
云计算中基于动态阈值的服务器唤醒策略
2015-08-17 11:23程春玲张登银
系统工程与电子技术 2015年6期
程春玲,王 颖,张登银
(1.南京邮电大学计算机学院,江苏南京210003;2.南京邮电大学物联网科技园,江苏南京210003)
云计算中基于动态阈值的服务器唤醒策略
程春玲1,王 颖1,张登银2
(1.南京邮电大学计算机学院,江苏南京210003;2.南京邮电大学物联网科技园,江苏南京210003)
基于预留机制的服务器动态开启/关闭(dynamic powering on/off servers,DPS)策略采用静态设置的任务请求数阈值,可能造成服务器状态频繁切换从而导致性能下降、能耗上升。对此,提出一种基于动态阈值的服务器唤醒策略。首先,用具有不耐烦任务的排队模型对云计算系统的任务调度进行建模,分析系统中的平均任务背叛数和能耗成本,提出任务请求数阈值动态调整策略;然后,根据服务器所在冷点区域和当前关闭时长选择服务器进行唤醒。仿真结果表明,与基于静态阈值的服务器唤醒策略相比,本文策略能够保证任务的平均响应时间,并有效降低云计算系统的能耗开销。
云计算;服务器动态开启/关闭;动态阈值;排队论;不耐烦任务
0 引 言
近年来,随着云计算规模的不断增长,数据中心产生的能耗不断增多,使云数据中心已经出现两难的情况:一方面由于物理服务器数量的不断增多和处理能力的不断增强,带来了更多的能量消耗;另一方面每个服务器过低的利用率又造成了巨大的电能浪费[1]。目前,高能耗问题已经成为云计算领域突出的问题,严重制约着云计算技术的发展。数据中心主要由IT设备、空调系统和配电系统3部分组成,调查显示,IT设备是能耗最高的部分,约占数据中心总能耗的50%,其中用于数据处理的服务器能耗约占40%,存储设备和网络通信设备能耗各约占5%[2]。然而在服务器能耗中,85%都是无效的,这主要是因为云数据中心的服务器通常长时间处于开启状态,等待云任务的到达,而云任务到达具有随机性,当任务稀疏时,服务器处于空转状态,造成无效电力[3]。因此,在当前和未来一段时间内,云数据中心的能耗优化管理尤其是服务器的能耗优化管理至关重要。
目前,能耗优化主要有两种思路:开发出更加节能的硬件设备和关闭空闲设备,文献[4]通过对云数据管理系统的测试和分析,提出降低“等待能耗”的第3种思路。在服务器能耗优化方面,服务器动态开启/关闭(dynamic powering on/off servers,DPS)技术仍是较为有效的一种方法。DPS技术通常针对服务器的开启/关闭时机进行设定或预测,在节点不提供服务的时段将其关闭,从而减少服务器能耗[5]。DPS技术主要包括超时策略、预测策略和随机策略3类[6]。超时策略的基本思想是预先设定超时阈值,一旦空闲时间超过阈值,就切换到休眠模式,阈值可固定,也可随系统自适应调整。固定阈值策略[7]适合于对节约功耗要求不高、运行中出现变化少的设备,若要提高节能效率,则需要考虑阈值自适应调整。文献[8]通过构建一个半马尔可夫控制过程模型,结合梯度估计与随机逼近提出了一种超时策略的自适应优化算法。算法设定初始阈值,求解一个带约束的优化问题,在满足性能要求的情况下,使得系统的功耗最小,从而得到一个最优的超时阈值。该算法可以以较少的计算量实现全局最优解。文献[9]分析了超时阈值选择的影响因素,证实了综合考虑系统休眠与唤醒的能量消耗、电池放电电压大小和系统具体的应用环境3方面是找到最优阈值的捷径。超时策略虽然实现简单,但是超时阈值难以合理的设置,若设置过大,服务器在等待超时的过程中仍然处于工作状态,不能有效地降低能耗;若设置过小,当新的任务请求到达时经常会引起服务延迟。预测策略的基本思想是通过对历史空闲时间长度的学习来预测将来的空闲时间长度,根据预测结果是否大于空闲时间阈值决定是否需要关闭或休眠服务器。文献[10]对经典的指数平均算法进行改进,提出了自适应指数平均算法(exponential double smoothing-based adaptive sampling,EDSAS),其应对空闲时间序列波动较大情况的能力有所增强。文献[11]提出了一种在线预测算法,该算法计算在固定间隔时间内没有任务到达服务器的概率P,若P>0.5,就将服务器关闭。预测策略通常要求空闲时间值具有前后关联性,然而现有的预测机制对于真实数据的预测效果均不甚理想[12]。文献[13]结合超时策略和预测策略提出了一种新的低功耗自适应混合算法,该算法能够在请求突发期间调整超时值,在请求非突发期间决定服务器状态,很好地适应了突发性的请求到达模式,与超时、预测策略相比,能够提供更低的功耗和更少的响应时间。随机策略将系统负载看成一个随机优化问题,利用随机决策模型求解算法。文献[14]提出了一个随机动态模型,描述了在不确定条件下的资源配置策略,该策略基于马尔可夫链概率模型,通过动态规划实现问题求解。文献[15]基于强化学习理论提出了一个自适应算法,与传统的随机算法相比,该算法不需要先验状态转移概率矩阵,能够很好地适应负载变化。随机策略是在给定性能约束条件下寻求最小功耗的线性规划问题,能够得到问题的相对较优解,然而该策略在实施过程中开销过大,算法复杂度高,可应用性较差[16]。
以上3种DPS策略都存在一定的不足,并且用户请求的任务量是动态变化的,而云数据中心的服务器失效是一种常态,倘若在大量关闭服务器节点的同时突遇用户任务请求高峰期,则由于启动服务器需要花费一定的时间而无法及时地、有效地应付云用户的请求,因此研究者开始研究基于预留机制的DPS策略。基于预留机制的DPS策略通过预留服务器来缓冲任务量的动态变化,该策略将数据中心的服务器分为两大模块,其中永久运行服务器构成服务主模块(service main module,SMM),等待启动的服务器构成服务预留模块(service reserved module,SRM),动态决定该预留模块中的服务器状态。文献[17]提出了never-off策略:数据中心的服务器全部开启,等待任务的到达并提供服务。相对于never-off策略,基于预留机制的DPS策略可以获得较好的节能效果。文献[18]从经济学角度出发,提出基于预留机制的服务器状态管理策略,根据用户支付给云数据中心的费用与云数据中心支付的电费的大小关系决定SRM中服务器的状态。另外,一些文献[19-21]从设置阈值出发,对服务器状态进行管理,当集群利用率、任务请求数或其他性能指标超出阈值时,开启SRM中的服务器;低于阈值时,关闭SRM中被开启的服务器。文献[19]设置服务器集群利用率阈值,根据系统当前的集群利用率与集群利用率阈值的关系动态地配置SRM中服务器的状态。文献[20]基于休假排队系统中休假时间选择的思想设置任务请求数阈值,该阈值的选取考虑了用户给定的延迟上限以及服务器的开启和关闭速率。文献[21]根据任务的期望执行时间将任务分配到相应任务缓冲区中,并设置任务错失率上阈值和任务请求数下阈值,当任务缓冲区中的任务错失率高于上阈值Ψ时,开启服务器,当任务缓冲区对应的任务请求数低于下阈值γ时,关闭服务器。文献[19]的集群利用率和文献[21]的任务错失率,本质上都是与任务请求数相关的,因为任务请求数越多,相对地,服务器集群利用率、任务缓冲区中任务错失率就越高。但文献[19-21]中与任务请求数相关的阈值都是静态设置的,不能根据实际情况动态调整。此外,当需要开启SRM中的服务器时,需要考虑选择哪个服务器进行唤醒。文献[22]指出现有的集群系统中Maui作业调度器提供的经典服务器分配算法是CPULoad,该算法选择服务器的依据是可用CPU计算能力,然而文献[23]指出服务器集群中存在“热点区域”,“热点区域”通常会加快硬件失效的速度,给数据中心带来额外开销,所以可以根据温度因素优化选择要唤醒的服务器,但是该文献只考虑了制冷设备对服务器运行的影响,没有考虑频繁的状态切换对服务器自身造成的不良结果。综上,基于预留机制的服务器状态管理策略存在一定的不足,从任务请求数阈值角度出发的DPS策略主要存在以下不足:
(1)静态设置的任务请求数阈值可能造成系统的抖动。如果排队的任务请求数在任务请求数阈值左右徘徊,可能造成SRM中的服务器频繁地在关闭和开启状态间切换,不仅不能达到节能的目的,还会造成系统性能的下降。
(2)当需要开启SRM中的服务器时,依据CPU计算能力选择服务器可能会导致SRM中的部分服务器经常被选择,使得部分服务器状态转换次数较大,导致能耗的上升;此外,温度的快速波动会对服务器的运行产生负面影响,导致服务器的性能变差,加快硬件失效的速度。
针对以上不足,本文改进了基于预留机制的服务器状态管理策略,提出一种基于动态阈值的服务器唤醒策略来优化管理云数据中心的服务器状态,其改进点在于:
(1)根据系统中的平均任务背叛数和能耗成本动态调整任务请求数阈值,使得云计算系统在性能和节能之间达到相对平衡;
(2)根据服务器冷点区域优先级和时间优先级选择唤醒服务器,使服务器关闭/休眠时间尽可能长,减少服务器状态转换次数,做到能耗的进一步优化以及保证数据中心服务器的稳定。
1 云计算系统排队调度模型
在云数据中心,任务请求随机到达系统,当任务到达时,如果系统内有空闲的服务器,则直接调度到相应的空闲服务器运行,否则该任务在全局任务队列中排队等待,系统根据当前排队的任务请求数是否超过任务请求数阈值决定是否唤醒额外的服务器;在排队过程中,任务等待服务器的响应具有一定的忍耐度,若等待时间过长,就会引起用户出现不耐烦情绪,从而离开队伍去别处另求服务,即发生“任务背叛”。云数据中心当前处于开启状态的服务器数量越少,发生任务背叛的强度越高。以上任务到达系统并接受服务的调度过程可以用具有不耐烦任务的排队系统来建模,图1是基于具有不耐烦任务的M/M/n排队系统调度框架。

图1 云计算系统中具有不耐烦任务的排队调度模型
图1中,任务以泊松流到达云计算系统,平均到达率为λ,任务控制器按照先来先服务的原则将任务队列中的任务调度到相应服务器节点,服务器节点接收并执行任务,平均服务率为μ。本模型假设任务到达过程相互独立,所有服务器的服务过程也相互独立。数据中心共提供N台同构的服务器,其中的n(0≤n≤N)台服务器构成SMM,剩下的N-n台服务器构成SRM。状态管理器根据全局任务队列Qglobal中的任务请求数与任务请求数阈值的关系对SRM中的服务器进行状态管理。Qglobal中的排队系统可定义为三元组(k,Φk,non),其中,k表示系统中当前排队的任务数;Φk表示系统中不耐烦任务离去的强度(发生任务背叛的强度),其值与系统中的排队长k有关(排队长为k时,发生任务背叛的强度为Φk),且Φk→∞(当k→∞);non为云计算系统处于开启状态的服务器数量。
全局任务队列中具有不耐烦顾客的M/M/n排队系统的状态流图如图2所示。
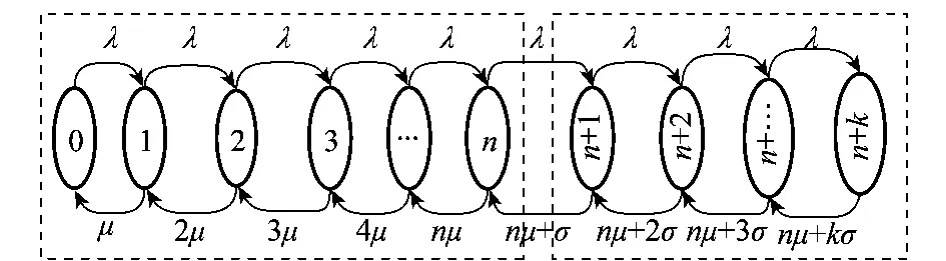
图2 具有不耐烦顾客的M/M/n排队系统的状态流图
图2中,0,1,…,n,n+1,…,n+k分别表示云计算系统处于各种不同的状态,其中0状态表示系统中没有任务执行,也没有任务排队,处于该状态的概率为p0;n+k(0≤n;0≤k)状态表示系统中有n个任务正在执行,有k个任务正在排队,处于该状态的概率为pn+k。
2 基于动态阈值的服务器唤醒策略
2.1 任务请求数阈值的动态调整
将服务器唤醒需要消耗电力,如果服务器唤醒后只是短暂的使用,那么这个唤醒能耗就无法带来收益,因此合理设置任务请求数阈值可以优化管理服务器的状态。较小的任务请求数阈值可以促使服务器快速启动以降低服务延迟,而较大的任务请求数阈值可以避免开启过多预留模块的服务器,有利于降低系统能耗。为了在性能和能耗之间取得较好的平衡,可以根据平均任务背叛数和能耗成本共同控制任务请求数阈值的变化。
2.1.1 平均任务背叛数的计算
系统当前的平均任务背叛数L是系统排队长为i(1≤i≤k)时发生任务背叛的强度以及系统排队长为i的概率乘积求和,则L为
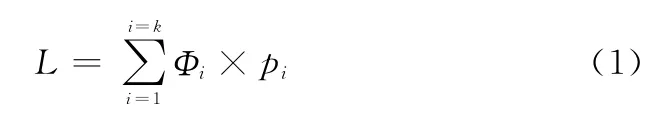
式中,pi为云计算系统中排队长为i(1≤i≤k)的概率;Φi为系统排队长为i时发生任务背叛的强度。
要计算出L,须求出在当前已经开启的服务器总数non下系统处于各个状态的概率,为简便表示,设Φi=δ×i(即任务背叛强度是排队长的正比例函数,δ为正比例系数),设,到达云计算系统的任务总数为K,初始时刻,系统开启的服务器数量为永久运行的服务器数量n,则根据图2,可以列出已经开启的服务器数量为n时系统平衡条件下的K氏方程。
当K≤non时:
对0状态有λp0=μp1,得

对n-1状态有λpn-1=nμpn,得
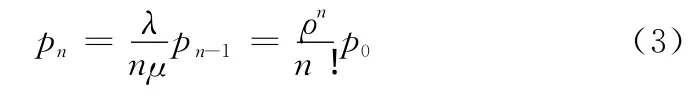
当K>non时:
对n状态有λpn=(nμ+δ)pn+1,得

一般地
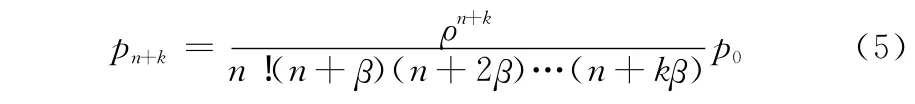
已知状态转移概率的正则性条件为

将式(2)~式(5)代入式(6),可以计算得到p0的值为

综上,系统当前的平均任务背叛数L的计算公式为
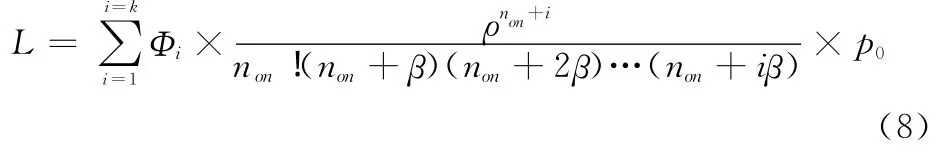
式中,系统当前排队的任务数k、开启的服务器数量non可以从系统当前运行情况获得;正比例系数δ、系统的任务平均到达率λ、系统的服务器平均服务率μ可以通过长期监测云计算系统的运行情况统计获得。
2.1.2 能耗成本的计算
云数据中心中,服务器处于不同状态下的功耗不同。设处于繁忙运行的服务器的功耗为Pbusy;处于空闲运行的服务器的功耗为Pidle;服务器从关闭/休眠状态转换为开启状态消耗的功耗为Poff->on,转换时间为tswitch;服务器从开启状态转换为关闭/休眠状态消耗的电量和转换时间很少,可以忽略不计。系统按预设的周期T计算能耗成本,设在周期T内,SRM中有x台服务器处于繁忙运行状态,有y台服务器处于空闲运行状态,则云计算系统在周期T内运行能耗Prun和转换能耗Pswitch分别为
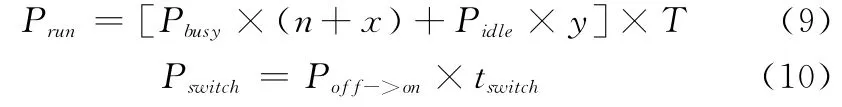
则在一个周期内总的能耗成本

2.1.3 任务请求数阈值的动态控制
若平均任务背叛数较多,说明任务请求队列过长,处于运行状态服务器数量较少,表明上次设置的阈值较大,因此可以将阈值调小;若能耗较大,说明开启的预留服务器较多,表明上次设置的阈值较小,因此可以将阈值调大。调整方法如下:

其中,阈值调整参数
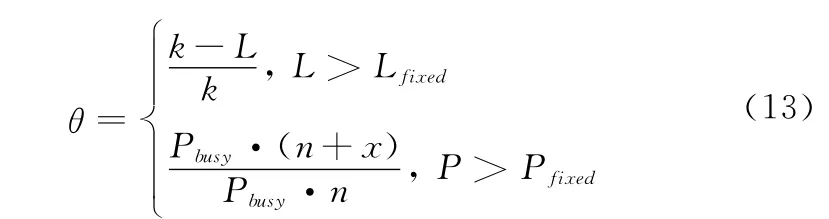
式中,α(t)为第t个周期的任务请求数阈值,t={1,2,3…};初始值α(1)在数值上设为云计算系统中的服务器的总数N;k为当前排队的任务数;L为当前的平均任务背叛数;Lfixed为任务背叛数阈值;Pbusy为单台服务器处于繁忙运行状态的功耗;Pfixed为能耗成本阈值;n为永久运行服务器的数量;x为SRM中当前处于繁忙运行状态的服务器数量;ROUND为取整函数。
2.2 服务器节点的选择唤醒
通常云数据中心采用中央空调,并且采用通风地砖实现云数据中心制冷[23],典型的数据中心机房制冷设备部署如图3所示,数据中心机房中共有I个通风口,由于各个通风口成行排列,可以将三维空间的距离问题转化为二维平面的距离问题(只考虑横向坐标和竖向坐标),并且距离服务器最近的通风口对服务器的温度影响最大(其余的通风口与服务器之间隔着一系列服务器机组,从而对服务器的温度影响可以忽略不计)。设第i(1≤i≤I)个通风口的坐标为(Xi,0),第j个服务器节点的坐标为(xj,zj)(1≤j≤N),服务器j到通风口i的距离记为disji,设dj表示第j个服务器的冷点区域优先级,服务器节点距离通风口距离越短,温度越低,服务器节点的冷点区域优先级越高;tj表示第j个服务器节点的时间优先级,服务器的频繁开关会影响服务器的性能,上一次关闭时刻距离当前时间越长,服务器节点的时间优先级越高。
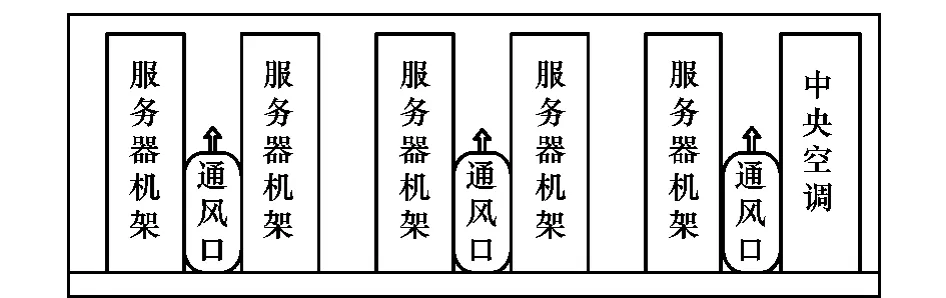
图3 数据中心机房制冷设备部署
2.2.1 冷点区域优先级
首先计算服务器j到最近一个通风口的距离disji,根据disji按照固定组距r划分d优先级,若disji∈[0,r),则为1级冷点区域,依此类推;dj的计算公式为

2.2.2 时间优先级
为系统SRM中的服务器设置计时器,初始时刻计时器的值为∞,当服务器开启后运行一段时间并再次关闭的时候,该服务器上计时器的值更新为0,并重新开始计时。计时器的值越大,该服务器的时间优先级越高。若服务器j上的计时器关闭,则Timerj=0,此时∞表示计时器的计时值;反之,若服务器j上的计时器开启,则Timerj=1,此时Timerj·t表示服务器j上计时器的计时值。tj的计算公式如下:

2.3 基于动态阈值的服务器唤醒算法
基于动态阈值的服务器唤醒(servers awakening based on dynamic threshold,SADT)算法过程为:
步骤1 初始化
包括全局任务队列初始化、任务请求数阈值初始化、确定冷点区域优先级。
步骤2 接收用户的任务请求
若SMM中有空闲服务器,则按照先来先服务原则将该任务调度到空闲服务器上,否则任务进入全局任务队列等待。
步骤3 按预设周期T动态调整任务请求数阈值
计算平均任务背叛数和能耗成本,根据计算结果与任务背叛数阈值和能耗成本阈值的关系调整任务请求数阈值。
步骤4 唤醒服务器
当排队的任务请求数超过任务请求数阈值时,首先根据服务器的冷点区域优先级选择冷点区域,再根据冷点区域上SRM服务器的时间优先级来确定最终选择的服务器。
SADT算法的伪代码描述如下:
输入:任务及其属性
输出:服务器选择唤醒方案


SADT算法从服务器的唤醒时机和唤醒对象两个角度改进了现有基于预留机制的DPS算法。在唤醒时机上,通过具有不耐烦顾客的排队论分析系统的平均任务背叛数和能耗成本来动态设置任务请求数阈值,解决了传统的静态阈值取值困难、依赖于主观经验、难以适应动态的云任务负载而出现系统抖动问题;在唤醒对象上,根据服务器的温度和运行时间选择需唤醒的服务器,解决了随机选择服务器唤醒的不确定性,避免了根据CPU计算能力选择服务器可能造成的部分服务器被频繁唤醒引起的性能下降和服务器失效。SADT算法的时间复杂度为O(KN),其中,K为到达云计算系统的任务总数,N为云数据中心的服务器总数,与传统的基于预留机制的DPS算法和never-off算法[17]的时间复杂度相同。
3 仿真及结果分析
3.1 实验环境和参数设置
在CloudSim-2.1.1环境下,设计了3组实验,对本文改进的动态阈值策略、选择唤醒策略和完整的基于动态阈值的服务器唤醒策略,分别从任务的平均响应时间和系统执行任务产生的总能耗两个方面进行仿真来评估算法的性能。实验建立了一个由100个服务器组成的数据中心,其中75个SMM服务器,25个等待启动的SRM服务器。首先生成一批独立的任务请求,使得任务的到达间隔时间服从参数为1/λ的负指数分布,该间隔时间可以通过负指数分布函数来生成。根据任务的到达时间间隔,计算得到每个任务到达系统的时刻,最终确定所有任务到达系统的时刻。系统按照先来先服务的原则调度任务,当任务到达系统时,若发现系统中有空闲运行服务器,则该任务调度到空闲运行服务器上执行,此时系统对该任务的响应时间为服务时间;若系统中没有空闲运行服务器,则该任务需要在全局任务队列中排队等候,在任务排队的过程中,根据平均任务背叛数和能耗成本调整任务请求数阈值,并根据当前排队的任务请求数与任务请求数的关系决定是否开启SRM中服务器,当系统中有空闲运行的服务器或已经额外开启SRM中的服务器时,继续调度全局任务队列中队首的任务,此时系统对该任务的响应时间为该任务的等待时间和服务时间之和,当所有任务全部执行完成时,模拟实验结束。实验的机器配置为:CPU Intel(R)Core(TM)2Duo T6500@2.10GHz;内存3GB;硬盘320GB;OS Windows 8 Enterprise Professional 32位。
实验中,为了保证仿真系统的运行存在平稳状态,设置0<λ/μ<1;服务器空闲运行功耗和服务器繁忙运行功耗的比值为0.7;实验环境涉及的相关参数以及取值如表1所示。

表1 实验参数设置
3.2 实验及其结果分析
由于本文提出的SADT算法的改进主要在于阈值的动态调整和服务器的选择唤醒,因此,先分别对两个改进点进行对比实验,再评估SADT算法的整体性能和能耗开销。
3.2.1 动态阈值策略的比较
首先,仿真比较了在随机选择服务器唤醒的情况下,本文提出的任务请求数阈值动态调整、never-off算法[17]和静态阈值算法[20]的任务平均响应时间和系统执行任务产生的总能耗。
平均响应时间为任务集上所有任务响应时间的平均值,反映了DPS策略的执行性能,平均响应时间越短,DPS策略的执行性能越高。实验比较了任务数在10~1 000个,每次递增变化时,3种算法的平均响应时间,实验结果如图4所示。
从图4可以看出,当任务数小于200时,3种算法的平均响应时间差别不大,这是由于任务数量较小时,云数据中心已经开启的服务器数量能够满足任务的需求。随着任务数的增加,never-off算法的平均响应时间最短,静态阈值算法的平均响应时间最长,本文算法的平均响应时间介于上述两者之间。这是由于在never-off算法中,云数据中心的服务器全部开启并提供服务,所有任务都可以尽快地分配到服务器;在静态阈值算法中,当开启的服务器增加到一定数量后就不再增加,因此当任务数继续增多时,部分任务排队等候,使平均响应时间增长,不能较好地满足云任务的响应时间需求;而在本文算法中,云数据中心的运行服务器数量能够根据任务背叛情况动态改变,能够较好地满足云任务的响应时间需求。
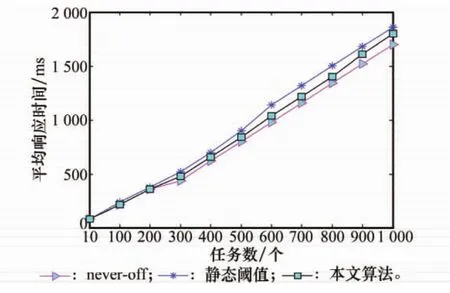
图4 不同阈值下的平均响应时间
系统总能耗为系统运行期间所有服务器产生的能耗总和,反映了DPS策略的节能效果。当任务数在10~1 000个,每次递增变化时,3种算法的系统总能耗如图5所示。
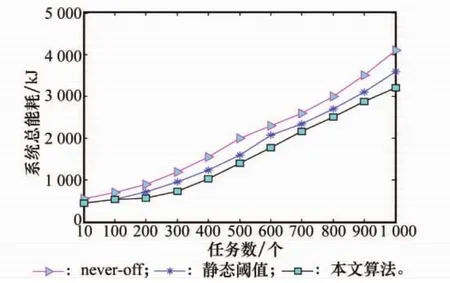
图5 不同阈值下的系统总能耗
从图5可以看出,never-off算法的能耗开销最大,本文算法的能耗开销最小,静态阈值算法的能耗开销介于上述两者之间。这是由于在never-off算法中,数据中心的服务器全部开启等待任务的到达,而服务器空闲运行时会产生大量空闲能耗,因此never-off的节能效果最差;在静态阈值算法中,只有当任务数超过任务请求数阈值时,部分服务器才开启并提供服务,避免了大量空闲能耗的产生,因此静态阈值算法相对never-off算法有一定的改进;然而静态设置的任务请求数阈值,可能造成服务器状态频繁切换从而导致能耗的上升,在本文算法中,可以根据系统运行情况动态调整任务请求数阈值,决策出相对较优的运行服务器数量,避免开启过多预留模块的服务器,有利于降低云数据中心空闲能耗。
通过对动态阈值策略的仿真比较可以看出,never-off算法能最好地保证系统性能,但是该策略所消耗的总能耗却也最大,不能够照顾云数据中心的利益;静态阈值算法虽然在一定程度上能够照顾到云数据中心的利益,达到较好的节能效果,但是任务数较多时,不能照顾到云用户的利益,使得系统执行任务的平均响应时间较长;而本文的动态阈值策略能够兼顾云用户和云数据中心的利益,相对较优。
3.2.2 选择唤醒策略的比较
本节评估了在静态设置的任务请求数阈值下,不同的唤醒服务器策略对系统性能的影响。从任务的平均响应时间和系统执行任务产生的总能耗比较了本文的服务器唤醒策略、CPUload唤醒算法[22]、温度感知唤醒算法[23]3种算法的执行效果。首先,比较了任务数在10~1 000个,每次递增变化时,3种算法的平均响应时间,仿真结果如图6所示。
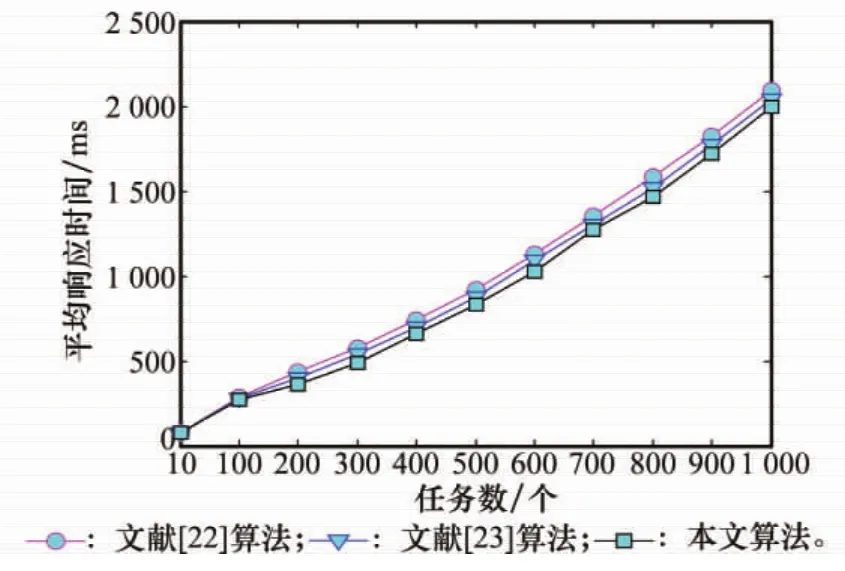
图6 不同唤醒策略下的平均响应时间
从图6可以看出,文献[22]算法的平均响应时间最长,本文算法的平均响应时间最短,文献[23]算法的平均响应时间介于上述两者之间。这是因为在文献[22]算法中,只根据CPU计算能力选择唤醒服务器,在文献[23]算法中,根据服务器和制冷设备的相对位置选择服务器唤醒,这样会导致部分服务器节点频繁在关闭态和开启态之间切换,加快服务器节点失效,从而需要开启额外的服务器,因此会延长服务器对任务的响应时间;而在本文算法中,同时根据冷点区域优先级和时间优先级优化选择服务器,这样就不会导致部分服务器温度的快速波动,从而减缓服务器的失效速度,不至于影响服务器对任务的响应时间。
本节评估了3种算法的系统总能耗,实验中,任务数在10~1 000个,每次递增变化时,3种算法的系统总能耗仿真结果如图7所示。
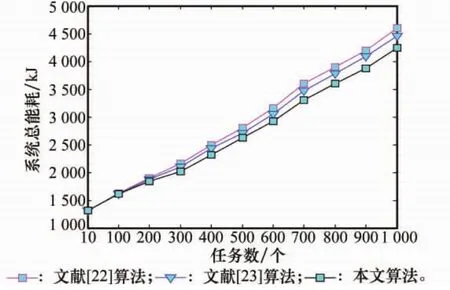
图7 不同唤醒策略下的系统总能耗
从图7可以看出,文献[22]算法的系统总能耗最高,本文算法的系统总能耗最低,文献[23]算法的系统总能耗介于上述两者之间,这是因为在文献[22]算法中,只根据CPU计算能力选择唤醒服务器;文献[23]算法中,根据服务器和制冷设备的相对位置选择唤醒服务器,相对文献[22]算法有一定的改进,然而该算法没有考虑频繁的状态切换对服务器自身造成的不良结果;而在本文算法中,能够优化选择已关闭时间长度较大的服务器进行唤醒,不至于导致SRM中的部分服务器频繁进行状态切换,从而减缓服务器失效的速度,不需要开启额外的服务器,因此产生的转换能耗较低,相应产生的系统总能耗就低。
通过对选择唤醒策略的仿真比较可以看出,本文算法的平均响应时间小,产生的系统总能耗低。因此,本文的选择唤醒策略相对较优。
3.2.3 SADT算法的性能分析
最后,完整地将本文提出的SADT算法与无阈值的服务器唤醒算法[17]、基于静态阈值的服务器唤醒算法[20]进行比较。同样仿真了当任务数在10~1 000个,每次递增变化时,3种算法的任务平均响应时间和系统总能耗,实验结果分别如图8、图9所示。
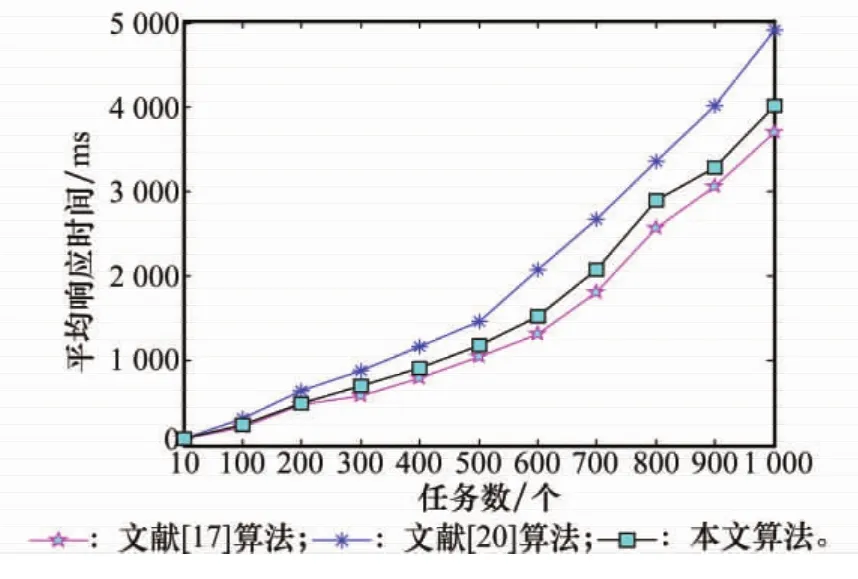
图8 完整算法的平均响应时间
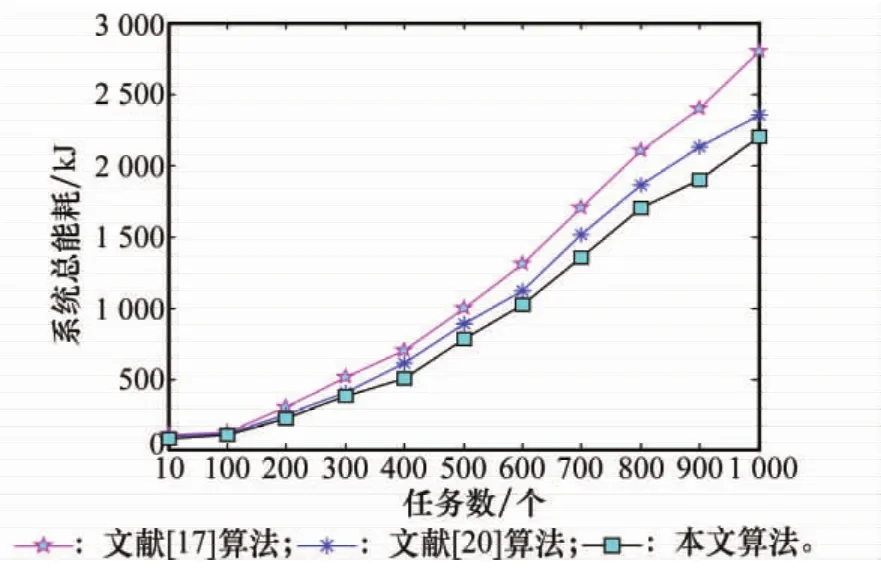
图9 完整算法的系统总能耗
从图8可以看出,文献[17]算法的平均响应时间最短,文献[20]算法的平均响应时间最长,而本文算法的平均响应时间介于上述两者之间,这是因为本文算法能够根据任务阻塞率动态调整任务请求数阈值,从而动态控制数据中心的活跃服务器数量,不会造成云数据中心开启的服务器数量过少,可以很好地适应云用户的要求。
从图9可以看出,文献[17]算法的系统总能耗最高,文献[20]算法的系统总能耗次之,本文算法的系统总能耗最低,这是因为本文算法能够根据能耗成本动态调整任务请求数阈值,从而动态控制数据中心的活跃服务器数量,不会造成云数据中心开启的服务器数量过多,因此降低了云数据中心的整体能耗。
综上,本文提出的SADT算法能够兼顾到云用户和云数据中心的利益,既保证了系统对任务的平均响应时间又降低了云计算系统的能耗开销。
4 结束语
云数据中心需要消耗大量电力来维持其正常工作,向云用户提供服务,基于预留机制的服务器状态管理策略可以确保服务器给用户提供较高性能的服务并且减少服务器的电力消耗。本文在基于预留机制的服务器状态管理策略的基础上,提出了一种基于动态阈值的服务器唤醒策略。该策略综合考虑用户端的任务背叛情况和服务端的能耗成本情况,动态调整任务请求数阈值,并根据服务器的冷点区域优先级和时间优先级来控制唤醒服务器的选择,从而做到性能的保证和能耗的进一步优化。
到达云计算系统的任务分为实时任务和非实时任务,实时任务对任务的截止期有一定要求,本文主要面向非实时任务,下一步将重点考虑用户对任务截止期的要求,面向硬实时任务和软实时任务,结合动态开启/关闭技术、动态电压和频率调整技术,进一步对云计算系统的能耗进行优化管理。
[1]Beloglazov A.Energy-efficient management of virtual machines in data centers for cloud computing[D].Melbourne:The University of Melbourne,2013.
[2]Gu L J,Zhou F Q,Meng H.The research of power consumption and energy efficiency in our datacenter[J].The Energy of China,2010,32(11):42-45.(谷立静,周伏秋,孟辉.我国数据中心能耗及能效水平研究[J].中国能源,2010,32(11):42-45.)
[3]Tan Y M,Zeng G S,Wang W.Policy of energy optimal management for cloud computing platform with stochastic tasks[J].Journal of Software,2012,23(2):266-278.(谭一鸣,曾国荪,王伟.随机任务在云计算平台中能耗的优化管理方法[J].软件学报,2012,23(2):266-278.)
[4]Song J,Li T T,Zhu Z L,et al.Benchmarking and analyzing the energy consumption of cloud data management system[J].Chinese Journal of Computers,2013,36(7):1485-1499.(宋杰,李甜甜,朱志良,等.云数据管理系统能耗基准测试与分析[J].计算机学报,2013,36(7):1485-1499.)
[5]Kumar J A,Vasudevan S.Verifying dynamic power management schemes using statistical model checking[C]∥Proc.of the 17th Asia and South Pacific Design Automation Conference,2012:579-584.
[6]Jeyarani R,Nagaveni N,Vasanth-Ram R.Design and implementation of adaptive power-aware virtual machine provisioner(APA-VMP)using swarm intelligence[J].Future Generation Computer Systems,2012,28(5):811-821.
[7]Khan U A,Rinner B.Online learning of timeout policies for dynamic power management[D].Klagenfurt:Alpen-Adria University Klagenfurt,2013.
[8]Jiang Q,Xi H S,Yin B Q.Adaptive optimisation of timeout policy for dynamic power management based on semi-Markov control processes[J].IET Control Theory &Applications,2010,4(10):1945-1958.
[9]Cao Z,You Z.The influencing factor of threshold selection in dynamic threshold of timeout policies[J].Journal of Harbin Institute of Technology,2013,45(6):119-123.(曹哲,尤政.超时策略动态阈值的阈值选择影响因素[J].哈尔滨工业大学学报,2013,45(6):119-123.)
[10]Gupta M,Shum L V,Bodanese E,et al.Design and evaluation of an adaptive sampling strategy for a wireless air pollution sensor network[C]∥Proc.of the 36th Conference on Local Computer Networks,2011:1003-1010.
[11]Long S,Zhao Y,Chen W.A three-phase energy-saving strategy for cloud storage systems[J].Journal of Systems and Software,2014,87(1):38-47.
[12]Triki M,Ammari A C,Wang Y,et al.Reinforcement learning-based dynamic power management of a battery-powered system supplying multiple active modes[C]∥Proc.of the European Modelling Symposium,2013:437-442.
[13]Shih H C,Wang K.An adaptive hybrid dynamic power management algorithm for mobile devices[J].Computer Networks,2012,56(2):548-565.
[14]Choi G B,Lee S G,Lee J M.Modeling and stochastic dynamic optimization for optimal energy resource allocation[J].Computer-Aided Chemical Engineering,2012,31(5):765-769.
[15]Yue S,Zhu D,Wang Y,et al.Reinforcement learning based dynamic power management with a hybrid power supply[C]∥Proc.of the 30th International Conference on Computer Design,2012:81-86.
[16]Terzopoulos G,Karatza H.Performance evaluation and energy consumption of a real-time heterogeneous grid system using DVS and DPM[J].Simulation Modelling Practice and Theory,2013,36(2):33-43.
[17]HyytiäE,Righter R,Aalto S.Task assignment in a heterogeneous server farm with switching delays and general energyaware cost structure[J].Performance Evaluation,2014,75(5):17-35.
[18]Mazzucco M,Dyachuk D.Optimizing cloud providers revenues via energy efficient server allocation[J].Sustainable Computing:Informatics and Systems,2012,2(1):1-12.
[19]Maheshwari N,Nanduri R,Varma V.Dynamic energy efficient data placement and cluster reconfiguration algorithm for MapReduce framework[J].Future Generation Computer Systems,2012,28(1):119-127.
[20]Wang W,Luo J Z,Song A B.Dynamic pricing based energycost optimization in data center environments[J].Chinese Journal of Computers,2013,36(3):599-612.(王巍,罗军舟,宋爱波.基于动态定价策略的数据中心能耗成本优化[J].计算机学报,2013,36(3):599-612.)
[21]Kim W,Mvulla J.Reducing resource over-provisioning using workload shaping for energy efficient cloud computing[J].Applied Mathematics &Information Sciences,2013,7(5):2097-2104.
[22]Li Y.Research and implementation of cluster job management middleware[D].Beijing:Capital Normal University,2009.(李媛.集群作业管理中间件的研究与实现[D].北京:首都师范大学,2009.)
[23]Liang A,Xiao L,Pang Y,et al.Thermal-aware workload distribu-tion for clusters[J].Procedia Engineering,2011,15:3308-3312.
E-mail:chengcl@njupt.edu.cn
王 颖(1989-),女,硕士研究生,主要研究方向为资源管理、云计算。E-mail:15050523137@163.com
张登银(1965-),男,研究员,博士研究生导师,博士,主要研究方向为信号与信息处理、信息网络。
E-mail:zhangdy@njupt.edu.cn
Strategy of servers awakening based on dynamic threshold in cloud computing
CHENG Chun-ling1,WANG Ying1,ZHANG Deng-yin2
(1.College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.Internet of Things Technology Park,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
The dynamic powering on/off servers(DPS)strategy based on reservation sets the static threshold of the task request number beforehand,which may cause frequent switching of the server status.To solve this problem,a strategy of servers awakening based on the dynamic threshold in cloud computing is proposed.Firstly,the queuing model with impatient tasks is introduced to model the task scheduling in the cloud computing system,and analyze the average number of task betrayal and the cost of power consumption,thereby the strategy of dynamicly adjusting the threshold of the task request number is presented.After that,a server is chosen to be awakened according to the cold area where the server located and the length of its shutdown time.The simulation results show that the proposed strategy can ensure the average response time for tasks and reduce the energy cost in cloud computing system efficiently.
cloud computing;dynamic powering on/off servers(DPS);dynamic threshold;queuing theory;impatient tasks
TP 393
A
10.3969/j.issn.1001-506X.2015.06.32
程春玲(1972-),女,教授,博士研究生,主要研究方向为云计算、资源管理及性能优化。
1001-506X(2015)06-1437-09
2014-05-19;
2014-08-23;网络优先出版日期:2014-10-22。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20141022.1305.001.html
江苏省科技支撑项目(BE2012849);江苏省研究生科研创新计划(CXZZ12_0483)资助课题
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年7期)2021-07-16
建材发展导向(2021年23期)2021-03-08
制造技术与机床(2019年9期)2019-09-10
西藏艺术研究(2019年1期)2019-09-04
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
华人时刊(2018年15期)2018-11-10
