
基于关联规则的数据挖掘技术研究
2015-09-18 02:33万晓燕青岛酒店管理职业技术学院信息工程技术学院青岛266100
现代计算机 2015年14期
万晓燕,陈 姗(青岛酒店管理职业技术学院信息工程技术学院,青岛266100)
基于关联规则的数据挖掘技术研究
万晓燕,陈姗
(青岛酒店管理职业技术学院信息工程技术学院,青岛266100)
由于信息技术领域的飞速发展,在我国数据挖掘技术已经被广泛应用于与生活息息相关的领域中,针对Apriori算法的关联规则的数据挖掘中所存在的诸多问题,介绍基于粒计算算法的关联规则数据挖掘技术,它是在传统算法上的优化改进。通过具体的实证分析,比较分析Apriori算法和基于粒计算算法的不同效果。因而得出结论,粒计算算法的关联规则数据挖掘技术在进行数据挖掘处理时更加可行直观且高效,构建一个良好的、开放式的数据挖掘平台。
数据挖掘技术;Apriori算法;粒计算;关联规则;数据挖掘平台
0 引言
数据挖掘技术是在信息领域中发展最迅速的技术,许多领域内的专家,例如统计学家和数据库专家都需要准确尽快地获取自己所需信息,这都促进了数据挖掘技术的不断进步。同时随着信息技术的发展也带动了采集方式和能力的不断高端化,使我们积累的数据快速膨胀。一方面,这些海量的数据为合理正确的决策提供了基础条件,但如何从一堆数据中识别有用信息则需要耗费大量的人力物力。数据挖掘技术在发展进步的过程中综合理论统计学知识等发展出了自动的模式识别功能和数字人工智能,广泛应用到机器研究和神经网络等专业领域。
关联规则的数据挖掘方法的流程主要是:综合频繁项集,由频繁项集寻找强关联规则,发现在某一交易数据库中各个不同项之间的联系,所有这些关联规则是对所需检测对象的某种特殊模式的反映[3]。但无论在商业零售领域还是金融电信等领域整个数据量是巨大的,提高算法的效率这才是发展数据挖掘技术的重中之重。通过粒计算算法的关联规则数据挖掘分析,可以解决传统算法带来的问题,从而达到简单快速的发现在数据库当中的频繁项集。
1 基于关联规则的数据挖掘基本方法
1.1基本概念分析
关联规则的数据挖掘的数据集称作事务数据库,给定为D={t1,t2,…,tk,…,tn)。其中tk={i1,i2,…,im,ip)(k= 1,2,…,n)称为事务,im(m=1,2,…,p)称为项目。
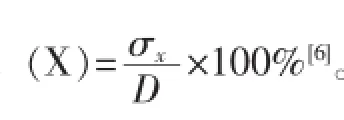
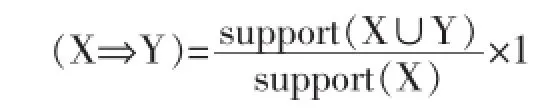
若support(X⇒Y)minsupport且support(X⇒Y)minconfidence,就称关联规则X⇒Y为强规则,否则就称关联规则X⇒Y为弱规则。
挖掘数据集中的全部强规则,是关联规则挖掘中的一个主要任务。强规则X⇒Y对应的项目集(X∪Y)为频集,则频集(X∪Y)导出的强关联规则X⇒Y的置信度通过频集与X⇒Y的支持度的计算结果得出。综上所述,能够将基于关联规则的数据挖掘切割为两个子问题:一是通过minsupport发现数据集中的全部频集,二是通过频繁项目集和最小置信度得出关联规则的。
第一个子问题是通过minsupport迅速高效发现数据集中的全部频集,其主要是基于关联规则数据挖掘技术的核心,主要使用其衡量关联规则的数据挖掘算法;第二个子问题是通过频繁项目集和最小置信度来获取关联规则,具体如下图所示为关联规则挖掘的基本模型。
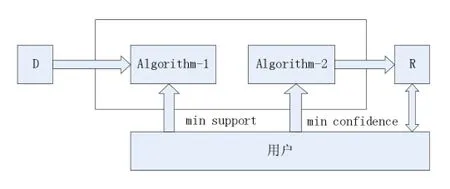
图1 基于关联规则的数据挖掘过程的基本模型
在上图中,表示为这个数据集,其中Algorithm-1是频繁项目集的搜索算法,Algorithm-2是经过关联规则而产生的算法,R表示经过关联规则数据挖掘技术处理得到的集合。当用户指定了minsupport和minconfidence,再进行搜索算法的交互,并跟R进行交互,进行评价解释得出的挖掘结果。
1.2基于关联规则的数据挖掘技术方法核心
当前的普遍的串行算法表述中,Agrawal R.等人提出的Apriori算法是应用最为广泛的,以Apriori算法为基础,衍生出更多的算法,其核心是最大限度的构建最小的候选项目集,再将频繁项目集的随机子集进行关联运算分析。
Apriori算法以构建频繁项目集为主要方式来完成项目集元素的数量,首先获得1-频繁项集L1,再获得2-频繁项集L2,如扩展结束,则整个算法停止。当第k次循环时,需要首先产生k-候选项集,并且在集合ck内,在经过数据库的支持度运算获取k-频繁项集Lk。
因此将Apriori算法归纳为三个步骤[7~9]:
首先是频繁k-1项集自连接获得长度为k的候选k项集ck;
其次是对两个或两个以上的非频繁子集的候选项剪枝;
最后将扫描得到的全部事务用来获取候选项集的支持度。
表1中反映了在传统的Apriori算法中选用Apriori-gen(Lk-1),目的得到(k-1)-频繁项集所得到得k候选集。

但是作为一个经典关联规则,Apriori算法仍然存在着许多问题:一是需要扫描数据库反复;二是产生的候选项目集数目太过庞大。如果要解决以上的问题,可以通过改进四个方面来实现:
(1)通过减少次扫描数据集减少I/O操作。
(2)减少计算支持度项目集的数量,使之与频繁项目集的数目达到相近。
(3)使用的一个子项目集的数量获得最大程度的分解。
(4)生成的多个同时进行的项目集。
2 基于粒计算的关联数据挖掘分析
2.1粒计算
基于粒计算的关联规则挖掘可以高效实现上述改进。粒计算(Grc)指是一种基于粒子的问题求解和进行信息处理的方法,该算法的基本思想已经应用于多种领域,例如聚类分析、决策数、神经网络、语义网络、区间分析等。我们在处理大数量并且复杂的问题时,常常对问题进行信息粒化,所谓信息粒化就是根据各自特征和性能把信息划分为多个简单粒子。
因此可以将基于粒计算的关联数据挖掘技术基本问题概括为两个方面,一方面是,如何去构建信息粒度(也称作粒的结构)另一方面就是如何进行粒的计算。粒的结构实际上就是粒的形式化表示和解释。计算的目的是试图找到最小的计算复杂性近似解去满足足够的可行性误差范围。计算的基础取决于前面讨论的信息粒化的概念,可以研究来自不同的语义和算法的数据。基本任务之一是粒计算,一个可以检查和进一步探索颗粒之间的关系,例如:邻近、依赖、关联等,信息粒化之间的关系处在较低的水平还是较高的水平,并且要定义和解释基于粒的各种算子;并且设计能够计算粒的算法和工具。
信息和信息表的基本组成是通过粒空间中的基本粒来表述的,基于粒计算关联规则的数据挖掘算法主要解决的是在过程中粒空间内获取所有的频繁项集。这种算法输入的是信息表和支持度,输出的是频繁项集合。
将信息根据其属性值域对论域粒化,得到每个属性的原子信息粒向量grc={a1,a2,…},其中a1={Cg1,Cg2,…},m为粒空间的分解层数即粒空间中向量的个数。
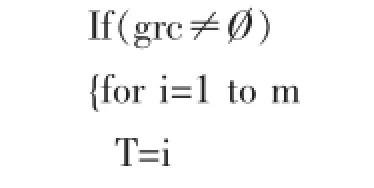
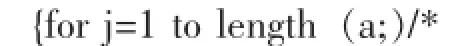
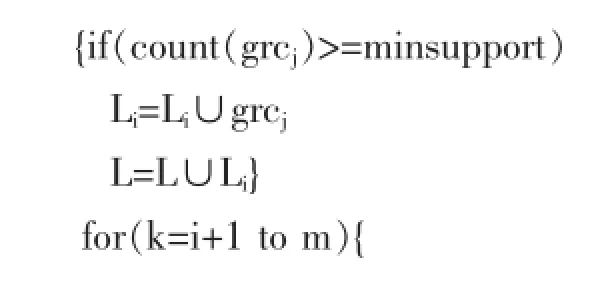
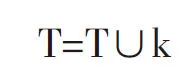
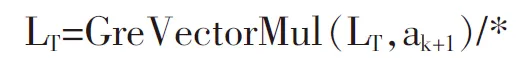
L=L∪(LT的每个元素的所有子集);
输出L,算法结束。

2.2实证分析
设一个事务数据库有九项事务,T1={B,D,E},T2= {A,D},T3={C,D},T4={A,B,D},T5={B,C},T6={C,D},T7={B,C},T8={B,C,D,E},T9={B,C,D}。
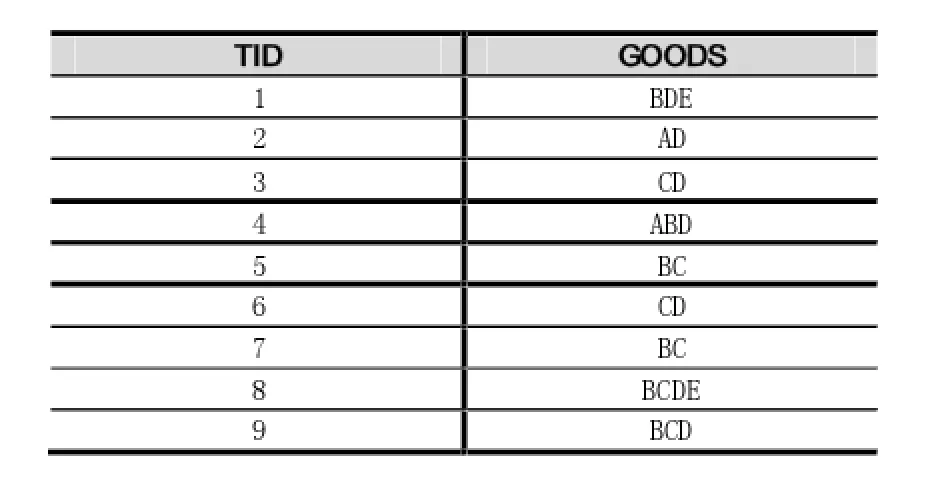
表1 事务数据库(D)表
首先运用Apriori算法对上述数据进行的关联规则数据挖掘,结果如下表所示:

表2 一组频繁项集表
将上表中扫描数据集,并对每一项扫描进行设置和计数,去除那些支持度小的,保留支持度大的,结果如图所示:
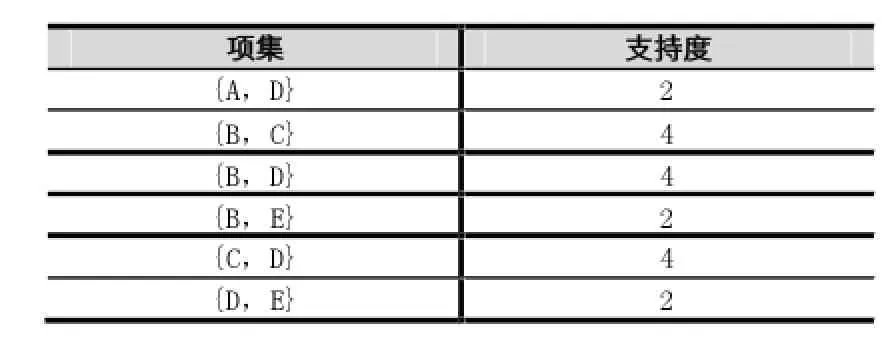
表3 两组频繁项集表
从上表可知,比较各选项的支持数和最小支持度,去除那些确实不满足最低要求的支持度的项目。例如,(B,C)可以和(B,D)相关,但不与(C,D)相关,通过这一原则,得到(B,C,D),(B,C,E),(B,D,E)之间关系,因为(C,E)不是(B,C,E)的频繁的子集,所以删除(B,C,E)在这三个项目。如下所示:

表4 三组频繁项集表
再用相同方法处理,不满足联接条件选集是空的。第二步通过粒计算的关联数据挖掘将上述表的信息储存,首先创建扫描数据集,如下表所示:
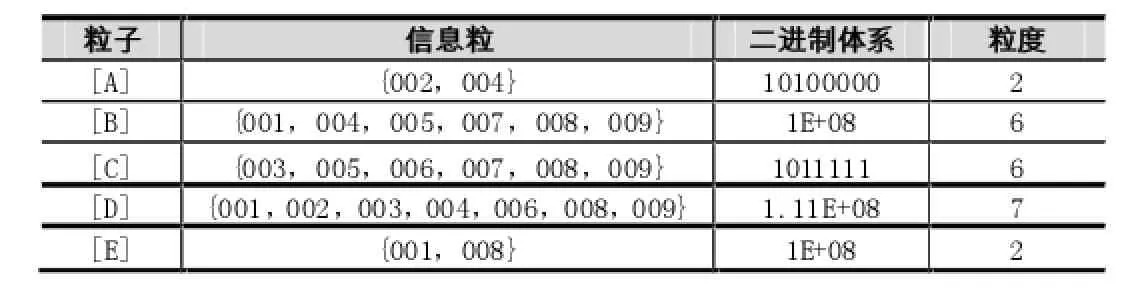
表5 粒计算表
上表可知,所有粒度大小达到最小支持度,所以它们通常是一组。在我们得到频繁项集中,让所有粒子组合,进一步合并得到:[A,B],[A,C],[A,D],[A,E],[B,C],[B,D],[B,E],[C,D],[C,E],[D,E]。结果如下。
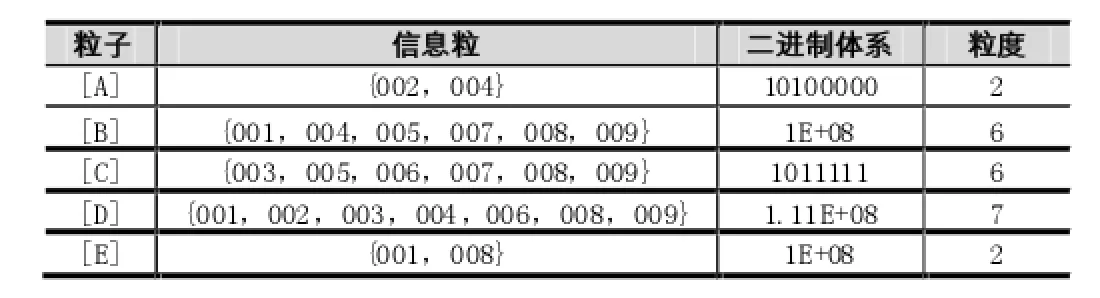
表6 粒计算后的两组频繁项集表
得到获取的项目集的数量,它由新的频繁项集组合可以表示为:[B,C,D],[B,C,E],[B,D,E]。二进制字符串是用来表达信息的,用点位提取频繁项集和关联规则发现的。通过分析,[C,E]非候选频繁集,所以只有[B,C,D]、[B,D,E]是频繁集,但[B,C,E]并不是。它们的二进制表示和二进制计算结果如下:

表7 粒计算后的三组频繁项集表
由以上算法可得,对于Apriori算法的应用,其数据库的扫描需要对整个统计数值进行多次的匹配才能完成,由于匹配时间过长,在实际应用中并不能够体现算法所具有的快捷性,但是基于粒计算关联规则的数据挖掘技术在一定程度上可以解决这个问题,故,两种算法的执行时间比较如图3所示。
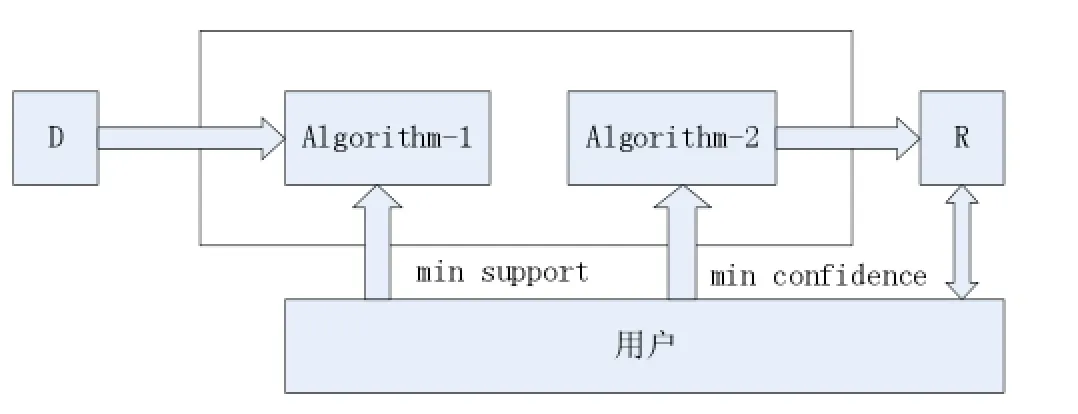
图3 两种算法的执行时间图
3 结语
伴随信息技术的不断发展,网络数据域数据库的构建需求日益增长,同时会导致数据信息处理规模不断增大,因此,如何快速高效的数据挖掘是当前该领域亟待解决的问题。粒子算法的核心是通过粒度计算关联规则的挖掘频繁项集,其具有实现减少对象扫描数据集的工作量,有效提高算法效率的优点。使得基于粒计算的关联规则数据挖掘算法能够被企业用来进行筛选评估,为该领域的研究提供定量性的参考依据,同时使服务对象更加具有优化的竞争优势和更专注自身需
[1]郭建威,张玉臣.基于关联规则的创新矛盾矩阵的研究[J].计算机应用研究,2012,29(10)
[2]贾燕茹,王玉芬.基于数据挖掘关联规则技术的程序设计训练课程指导系统研究[J].大家,2010(2):22~24
[3]瞿丽.基于数据挖掘技术的查询优化[D].东华大学出版社,2009(12)
[4]王付山.关联规则挖掘技术在商场中的应用[J].商场现代化,2008(4)
[5]范明译.数据挖掘概念与技术[M].北京:机械工业出版社,2004.2
[6]毛国君,段立娟.数据挖掘原理与算法[M].北京:清华大学出版社,2005.7
Data Mining Technology;Apriori Algorithm;Granular Computing;Association Rule;Data Mining Platform
Research on Data Mining Technology of Association Rule
WAN Xiao-yan,CHEN Shan
(Department of Information Technology,Qingdao Vocational and Technical College of Hotel Management,Qingdao 266100)
With the rapidly development of the information field,data mining technology is widely used in the field closely related with our life. Improves the traditional algorithm based on the association rule data mining technology and the problems of Apriori algorithm of association rules mining.Analyzes the differences between Apriori algorithm and granular computing algorithm through the empirical analysis.The result shows that the granular computing data mining association rules are more feasible and effective in data processing,it can provide necessary conditions for the construction of open data mining platform.
1007-1423(2015)14-0018-05
10.3969/j.issn.1007-1423.2015.14.005
万晓燕(1980-),女,江西南昌人,硕士,讲师,研究方向为数据挖掘
陈姗(1980-),女,济南人,本科,副教授,研究方向为计算机软件技术
2015-03-24
2015-04-08
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
当代陕西(2019年15期)2019-09-02
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
信息通信技术(2015年6期)2015-12-26
智能系统学报(2013年1期)2013-01-28
