
汽轮机热耗率多模型建模方法研究
2015-08-10 10:10:19牛培峰李国强马云飞陈贵林张先臣
计量学报 2015年3期
牛培峰, 刘 超, 李国强, 马云飞, 陈贵林, 张先臣
(1.燕山大学工业计算机控制工程河北省重点实验室,河北秦皇岛066004;2.国家冷轧板带装备及工艺工程技术研究中心,河北秦皇岛066004)
汽轮机热耗率多模型建模方法研究
牛培峰1,2, 刘 超1, 李国强1, 马云飞1, 陈贵林1,2, 张先臣1,2
(1.燕山大学工业计算机控制工程河北省重点实验室,河北秦皇岛066004;2.国家冷轧板带装备及工艺工程技术研究中心,河北秦皇岛066004)
针对汽轮机热耗率难以准确计算的问题,提出了核模糊c均值与混合蛙跳算法优化最小二乘支持向量机(LS-SVM)的汽轮机热耗率多模型建模方法,用来计算不同工况下的热耗率。该方法利用核模糊c均值算法对热耗率数据聚类,采用5折交叉验证平均误差作为LS-SVM参数选择的适应度值,利用混合蛙跳算法优化参数并建立局部模型,采用开关切换得到模型输出,以此实现热耗率的多模型建模。与单一的LS-SVM模型和BP网络热耗率预测模型比较,结果表明该多模型方法有更高的预测精确和更好的泛化能力,能更准确地计算汽轮机热耗率。
计量学;汽轮机热耗率;混合蛙跳算法;多模型建模;最小二乘支持向量机;核模糊c均值
1 引 言
汽轮机组的热耗率是衡量火电机组运行经济性的重要技术指标,降低机组的热耗率在建立发电厂安全、经济、可靠运行系统以及在电力市场化,竞价上网的成本核算体系中有重要的指导作用。核心问题便是如何精确地计算机组热耗率。一种可行办法是利用回归方法得到各个运行工况下热耗率与有关热力参数之间的关系模型,在运行中将某工况的有关参数代入已建立好的模型中,即可得到汽轮机热耗率的实时计算值[1]。
回归建模方法主要有神经网络、支持向量机等。人工神经网络[2,3]由于是基于经验风险最小化,存在着难以克服的缺点,在缺少样本的情况下,训练的模型泛化能力不强。而支持向量机(SVM)是建立在结构风险最小理论基础上的学习机[4~6],相对神经网络,SVM具有严格的理论和数学基础,能较好地解决小样本等实际问题。最小二乘支持向量机(Least square support vector machine,LS-SVM)是标准SVM的一种变体[7],它将求解二次规划问题转化为求解线性方程以提高运算速度。采用混合蛙跳算法[8]调整LS-SVM的正规化参数和核参数,可以提高模型预测精度。由于机组的负荷率有较大的动态变化范围,采用单一LS-SVM模型难以精确描述热耗率特性;而多模型建模时,各个子模型是相对独立的,无论在模型精度还是预测精度均要优于单模型[9]。
根据上述分析,本文提出汽轮机热耗率多模型建模方法。首先采用核模糊c均值对热耗率样本进行聚类划分;然后,用蛙跳算法优化的LS-SVM对各子类分别建立局部模型;最后,采用开关切换得到模型输出。仿真实验表明,该方法能有效预测汽轮机热耗率。
2 核模糊c均值
模糊c均值是一种广泛应用的聚类算法,由于其对边缘点和对非线性问题处理不是很理想,计算过程易陷入局部最优,本文采用核模糊c均值对热耗率数据在高维空间进行聚类划分。
假设数据样本{(x1,y1),…,(xn,yn)}⊂Rm× R,n为样本数量。数据样本通过一个非线性映射φ:x→F,将输入空间Rm映射为高维特征空间F:(x∈Rm→φ(x)∈Rq,q>m),并在特征空间F内进行模糊c均值聚类,把热耗率数据聚类划分成c类。
在特征空间F中定义核函数K(x,y),文中核函数选用高斯核函数。则F空间中点积就用输入空间的核K(x,y)函数来表示

其K(x,x)=1,F空间的欧式距离为

在F空间的聚类价值函数可以表示为
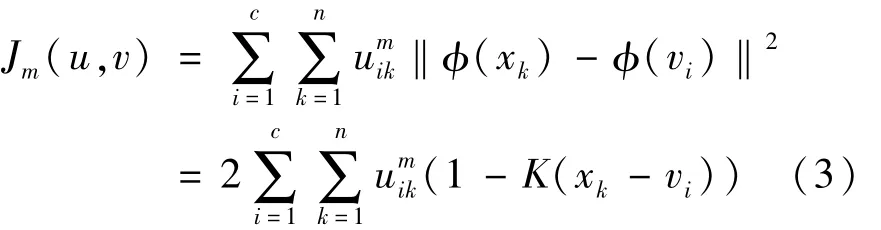
式中,m∈[1,∞)为一个加权指数;φ(xk)和φ(vi)为映射到高维空间的数据样本和聚类中心;uik为第k个样本属于第i类的隶属度,uik必须满足

在式(5)的约束下,令∂Jm/∂vi=0和∂Jm/∂ui(xk)=0,可得u、v的更新式

3 最小二乘支持向量机
支持向量机是建立在VC维理论和结构风险最小原理上的学习机,它能够有效地抑制模型建立过程中欠学习和过学习现象。LS-SVM是标准SVM的一种变体,LS-SVM以等式约束代替传统支持向量机的不等式约束,将求解二次规划问题转化为求解线性方程组。LS-SVM优化目标可表示为

式中,w为权向量;b为偏置;φ(x)为将输入空间映射到高维特征空间的非线性映射。
定义拉格朗日函数为
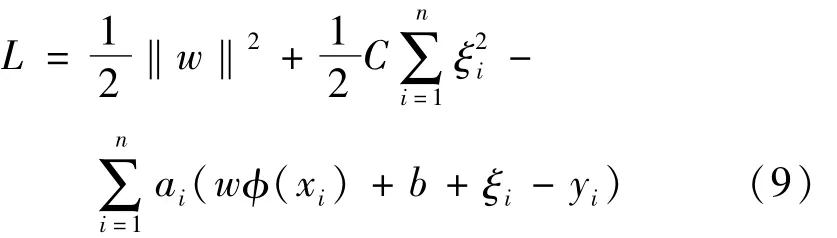
式中,ai为Lagrange乘子。
分别求L(w,b,a,ξ)对w,b,a,ξ的偏微分,可以得到式(10)的最优条件

优化问题最终转化为求解方程组

式中,y=[y1,…,yn]T,I=[1,…,1]T,a=[a1,…,an]T,Z=[φ(x1),…,φ(xn)]T。
解方程(11)可以得到最小二乘支持向量机系数w和b,进而得到LS-SVM回归函数

核函数的引入,巧妙地消除了高维空间直接求内积的“维数灾难”的问题。本文选用RBF核函数

由上可见,模型的精度和预测能力主要由参数C和核参数δ2决定。其中,C在于调节置信范围和经验风险的比例,核参数δ2主要影响样本数据在高维特征空间中的分布复杂程度。
4 混合蛙跳算法优化LS-SVM
LS-SVM参数选择过程本质上是一个优化搜索过程,搜索空间的每个点均为最佳参数的一个潜在解。本文利用混合蛙跳算法强劲的全局搜索能力实现模型参数的优化。
4.1 蛙跳算法
蛙跳算法(SFLA)是Eusuff和Lansey提出的一种全新的后启发优化算法[8]。局部搜索和全局信息交换使该算法具有高效的计算性能和优良的全局搜索能力。假设由N个青蛙构成的种群{Xi|Xi=(xi1,…,xis)},其中s为解空间的维数。根据式(14)计算适应度f(xi)

将个体按适应度降序排序,然后将整个种群按式(15)划分为m个子群,每个子群包含n=N/m只青蛙。

然后,在每个子群中分别执行局部搜索策略,按照式(16)和(17)更新子群中适应度最差的个体。

式中,Xb和Xw为适应度最好和最差的个体;di为个体的调整矢量;dmax为允许青蛙个体最大步长。在迭代中,如果更改后的new Xw的适应度比old Xw好,则其取代最差的个体;否则,用全局适应度最好的个体Xg替换式(16)中的Xb,重新执行式(16)、(17)。如果适应度还未提高,则随机产生一个个体。
执行完局部搜索后,将各子群个体混合在一起,更新全局最优个体,并按照式(15)重新划分,重复上述的局部进化搜索,直到终止条件满足为止。
4.2 SFLA优化LS-SVM的参数
SFLA算法采用实值编码,本文选用5折交叉验证平均误差作为LS-SVM参数选择的适应度值。图1为用混合蛙跳算法优化LS-SVM参数的示意图。
(1)设置初始值:种群规模、迭代次数、终止条件、(C,δ2)取值范围分别设为[0.1,1000]和[0.1,1000]。
(2)将具有n个热耗率训练样本(xi,i=1,2,…,n),随机分成5个数据集合S1,…,S5。
(3)计算5折交叉验证误差:初始化i=1,取第i个集合Si作校验集合,其余合并作训练集合,根据当前的(C,δ2)训练LS-SVM,按式(18)计算泛化误差

图1 混合蛙跳算法优化LS-SVM的参数

式中,yj和fj分别为真实值和预测值;m为校验集中数据样本的个数。令i=i+1,重复直至i=5。
(4)5次泛化误差的平均值作为混合蛙跳算法的适应度值J(xi),然后利用SFLA搜索更好的(C,δ2)。
5 汽轮机热耗率多模型建模
5.1 热耗率多模型思路
热耗率多模型建模总体结构见图2。算法分为3层:第1层把采集到的汽轮机热耗率数据用核模糊c均值算法聚类,得到聚类中心v和隶属度U,然后再按照各个样本的隶属度大小将数据划分成c个子类样本;第2层用混合蛙跳算法优化的LS-SVM对各个子类建立局部模型;第3层根据开关切换准则得到最终模型的输出。在对测试集预测时,首先在n维空间中定义测试样本点与聚类中心v的欧式距离
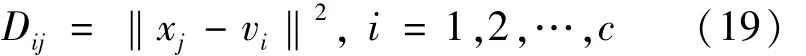
式中,Dij为测试样本xj与聚类中心vi的欧式距离。
按式(19)计算测试样本与聚类中心的欧式距离,根据最小欧式距离判别各个测试样本所属类。最后将测试样本点送到所属类对应的局部模型预测输出。

图2 开关切换方式的热耗率多模型结构
5.2 热耗率多模型预测实例及精度验证
5.2.1 多模型的输入与输出
汽轮机热耗率及影响热耗率的参数之间存在着强非线性关系。文献[10]指出了超临界凝汽式汽轮机组热耗率计算公式,式中焓值可以通过介质的压力和温度求解,故根据该公式确定热力参数。根据这个原则选择:Pe(发电机输出功率,MW)和P0,T0,D0,Pzl,Tzl,Dzl,Pzr,Tzr,Dzr,Pfw,Tfw,Dfw,Pgl,Tgl,Dgl,Pzj,Tzj,Dzj等19个参数作为输入,下标0、zl、zr、fw、gl、zj分别表示主蒸汽、再热蒸汽入口、再热蒸汽出口、给水、过热减温水、再热减温水的压力 P/Mpa、温度T/℃、流量D/t·h-1。输出则为汽轮机热耗率RH/kJ·(kW·h)-1。
5.2.2 热耗率预测实例分析
表1 为在多工况下采集的某火电厂超临界汽轮机组(CLN600-24.2/566/566 MW)的289组原始数据,将其中的217组数据用来训练模型,72组数据用来预测模型,建立多模型预测模型。核模糊聚类个数c为5,局部模型最优的参数对见表2。为了验证多模型的性能,与单一LS-SVM模型和BP网络模型进行比较。BP网络采用3层网络结构:第1层19个输入,第3层1个输出,含有14个神经元的隐层,训练函数为traingdm。具体各预测模型预测结果与精度分析见图3、图4、图5和表3。精度指标定义为
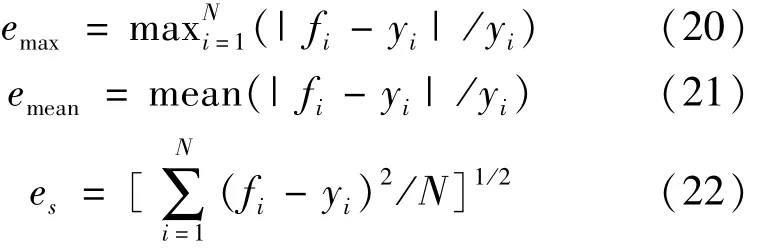
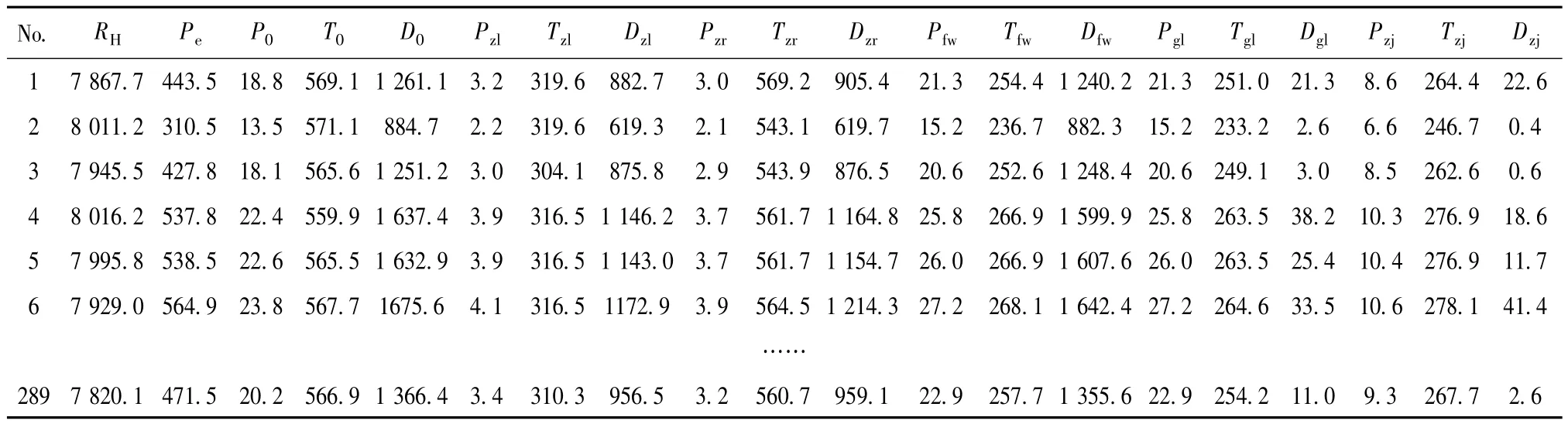
表1 某火电厂超临界汽轮机组运行参数

表2 参数选择结果

表3 各模型预测结果精度分析
图3~图5为各模型对测试集的预测结果,由图可以发现,多模型方法的预测精度高于单模型和BP网络。图6为测试集的各模型预测误差曲线,由图可以看出,多模型预测误差明显小于单模型预测误差和BP神经网络预测误差。表3数据显示,无论对训练样本还是测试样本,文中提出的方法的emax、emean和es均优于单一LS-SVM和BP网络。尤其是es指标,表明多模型预测误差波动范围小,更能适合工况范围大的建模。实验结果表明,文中提出的多模型建模方法能进一步提高软测量模型的精度,能较好地预测热耗率。

图3 单LS-SVM模型预测结果

图4 BP网络模型预测结果

图5 多模型预测结果
6 结 论
热耗率与影响它的因素之间是一种高度非线性关系,其工况变换范围较大,基于核模糊c均值和SFLA优化的LS-SVM的热耗率多模型能根据测试样本所属类进行对测试数据的输出预测,并且多模型可以为各个工况建立子模型,这样提高了整体的预测精度。仿真实验充分表明:该方法能更加有效、精确地描述热耗率特性,能够满足工业生产的需求,具有很好的推广价值。
]
[1] 王雷,张欣刚,王洪跃,等.基于支持向量回归算法的汽轮机热耗率模型[J].动力工程,2007,27(1):19-23.
[2] 陈鸿伟,刘焕志,李晓伟,等.双循环流化床颗粒循环流率试验与BP神经网络预测[J].中国电机工程学报,2010,30(32):25-29.
[3] 李岩,王东风,焦嵩鸣,等.采用微分进化算法和径向基函数神经网络的热工过程模型辨识[J].中国电机工程学报,2010,30(8):110-116.
[4] Vapnik V.The nature of statistical learning theory[M].New York:Springer,1995.
[5] 叶林,刘鹏.基于经验模态分解和支持向量机的短期风电功率组合预测模型[J].中国电机工程学报,2011,31(31):102-108.
[6] Liu G H,Zhou DW,Xu H X,etal.Model optimization of SVM for a fermentation soft sensor[J].Expert Systems with Applications,2010,37(4):2708-2713.
[7] Wang P,Tian J W,Gao C Q.Infrared small target detection using directional highpass filters based on LSSVM[J].Electronics Letters,2009,45(3):156-158.
[8] Eusuff M,Lansey K,Pasha F.Shuffled frog-leaping algorithm:a memetic meta-heuristic for discrete optimization[J].Engineering Optimization,2006,38(2):129-54.
[9] 王洋课.基于聚类的多模型软测量技术的研究[D].南京:东南大学,2010.
[10] Niu P F,Zhang W P.Model of turbine optimal initial pressure under off-design operation based on SVR and GA[J].Neurocomputing,2012,78(1):64-71.
Investigation on Multi-modelModeling Method of Steam Turbine Heat Rate
NIU Pei-feng1,2, LIU Chao1, LIGuo-qiang1, MA Yun-fei1, CHEN Gui-lin1,2, ZHANG Xian-chen1,2
(1.Key Lab of Industrial Computer Control Engineering of Hebei Province,Yanshan University,Qinhuangdao,Hebei066004,China;2.National Engineering Research Center for Equipment and Technology of Cold Strip Rolling,Qinhuangdao,Hebei066004,China)
Taking into account the problem that the heat rate of steam turbine is difficult to accurately calculate,a novel heat rate multi-model soft measurement methodology based on kernel fuzzy c-means and shuffled frog-leaping algorithm optimized least squares support vectormachine(LS-SVM is proposed),which is employed to calculate the heat rate under differentworking conditions.Thismethod applies kernel fuzzy c-means algorithm clustering heat rate data.Taking themean error of5-fold cross-validation as fitness value of parameters selection for LS-SVM,LS-SVM based on SFLA is trained and established localmodel for each cluster,and then themodel output is obtained by the switch way,so as to realize the heat ratemulti-modelmethod.Compared with the single LS-SVM model and BP network heat rate prediction model,the multimodel has a higher prediction accuracy and better generalization ability.
Metrology;Heat rate of steam turbine;Shuffled frog-leaping algorithm;Multi-model modeling;Least square support vectormachine;Kernel fuzzy c-means algorithm
TP941
:A
:1000-1158(2015)03-0251-05
10.3969/j.issn.1000-1158.2015.03.07
2012-08-25;
:2015-02-13
国家自然科学基金(60774028);河北省自然科学基金(F2010001318)
牛培峰(1958-),男,吉林舒兰人,燕山大学教授,博士生导师,主要研究方向为复杂工业系统的智能建模与智能控制及流程工业综合自动化。npf882000@163.com
猜你喜欢
体育教学(2022年4期)2022-05-05 21:26:58
机电信息(2021年5期)2021-02-22 06:47:26
能源工程(2020年5期)2021-01-04 01:29:00
魅力中国(2016年52期)2017-09-01 12:02:09
娃娃画报(2016年5期)2016-08-03 19:25:40
广西电力(2016年4期)2016-07-10 10:23:38
工业设计(2016年4期)2016-05-04 04:00:23
科技资讯(2014年1期)2014-11-10 21:24:52
河南科技(2014年11期)2014-02-27 14:09:55
华东理工大学学报(自然科学版)(2014年1期)2014-02-27 13:48:35
