
面向非写分配高速缓存的一致性协议及实现
2015-08-10 09:19修思文谢天艺葛海通严晓浪
浙江大学学报(工学版) 2015年2期
修思文,黄 凯,余 慜,谢天艺,葛海通,严晓浪
(1.浙江大学 超大规模集成电路研究所,浙江 杭州310027;2.杭州中天微系统有限公司,浙江 杭州310027)
随着性能和功耗需求的不断增长,多核处理器系统已被业界广泛使用.其中,基于对称式共享存储器的多核处理器架构具有较低的通信延迟、易懂的编程模型、高效的代码和数据共享等特点因而备受欢迎,也最为常用[1].由于共享数据的存在,可能出现一个数据的多个版本同时存在于共享存储器和多个处理器的高速缓存(cache)中的情况.如果此时有多于一个的处理器对该数据进行写操作,则可能出现数据不一致的问题,导致程序执行发生错误.缓存一致性协议是一种用于保证多核处理器系统各处理器缓存中数据一致的机制,可由软件或硬件方式来实现[2].采用硬件方式维护一致性非常方便高效而且对软件透明,因此被广泛采用[3].其中,基于监听式的写无效协议具有对互连带宽占用小、硬件实现简单、资源占用较少等优点,被大多数多核处理器所采用[4].
写无效协议和处理器所采用的缓存的类型相关,如更新内存的方式是写回(write back)还是写透(write through);写缺失时的策略是写分配(write allocate)还是非写分配(no-write allocate).一些面向特殊应用的多核处理器会经常处理一些有大量数据重用的、输入和输出的数据流地址不相关的并行化应用(如图像处理等),适合采用基于写回、非写分配的缓存[5],避免不必要的缓存分配,减小对存储器带宽的压力.然而,现有的一致性协议及一些优化措施[6-9]都是针对写回、写分配的缓存.虽然传统的写无效协议可以应用在非写分配的缓存上,但发生写缺失时,不仅要发起对共享存储器的写操作,而且系统中不再存在有效的该缓存行,对性能和功耗的损失很大,亟待改进.
针对基于写回、非写分配缓存的特点,本文提出一种新型的高速缓存一致性协议——写干涉协议及其硬件架构.采用写干涉协议,可以减少对共享存储器的读写操作,降低了功耗,提升了系统的性能.
1 现有的写无效协议
现有的写无效协议主要包括MESI(Modified/Exclusive/Shared/Invalid)及其变种协议.MESI协议应用比较广泛,其缺点是只能共享干净的缓存行——缓存行从修改状态(M)转移到其他状态时,一定要引起 写 回 操 作.MOESI(Modified/Owner/Exclusive/Shared/Invalid)协议解决了这个问题,它引入了所有者状态(O),支持了脏数据的共享,减少了写回操作,是目前最为流行的MESI类协议[4],被AMD、ARM等公司所采用.Intel公司提出的MESIF(Modified/Exclusive/Shared/Invalid/Forward)协议是另外一种MESI协议的另外一个变种,但其旨在解决ccNUMA(Cache Coherence Non Uniform Memory Access)架构中处理器子系统间的一致性问题[10].然而,现有的MESI和MOESI等协议在应用到写回、非写分配的缓存时,都会引起性能和功耗上的损失,这里以MESI为典型例子加以说明.基于写回、非写分配的缓存的MESI协议的状态转换如图1所示.

图1 基于写回、非写分配缓存的MESI协议状态转换图Fig.1 Write-back and no-write-allocate cache based MESI protocol state transition
处理器发生写缺失时,先发出一个写缺失请求,使其他处理器中该缓存行的副本无效,然后再把数据写到共享存储器中.其他处理器若监听到有处理器对处于独占(E)、共享(S)或修改状态(M)的缓存行进行写操作,都将该缓存行的状态转换为无效状态(I),处于修改状态(M)的缓存行还要抢先写回共享存储器中.可见,由于采用非写分配的高速缓存,当有处理器对某个高速缓存行产生一次写缺失时,需要发起对共享存储器的写更新操作,且所有处理器均不存在该高速缓存行的有效副本.紧接着,任何处理器下一次对该缓存行的读操作也必定是缺失的,且需要发起对共享存储器中该行的读操作.更差的情况,如果没有处理器发起过对该缓存行的读操作,之后对该缓存行的写操作都是缺失的,处理器会频繁地发起对共享存储器的访问.由于外部共享存储器一般由容量较大的DRAM 实现,需要不断的刷新,不仅功耗较大,而且访问延时远大于处理器内部时钟,因此,以上情况极大地影响了性能和功耗.
2 写干涉协议
针对现有MOESI等协议运用于写回、非写分配缓存的缺点,提出了写干涉协议,该协议利用以下5种状态的一种来标记各缓存行:
无效状态(I):指示该缓存行无效.
独占干净状态(EC):指示该缓存行只存在于当前的缓存中,并且是干净的(和共享存储器中该行中的数据一致).当监听到数据请求时,处于EC 状态的缓存行必须提供数据.
独占修改状态(ED):指示该缓存行只存在于当前的缓存中,但它已被修改过,是脏的(在共享存储器中的该行中的数据不再有效).当监听到数据请求时,处于ED 状态的缓存行必须提供数据.
共享干净状态(SC):指示该缓存行存在于当前的缓存中,而且其他处理器也可能拥有该缓存行.处于SC状态的缓存行在被替换时不负责更新共享存储器;当监听到数据请求时,如果被仲裁选中,它必须提供数据.
共享修改状态(SD):指示该缓存行存在于当前的缓存中,而且其他处理器也可能拥有该缓存行.处于SD 状态的缓存行在被替换时负责更新共享存储器;当监听到数据请求时,如果被仲裁选中,它必须提供数据.
本协议定义了2个标记:“修改者标记”和“所有者标记”.拥有修改者标记的缓存行要负责把被修改过的数据写回到共享存储器中.因此,处于ED 状态和SD状态的缓存行拥有修改者标记.拥有所有者标记的缓存行既要负责给请求该缓存行的处理器提供数据,也要承担对该缓存行的写干涉.显然,处于ED状态和EC状态的缓存行拥有所有者标记.当缓存行在系统中仅存在SD状态或SC状态时,由核间互连负责仲裁、赋予所有者标记.根据时间局部性原理,当发生缓存间的数据拷贝时,修改者标记将随之迁移,请求该缓存行的处理将在下次所有者标记仲裁时拥有最高的优先级.
如图2所示列出了本协议的状态转换图.当某个处理器对某个缓存行中的某个地址产生写缺失操作时:若其他所有处理器中均不存在有效的该缓存行,则把数据写到共享存储器的该地址中.若其他处理器中存在有效的该缓存行,则把数据直接写入到其他处理器中拥有所有者标记的该缓存行中(定义为“写干涉”操作),并将其状态转换为ED 状态;同时,把其他处理器的该缓存行无效掉(定义为“写无效”操作),即状态转换为I状态.
当某个处理器对某个缓存行中的某个地址产生读缺失操作时:若其他所有处理器中均不存在有效的该缓存行,则将共享存储器中的该地址行分配到该处理器的缓存中,状态设为EC状态.若其他处理器中存在有效的该缓存行,则拥有所有者标记的该缓存行负责提供数据,并将其状态转化为SC 状态.同时,提供数据的缓存行将其修改者标记转移给请求数据的缓存行.
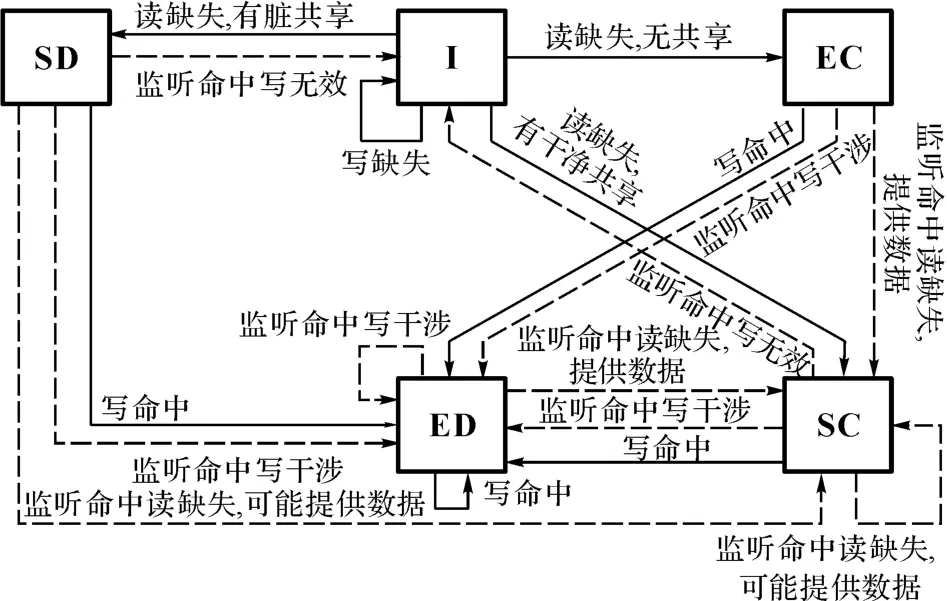
图2 写干涉协议状态转换图Fig.2 Write intervention protocol state transition
当某个处理器对某个处于SD 或SC 状态的缓存行中的某个地址产生写命中操作时:若不存在其他有效的该缓存行,则可以执行该写操作,且状态转换为ED 状态;若存在有效的该缓存行,则须将它们均无效掉,然后发起该写命中操作的处理器才可以执行该写操作,状态转换为ED 状态.
当某个处理器对某个处于EC 状态的缓存行的某个地址产生写命中操作时,可以直接执行该写操作,状态转换为ED 状态.其他情况下,状态不变.
3 协议正确性
利用符号模型状态法[11](symbolic state model,SSM),定义如下表示符:
0:表示有0个实例,表示时可以省略;
1:表示有且只有1个实例;
+:表示1个或多个实例;
*:表示0个、1个或多个实例.
通过这些符号,可以构建复杂状态的简明表示,例如可以用(SD1,SC+,I*)来表示:对于某个缓存行,一个或者多个缓存处于SC 状态,仅有1个缓存处于SD 状态,0个、1个或多个缓存是无效的.对于写干涉协议,从初始的(I+)状态开始扩张,每个状态转换的条件要覆盖写/读操作和替换操作,最后形成的状态转换图如图3所示.共产生了另外7种状态,在这些状态中,一致性都得到了保证,从而验证了写干涉协议的正确性.

图3 写干涉协议的SSM 状态转换Fig.3 SSM state transition of write intervention protocol
4 协议分析
4.1 写缺失
对于现有MOESI等协议,需要把系统中有效的该缓存行无效掉,如果系统中存在被修改过的缓存行,还要先把该缓存行写回到共享存储器中,最后把写缺失的数据写到共享存储器中.耗时(单位:处理器周期数)为
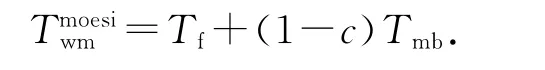
功耗为
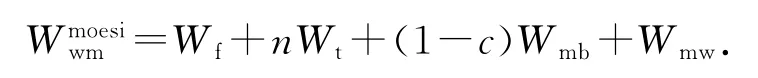
式中:耗时和功耗从处理器发出一致性请求开始算起,下同;c为指示系统中缓存行是否都是干净的布尔型变量,c=1代表系统中该缓存行都是干净的;n为表存在有效的该缓存行的处理器的个数;Tf和Wf分别为一致性操作固定的耗时和功耗;Tmb和Wmb分别为写回一个缓存行的耗时和功耗,有Tf≪Tmb;Wt为一致性命令更新一个处理器Tag RAM的功耗;Wmw为向共享存储器某地址写1个数据的功耗.设处理器每个缓存行包含k(一般k≥4)个写数据宽度大小的数据,则有2Wmw<Wmb≤kWmw.由于写缓冲区的广泛应用,对共享存储器的写操作对系统性能的影响很小.假设写缓冲区足够大,从处理器角度看,认为向共享存储器写一个数据没有耗时.
对于写干涉协议,只需把数据直接写到拥有所有者标记的缓存行,并更新缓存状态,同时把其他有效的缓存行无效掉.耗时为

功耗为

式中:Wcw为向处理器的某缓存行中写一个数据的功耗,有Wt<Wcw<Wf≪Wmw.
则写干涉协议相对于现有MOESI等协议的耗时节省比例为

功耗节省比例为

根据前面对各系数的分析可知,当c=1时,βwm趋近于1,αwm=0;当c=0时,βwm更趋近于1,αwm趋近于1.对比可见,采用写干涉协议,发生写缺失时,可以显著降低系统功耗;当存在脏缓存行时,可以显著提高系统性能;当不存在脏缓存行时,虽然性能没有提升,但由于缓存中保留了有效的该缓存行,对写缺失后再读和写缺失后再写影响很大.
4.2 写缺失后再读
对于现有MOESI等协议,系统中已不存在有效的缓存行,从共享存储器中读取数据,并更新该缓存行状态.耗时为
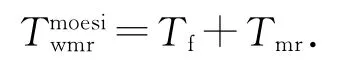
功耗为

式中:Tmr和Wmr分别为从共享存储器中读取一个缓存行到缓存中的耗时和功耗.
对于写干涉协议,如果发起读请求的是处于ED 状态的缓存行,直接命中;否则,产生读缺失,由处于ED 状态的缓存行提供数据,并更新双方的缓存行状态.耗时为
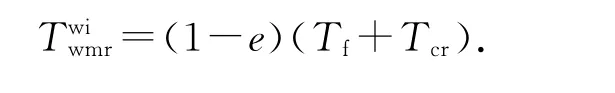
功耗为

式中:e为指示发起读请求的是否处于ED 状态的缓存行的布尔型变量,e=1时代表发起读请求的是处于ED 状态的缓存行;Tcr和Wcr分别为缓存间数据拷贝的耗时和功耗,有Tcr≤Tf≪Tmr和Wt<Wcr≤Wf≪Wmr.
则写干涉协议相对于现有MOESI等协议的耗时节省比例为

功耗节省比例为

根据前面对各系数的分析可知,当e=1 时,αwmr=1,βwmr=1;当e=0时,αwmr和βwmr均趋近于1.对比可见,采用写干涉协议,发生写缺失后再读时,可以显著降低系统功耗、提升系统性能.
4.3 写缺失后再写
如果写缺失后还没有处理器对该缓存行进行过读操作,对于现有MOESI等协议,系统中已不存在有效的该缓存行,直接把数据写到共享存储器中,耗时为

功耗为
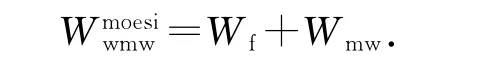
对于写干涉协议,如果发起读请求的是处于ED 状态的缓存行,直接命中;否则,直接把数据写到出于ED 状态的缓存行.耗时为

功耗为
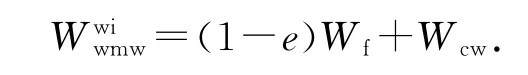
则写干涉协议相对于现有MOESI等协议的耗时节省比例为
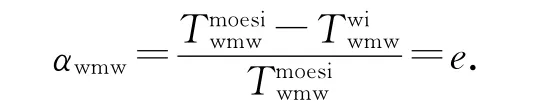
功耗节省比例为

根据前面对各系数的分析可知,当e=0 时,αwmw=0,βwmw均趋近于1;当e=1时,αwmw=1,βwmw更趋近于1;可见,采用写干涉协议,发生写缺失后再写时,可以显著降低系统功耗;当发起写操作的是被写干涉的处理器时,可以显著提升系统性能.更重要的是,如果写缺失之后没有对该缓存行的读操作,之后的写操作仍然存在这些优势.
5 硬件实现
5.1 总体架构

图4 CK610MP总体架构Fig.4 Architecture of CK610MP
采用写干涉协议,设计出如图4所示的CK610MP多核处理器,由修改后的CK610处理器[12]、核间互连以及AMBA AXI总线接口单元组成,并支持2~8个处理器的配置.修改了CK610处理器的读写单元(LSU)部分的逻辑,使其支持一致性请求的发起和一致性命令的响应.定制了核间互连模块,它不仅负责维护写干涉协议,还负责处理对共享存储器的请求;为了提高带宽,把数据和指令的通道分开.由于指令不存在一致性的问题,以下只讨论数据通道.
5.2 核间互连设计
如图5所示,核间互连由请求单元、一致性处理单元、存储器接口单元和应答单元组成.
请求单元负责串行化各个处理器的访问,并把一致性访问转发到一致性处理单元,把非一致性访问转发到存储器接口单元.

图5 核间互连架构Fig.5 Architecture of interconnect
一致性处理单元是核间互连的核心模块.一致性处理单元收到访问请求后,首先把信息压入一致性请求队列,同时查询Snoop Tag.下一个周期结果出来后进行比较,并根据查询的结果产生相应的一致性命令.由于Tag 比较后的时序已经非常紧张了,一致性命令会进入一致性命令缓冲区,下一个周期再发往相应的处理器,同时请求更新Snoop Tag.当一致性操作是读缺失时,如果Snoop Tag查询结果指示系统中存在有效的该缓存行,通过缓存间数据拷贝获取数据并发送给应答单元;否则把读请求发给存储器接口单元.当一致性操作是写缺失时,如果Snoop Tag查询结果指示系统中存在有效的该缓存行,则通过写干涉命令把缺失的数据写到拥有所有者标记的缓存中;否则把数据发送给存储器接口单元,写到共享存储器中.
存储器接口单元由写缓冲区、读缓冲区及总线接口组成,负责接收并发起对共享存储器的访问.
应答单元接收到一致性处理单元或存储器接口单元的响应后,按照相应的顺序答复发起访问的处理器.同一个处理器的操作,在核间互连中可以乱序执行,但需要按照请求单元记录的顺序按序应答;对于不同处理器的操作,如果没有地址依赖关系,可以乱序执行、乱序应答,极大地提高了性能.
5.3 处理器Tag和Snoop Tag
单核处理器Tag 一般由Tag RAM 和Dirty RAM 组 成.Tag RAM 中 保 存 相 应 索 引 字 段(index)的有效状态位(V)和标志字段(tag),Dirty RAM 用来保存脏状态位(D).对于写干涉协议,只需在Tag RAM 中扩充一个Exclusive(E)状态位,即可表示协议的5种状态.但是这里脏状态位的意义发生了改变,它不仅代表缓存中的数据和存储器中不一致,还代表更新共享存储器的责任,即拥有修改者标记.
在一致性处理单元中,利用Snoop Tag 来减少对其他处理器的不必要的干扰.Snoop Tag 可以看作是对每个处理器内部Tag 的拷贝,但由于Snoop Tag 只用来查询各处理器中是否存在被访问的缓存行,所以只需要一个有效状态位(V)即可,如表1所示.
如图5所示,Snoop Tag有3个访问源:查询请求、更新请求和维护请求(处理器的缓存清空或缓存同步操作).为确保功能正确,把维护请求的优先级设为最高.为了提高性能,避免一致性访问的堵塞,设置查询的优先级高于更新的优先级.如果出现查询与更新的竞争,更新请求将在一致性命令缓冲区等待,并且被视为Snoop Tag中的内容,会被随后的一致性访问所查询.然而,一致性命令缓冲区的大小终归有限,如果被填满仍会阻塞一致性访问.为了进一步提高性能,按照索引字段的低2位模4运算的结果把每个处理器的Snoop Tag 分为4 个块(bank),不同的块可以被同时访问,从而降低了查询请求与更新请求冲突的概率.至于处理器Tag,由于对Tag的访问处于时序的关键路径,所以不能进行分块.

表1 处理器Tag和Snoop Tag各状态位与写干涉协议各状态的对应关系Tab.1 Corresponding relation between the states of processor Tag and Snoop Tag and the states of write intervention protocol
5.4 处理器设计
处理器部分的设计是基于CK610单核的扩展.如图6所示,新增了一致性命令接口、缓存间数据拷贝接口、缓存仲裁逻辑、一致性判断逻辑、请求接口和应答接口.
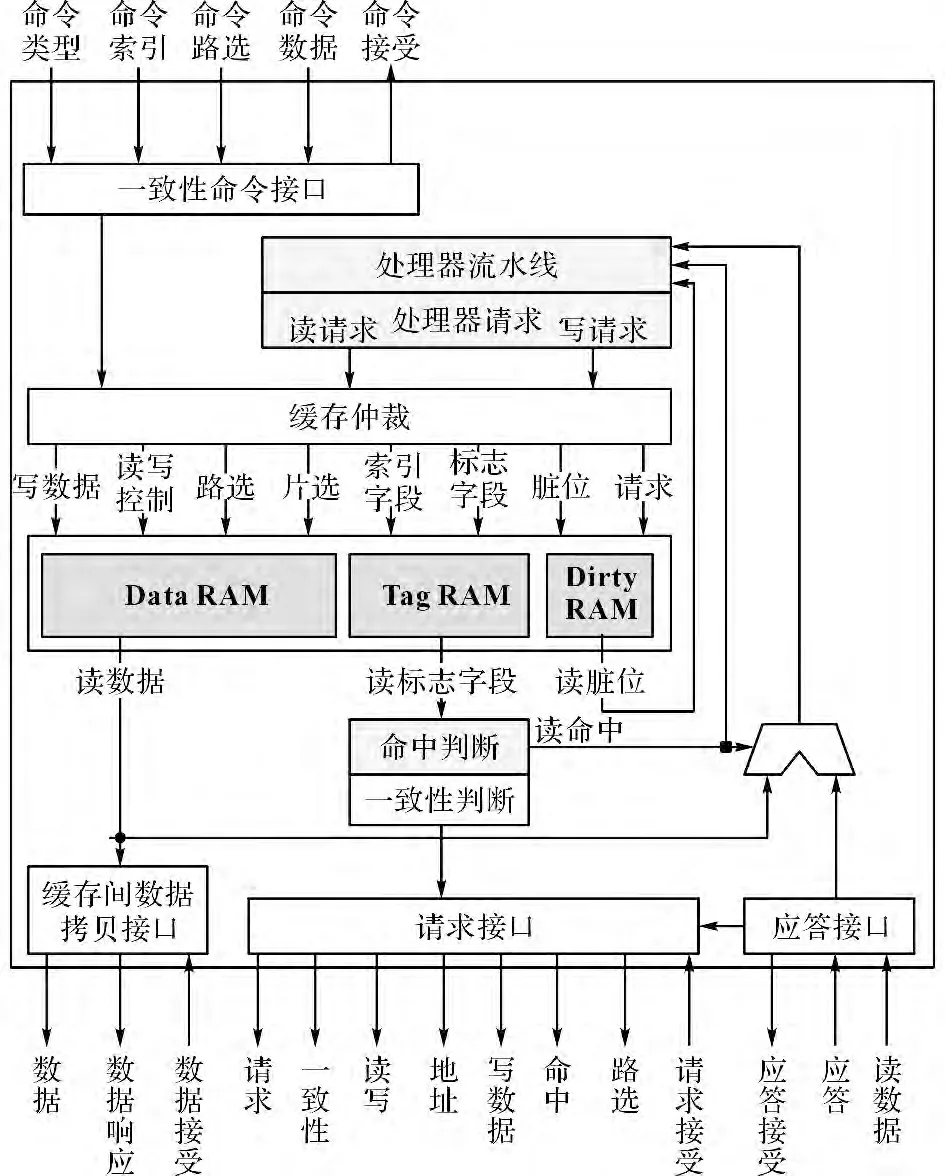
图6 处理器部分的架构Fig.6 Architecture of processor
利用可反转固定优先级的缓存仲裁逻辑来选择请求缓存操作的源.为了减少处理器的阻塞,提高性能,定义处理器读请求的优先级最高,其中,Tag查询请求也是读请求的一种.但是,如果处理器一直发起读请求,将会堵塞一致性命令,造成整个系统的堵塞.因此,设计规定:如果N 个处理器时钟周期后一致性命令还没有抢到缓存资源,处理器读请求和一致性命令的优先级将临时反转一次.由于核间互连保证了能够发往处理器的一致性命令的顺序一定是先于处理器未完成的一致性请求的顺序,所以定义处理器对缓存写请求的优先级为最低.
一致性命令接口用来把接收到的一致性命令译码成相应的对各个RAM 的操作,如表2所示,根据写干涉协议,定义了4种一致性命令,这里以“读数据命令”为例简要说明.当某个处理器发起读缺失请求时,核间互连向拥有所有者标记的处理器发送读数据命令,把处理器Tag RAM 相应index的E 位写为0,Dirty RAM 的D 位写为0,同时读取Data RAM 中的数据.这里利用了SRAM 的特性,把Dirty RAM 的数据输入端置0的同时,在数据输出端同时读出之前的D 状态位,和数据一起通过缓存间数据拷贝接口答复给核间互连,完成了修改者标记的转移.
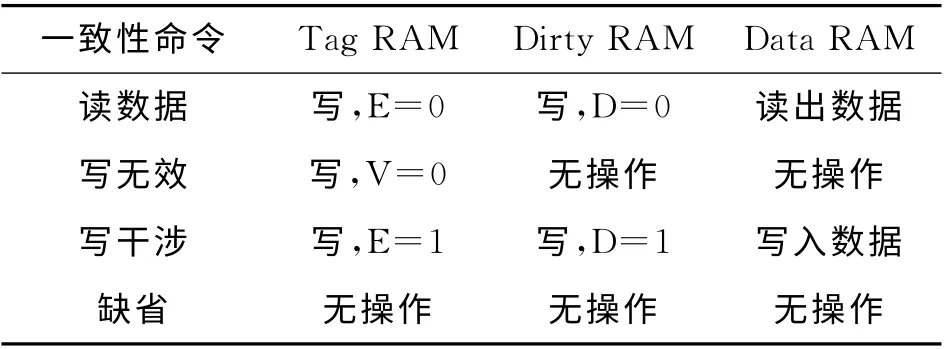
表2 一致性命令与对处理器缓存操作的对应关系Tab.2 Relation between coherence commands and operations on processor cache
一致性判断逻辑会根据一致性协议、缓存命中判断的结果和地址区间的属性来判断发起的请求是否为一致性请求,然后通过请求接口把信息发给核间互连.核间互连通过一致性处理后,通过应答接口发送应答、读数据、协议状态位、脏状态位等给处理器,完成整个操作.
6 实验结果与分析

图7 实验所用的系统环境Fig.7 Experiment environment
在实验中,CK610MP 被集成到一个小型系统中,如图7 所示,该系统还包括AXI总线、APB 总线、中 断 控 制 器(INTC)、定 时 器(TIM)、看 门 狗(WDT)、存储器控制器(MMC)及共享存储器(SDR).其中,各处理器一级数据/指令缓存大小为16KB,每个缓存行大小为4个字,采用SMIC65nmLL工艺的单端口SRAM;处理器时钟频率为480 MHz,AXI和SDR 时钟频率为120 MHz;SDR 选取的型号 为美光半导体(Micron)的MT48LC32M16A2[13],大小为128 MB.选取EEMBC Multi-bench[14]中有代表性的md5、rgbcmy和rotate程序进行性能测试和功耗评估.这3 个程序各有特点,md5 程序计算多数据流的MD5校验和,数据并行度较高,通信相对较少;rgbcmy程序把RGB 色彩模式的图像转换成CMYK 印刷色彩模式的图像,通信计算比高于md5;rotate程序处理一系列二进制图像,将其旋转90°、180°和270°,计算量很少,由于输入和输出的数据流地址相关性较低,会产生较多的写缺失,对共享存储器带宽带来压力.在服务器中进行ASIC仿真,通过统计程序运行时间以及对SDR 的访问次数来评 估 性 能;通 过Synopsys Prime Power 统 计CK610MP、AXI、MMC 和SDR 部分的动态功耗来评估功耗.其中,对共享存储器访问的统计是通过硬件性能计数器实现的.
实验中,用写无效协议中性能最好的MOESI协议作为参考和写干涉协议进行对比,分别比较2、4、6和8核配置下对相同任务的运行情况.为便于进行横向对比,CK610MP实现了2个版本:支持缓存间数据拷贝的MOESI协议版本和写干涉协议版本.
6.1 共享存储器访问次数测试结果及分析
如图8所示,在各种处理器核数N 配置下,写干涉协议(WI)对共享存储器的访问次数M 比MOESI协议对共享存储器的访问次数都有显著减少,其中,通信相对较少的md5 程序平均减少了6%;通信相对较多的rgbcmyk 程序平局减少了11%;写缺失较多的rotate程序平均减少了27%.

图8 共享存储器访问次数统计Fig.8 Statistics of shared memory access
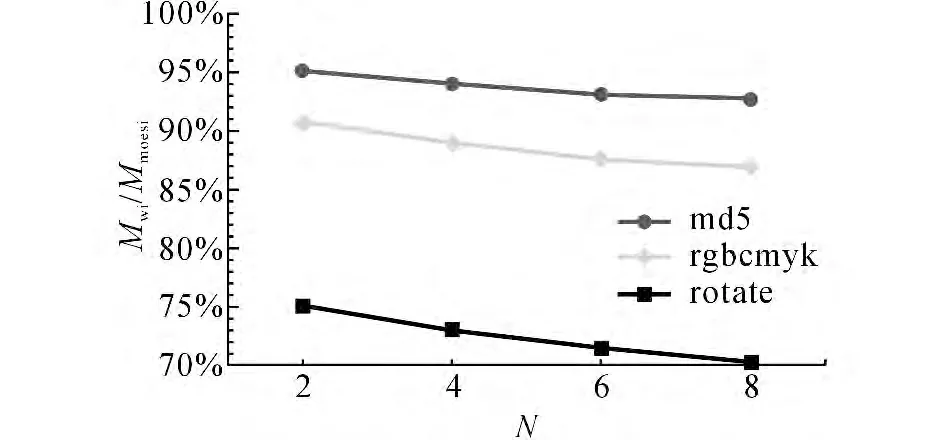
图9 归一化的共享存储器访问次数统计Fig.9 Normalized statistics of shared memory access
如图9所示 显示了写干涉协议对共享存储器访问次数(Mwi)占MOESI协议对共享存储器访问次数(Mmoesi)的百分比随处理器核数变化的情况.进一步发现,随着处理器核数的增多,核间通信随之增加,写干涉协议减少共享存储器访问次数的优势变得更明显.
6.2 性能测试结果及分析
如图10所示,写干涉协议减少了程序执行时间T,对性能有所提升,其中,md5程序平均减少了1%;rgbcmyk程序平均减少了2%,rotate程序平均减少了3%.从以上统计可以看出,写干涉协议可以减少共享存储器的访问次数,提升系统的性能,而且在处理器核数固定的情况下,随着核间通信比例的增加、写缺失比例的增加,这些提升变得更明显.
如图11所示显示了写干涉协议的程序执行时间(Twi)占MOESI协议的程序执行时间(Tmoesi)的百分比随处理器核数变化的情况.随着处理器核数的增多,核间通信及写缺失将增多.因此,在2、4、6核的配置下,写干涉协议对性能的提升逐渐变得明显.但是,随着处理器核数的增多,写干涉操作的时间、空间局部性将变差,被写干涉的缓存行极有可能被迅速替换掉,导致在8核配置下,写缺失比例少于rotate的md5 和rgbcmyk 程序对性能的提升程度有所降低.
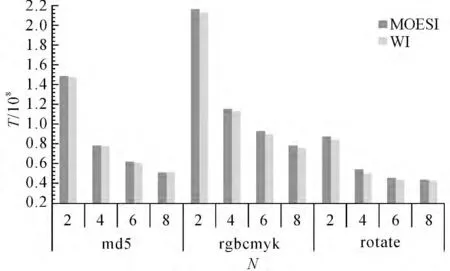
图10 执行时间统计Fig.10 Statistics of execution time
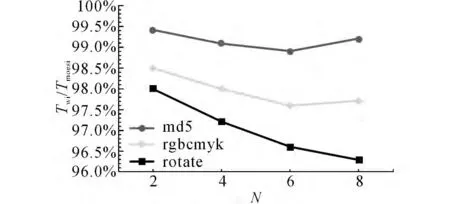
图11 归一化执行时间统计Fig.11 Normalized statistics of execution time
6.3 功耗测试结果及分析
CMOS电路中的功耗由2部分功耗组成,一部分是漏电流引起的静态功耗,另一部分是由信号翻转造成的动态功耗.这里讨论的功耗均为动态功耗.把整个系统的功耗分为3个部分:

式中:ECORES为处理器内核的功耗,EIC为核间互连的功耗,EOUT为AXI、MMC和SDR 部分的功耗.显然CK610MP部分的功耗为ECORES+EIC.根据第4 章分析可知,对比MOESI协议,写干涉协议大幅减少了对共享存储器的访问,因此降低了EOUT;增加了缓存命中率,因此降低了EIC;增加了缓存间的数据拷贝,将增加ECORES.而从如图12显示的实验结果来看,写干涉协议对EOUT的降低更为明显,因此总体的功耗(P)还是大幅下降的.其中,md5程序平均下降了3%;rgbcmyk程序平均下降了10%,rotate程序平均下降了13%.
如图13 所示显示了写干涉协议的总体功耗(Pwi)占MOESI协议的总体功能(Pmoesi)的百分比随处理器核数变化的情况.随着处理器核数的增多,数据部分的缓存间共享将增多,而指令部分无法进行缓存共享,导致处理器指令部分的功耗所占的比例将越来越大,是一致性协议无法解决的,因此ECORES占系统功耗的比例将越来越大,写干涉协议对功耗节省的优势将趋近饱和.
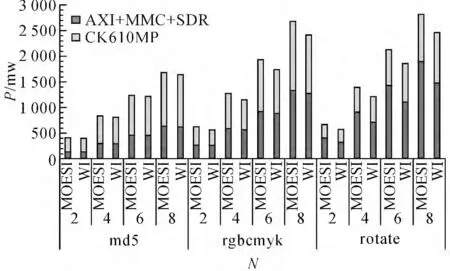
图12 动态功耗统计Fig.12 Statistics of dynamic power dissipation

图13 归一化动态功耗统计Fig.13 Normalized statistics of dynamic power dissipation
7 结 语
本文提出了一种基于写干涉的高速缓存一致性协议,用于采用写回、非写分配缓存的多核处理器系统,并在32位嵌入式多核处理器设计中加以实现.实验结果表明,和MOESI协议相比,写干涉协议减少了共享存储器的访问量,提升了系统的性能,同时也降低了动态功耗.
利用仿真的方法进行性能和功耗的评估,虽然结果精确,但速度很慢.今后,将对写干涉协议在更高的抽象层次进行快速评估,并将进一步考虑不同缓存大小和不同处理器体系结构等对协议的影响.
(
):
[1]ZHOU X,YU C,DASH A,et al.Application-aware snoop filtering for low-power cache coherence in embedded multiprocessors[J].ACM Transactions on Design Automation of Electronic Systems(TODAES),2008,13(1):16:1-16:25.
[2]CRAWFORD S E,DEMARA R F.Cache coherence in a multiport memory environment[C]∥Proceedings of the First International Conference on Massively Parallel Computing Systems.Ischia:IEEE,1994:632-642.
[3]STENSTROM P.A survey of cache coherence schemes for multiprocessors [J].Computer,1990,23(6):12-24.
[4]HENNESSY J L,PATTERSON D A.Computer architecture:aquantitative approach,Fourth Edition [M].Amsterdam:Elsevier,2007:208-284.
[5]LEVERICH J,ARAKIDA H,SOLOMATNIKOV A,et al.Comparing memory systems for chip multiprocessors[J].ACM SIGARCH Computer Architecture News,2007,35(2):358-368.
[6]JANG Y J,RO W W.Evaluation of cache coherence protocols on multi-core systems with linear workloads[C]∥ISECS International Colloquium on Computing,Communication, Control,and Managemen. Sanya:IEEE,2009:342-345.
[7]YI K,RO W,GAUDIOT J.Importance of coherence protocols with network applications on multi-Core processors[J].IEEE Transactions on Computers,2013,62(1):6-15.
[8]LI J M,LIU W J,JIAO P.A new kind of cache coherence protocol with sc-cache for multiprocessor[C]∥2010 2nd International Workshop on Intelligent Systems and Applications(ISA).Wuhan:IEEE,2010:1-5.
[9]KAXIRAS S,ROS A.Efficient,snoopless,system-onchip coherence[C]∥SOC Conference(SOCC).Niagara Falls,NY:IEEE,2012:230-235.
[10]HACKENBERG D,MOLKA D,NAGEL W E.Comparing cache architectures and coherency protocols on x86-64 multicore SMP systems[C]∥Proceedings of the 42Nd Annual IEEE/ACM International Symposium on microarchitecture. New York: IEEE, 2009:413-422.
[11]PONG F,DUBOIS M.Formal automatic verification of cache coherence in multiprocessors with relaxed memory models[J].IEEE Transactions on Parallel and Distributed Systems,2000,11(9):989-1006.
[12]C-SKY Microsystems Co.,Ltd.CK600Introduction[EB/OL].[2014-01-11].http:∥www.c-sky.com/downdisp.php?aid=72
[13]Micron Technology,Inc.MT48LC32M16A2datasheet[EB/OL].[2014-01-11].http:∥www.micron.com/~/media/Documents/Products/Data%20Sheet/DRAM/512Mb_sdr.pdf
[14]Embedded Microprocessor Benchmark Consortium.MultiBenchTM1.0 Benchmark Software [EB/OL].[2014-01-11].http:∥www.eembc.org/benchmark/multi_sl.php
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
教学考试(高考物理)(2021年5期)2021-11-08
历史教学问题(2021年4期)2021-11-05
中医眼耳鼻喉杂志(2021年1期)2021-07-22
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
燕山大学学报(2015年4期)2015-12-25
空间控制技术与应用(2015年3期)2015-06-05
汽车零部件(2014年1期)2014-09-21
微型计算机(2009年17期)2009-05-19
