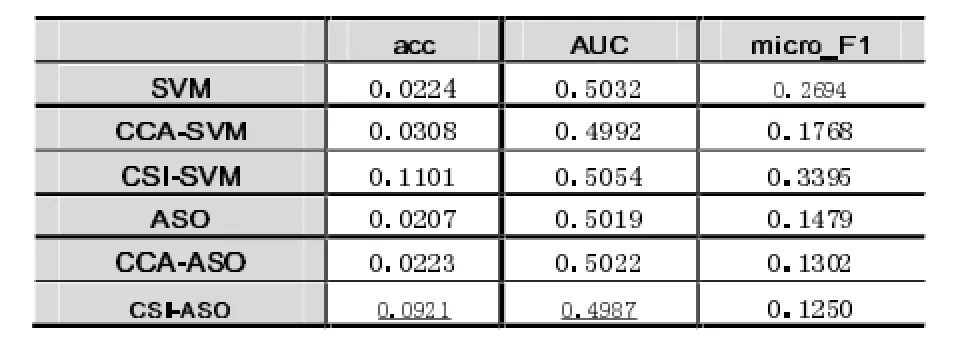
表3 输入数据为Health的实验结果对比
表2、表3中粗体数据和带有下划线的数据分别表示对应的值最大和次之的数据。通过上述两个表格所列出的对比数据可以看出,CSI-SVM和CSI-ASO两种方法的分类性能较优,也就是说在通过我们所提出新模型的学习,并对原始数据进行重表示后,能有效地提升已有多标签分类方法的分类效果。由公式(1)可以知道,我们在提出模型时,不仅考虑了从原始数据提炼出高层语义的信息,并使用相应的标签信息作指导来对数据进行重表示,充分体现了多标签之间含有共享信息的特点。
5 结语
本文基于多标签之间的共享信息提出了一个新的模型,经过此模型的学习,可以得到一个低维的数据与标签之间的共享空间的关系变量,即从原始数据中提取出高层的语义信息。通过学习到的这个变量,将原始数据映射到一个低维的共享空间中,即对原始数据进行重表示,将重表示后的数据利用已有的多标签分类方法进行分类学习。经过实验可以知道,将数据进行重表示后,在一定程度上提高了多标签学习的分类效果,从而也验证了标签之间的共享信息对于多标签分类的重要性。
随着多标签学习技术的不断发展,多标签分类被应用到各个领域。如何更好地挖掘和使用标签之间的共享信息,从而提高分类效果,是未来主要的研究课题。
[1]SchapireRE,SingerY.BoosTexter:a Boosting-Based System for Text Categorization.Machine Learning,2000,39(2-3):135~168
[2]McCallum A.Multi-Label Text Classification with a Mixture Model Trained by EM.In:Working Notes of the AAAI'99 Workshop on Text Learning.MenloPark,CA:AAAI Press,1999
[3]ElisseeffA,Weston J.A Kernel Method for Multi-Labelled Classification.In:Dietterich TG,BeckerS,GhahramaniZ,eds.Advances in Neural Information Processing Systems14.Cambridge,MA:MIT Press,2002:681~687
[4]Min-Ling Zhang.Learning from Multi-Label Data.School of Computer Science&Engineering,Southeast University,China
[5]Grigorios Tsoumakes,IoannisKatakis.Multi-Label Classification:An Overview.Deptofinformatics,Aristotle University of Thessaloniki, 54124,Greece
[6]S.Ji,L.Tang,S.Yu,J.Ye.Extracting Shared Subspace for Multi-Label Classification.In Proceedings of the 14th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,Las Vegas,NV,2008:381~389
[7]M.-L.Zhang,KZhang.Multi-Label Learning by Exploiting Label Dependency.in Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington D.C.,2010:999~1007
[8]M-L Zhang,KZhang.Multi-Label Learning by Exploiting Label Dependency.InProceedings of the 16th ACM SIGKDD International Conference on Knowledge Discover and Data Mining,KDD`10
[9]On Label Dependence and Loss Minimization in Multi-Label Classification.Machine Learning,vol.88,no.1-2,pp.5-45,2012
[10]Y.Yang,J.O.Pedersen.A Comparative Study on Feature Selection in Text Categorization.In Proceedings of the Fourteenth International Conference on Machine Learning,pages 412~420,1997
[11]Lewis P M.The Characteristic Selection Problem in Recognition System[J].IRE Transaction on Information Theory,1962,8:171~178
[12]N.Ueda,K.Saito.Parametric Mixture Models for Multi-Labeled Text.In Advances in Neural Information Processing Systems 15, pages 721~728.2002
[13]H.Kazawa,T.Izumitani,H.Taira,E.Maeda.Maximal Margin Labeling for Multi-Topic Text Categorization.In Advances in Neural Information Processing Systems 17,pages 649~656,2005
[14]N.Ueda,K.Saito.Single-Shot Detection of Multiple Categories of Text Using Parametric Mixture Models.In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,pages 626~631,2002
Multi-Label Learning;Shared Subspaces;Data Representation
Research on the Multi-Label Learning Model Based on Shared Subspaces
ZOU Shan
(Institute of Computer and Information Technology,Beijing Jiaotong University,Beijing 100044)
In the multi-label classification problems,multiple labels share the same input space,but there are some correlations between different instances of the same label,so in the study of such problems,correlation studies between labels become particularly important.Existing multi-label learning for relevant research between the labels are on the original data,and we hope to re-represent the original data,highlevel semantic information extracted from high-dimensional data,mapping from the original input space to a low-dimensional subspace, in the case of class standard reflects the characteristics of the information as a guide to share information between class standard.Then uses the existing multi-label classification method to classify.Multiples Web classification tasks,experimental results show that this method is to some extent improve the classification results.
1007-1423(2015)14-0033-04
10.3969/j.issn.1007-1423.2015.14.008
邹珊(1990-),女,内蒙古赤峰人,硕士研究生,研究方向为机器学习
2015-03-20
2015-04-22
猜你喜欢
China Report Asean(2022年8期)2022-09-02
车主之友(2022年4期)2022-08-27
物联网技术(2020年12期)2021-01-27
海峡姐妹(2019年12期)2020-01-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
汽车零部件(2017年4期)2017-07-12
火控雷达技术(2016年1期)2016-02-06
Coco薇(2015年11期)2015-11-09
