
基于免疫算法的非监督克隆选择聚类算法研究
2015-09-18 01:52广西科技大学鹿山学院电气与计算机工程系柳州545001
现代计算机 2015年11期
韦 灵(广西科技大学鹿山学院电气与计算机工程系,柳州545001)
基于免疫算法的非监督克隆选择聚类算法研究
韦灵
(广西科技大学鹿山学院电气与计算机工程系,柳州545001)
在详细分析克隆选择算法的基础上,提出非监督克隆选择聚类算法。该算法是数据驱动的自适应调整其参数,它对数据进行分类的操作尽可能快,改善过早收敛的问题,提高数据聚类的速度。通过使用一些人工和现实生活中的数据集,比较非监督克隆选择聚类算法与著名的K-means算法之间的性能优劣。实验结果表明,该算法不仅解决K-means算法需事先确定的类数K和在次佳值卡住的缺点,而且在功能上比传统的K-means分类算法具有较高的分类精度和更高的可靠性。
人工免疫系统;克隆选择算法;聚类;多目标优化;K-means算法
0 引言
从信息处理的角度来看,免疫系统是与神经系统、遗传系统并列的人体三大信息系统之一[1]。免疫是人体经过长期的进化所具有的特殊的保护性生理功能,通过免疫机制人体能够识别“自己”,排除“非己”,以维持人体内环境的平衡和稳定。免疫是生物体的特异性生理反应,由具有免疫功能的器官、组织、细胞、免疫效应分子及基因等组成[2]。人工免疫系统(Artificial Immune Systems,AIS)是由免疫学理论和观察到的免疫功能、原理和模型启发而生成的适应性系统。这方面的研究最初从20世纪80年代中期的免疫学研究发展而来[3]。人工免疫系统是人工智能领域的最新研究成果之一,是模仿自然免疫系统功能的一种智能方法,它实现一种受生物免疫系统启发,通过学习外界物质的自然防御机理的学习技术,提供噪声忍耐、无教师学习、自组织、记忆等进化学习机理,结合了分类器、神经网络和机器推理等系统的一些优点,因此具有提供新颖解决问题方法的潜力[4]。一些研究者基于遗传算法提出了一些模仿生物机理的免疫算法[5];人工免疫系统的应用问题也得到了研究[6];还有一些学者研究了控制系统与免疫机制的关系[7]。目前国内外学者们针对抗体群多样性特性的研究已经提出多种改进的人工免疫算法[8],然而关于人工免疫算法中抗体的多样性特性问题仍有待进一步深入研究。随着人工智能和计算机技术的发展,一些新型的优化算法如:专家系统、Tabu搜索[9]、遗传算法[10]等都取得了一定的成果。
聚类(clustering)就是按照一定的要求和规律,使数据集中具有相似特性的对象成为一类,从而达到相同类内的对象间的相似性最大,不同类间的对象相似性最小[15]。聚类分析已成为数据挖掘、图像分割与压缩、目标特征识别等领域研究的一个重要方面。目前有许多聚类算法,这些算法基本上可以分为两类:分层和分块。与层次聚类相比,其将产生集群迭代融合或分裂的连续程度,划分聚类分配一组数据点为K个簇,没有任何的层次结构。这个过程通常伴随着准则函数的优化。K-means均值算法是广泛使用的分块算法之一,它是一种迭代的爬山算法。AIS应用包括以下几个方面:聚类、分类、异常检测、优化、控制、计算机安全、学习、生物信息学、图像处理、机器人、病毒检测和Web挖掘。
在这次研究中,试图使用克隆选择算法的随机优化方法用于聚类的可能性,提出基于克隆选择原理的非监督克隆选择聚类算法,该算法是数据驱动的自适应调整其参数,它对数据进行分类的操作尽可能的快。该方法已经测试了几个人工和现实生活中的数据集,把它的性能与已知K-means算法相比较。实验结果表明,所提出的算法具有更高的可靠性,在功能上比传统的分类方法具有较高的分类精度。
1 非监督的克隆选择聚类算法
1.1基本原理
在非监督克隆选择聚类算法中,聚类问题被视为优化问题,其目的是找到数据的最优分区,由此产生的聚类往往会尽可能紧密。非监督克隆选择聚类算法使用的准则是聚类内扩散准则,为了得到良好聚类,这一准则要被最小化。与使用均方误差准则测量聚类内扩散的K均值算法不同,非监督克隆选择聚类算法使用各聚类质心的点的欧几里德距离的总和作为分群量度,并用克隆选择算法作为聚类算法,这可以确保找到全局最优,而不像K均值算法之类的大部分算法只能得到局部最优。K聚类的数目应该是已知的,并且必须找到恰当的聚类中心m1,m2,…,mk,才能够使聚类度量J最小化。在数学上,K聚类C={C1,C2,…,CK}的聚类度量J由以下方程表示:
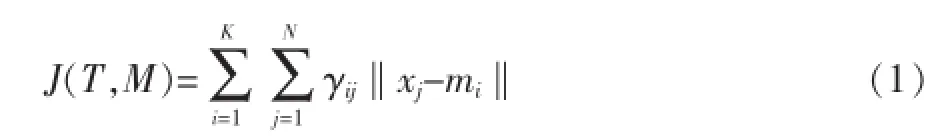
其中,χj∈Rd,j=1,…,N为数据点,Τ={Υij}为由公式(2)表示的分块矩阵。M是由公式(3)表示的质心矩阵,mi∈Rd,i=1,…,K含Ni数据点的Ci聚类的平均值。
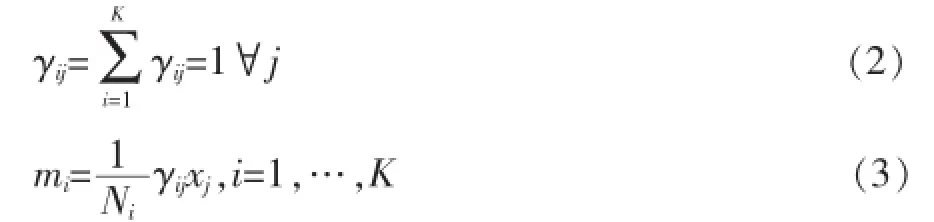
克隆选择算法的任务是寻找适当的集群中心由此使J最小化。基于聚类准则,如果集群紧凑且呈现超球面形状,非监督克隆选择聚类算法给出的结果应该是正确的。
1.2克隆选择算法
所有的克隆选择算法具有相同的基本步骤,总结如下:
生成抗体的种群P(候选解):
当不满足停止准则时{
根据它们的亲和度克隆P
对结果种群进行超变异方案
选择最高亲和度形成新的种群
维持种群的多样性}
选择最高亲和力抗体形成免疫记忆;
以上是克隆选择算法的伪代码流程。
设计和运行一个克隆选择算法时,必须考虑一些关键问题,例如:表现解决方案、保持种群多样性、亲和度度量和超变异机制。以上任一方面的微小变化都可能导致克隆选择算法执行中产生相当大的改变。
非监督克隆选择聚类算法伪代码描述如下:
初始化:随机生成N抗体的种群P(候选解):
对每一个代{
种群P中所有抗体亲和度测试
克隆P生成一个种群PC
对PC进行超变异方案,生成Pm,合并P&Pm
所有抗体亲和度测试
重新选择n最高亲和度来形成种群P
生成新L个体(随机)
在种群P中,用新个体取代最低L亲和度抗体}
最后:选择P种群中最高亲和度抗体。
1.3解决方案
种群P中各抗体形成一串实数代表K聚类中心。D维空间中,数符串的长度是d*K数目,其中聚类中心的坐标逐一定位。
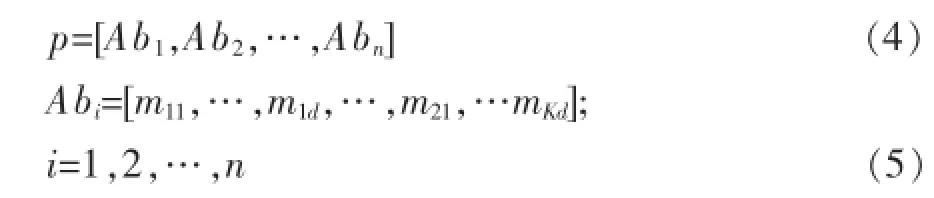
第一批数字d代表第一个聚类中心的d维度;下一批d位置代表第二个聚类中心的d维度,如此类推。
1.4亲和度度量
测量一个抗体的亲和度,会根据经考虑的抗体中的编码中心形成聚类,这是通过将χj∈Rd,j=1,…,N每个点分配给聚类Ci的每个集群做到的,该聚类的中心最靠近点。该聚集完成后,新的聚类质心通过找各自聚类的平均点计算得到,然后聚集标准J由公式(1)计算得到。该亲和度被定义为:

亲和度最大值代表J最小值。如果任何聚类变为空,亲和度用零表示。
1.5克隆
种群P的抗体比照其亲和度正比被克隆,亲和度越高,抗体生成的克隆数量越多。抗体按亲和度降序排序,抗体生成的克隆数量由以下方程式表示:

其中,nci是克隆数量,β是克隆因素。
1.6超变异
PC种群中,每个抗体服从于一种与亲和度成反比例的突变,这种突变按以下方程完成:

其中,Ab*是Ab变异所产生的抗体,N(0,1)是一个零均值且标准偏差为1的d*K高斯随机变量的矩阵,aff是抗体的亲和度,其被规范在[0,1]区间。α是一个调整高斯变异数值的因素,其与亲和度成反比,亲和度可控制α的范围。为达到算法快速、数据驱动的目的,这个因素表示为以下方程式:

其中,最大数据和最小数据是所有维度中的数据特性的最大值和最小值。通过这种方式,突变概率取决于抗体亲和度及搜索范围。
1.7新抗体生成器
为生成新的随机解,决定了搜索范围,就是特征空间里的数据分布范围。数据范围用每个维度的数据上限和下限计算得到:
其中,rand是一个[0-1]区间含均等概率分布的d*K随机变量的矩阵。该新随机解生成器可用于确保非监督克隆选择聚类算法快速、准确地执行,因为所有的解答都在搜索范围之内,因而能加快算法的收敛速度。
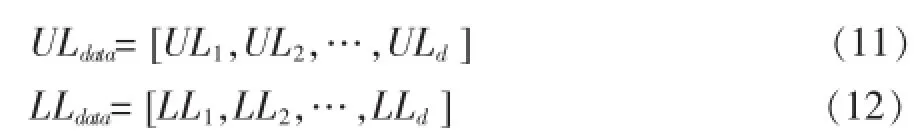
其中,UL数据,LL数据分别是特征上限和下限的矩阵。新的随机解依照以下方程式生成:
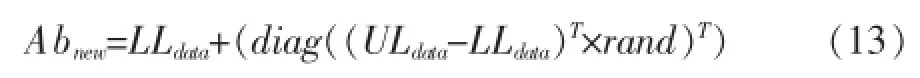
2 实验
通过几组人工数据集和实际数据集对非监督克隆选择聚类算法进行测试,然后将其与众所周知的K均值算法进行对比[1]。非监督克隆选择聚类算法经以下参数进行测试,n=10,β=5,L=4,代的数目gen=30。K均值算法,在不正常终止的情况下,1000被作为最大迭代数。在每个实验中,算法以不同的随机初始配置进行100次。为提供执行情况的统计学评估,数据集描述如下:
2.1人工数据集
数据集1:由重叠的两类(各为100模式)组成的人工数据集,其二元高斯密度用以下参数表示:m1=(0.1,0.1),m2=(0.35,0.1)。该数据集如图1所示:

图1 由两类组成的人工数据集1
数据集2:由9类(各为25模式)组成的人工数据集,其二元高斯密度用以下参数表示:
m1=(0.1,0.1),m2=(0.1,0.5),m3=(0.1,0.9),m4=(0.5,0.1),m5=(0.5,0.5),m6=(0.5,0.9),m7=(0.9,0.1),m8=(0.9,0.5),m9=(0.9,0.9)。
该数据集如图2所示。
数据集3:由3个类(各为50模式)组成的人工数据集,其二元高斯密度用以下参数表示:
m1=(1,1,1)
m2=(2,2.5,2.5)
m3=(2,3,3)
该数据集如图3所示。
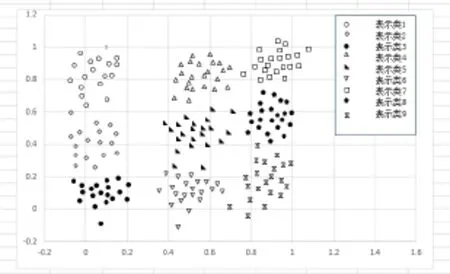
图2 由九类组成的人工数据集2

图3 由三类组成的人工数据集3
2.2世纪数据集
以下实际数据集已经被测试:
(1)玫瑰花数据集有150个四维模式,分为三个类(各50模式)组成,各代表有四个不同类别玫瑰花的特性值。这四个特征值代表花萼长度、萼片宽度、花瓣长度和花瓣宽带,以厘米计算。这三个类是:数据类1、数据类2和数据类3。
(2)乳腺癌数据集有699个9维模式,分为两个类组成,一类良性的(458模式)和一类恶性的(241模式)。9个特征是:肿块厚度、细胞大小的均匀性、细胞形状的均匀性、边缘附着力、单上皮细胞大小、裸核、微受激染色质、正常核和有丝分裂。
3 实验结果及分析
非监督克隆选择聚类算法最佳分类结果和实验运行100此后的K均值如表1所示,其中包括所获的所有数据集分类精度。从表1中我们可以看出:非监督克隆选择聚类算法比K均值算法更准确。

表1 所有数据集的分类结果
实验表明,即使是简单数据,K均值算法在次佳解就卡住了,但非监督克隆选择聚类算法却不会如此。表2展示了J的最佳值,及每个数据集中非监督克隆选择聚类算法和K均值算法的总运行次数的J百分比。从表2我们可以看出,对于所有数据集,非监督克隆选择聚类算法发现的解答比K均值算法发现的解答更好,并且由非监督克隆选择聚类算法形成的聚类比由K均值形成的聚类更紧密。结果表明,非监督克隆选择聚类算法比K均值算法更可靠,因为它始终能发现最佳解,而不像K均值算法并不能每一次都找到最佳解。

表2 不同数据集的J的值
所有实验中,不到30代,非监督克隆选择聚类算法就找到了解答。
4 结语
本文提出了基于克隆选择原理的非监督克隆选择聚类算法用来找到数据之间的最优分区。它使用聚类内传播标准作为聚类标准。该标准基于聚类中数据之间的欧几里德距离。新算法是数据驱动和自适应的,可根据数据调整参数,以实现尽可能快的分类操作。
通过几组人工数据集和实际数据集对非监督克隆选择聚类算法进行测试,然后将其与众所周知的K均值算法进行对比。实验表明,非监督克隆选择聚类算法比K均值算法的分类精度更高,后者即使在简单数据集中,在次佳值就卡住了。新算法在第30代就可以找到解答,而且使用的种群规模小n=10,而其他大多数评估算法需要至少为100的种群规模。如果聚类紧凑且呈超球面形状,非监督克隆选择聚类算法可以给出更好结果。
[1]高静,应吉康.基于人工免疫系统的推荐系统[J].计算机技术与发展,2007,17(5):180~183
[2]漆安慎,杜婵英.免疫的非线性模型[M].上海:上海科技教育出版社,1998:7
[3]蔡自兴,龚涛.免疫算法研究的进展[J].控制与决策,2004(8):P842
[4]焦李成,尚荣华,马文萍,公茂果等.多目标优化免疫算法、理论和应用[M].北京:科学出版社,2010:P43
[5]Jiao Licheng,Wang Lei.Novel Genetic Algorithm Based on Immunity[J].IEEE Trans on Systems,Man and Cybernetics-PartA:Systems and Humans,2000,30(5):552~561
[6]Ha Daew on,Shin Dongwon,Koh Dwan-Hyeob,et al.Cost Effective Embedded DRAM Integration for High-Density Memory and High Performance Logic Using 0.15Lm Technology node and Beyond[J].IEEE Trans on Election Devices,2000,47(7):1499~1506
[7]Ding Yong-sheng,Ren Li-hong.Fuzzy Self-Tuning Immune Feedback Controller for Tissue Hypert Hermia[A].IEEE Int.Conf.on Fuzzy Systems[C].San Antonio,2000,1:534~538
[8]颜伟,孙渝江,罗春雷,龙小平,黄尚廉.基于专家经验的进化规划方法及其在无功优化中的应用[J].中国电机工程学报,2003,23(7):76~80
[9]刘玉田,马莉.基于Tabu搜索方法的电力系统无功优化[J].电力系统自动化,2000,24(2):61~64
[10]方鸽飞,王惠祥,黄晓烁.改进遗传算法在无功优化中的应用[J].电力系统及其自动化学报,2003,(4):15~18
Unsupervised Clonal Selection Clustering Algorithm Based on Immune Algorithm
WEI Ling
(Department of Electrical and Computer Engineering,Lushan College,Guangxi University of Science and Technology,Liuzhou 545006)
Based on the detailed analysis of clonal selection algorithm,proposes unsupervised clone selection clustering algorithm.Which is adaptive data driven by adjusting its parameters,it carries on the classification of data operations as soon as possible,improves the premature convergence problem,improves the speed of data clustering.By using several artificial and real-life data sets,comparing the performance between unsupervised clonal selection clustering algorithm K-means algorithm.The experimental results show that,this algorithm solves the K-means algorithm needs several classes of K determined in advance,and the second best value stuck faults,the classification accuracy,and it is much better than traditional K-means classification algorithm in function and with higher reliability.
Artificial Immune Systems;Clonal Selection Algorithms;Clustering;Multi-Objective Optimization;K-means Algorithm
广西科技大学鹿山学院科学基金项目(No.2013LSZK05)
1007-1423(2015)11-0021-05
10.3969/j.issn.1007-1423.2015.11.004
韦灵(1979-),男,广西柳州人,硕士,助教,研究方向为人工智能、数据处理、挖掘和分析
收谢日期:2015-02-052015-03-19
猜你喜欢
今日农业(2022年15期)2022-09-20
湖南电力(2021年1期)2021-04-13
铁道通信信号(2019年6期)2019-10-08
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
红土地(2018年7期)2018-09-26
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
