
文本易读度相关研究评述
2015-08-20 03:38:44刘潇
湖北大学学报(哲学社会科学版) 2015年3期
刘 潇
(武汉大学外国语学院,湖北武汉420072)
1.引言
进入信息社会后,人们可阅读到的文本呈现爆炸式的增长。在外语教学领域,《欧洲语言共同参考框架:学习、教学、评估》(CECR)中提倡使用真实语料作为教学材料。而根据前苏联心理学家维果茨基(Vygotsky,1978)的最近发展区理论(Zone of Proximal Development)假设和美国语言学家克拉申(Krashen,1989)的语言学习输入i/i+1理论(The input hypotheses),教学材料应当稍高于学习者当前水平,才能达到最佳效果。但是,对于教学者和自学外语的学生而言,在繁多的资料中选取难度合适的文本,需要大量的时间与精力,他们迫切需要有力的工具以提高选取阅读材料的效率。
为满足这一需求,必须采用量化的方法,高效率地评估文本的困难程度,即易读度(readability,也译作易读性)①对应的法语单词为lisibilité。国内相关文章多采用“易读性”这一译法。“易读性”也更为贴近外语单词本义。但为强调对文本易读程度的量化测量,此文中主要采用“易读度”这一译法。。美国早在上世纪20年代就开始致力于相关研究,并将总结出的易读度公式运用于英语教学、新闻、军事等多个领域,以确保相关行业的文本更易为大众所理解。2007年以来,这一课题也引起国内英语教学、对外汉语和新闻等领域的学者越来越多的关注②根据中国知网的“学术趋势”功能中的“学术关注度”对“易读性”和“易读度”两个词条的反馈,可以看到,具有这两个关键词的文本的收录量之和在2007年之后有较大幅度上升。。
本文试图对易读度在英语、汉语和法语三个语种的国内外研究方法和成果进行综述,并将重点放在教学领域。在第二部分中,分别介绍国外的英语和法语易读度研究的历史、发展和应用情况;第三部分则将目光转向国内,概览英语教学界和汉语学者在易读度上的成果;最后总结目前研究存在的问题,尝试预测这一领域的发展趋势。
2.国外易读度研究
2.1英语易读度研究
与语言学研究的其他分支相似,美国学者在文本易读度方面的研究走在前列,也最为成熟。最早的研究始于上世纪20年代莱弗利和普莱西(Lively&Pressey,1923)对教材词汇难度的考察。相关研究的内容主要集中在两个方面:影响易读度的因素和易读度的测定方法。与之相关的还有语料的选取,以及评估测量结果的方法等问题,本文暂不讨论。
从研究方法的演变,到研究工具的发展,文本难度研究大致可分为三个阶段(Thomas François,2012):
(1)20世纪20至70年代,易读度的主流研究方法一直是由沃格尔和沃什伯恩(Vogel&Washburne)在1928年所提出的多元线性回归模型。研究者将词汇和语法作为区分文本难度的特征,选用单词长度(或测量Dale-Chall等常用词表之外单词所得到的生疏词比例)及句长等2(或3)个变量,通过手工抽样或(50年代之后逐渐采用的)机器辅助统计的方式测出变量值,按其与易读度的相关度为每个变量赋以权重并相加,构建出上千个易读度公式。
以弗雷奇(Flesch)在1948年提出的Flesch Reading Ease为例:
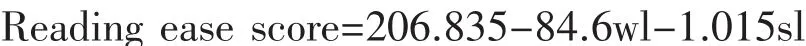
其中,wl(word length)=每个单词的平均音节数,sl(sentence length)=每个句子的平均单词数。
该公式算出的分数取值区间为0-100。分数越低,说明文章越难。其数值对应的难度参照表如下:

(表 1)
Flesch Reading Ease和Flesch-Kincaid Grade Level是得到最为广泛应用的两个公式。二者都采用单词和句子长度作为语义和句法复杂度的依据,均被内置于Microsoft Office Word软件。后者更是美国国防部使用的标准文本难度测量公式。
此外,较常用的公式还有:Gunning-Fog Score,Coleman-Liau Index,Automated Readability Index(ARI),SMOG Index,Dale-Chall Readability Formula,Fry Readability Formula,Spache,FORCAST 等。它们的预测变量都采用了传统的一个词汇因素加一个句法因素的形式,提出的时间较早,介于40年代末和60年代末之间。这些公式至今仍是易读度应用的主要工具。
以上易读度公式具有显著优点:使用起来十分便捷,所需的变量也易于获取。但其缺点同样明显:对文本难度的评估被过度简化。2~3个变量远不足以表达文本的复杂程度。词长等因素本身与易读度的关联也有争议。因此,必须引入新的思路和技术来评估文本难度。
(2)20世纪80至90年代,Kintsh、Vipond和Kemper等认知心理学专家对传统方法进行了批评,认为这些公式采用的仅仅是文本表层的特征,忽略了文本真实的复杂度。他们指出:在阅读时,读者不仅对文章进行词汇的辨认和语法的解读,还需从概念上理解文本背后的涵义。鉴于此,他们提出了许多基于语义和篇章等认知心理学领域因素的特征,如概念本身的难度(虚词的比例、人称代词、同形多义词的数量),概念密度(小句的数量),回指的密度以及彼此的距离,近义词或逻辑联结词,相邻句子之间的相似度,词汇覆盖度(即两句之间相同的名词/论元/词干的数量)等等。
然而,他们的研究并没有提升难度区分的准确率,无法证明其相对于传统方法的优越性,反而因方法复杂常需手工统计,难以实践而未得到广泛采用。在这一时期,易读度研究的发展陷入停滞和低潮。
(3)20世纪90年代至今,随着越来越多学科与计算机和信息领域相交叉,自然语言处理技术不断成熟,相关研究成果也被应用到易读度研究中。其中绝大多数的研究针对英语文本难度。研究者总体上对相关技术在实现更准确的文本难度量化评估中的作用持审慎的乐观态度。
这些新方法有如下几个特点:(1)采用机器学习技术;(2)引入包括语义和篇章类型的更多变量,以建立复杂的模型;(3)需要大量文本作为数据库。
Foltz等学者在1998年最早引入了潜在语义分析技术(Latent Semantic Analysis,缩写为LSA)①1988年由S.T.Dumais等人提出的一种新的信息检索代数模型,它使用统计计算的方法对大量的文本集进行分析,从而提取出词与词之间潜在的语义结构,用来表示词和文本,达到消除词之间的相关性和简化文本向量实现降维的目的。以分析文本的连贯性。他们将文本作为大量不同特征值构成的向量空间,处理为许多数据的集合,实现分析比对。Si和Callan于2001年最早将易读度问题归为自然语言分类的一个子问题,从而将它与人工智能和机器学习领域联系起来。从此,多元线性回归不再是测量易读度的唯一数学模型,朴素贝叶斯、支撑向量机(SVM)等算法成为了这个领域的有力工具。
与传统的易读度公式相比,他们使用的变量更多,建立的统计模型更为复杂。目前,这一新方法还未明显建立起相对于传统公式的优势,但他们提供了将认知心理学家提出的新变量与传统变量结合起来的可能,找到了该领域发展的突破口。
美国政府一直大力支持易读度相关研究和将其成果推广应用。卡耐基-梅隆大学的语言技术学院正开展的基于网络文本的REAP(READer-specific Practice)项目就得益于美国教育部的支持。它能对阅读者进行预先测验,再有针对性地推荐适合对象阅读水平的文本。经过匹兹堡大学英语学院的教学实验,该系统被认为能较好地融入正常的教学计划中,取得了阶段性成功(Feeney&Heilman,2008)。
商用方面,易读度研究在母语教学领域的应用最为常见。MetaMetrics公司开发的蓝思阅读测评系统(Lexile Framework)就是其中的成功案例。他们通过计算大样本的教材难度,为每个年级提出了必读文本难度和扩展文本难度分值,推动了儿童分级阅读的专业合作与指导(罗德红、余婧,2013)。除英语外,该公司的阅读评测系统还有西班牙语版。2009年,他们还与托福考试(TOEFL)的研发和主办机构——美国教育考试服务中心(ETS)合作,将托福考试阅读部分的分数联入蓝思测评系统。
美国孟菲斯大学(University of Memphis)的Coh-Metrix系统则侧重于文本的连贯性。在二语习得领域,它所采用的Coh-Metrix L2 Reading Index的表现优于传统易读度公式,但59%的分类准确度在实践中仍不能让人满意(Crossley&al.,2011)。
此外,在军事、新闻、保险等领域,易读度研究也发挥着作用,用以确保相关文本更易为大众所理解。如美国马萨诸塞州保险委员会规定保险单的易读度用Flesch Reading Ease公式计算得分应不低于50,而明尼苏达州则要求不低于40(晏生宏、黄莉,2005)。
2.2法语易读度研究
直到1956年,法语世界才通过André Conquet的著作《易读度》(La lisibilité)接触到这一领域。在20世纪50至60年代,Kandel、Moles和Landsheere改造Flesch Reading Ease以适应法语文本。最早的原创公式是Henry在1975年提出的。随后,Cornaire在1988年将Henry的公式应用于FLE教学。Uitdenbogerd在2005年针对母语为英语的法语学生构建了自己的易读度公式,将两种语言的词汇相似度作为变量之一(François,2009)。
近年来,比利时鲁汶天主教大学的François(2012)致力于利用语言自动处理技术提高文本易读度的准确度,并应用于FLE领域②他的研究面向的对象是母语非特定某种语言、非为特定目的学习法语(FOS)的成年人。。François采取由教学专家预先按照《欧洲语言共同参考框架:学习、教学、评估》(CECR)标准分类③《欧洲语言共同参考框架:学习、教学、评估》(C E C R)中将语言学习者的能力分为A 1、A 2、B 1、B 2、C 1、C 2,共6级。此外,还可加入A 1+、A 2+、B 1+,细化为 9个等级。的法语教材作为语料,通过机器学习和文本挖掘的方法对406个变量进行实验。他确认传统所采用的词汇变量(尤其是常用词表之外的单词所占比例)仍是最佳特征值,证明语言自动处理技术引入的基于LSA的变量和词类等变量对准确评估文本易读度的效果显著;而短语和多元模型等变量则并不比传统公式采用的变量更有效。他的实验结果显示:实现较好的文本难度自动评估所需的特征值数目远超传统公式。通过对47个特征值(包含传统特征及语言自动处理技术所发掘的新特征)的最优运用,能得到比传统方式高15%的准确度。在统计模型方面,Boosting方法④Boosting(增强)方法是一种集成学习的分类方法,反复使用多个准确度较低的弱分类器,在每次迭代中增加被分类错误样本的权重,最终分类器通过对多个弱分类器结果按不同加权投票建立。和SVM方法效率最高,而前者在屡次迭代过程中花费时间过长,因此采用SVM方法。
这两种方法也是目前机器学习领域广泛认定具有较好效果的模型。最终模型在将语料根据CECR标准分为6类和9类难度时取得了准确率49%和35%的最佳效果,大致相当于未经专业训练的普通人进行难度分类判断时的结果。尽管这样的表现离实际应用还有较大差距,但这也正反映出研究的困难度。
3.国内易读度研究
3.1英语易读度研究
在2.1中,我们看到:美国的英语文本难度研究已取得不少成果,在较多领域进入应用层面,具有借鉴意义。但这些方案主要面向的是以英语为母语的读者,针对的是美国人的阅读能力和特点,不能将这些公式和工具简单照搬到面向二语习得者的英语教学及其他语种的易读度测量中。王晶(2010)对不同水平的中国英语学习者进行阅读测试,发现大多数学生对测试所选用的6篇文本的难度排序和实际阅读能力的表现不符合Flesch Reading Ease公式的预测结果。可见,中国学习英语的阅读者需要适合自身特点的软件和工具。
在我国英语教学领域,林铮(1995)最早对国外易读度研究进行了综述。此后,李绍山(2000)、晏生宏(2005)、章辞(2010)等也开始关注这一课题。目前,国内已自主开发了以下三款自动测量英语文本难度的软件,但尚未得到大规模应用。
福建师范大学外国语学院开发了ERDA软件,分中学版和大学版两个版本。采用的公式中选取词汇和句法两个变量。词汇按习得的顺序分等级,中学版按年级数分为6个等级,大学版根据教委颁布的大纲分为8个等级。句长按单词数分为4个类型。不同等级的词汇、句子类型分别乘以给定的系数,结果介于 0-10之间(林铮,1995)。
重庆大学的ERMS系统以Flesch Reading Ease为计算公式。它将词汇分为大学前、英语四级、英语六级、研究生四个等级建立以大学英语教学大纲词汇表为基础的词库。词库具有开放性,可更新。除统计句子数、总音节数、总词数后利用公式得出分数外,该软件还可通过类符/词符比统计词汇密度(晏生宏、黄莉,2005)。
解放军外国语学院的IRMS系统则未采用传统的易读度公式,采用了自然语言处理技术。邢富坤、程东元(2007,2008)基于信息计算开发的原理,通过对语篇信息量、词熵、句熵的统计,进行易读度测量。其成果比上述两款软件具有更强的普遍适用性,易于转换为其他语种的易读度测量工具。
刘海清(2013)则呼吁学者对公安等特殊行业的英语教材开发有针对性的易读性软件。然而,受语料库大小、相关理论研究水平和易读度研究难度等条件制约,目前易读度研究主要针对的都是有较大样本量的普通阅读者。在普通易读度研究取得重大进展前,此类特殊需求很可能会长期无法得到满足。
此外,我国英语教学专家也注意使用国外开发的文本难度测量软件。2008年7月27日,外语教学与研究出版社在北京举办了“全国高等学校英语教师教育与发展系列研修班”第4期——“语料库在外语教学中的应用”。许家金向教师介绍的实用软件中,就包含了日本早稻田大学的Laurence Antony开发的Ant Word Profiler。王正胜(2010)也发文介绍了这款软件的使用方法。然而,这款软件仅能用于统计常用词表在文本中的分布情况,尚不能测量并评估文本的具体难度。
也有一些研究者运用文本易读度公式和软件来研究英语阅读教学。蒋晶晶(2009)运用6种易读度公式评估英语分级考试CEPT文本中出现的词汇难度情况,认为Flesch-Kincaid Grade Level公式最为可信。辜向东和关晓仙(2003)对CET阅读测试和大学英语阅读教材进行了易读度抽样研究。李安心(2012)利用Ant Word Profiler和SPSS软件对高考英语湖南卷的阅读理解进行了文本难度因素分析。王丽(2011)利用Office Word软件自带的Flesch Reading Ease公式对高职英语教材中的阅读材料做了抽样分析。
陈炎龙和张志明(2010)则对传统的易读性公式进行了批评,认为它们虽然容易施行,但计算值过于集中,不利于进行等级划分。作为改善,他们提出以词汇为特征值,建立文本分类时常用到的向量空间模型。这样的方法符合国际易读度研究倾向于采用自然语言处理技术的新趋势。
目前我国英语界学者对易读度的研究成果较丰富,不仅有对国外开发的传统公式的借鉴和应用,更有自主创新,部分最近成果符合国际上采用自然语言处理技术的新趋势。但在应用和分析文本难度时,被广泛使用的仍是国外的传统公式,我国自主研发的几款软件在推广方面仍有不足。另外,在研发易读度工具时,缺少统一的、大规模的英语教材语料库支持。这些都有待在今后研究中得到改善。
3.2汉语易读度研究
和法语以及其他外语相似,汉语易读度研究起步较晚,成果也较少。早期研究直接借鉴英语的易读度公式,逐渐开始构拟原创的易读度模型。研究对象也从是母语阅读者开始,慢慢扩展到面向外国的二语教学领域。
在新闻领域,台湾学者于宗先在1959年最早应用Flesch Reading Ease易读公式,但仅为直接照搬,未考虑汉语与英语的差异。1970年,陈世敏改良了Gunning-Fog Score。在同时或稍早时候,留美学者杨孝溁也进行了中文易读性公式的构拟。这些探索都受到英语文本难度公式启发,并将其改良,应用于汉语。他们的共性是只考虑了字或词的简单特征,忽略了文本的复杂程度(黄敏,2010)。
陈阿林和张素(1999)模拟人工神经网络,建立了汉语的阅读难度量化计算模型。该模型考虑了平均句字长、平均句词长、全体词集使用度、全体句子使用频度、文体等变量。其中文体变量由人工取值。
在儿童母语阅读领域,接力儿童分级阅读研究中心发布的中国儿童分级阅读指导手册(2010版)中虽然提到,该手册参考了国外分级阅读理论,但实质上仍然是由专家人工完成难度分级。
对外汉语教学中,王蕾(2005)通过多元线性回归的方式,以汉语水平是初、中级的日韩留学生的完形填空成绩为语料建立了一个可读性公式,其中考虑了简单词的比例、虚词数和分句数这三个变量。郭望皓(2009)考察了汉语句子难度与字、词难度的关系,并利用CRITIC加权法得到一组8个以《汉语水平词汇与汉字等级大纲(修订本)》为难度划分,利用现有的字、词难度等级来预测句子难度的公式。江少敏(2009)将易读度的研究层面从宏观转向微观,在句子层面研究难度分级。他基于对留学生和小学生的问卷调查,建构了一套度量公式并制作了对应的软件。
由于汉语和英语、法语等欧洲语言在形态、语法上有极大差异,在汉语易读度研究上,需要更多的创新精神,能借鉴的工具有限。另外,受限于目前中文自然语言处理的整体水平,相关的研究和应用较少。相对于对外汉语教学领域的学者,儿童分级阅读方面的教学专家更缺乏量化评估的尝试。
3.3法语易读度研究
目前,我国法语教学界尚无文本易读度方面的研究。虽然上海外语教育出版社从2005年起陆续出版了根据欧盟通行的CECR标准分类的法语分级注释读物丛书,但并不是基于量化的易读度研究基础上评定难度,而是采用专家人工分类的方式。
为填补这一领域的空白,研究者可一方面关注法语世界在易读度和文本处理方面的最新研究成果,另一方面从中国法语教学界使用的教材和分类标准、中国学生学习法语(尤其是阅读时)普遍的难点等方面着手,收集教材课文、课外阅读材料、学生阅读测试结果等资料,建立包含各级难度文章的语料库,测试词汇、句法等因素对学生理解文章难度的影响,为研究打下基础。
4.结语
作为新兴领域,易读度有广阔的社会应用前景,涉及到文本阅读的各个层面。它能有助于教材编写者高效、客观地评价教材,提高教材的选材效率和编写水平;能提高教师选择更适合学生水平的真实语料(尤其是网络文本)的效率;能辅助学生自主选择课外阅读文本,并对其阅读能力提供反馈和评估;能帮助作者(特别是科普作家和儿童作家)提高文本的可读性,促进作品的传播;能辅助降低新闻报道、技术手册、科技文献、法律文本等的难度,以确保相关文本更易为大众所理解。
目前,在英语之外,汉语、法语等语种的易读度研究较为滞后。国际上得到最广泛应用的传统易读度公式还是上世纪50至60年代的产物,所选用的用于测量文本难度的变量(如词长、句长等)相对粗疏,不足以反映文本本身的复杂程度,准确率离实际应用还有较大差距,仍有很大的改进空间。
可见,文本的易读度是一个复杂的问题,需要教学法专家、语言学专家与计算机专家、认知心理学家建立跨领域的深入合作,以取得贴近实际应用需要的成果。
首先,需建立难度分类准确、包含大量各类文本、且符合实际教学等工作需要的语料库。目前文本易读度的语料来源较单一,多为课文,可能导致结果对教学材料的过拟合,即仅能对作为样本的语料进行有效分类,影响对生活中报刊、说明文等其他类型文本的难度判定。另外,由于分类越多越易出错,为取得较好的分类效果,部分研究仅将文本分为易、中、难三类,难以贴合实际运用的需要。
其次,为取得这一领域的突破,离不开自然语言处理技术的支持。受当前相关技术发展的制约,目前在综合考察影响文本难度的变量时,体现出强烈的“词汇主义”倾向,对跨词汇、跨句子的文本关联性及句法复杂度等因素缺乏有效的统计方法,甚至不作考量。研究者需注意吸收句法分析、自动摘要等自然语言处理技术的新成果,综合各种影响文本难度的因素,对易读度进行更全面的研究。
此外,外语教学是易读度的重要应用领域,但相较于母语教学,对二语习得方面的易读度研究受到的关注更是严重不足。由于作为目标语的英语、法语和作为母语的汉语差异巨大,时态、词型变化等语法特征给中国学生带来的难度明显大于其对欧洲学生的影响。应将这些差异带入易读度研究中,予以逐一验证。
[1]Vygotsky Lev Semyonovich.Mind in Society:The Development of Higher Psychological Processes[M].Cambridge,Mass:Harvard University Press,1978.
[2]Krashen S.D.We Acquire Vocabulary and Spelling by Reading:Additional Evidence for the Input Hypothesis[J].The Modern Language Journal,1989,(4).
[3]Lively Bertha A.,Pressey S.L.A method for measuring the“vocabulary burden”of textbooks[J].Educational administration and supervision,1923,(9).
[4]François Thomas.Modèles statistiques pour l’estimation automatique de la difficulté de textes de FLE,Rencontre des Êtudiants Chercheurs en Informatique pour le Traitement Automatique des Langues(RECITAL 2009)[EB/OL].http://cental.fltr.ucl.ac.be/team/tfrancois/articles/Francois 2009b.pdf.
[5]François Thomas.Thèse:Les Apportsdu Traitement Automatique du Langageàla Lisibilitédu Français Langue Ètrangère[D].Louvain-la-Neuve:Université catholique de Louvain,2012.
[6]François Thomas,Fairon C.Les apports du TAL à la lisibilité du français langue étrangère[J].Traitement Automatique des Langues(TAL),2013,(1).
[7]Feeney,Heilman.Automatically Generating and Validating Reading-Check Questions[J].Intelligent Tutoring Systems Lecture Notes in Computer Science,2008,(5091).
[8]Crossley&al.Text readability and intuitive simplification:A comparison of readability formulas[J].Reading in a Foreign Language,2011,(1).
[9]晏生宏,黄莉.英文易读度测量程序开发探索[J].重庆大学学报:社会科学版,2005,(2).
[10]罗德红,余婧.儿童分级阅读研究的中美对比分析[J].图书馆,2013,(2).
[11]林铮.英文易读度的测定[J].外语教学与研究,1995,(4).
[12]李绍山.易读性研究概述[J].解放军外国语学院学报,2000,(4).
[13]章辞.英文易读性研究:回顾与反思[J].湖南工程学院学报:社会科学版,2010,(3).
[14]邢富坤,程东元,等.英文文本难度自动测量系统的研制与开放[J].现代教育技术,2008,(6).
[15]邢富坤.基于信息计算的英语易读性研究及IRMS应用系统开发[D].北京:中国人民解放军外国语学院,2007.
[16]王正胜.英语文本易读性测量软件AntWordProfiler的使用[J].外语艺术教育研究,2010,(4).
[17]蒋晶晶.CEPT阅读文本易读度分析及词汇检测工具的开发[D].长沙:湖南大学,2009.
[18]辜向东,关晓仙.CET阅读测试与大学英语阅读教材易读度抽样研究[J].西安外国语学院学报,2003,(3).
[19]李安心.高考英语湖南卷阅读理解文本难度因素分析[D].长沙:湖南师范大学,2012.
[20]王丽.高职英语教材中阅读材料易读度的抽样分析[J].辽宁高职学报,2011,(8).
[21]刘海清.公安行业英语教材易读性研究述评[J].牡丹江教育学院学报,2013,(4).
[22]陈炎龙,张志明.基于向量空间模型的英文文本难度判定[J].电脑知识与技术,2010,(12).
[23]黄敏.汉语特质与中文新闻易读性公式研究[J].新闻与传播研究,2010,(4).
[24]陈阿林,张素.中文阅读难度模型及易读性公式探索[J].计算机科学,1999,(11).
[25]王蕾.初中级日韩留学生文本可读性公式初探[D].北京:北京语言大学,2005.
[26]郭望皓.对外汉语文本易读性公式研究[D].上海:上海交通大学,2010.
[27]江少敏.句子难度度量研究[D].厦门:厦门大学,2009.
[28]王晶.验证易读性程式是否适合中国英语学习者[D].上海:华东师范大学,2010.
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29 05:08:09
新高考·高二数学(2022年3期)2022-04-29 05:08:09
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14 07:36:40
天津外国语大学学报(2020年1期)2020-03-25 13:29:08
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
中学生数理化·高一版(2018年6期)2018-07-09 06:00:54
英语知识(2016年1期)2016-11-11 07:08:01
外语教学理论与实践(2016年4期)2016-06-11 06:05:04
小学教学参考(2015年20期)2016-01-15 08:44:38
