
检测多元相关关系的最大信息熵方法
2015-07-05 16:46张亚红李玉鑑
电子与信息学报 2015年1期
张亚红李玉鑑 张 婷
(北京工业大学计算机学院 北京 100124)
检测多元相关关系的最大信息熵方法
张亚红*李玉鑑 张 婷
(北京工业大学计算机学院 北京 100124)
目前提出的用于检测变量间相关关系的方法,如最大信息系数(Maximal Information Coefficient, MIC),多应用于成对变量,却很少用于三元变量或更高元变量间的相关性检测。基于此,该文提出能够检测多元变量间相关关系的新方法 最大信息熵(Maximal Information Entropy, MIE)。对于k元变量,首先基于任意两变量间的MIC值构造最大信息矩阵,然后根据最大信息矩阵计算最大信息熵来度量变量间的相关度。仿真实验结果表明MIE能够检测三元变量间的1维流形依赖关系,真实数据集上的实验验证了MIE的实用性。
数据挖掘;多元相关;最大信息系数;最大信息熵
1 引言
相关性挖掘是数据挖掘的一个重要组成部分,其目标是发现数据集中变量间潜在的相关关系。当检测数据集中成对变量间的相关关系时,通常需要对成千上万对的变量进行检测,对于人工来说这是不可行的,由此人们提出了大量的用于检测变量间相关关系的方法。最常用于检测变量间线性相关的方法为Pearson相关系数,可定义为两个变量的协方差与二者标准差积的商,通常用r或ρ表示,其取值范围在[-1, 1]之间,绝对值越大表明变量间正(负)线性相关性越强。Pearson相关系数仅对变量间的线性依赖关系敏感,不具有通用性,然而在实际数据分析中,变量间的相关可以是任意的线性或非线性函数关系,以及更为复杂的统计依赖关系。由于对于存在相关关系的变量,Pearson系数通常也为0,即Pearson相关系数为0并不意味着两个变量在统计意义上独立。文献[1, 2]介绍了一种检测两个随机变量或向量(两向量可以不同维)间相关关系的方法 距离相关,任意两个随机变量的距离相关可由它们的距离协方差除以它们的标准距离方差的乘积得到,当且仅当两个随机变量在统计意义上独立时,距离相关才为0,该方法能够很好地检测变量间的线性和非线性相关关系。然而,距离相关在所有的噪声模型实验中表现出高度的不公平性,即具有不同的函数依赖形式的数据都加上类似的噪音,其相关性评分就会差别很大。另一方面互信息提供了一种通用的衡量两个变量间相关性的度量。文献[3-5]分别应用B样条方法、直方图法以及密度估计方法来估算变量间的互信息试图发现试验数据中变量间的相关关系,但都不具有良好的通用性和公平性。文献[6]介绍了一种以互信息为基础的在大型数据集中发现潜在相关关系的统计方法 最大信息系数(Maximal Information Coefficient, MIC),该方法能快速通过给不同类型相关进行评估,从而发现广泛范围的相关关系类型。与当前的变量相关性检测方法相比,MIC同时具有通用性和公平性,即无论数据是怎样分布的,不限于特定的相关函数类型,MIC都有效;计算的MIC值和噪音的程度有关,与相关的类型无关。MIC可能是世界上目前最好的相关性检测方法,被称为21世纪的相关性[7]。事实上,将MIC应用于世界卫生数据、棒球统计数据、酵母菌基因表达数据及一组人类肠道中细菌丰度的数据中确实发现了已知的和新奇的变量相关关系。此外,MIC还被广泛地应用于基因组学[8],蛋白质组学[9],微生物学[10],传感器[11]以及临床数据分析[12,13]等领域。
多元变量间相关性研究还比较少,主要有非线性相关信息熵[14](Nonlinear Correlation Information Entropy, NCIE)方法和距离相关t-检验[15](distance correlation t test)法。NCIE是一种无参数检测多元变量相关关系的方法,计算简单,且易于理解。通过将数据点均匀地分成几部分来估计任意两变量间的互信息,从而构造信息矩阵以计算多元变量间的非线性相关信息熵。NCIE虽然能够用0到1之间的值来衡量变量间的相关性但却不具有良好的通用性(如表1所示),而且高维数据空间经常出现的稀疏数据分布会大大降低该方法的可靠性。距离相关t-检验法通过扩展距离相关的方法来检验高维空间随机向量的独立性,与NCIE相比,该方法能够高效地检测出随机向量中的相关性,但同时计算复杂度也很高,且该方法仅适用于样本维度远大于样本点个数的情况。
本文以MIC能够很好地检测成对变量间的线性和非线性依赖关系,但却不能直接用于多元变量间的相关性分析为出发点,基于MIC,提出了能够检测多元变量间相关关系的最大信息熵(Maximal Information Entropy, MIE)方法。对于k元变量集合,首先根据任意两个变量间的MIC值来构造最大信息矩阵R,然后由R的正特征根来计算这k个变量间的最大信息联合熵,最后用1-来衡量变量间的相关度。MIE的取值范围为[0, 1],其中0和1分别表示最弱和最强的相关。
本文的组织结构如下:第2节介绍了最大信息系数(MIC);第3节提出了最大信息熵(MIE)方法;第4节通过3维空间曲线上的仿真实验说明MIE能够有效地检测三元变量间1维流形依赖关系,此外,本文还将MIE应用于全球健康数据的分析,进一步评价其分析真实数据的有效性和可行性;最后为总结和讨论。
2 最大信息系数(MIC)
MIC为检测两元变量间相关关系的统计量,其依据的理念是:如果变量X和Y之间存在着一种相关关系,那么就应该能够在变量的散点图上画一个网格,使得大多数的数据点集中在该网格的几个单元格中。通过搜寻这种“最适合”的网格,MIC可发现变量间广泛范围的相关关系。
给定一有限两元数据集合D,可按数据的x-和y-值把数据集D划分到不同的x行或y列中,其中允许某些行或列为空,这样一组划分称为x-by-y 网格G(grid)。D|G为集合D在G上的概率分布,其中任意一个格子内的概率密度函数值为这个格子内所包含的样本点数量占全体样本点的比例。对于固定的数据集合D,在不同的网格G划分下有不同的分布D|G。这里本文给出MIC的定义:
定义1 给定一个有限两元变量的数据集D,设G为一x-by-y划分,I(D|G)为集合D在划分G下的互信息,则

其中max取遍所有可能的x-by-y网格G。
定义2 给定一个有限两元变量的数据集D,设n为数据集大小,x, y为大于1的正整数,则MIC可定义为

其中B为可搜寻网格的上界,控制了MIC能够检测的相关关系的复杂度,在文献[6]中作者默认设置B=n0.6。
MIC以互信息来评价每个网格划分的好坏,再对得到的互信息值进行归一化处理,保证MIC的值在0到1之间。事实上,对于任意变量对(X, Y), MIC有如下3个性质:(1)如果Y为X的函数,且在任意的开区间不是常数,则随着样本数的增加,MIC必然趋于1; (2)如果X和Y是从形如c(t)=[x(t), y(t), z(t)]的可微空间曲线上抽取的,且dx/dt, dy/dt和dz/dt只在有限点为0,则随着样本点的增加,MIC必然趋于1; (3)如果X和Y在统计意义上独立,则随着样本点的增加,MIC必然趋于0。
3 最大信息熵(MIE)
对于k元变量数据集{X1, X2,…,Xk}, k>2,本文可根据MIC来计算任意两个变量间的相关度,由此可构建这k个变量的最大信息矩阵R。

最大信息矩阵R的对角元素表示k个变量中每个变量的自相关,由于有MIC(X, X)=1,所以ri, j= 1,{i=j,1≤i, j≤k };矩阵中的其他元素为不同变量间的最大信息系数,因为0≤MIC≤1,所以0≤故综上所述可知最大信息矩阵R为对角元素全为1且其他元素值在0到1之间的实对称矩阵。当k个变量中的任意两个变量在统计意义上相互独立,即R为单位矩阵,在这种情况下,k个变量间存在最弱的相关关系;当k个变量中的任意两个变量都有≤k }, R为全1矩阵,在这种情况下,k个变量间存在着最强的相关关系。也就是说k元变量的最大信息矩阵R能够反映这k个变量间的相关度。给定一有限数据集合D={X1, X2,…,Xk}以及对应的最大信息矩阵R,我们可定义集合D的信息联合熵为
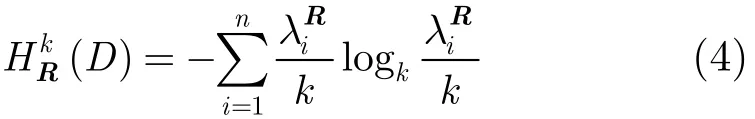
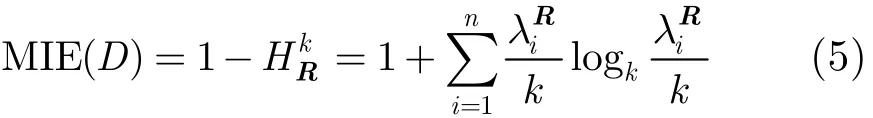
直观上来说,MIE是MIC从2维平面到高维空间的一种推广。给定一个有限k元变量的数据集D, MIE的计算过程可归纳为以下4步:
步骤1 计算k元变量间任意两变量间的MIC值;
步骤2 根据计算得到的MIC值构造最大信息矩阵R,其中R中的元素为
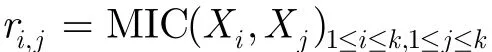
接下来本文给出MIE的3个基本特征。(1)MIE值在0和1之间;(2)MIE是对称的;(3)MIE具有保序变换不变性。这些特征的详细描述如下:
特征1 对于任意的k (k>2)元变量集合{X1,
证明 λiR为k元变量的最大信息矩阵R的正特征根,则有0<λiR,且根据矩阵特征根理论有已知在x∈(0,1]的区间上-xlogx
k在x=1/e处取得最大值,故有
当k个变量中的任意两个变量在统计意义上相互独立,即最大信息矩阵R为单位矩阵,{i=1,2,…,k },由式(5)可知MIE=0。当k个变量中任意两个变量间都有MIC(Xi, Xj)=1,{1≤i, j≤k},即最大信息矩阵R为全1矩阵,=0, {i=1,2,…,k -1}和=k,由式(5)可知MIE=1。
特征2 对于(1,2,…,k)的任意排列组合(i, j,…,m) 有MIE(X1, X2,…,Xk)=MIE(Xi, Xj,…,Xm)。
证明 任意k元变量集合{X1, X2,…,Xk},变量位置的变换相当于最大信息矩阵的行或列的转置,矩阵行或列的转置并不会改变矩阵的特征根,最大信息矩阵的特征根不变,所以MIE不变。 证毕
特征3 给定一任意k元变量集D=(X1, X2,…, Xk),如果D′为集合D中x1-,x2-,…,xk-值的保序变换集合,则有MIE(D′)=MIE (D)。
证明 给定集合D2={Xi, Xj},{1≤i, j≤k }和它的保序变换集合,有MIC(D2′)=MIC(D2)[6],故对k元变量集合D={X1, X2,…,Xk}做保序变换时,集合D对应的最大信息矩阵不变,即最大信息矩阵的特征根不变,所以有MIE(D′)=MIE(D)。 证毕
此外,MIE具有与MIC类似的通用性,即MIE能够检测多元变量间的线性和非线性相关关系。如图1所示。对于3维空间中的经典随机分布:均匀分布,正态分布和指数分布,它们的MIE值都很小,非常接近于0(如表1所示)。而对于3维空间中不同的1维流形依赖关系包括线性(如图1(d))和非线性(如图1(e)~图1(i))依赖关系,它们的MIE值都为1(如表1所示)。
4 实验结果与分析
在这一节本文通过在3维空间上的仿真实验来测试MIE的通用性;为了说明MIE在分析实际数据时检测多元变量间相关关系的实用性,本文利用世界健康卫生数据(WHO)的一个子集进行了一组应用性实验。
4.1 通用性实验
根据表1中定义的9种函数类型,通过均匀抽样的方式生成无噪声三元数据集{Di, i=1,…,9},其中数据集的大小为10000,分别计算它们的MIE值和NCIE值(其中在NCIE的计算过程中,通过将数据点均匀地分成100份来估算变量间的互信息)。由表1不难看出,对于三元变量间不同类型的线性和非线性1维流形依赖关系,它们的MIE值都为1,而NCIE值却不全为1。对于NCIE来说,三元变量间无噪声的线性依赖关系的相关度要强于非线性依赖关系的相关度,且表1(d)~表1(i)的依赖关系的相关度逐渐减弱,而事实并非如此。与NCIE相比,MIE具有通用性,而且统计意义上独立的三元变量集合的MIE值比NCIE值更接近于0。
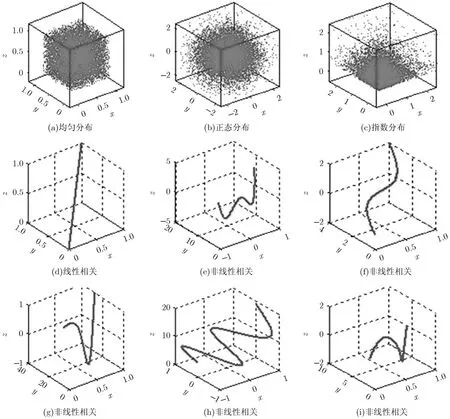
图1 3维空间中经典随机分布和1维流形依赖的例子

表1 图1中相关关系的定义以及对应的MIE值
在无噪声的情况下,以上实验结果验证了MIE能够检测三元变量间各种不同的1维流形依赖关系。对于图1(d)~图1(f)中列出的每一种流形依赖关系S,本文生成大小为10000的无噪声数据序列。接着通过对每一种依赖类型渐增地添加y-和z-方向的噪声的方式生成其余的49个数据序列计算确定系数R2(分别计算和在y-和z-方向上的平方Pearson相关系数和,其中R2为和的最小值)以及的MIE值。图2列出了R2分别为0.95, 0.90, 0.85, 0.80时每一种依赖关系S对应的MIE值。由图2不难看出,随着噪声的增加,三元变量间的相关度逐渐减弱,它们的MIE值逐渐减小。同时这一实验结果也验证了本文对MIE的定义:MIE值越大,变量间的相关性越强。
4.2 实用性实验
世界健康卫生数据(WHO)包含世界卫生组织及其合作伙伴[16, 17]所提供的社会、经济、健康和政治指标等数据。该数据集的二元依赖关系已经用MIC分析过[6],这里本文主要应用MIE分析其中三元变量间的相关关系。在分析时,本文只选择了其中的一个子集,由43个变量构成。这43个变量是文献[6]的表S9提供的,共包含12341个三元组。图3(a)是实验得到的MIE值直方图结果,其中MIE值大于0.5的三元组共有924个,占 7.5%。图3(b)~图3(h)给出了若干根据MIE值挑选的相关关系,图中拟合曲线由回归函数产生,较好地反映了数据的变化趋势。值得注意的是,图3(e)包含两条趋势线,少数点构成的趋势主要由一组高度发达的科技产业的国家组成,另一条趋势线则由其它大多数国家组成。此外,图3(f)包含3条趋势线,反映了“5岁以下儿童的死亡率(1/105)”,“人均健康投入”和“人均收入”这3个变量在不同条件下存在的3种依赖关系,从中不难看出,通过增加“人均收入”或者“人均健康投入”,都有助于降低“5岁以下儿童的死亡率(1/105) ”,因此可望指导决策者制定相应的全民健康政策。图3(h)中没有明显的变量相关关系,所以MIE值较小,只有0.083。
5 结束语
本文提出了一种检测多元变量间相关关系的最大信息熵(MIE)方法。同时给出了最大信息矩阵和MIE的定义,在该定义的基础上总结出MIE 3个基本特性:有界性、 对称性和保序变换不变性,且MIE值越大,变量间的相关性越强。3维空间上的仿真数据实验证实了MIE的通用性,且MIE在世界卫生真实数据集上的应用进一步证实它的实用性,而且发现了数据集中三元变量间新颖的依赖关系,所以可以说MIE对于大型数据集的相关性分析有着重要的意义。然而MIE依然面临不公平的问题,下一步将着重于研究MIE的公平性问题。
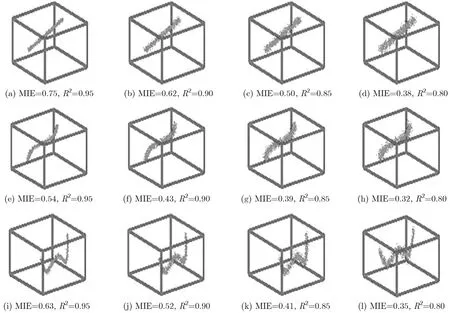
图2 MIE值随着噪声的变化

图3 MIE在WHO子集上的部分检测结果
[1] Székely G J, Rizzo M L, and Bakirov N K. Measuring and testing independence by correlation of distances[J]. The Annals of Statistics, 2007, 35(6): 2769-2794.
[2] Székely G J, Rizzo M L, and Bakirov N K. Brownian distance covariance[J]. The Annals of Applied Statistics, 2009, 3(4): 1236-1265.
[3] Venelli A. Efficient Entropy Estimation for Mutual Information Analysis Using B-splines[M]. Heidelberg, Berlin, Germany, Springer Berlin Heidelberg, 2010: 17-30.
[4] Silva J and Narayanan S S. On data-driven histogram-based estimation for mutual information[C]. IEEE International Symposium on Information Theory Proceedings, Austin, Texas, USA, 2010: 1423-1427.
[5] 韩敏, 梁志平. 改进型平均移位柱状图估算概率密度并对互信息做相关分析[J]. 控制理论与应用, 2011, 28(6): 845-850. Han Min and Liang Zhi-ping. Correlation analysis of mutual information by probability density estimated from improved averaged-shifted-histogram[J]. Control Theory and Applications, 2011, 28(6): 845-850.
[6] Reshef D N, Reshef Y A, Finucane H K, et al.. Detecting novel associations in large data sets[J]. Science, 2011, 334(6062): 1518-1524.
[7] Speed T. A correlation for the 21st century[J]. Science, 2011, 334(6062): 1502-1503.
[8] Das J, Mohammed J, and Yu H. Genome-scale analysis of interaction dynamics reveals organization of biological networks[J]. Bioinformatics, 2012, 28(14): 1873-1878.
[9] Pang C N I, Goel A, Li S S, et al.. A multi-dimensional matrix for systems biology research and its application to interaction networks[J]. Journal of Proteome Research, 2012, 11(11): 5204-5220.
[10] Koren O, Goodrich J K, Cullender T C, et al.. Host remodeling of the gut microbiome and metabolic changes during pregnancy[J]. Cell, 2012, 150(3): 470-480.
[11] Sagl G, Blaschke T, Beinat E, et al.. Ubiquitous geo-sensing for context-aware analysis: exploring relationships between environmental and human dynamics[J]. Sensors, 2012, 12(7): 9800-9822.
[12] Wang X, Duren Z, Zhang C, et al.. Clinical data analysis reveals three subytpes of gastric cancer[C]. 2012 IEEE 6th International Conference on Systems Biology, Xi’an, China, 2012: 315-320.
[13] Lin C, Can H, Miller T, et al.. Maximal information coefficient for feature selection for clinical document classication[C]. International Conference on Machine Learning (ICML) 2012, Workshop on Machine Learning from Clinical Data, Edingburgh, UK, 2012: 245-249.
[14] Wang Qiang, Shen Yi, and Zhang Jian-qiu. A nonlinear correlation measure for multivariable data set[J]. Physica D, 2005, 200(3/4): 287-295.
[15] Székely G J and Rizzo M L. The distance correlation t-test of independence in high dimension[J]. Journal of Multivariate Analysis, 2013, 117(1): 193-213.
[16] World-Health-Organization. World health organization statistical information systems (whosis)[OL]. http:// www. who.int/whosis/en/ 2009 .
[17] Rosling H, Indicators in gapminder world[OL]. http://www. gapminder.org/data/ 2008.
张亚红: 女,1987年生,博士生,研究方向为模式识别、数据挖掘、大数据分析等.
李玉鑑: 男,1968年生,教授,博士生导师,研究方向为模式识别、图像处理、机器学习、数据挖掘等.
张 婷: 女,1986年生,博士生,研究方向为模式识别、深度学习、大数据分析等.
Detecting Multivariable Correlation with Maximal Information Entropy
Zhang Ya-hong Li Yu-jian Zhang Ting
(College of Computer Science Beijing University of Technology, Beijing 100124, China)
Many measures, e.g., Maximal Information Coefficient (MIC), are presented to identify interesting correlations for pairs of variables, but few for triplets or even for higher dimension variable set. Based on that, the Maximal Information Entropy (MIE) is proposed for measuring the general correlation of a multivariable data set. For k variables, firstly, the maximal information matrix is constructed according to the MIC scores of any pairs of variables; then, maximal information entropy, which measures the correlation degree of the concerned k variables, is calculated based on the maximal information matrix. The simulation experimental results show that MIE can detect one-dimensional manifold dependence of triplets. The applications to real datasets further verify the feasibility of MIE.
Data mining; Multivariable correlation; Maximal Information Coefficient (MIC); Maximal Information Entropy (MIE)
TP391
A
1009-5896(2015)01-0123-07
10.11999/JEIT140053
2014-01-09收到,2014-04-01改回
国家自然科学基金(61175004),北京市自然科学基金(4112009),北京市教委科技发展重点项目(KZ01210005007),高等学校博士学科点专项科研基金(20121103110029)和北京工业大学第12届研究生科技基金(ykj-2013-9492)资助课题
*通信作者:张亚红 plahpu@163.com
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
铁道学报(2018年5期)2018-06-21
中国铸造装备与技术(2017年3期)2017-06-21
雷达学报(2017年6期)2017-03-26
安徽电气工程职业技术学院学报(2016年4期)2017-01-15
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
池州学院学报(2015年3期)2016-01-05
纺织导报(2015年4期)2015-06-18
电测与仪表(2015年9期)2015-04-09
