
图书馆利用大数据对策浅议
2015-08-11 06:23:06徐军玲
图书馆研究 2015年4期
徐军玲
(上海电机学院图书馆,上海 200240)
1 引言
随着网络技术、信息技术的发展,人们从来没有像现在这样对新设备、新技术、新理念应接不暇。在数字图书馆、移动图书馆、云图书馆、智慧图书馆之后,大数据来了。所谓大数据,并不是指那些单纯的体量巨大的数据,而是指那些无法在人们容忍的时间内用常规软件工具对其内容进行整合、存储、分析和应用的数据集合,具有体量巨大化(volume),结构多样化(variety),输入处理速度快(velocity)和价值密度低(value)的特点。图书馆面对大数据来袭,应该具备什么条件、采取什么样的措施,才能利用大数据做好知识服务,为国家科技进步、经济发展、社会稳定做出应有的贡献,是每一个图书馆不可回避的问题。
2 泛馆藏观是图书馆利用的大数据的最佳战略选择
尽管近年来图书馆界表现出了对大数据极度的关注并投入极大的热情,但是严格按大数据的特征来判断,除少数国家级、省市级图书馆外,大部分中、小型图书馆可利用的数据资源中称得上大数据的资源很少。其主要原因之一是多数图书馆对大数据还没有一个完整清晰的认识,没有建立自己的基于云计算的管理服务平台,当然也谈不上对大数据的抓取、借用;原因之二是多数图书馆缺乏大数据管理和应用的人才,要对大数据进行整理、分析、利用并产生社会价值还有很多工作要做。但无论如何,大数据是当前社会中的客观存在,大数据已经来到了图书馆人面前。
2.1 大数据资源的空间分布
以前,人们大都认为政府和信息机构(图书馆与有关信息机构)是大部分信息资源的拥有者。随着互联网和信息产业的发展,目前政府和信息机构拥有的信息数量远远少于信息运营商。美国麦肯锡公司2011年的调查结果显示,政府约拥有848PB(1PB=1 024TB)数据,约占数字信息资源总量的12%左右,信息机构的数字信息资源总量更是远远低于信息服务商的数据总量[1]。在国外,Facebook、Amazon、Yahoo、Twitter和Hulu等互联网企业每日每时都在孕育着大数据,在我国也是如此,百度每天要处理的任务总量超过120 000个,处理的数据总量超过20PB[2];2011年淘宝就有4亿条产品讯息和2亿多名注册用户在上面活动,每天超过4 000万人次访问,淘宝数据仓库每天大约要处理几亿次的用户行为,由此产生的每天的活跃数据总量超过50TB[3]。因此,图书馆要利用大数据向读者提供服务,不是利用现有的馆藏而是通过某种方式(如云计算服务平台)利用社会上的大数据资源。
2.2 大数据资源的存在形式
大数据的结构多样化是其重要特征之一。根据数据的生成方式和结构特点不同,它们存在的形式也各不相同,有时还会有交叉。大数据资源从存在形式上分,有结构化数据、半结构化数据和非结构化数据。结构化数据是指那些可以用二维表(字段和记录)结构来逻辑表达的数据,它的特点是任何一列的数据不可再细分,并具有唯一的类型,是数据管理最古老的一种数据形式。常见的管理软件有Excel、SQL等。半结构化数据是指那些字段可根据需要扩充的结构化数据,如以Exchange软件形式存储的数据。除结构化数据之外的数据统称为非结构化数据,也就是无法用统一的逻辑形式表达的数据,如文本数据、Web数据、图片、音频、视频数据等。
数据流是近年来颇受关注的一种新的数据形式,它既有结构化数据形式,也有非结构化数据形式。一般业界比较认同的定义是只能被读取一次或少数几次的有序数据序列,它具有数据到达的快速性、数据范围的广泛性和到达时间的持续性三个特点。它与传统的关系型数据的区别是联机即到、数据到达的先后顺序无法控制、数据量有可能是无限多、一般只能存储一个时间段的数据。
数据形式的不同导致对这些数据的抓取、整理、分析的方法不同和选用的软件工具的不同,虽然其中的一些数据可能会利用类似的底层技术,甚至会存在一定交叉,但由于很多大数据难以全部存储和重复读取,也给分析、利用这些数据带来了困难。图书馆要利用这些来自不同地域、形式各不相同的大数据为读者提供服务,就必须统筹考虑,引进专门人才和设备,抓住大数据的关键特征采用不同的工具和技术才能奏效。
2.3 泛馆藏观是大数据时代图书馆人应该建立的新观念
随着网络技术的发展,图书馆的馆藏已经突破了原有的馆藏概念,现在图书馆的馆藏不仅包括传统的馆藏内容,也包括了一定的虚拟馆藏,如各类信息产业的数据镜像。面对大数据和云计算,图书馆不可能也没有必要对大数据进行实际馆藏。首先,大数据馆藏投资巨大,不是一般图书馆所能承受的。其次,大数据本身具有体量巨大,数据类型复杂,价值密度低的特点,甚至有些大数据在经过一定的时间后就失去了保存的价值,花费大量的投资储藏所有的大数据,既不经济也没有必要。图书馆要使用的大数据可以通过云平台以即服务的方式向一些信息产业购买使用权。所谓泛馆藏,就是不仅包含图书馆的现有传统馆藏,也包括通过各种方式在本图书馆可以利用的网络产业信息资源和云信息资源。简单地说,图书馆的泛馆藏就是图书馆能够利用的所有的信息资源。
3 充分利用现有大数据处理技术是图书馆利用大数据的有效方法
3.1 大数据处理技术概述
大数据处理技术,从处理对象来划分主要有批量数据处理技术,数据流处理技术,交互式处理技术,图形数据处理技术等。
批量数据处理技术应用的主要对象有搜索引擎、电子商务、社交网络及社会上(如医疗保健、能源消费等)产生的大数据。批量数据处理的典型架构是Hadoop,它包含负责数据存储的分布式文件系统HDFS和负责数据计算和价值发现的分布式编程模式MapReduce两个开源软件。此外,还有Google开发的批量数据存储系统HFS和MapReduce等。
数据流处理技术应用于需要数据采集分析或需要实时分析的场合,如互联网日志、Web数据、金融银行业等产生的数据流。数据流处理技术的典型工具有Twitter的Storm系统、Facebook的Scribe系统、Linkedin的Samza系统等。Storm系统具有分布式、可靠性好、高容错率的特点,该软件把数据流分发给下属组件,由下属组件对数据进行单一的特定的处理任务。Scribe系统是一个开源的日志收集系统,它从网站日志源上收集日志,保存到一个分布式文件系统上,为统一处理和分析这些数据提供基础。这些系统大都各自具有分布式、可扩展、高容错的特点,从而被业界所推崇。
交互式处理技术是一种采用人—机对话模式处理大数据的技术,应用于互联网各种交互式平台产生的大数据的分析,使用NoSQL类型的数据库处理交互式数据。典型的交互式数据处理系统有Google的Dremel系统、Berkeley的Spark系统等。Google的Dremel是一种交互式数据分析系统,用于分析处理只读嵌套式数据。它可以组成上千规模的服务器集群,处理PB数量级的数据,相比于MapReduce具有列式存储、查询方便、分析速度快等特点。
图形数据处理技术用于需要处理分析图形数据的所有领域,应用范围极其广泛。典型的处理系统有Google的Pregel系统、Neo4j系统、微软的Trinity系统等。Pregel是一种分布式图形数据计算系统,主要用于图遍历(BFS)、最短路径(SSSP)以及Pagerank计算等场合,具有兼容性强、容错率高等特点。微软的Trinity是建立在分布式云存储上的图形分析系统,使用超图数据模型,兼容大部分数据库特点,具有查询速度快、支持批处理等特点。
3.2 立足于现有技术,开发大数据资源
正在使用和开发的大数据处理技术远不止以上介绍的这些,随着大数据时代的到来和深入,相信会有更多更有效的大数据处理技术和软件诞生。图书馆是利用知识信息资源进行对外服务的机构,不是大数据处理技术的研发机构。图书馆只要建立一个基于云计算的管理服务平台,运用云计算的即服务方式,得到大数据以及大数据处理架构的使用权,从而利用这些技术进行信息服务。因此,图书馆大数据处理技术只能采取“拿来主义”,引进或培养处理大数据的专门人才,利用目前市场上已有的处理技术,建立自己的云计算管理服务平台,才能够利用大数据资源对用户提供服务。
4 构建云管理服务平台是图书馆利用大数据的关键
4.1 图书馆通过云计算平台开展大数据服务
云计算与大数据是传统互联网、移动互联网、物联网发展到一定阶段催生的一对“孪生兄弟”。中科院物联网研究发展中心陈曙东研究员在“亚信大数据开放日”上提出:没有大数据的信息积淀,云计算的计算能力再强大,也难以找到用武之地;没有云计算的处理能力,数据信息的沉淀再丰富,也无法处理。大数据必须要依赖于云计算,才能进行实际的应用。云计算的虚拟化技术、分布式处理技术、海量数据的存储和管理技术、实时流数据处理、智能分析技术等,为大数据的应用提供了技术平台[4]。体量巨大的大数据只有在云端才能找到存储之所;结构复杂多样的大数据只有通过云计算相关技术才能整合、分析;低价值密度的大数据只有通过云计算的分析才能发现其应用价值。因此,图书馆开展大数据服务构建云管理服务平台是关键的一步。
目前图书馆利用大数据进行对外服务的条件还很不成熟。首先大部分图书馆没有自己的云管理服务平台,由大数据与云计算的关系可知,没有云计算,利用大数据几乎是一句空话。其次,当前大部分信息数据资源集中在各个信息产业机构和政府机构手中,且没有有效的法律条文支撑的资源共享,这样图书馆利用大数据就变成“无米之炊”。第三,大部分图书馆云计算、大数据方面专业人才匮乏,难以形成一支利用大数据的服务团队。面对大数据时代的来临,图书馆要在大数据面前有所作为,就必须解决无云计算平台、无大数据资源、无相关人才的“三无”现象。
4.2 图书馆面对大数据的云管理服务平台的架构设计
如图1所示,图书馆面对大数据的云管理服务平台可分为三层:资源层、云平台管理层和服务层。资源层分为硬件资源和软件资源两大部分,硬件资源主要包括图书馆各类实体馆藏、电子馆藏及承载这些馆藏的建筑、机械设备、电子设备及网络设备等资源;软件资源主要包括图书馆各类数字资源、虚拟馆藏(订购或通过其他方式拥有使用权的远程数字资源或数据库等)以及各类管理软件。云平台管理层由图书馆为云平台专用的虚拟设备、用于云服务的各类软件资源、用于云平台管理的软件(如云计算访问接口)及用于云安全保障的软件资源等组成,主要作用是对云计算服务层的可用性、可靠性和安全性提供保障并保证服务质量和运行安全。服务层主要包括云计算的IaaS、PaaS、SaaS三种云计算服务,IaaS提供馆内外硬件基础设施部署服务,为根据读者需要提供、配置实体或虚拟的计算、存储及相关网络资源;PaaS是云计算服务提供商提供的应用程序运行环境,用于提供应用程序的部署与管理服务,以访问、认证、管理、计费的一体化形式为广大用户提供高效的个性化服务;SaaS是基于云计算基础平台所开发的应用程序,其中既包括云计算服务提供商提供的各类应用程序也包括图书馆自己开发的应用程度。
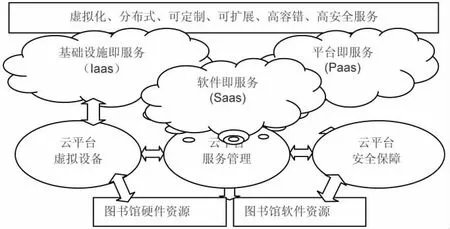
图1 图书馆云管理服务平台架构示意图
图书馆面对大数据的云管理服务平台的构建应该立足现有条件、现有技术,根据实际需求构建自己的应用服务系统,按实际需要集成外部第三方之间的运算、分析系统,充分发挥云计算即时服务、按需付费的特点打造适合本图书馆的云服务平台。当前国内外有不少的云服务提供商可供选择,国内的图书馆界CALIS数字图书馆的云服务平台已经初步建成[5],IT企业界阿里巴巴、华为、腾讯等众多著名公司都建立了云服务平台,不仅提供云平台建设方案,也提供数据使用。
5 结束语
大数据的利用是图书馆的一个重要发展契机,如何构建图书馆自己的云服务平台为社会服务,是当前图书馆面临的一个重要课题。各图书馆条件不同,基础各异,服务对象也不尽相同,利用大数据为自己的服务对象提供服务还有很长的路要走。尽管图书馆内部人才的缺乏、经费的短缺,外部环境中国家有关云计算、大数据方面法律建设、大数据共享等还不尽如人意,但笔者相信大数据的利用一定会成为图书馆一项崭新的业务。
[1]张斌,马费成.大数据环境下数字信息资源服务创新[J].情报理论与实践,2014(6):28-33.
[2]郭敏杰.大数据和云计算平台应用研究[J].现代电信科技,2014(8):7-11.
[3]每天50TB淘宝数据库海量数据轻松“漫游”记[EB/OL].[2011-01-12].http://soft.chinabyte.com/171/11775671.shtml.
[4]陈曙东.大数据的哲学思考[EB/OL].[2015-03-23].http://mt.sohu.com/20150323/n410190740.shtml.
[5]王文清,陈凌.CALIS数字图书馆云服务平台模型[J].大学图书馆学报,2009(4):13-18.
猜你喜欢
信息安全与通信保密(2023年8期)2023-10-12 11:19:30
现代装饰(2022年6期)2022-12-17 01:07:32
加油站服务指南(2022年6期)2022-07-28 06:07:08
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
湖北农机化(2020年4期)2020-07-24 09:07:38
艺术品鉴(2019年11期)2019-12-27 09:06:18
大观(书画家)(2018年6期)2018-07-08 00:43:26
通信电源技术(2018年3期)2018-06-26 06:33:54
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
