
科技计划与战略性新兴产业相关性研究与实现
2015-06-27 05:08:45李光文
天津科技 2015年12期
李光文
(天津市科技统计与发展研究中心 天津300051)
科技计划与战略性新兴产业相关性研究与实现
李光文
(天津市科技统计与发展研究中心 天津300051)
科技计划以支撑引领经济社会发展为目标,战略性新兴产业是未来经济持续增长的先导产业。为研究科技计划项目与战略性新兴产业之间的相关性,将战略性新兴产业行业分类进行关键词拆分,使用关键词在科技计划项目研究内容中进行搜索,对搜索结果利用空间向量模型建立一套分析模型,计算出科技计划与战略性新兴产业相关性系数,并对相关性系数进行分析。此外,利用天津市科技支撑计划项目数据对分析模型、分析方法进行了试算,试算结果显示两者相关性程度较高。
空间向量模型 科技计划 相关性
0 引 言
战略性新兴产业是一个国家或地区实现未来经济持续增长的先导产业,对国民经济发展和产业结构转换具有决定性的促进、导向作用,具有广阔的市场前景和引导科技进步的能力,关系到国家的经济命脉和产业安全。[1]战略性新兴产业具有技术新、市场前景好、资源消耗低、综合效益强等特点。我国的战略性新兴产业是在2009年召开的新兴战略性产业发展座谈会上提出来的,包括新能源、节能环保、电动汽车、新材料、新医药、生物育种和信息产业。
天津市以科学发展观为指导,不断提升自主创新能力,为更好地发挥科学技术对经济社会的支撑和引领作用,制定了天津市科技发展“十二五”规划,其主要目标是“加快提高优势产业和战略性新兴产业的技术自给能力和核心竞争力,提升科技对发展方式转变的支撑能力,率先建成水平更高、带动作用更强的创新型城市,成为我国自主创新高地、高水平研发转化基地、北方产业创新中心”。从规划可以看出,天津市把战略性新兴产业作为科技发展的重要任务。科技规划的落实主要体现在科技计划项目的实施上,“十二五”期间天津市科技计划项目与战略性新兴产业发展的相关性如何,是本文的研究重点。本文通过数据挖掘技术和搜索引擎技术,将战略性新兴产业包括的行业分类进行关键词拆分,利用关键词在科技计划项目主要研究内容中进行搜索,进行相关性分析,尝试建立两者的相关性。
1 分析技术与工具
1.1 向量空间模型(见图1)
向量空间模型(Vector Space Model)是由Salton等人在20 世纪70年代提出,用向量空间模型进行特征表达,用TFIDF (Term-Frequency Inverse-Document-Frequency)进行特征项赋权,TF-IDF认为如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,就认为该词或短语具有很好的区分能力,适合用来分类。向量空间模型用倒排文档进行索引,用余弦夹角进行距离度量,用查全率和查准率评价检索系统性能。向量空间模型已成为信息检索领域的研究基础。向量空间模型是在文本中提取其特征项构成特征向量,并以某种方式为特征项赋权,可以理解为在忽略特征项之间的相关信息后,一个文本用一个特征向量来表示,一个文本集表示成一个矩阵,也就是特征项空间中的一些点的集合。
1.2 向量空间模型使用关键
向量空间模型在使用过程中,需要重点解决特征项的选择和特征项赋权。中文文档是由汉字和标点符号等基本的语言符号组成的字符串,由字构成词,由词构成短语,进而形成句、段、节、章、篇等语言结构。中文文档的特征项可以是字、词、短语,甚至是句子或句群等。特征项的选择需要考虑处理速度、精度、存储空间等,遵循包含语义信息较多、文档在特征项上的分布具有统计规律性、容易实现等要求。特征项赋权一般由频率因子、文档集因子和规格化因子3部分组成。频率因子指特征项在文档中出现的频率,频繁出现的特征项具有较高权重。文档集因子是与文档集合有关的因子,加大文档之间的区分度。规格化因子是为了解决文档长度对匹配结果的影响。

图1 向量空间模型Fig.1 The vector space model
1.3 向量空间模型应用
向量空间模型的重要应用是两个文档D1和D2之间相似度Sim(D1,D2)研究,当文档D1、D2被表示为空间向量时,就可以计算向量之间的距离来表示文档间的相似度,常用的距离计算有余弦距离公式:
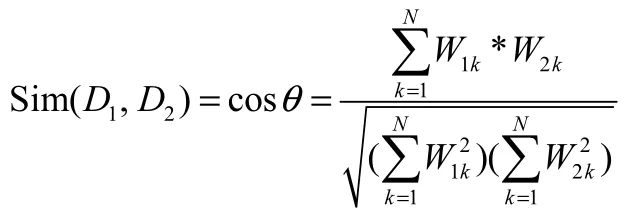
1.4 中文分词技术
英文以词为单位,词和词之间使用空格隔开,而中文是以字为单位,句子中所有的字连起来才能描述一个意思。例如,英文句子“I am a student”,用中文表达为“我是一个学生”。计算机程序可以很容易通过空格知道student是一个单词,但是不能很容易明白两个字合起来才表示一个词。把中文的汉字序列切分成有意义的词,就是中文分词。中文分词技术主要用于搜索引擎,用于对用户提交的查询关键词进行处理再搜索。中文分词技术主要有字符串匹配分词法、词义分词法、统计分词法。
1.5 Lucene搜索引擎
Lucene是Apache软件基金会的一个子项目,它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎以及部分文本分析引擎。Lucene为软件开发人员提供了一个简单易用的工具包,以便于在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
2 分析方法
本文对空间向量模型进行了微调,引入分词技术、搜索引擎技术定义了分析模型(见图2),实现科技计划与战略性新兴产业相关性研究。
①按照国家统计局制定的《战略性新兴产业分类》(试行),将《国务院关于加快培育和发展战略性新兴产业的决定》中包括的节能环保产业、新一代信息技术产业、生物产业、高端装备制造产业、新能源产业、新材料产业、新能源汽车产业等7个战略性新兴产业,与《国民经济行业分类》中的行业类别建立对应关系,实现了战略性新兴产业与行业分类相结合。共包括《国民经济行业分类》中的行业类别359个,战略性新兴产业产品及服务2410项,作为战略性新兴产业的特征项。
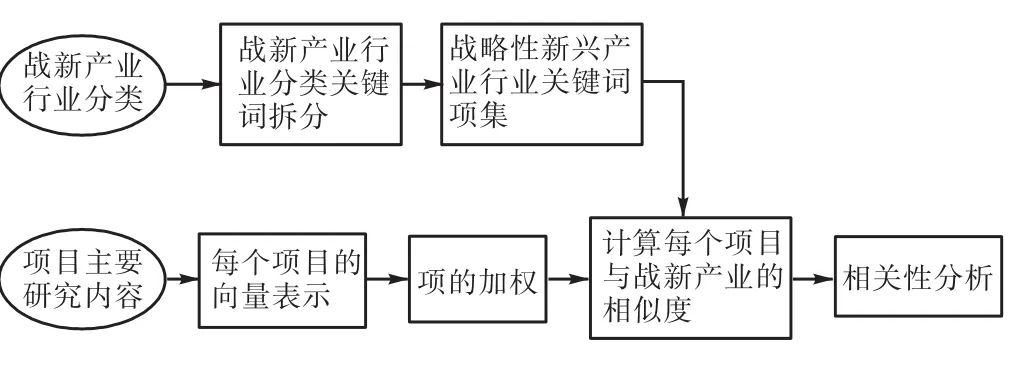
图2 分析模型Fig.2 Analysis model
②使用庖丁解牛分词技术编写程序,分别对七大战略性新兴产业对应的国民经济行业分类进行关键词拆分。再对关键词进行整理,包括:去掉每个产业中重复关键词;去掉一个字的关键词,如“大”、“新”等;通过主观判断去掉异常关键词,如“和气”、“水的”、“其他”等;去掉部分常用动词,如“发展”、“设计”、“利用”等。形成7个战略性新兴产业关键词项集Zn,n=7。7大战略性新兴产业规格化因子如表1所示。

表1 七大战略性新兴产业规格化因子Tab.1 Normalizing factor of seven strategic industries
③将科技计划项目主要研究内容作为科技计划特征项。使用Java语言,引入Lucene架构编写搜索引擎程序,利用每个战略性新兴产业的关键词项集,到每个科技计划项目中进行搜索,搜索出每个科技计划项目中出现的关键词,以及每个的关键词出现的次数,表示成X(t1,t2,…,tN)。计算出战略性新兴产业关键词项集与科技计划特征项之间向量余弦距离,作为其相关性系数。本文主要是研究向量相关性的相对大小,为了简化计算难度,忽略未在某个科技计划特征项中出现的战略性新兴产业关键词。将余弦距离计算公式变换为:
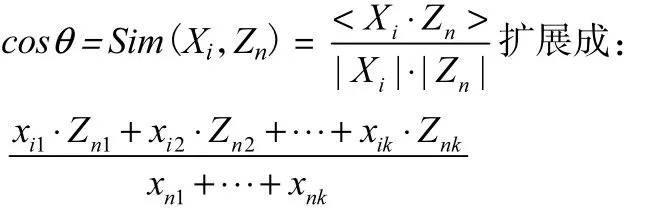
为消除每个产业关键词数量的差异导致的比较误差,设立规格化因子,w表示某个产业关键词项集的数量。每个项目内容与每个产业的相关性系数结果除以规格化因子作为最后相关性结果,对相关性系统进行分析。
3 研究结果
3.1 试算数据
天津市科技计划根据所支持项目研发处阶段设立了不同的科技计划类别,在天津市科技计划体系中,科技支撑计划定义为“为天津市产业升级和结构调整、社会可持续发展和提高人民生活质量提供技术支撑”,与产业发展最为紧密。本文选用“十二五”期间天津市科委支持的科技支撑计划项目作为试算数据。
3.2 试算结果
利用分析模型进行试算,试算结果显示,天津市科技支撑计划项目与战略性新兴产业相关性程度较高,不包含战略性信息产业关键词的项目仅占2.5%,含1个关键词的项目占9.8%,含2个关键词的项目占13.9%,含3个及以上关键词的项目占73.8%(见图3)。
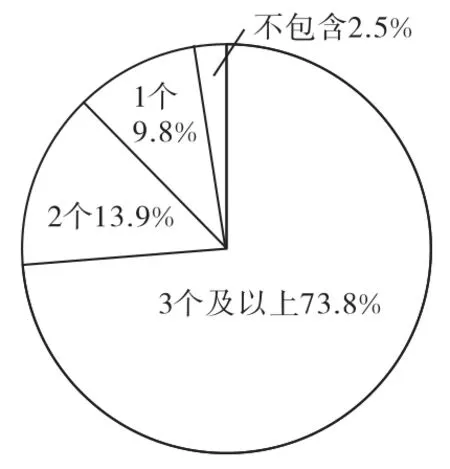
图3 项目含关键词数量比例Fig.3 Project keyword ratios
如果设定含有3个及以上关键词的项目与战略性新兴产业相关,说明天津市科技支撑计划项目与战略性新兴产业的相关性程度高。

图4 项目含关键词数量统计(单位:项)Fig.4 Statistics of project keyword numbers(Unit:per unit)
取含有3个及以上关键词的项目相关性系数作为有效观测数,共9544项(见图4),对有效观测数进行描述性汇总统计,相关性系数的最大值为4.111,最小值为1.007,中位数为1.671,众数为1.633。
根据项目立项年度对相关性结果进行分析,分析结果显示,天津市科技支撑计划项目与战略性新兴产业相关性逐年增大,呈上升趋势,如图5。

图5 相关性按年度统计Fig.5 Correlation between annual statistics
根据对七大战略性新兴产业分类,对相关性结果进行分析,结果显示天津市科技支撑计划项目与新一代信息技术相关性最高,与新能源汽车相关性最低,相关性程度依次为:新一代信息技术、高端装备制造、生物产业、节能环保、新能源、新材料、新能源汽车。说明天津市科技支撑计划对信息技术、装备制造、生物产业项目支持相对较多,而对新能源汽车项目支持相对较少。
4 存在不足
分析模型中为消除由于关键词数量不同导致的搜索结果偏差,设定了规格化因子,规格化因子的计算方式引自论文,其合理性需要进一步研究。本文在研究过程中,为了简化搜索过程,使用了约2000字的科技计划项目简要说明作为搜索内容,搜索内容偏少,下一步将研究实现对科技计划项目申请书进行全文搜索,增强相关性结果的科学性。分析模型完善后,可以应用到科技计划项目研究内容查重,项目评审回避专家等工作中,提高科技计划项目管理的科学性与公正性。
[1] 朱瑞博. 中国战略性新兴产业培育及其政策取向[J].改革,2010(3):19-28.
[2] 陈治纲,何丕廉,孙越恒,等. 基于向量空间模型的文本分类方法的研究与实现[J]. 计算机应用,2004(6):277-279.
[3] 杨小平,丁浩,黄都培. 基于向量空间模型的中文信息检索技术研究[J]. 计算机工程与应用,2003(15):109-111.
[4] Lucene 4. 0原理与代码分析–相似度评分算法之向量空间模型(VSM)[OB/EL]. http://so.searchtech. pro/articles/2013/05/22/1369204044879. html.
[5] 殷伟. 财务文档分词及文档相关性分析[J]. 电脑知识与技术,2013,9(7):1718-1719,1722.
[6] 庞剑锋,卜东波,白硕. 基于向量空间模型的文本自动分类系统的研究与实现[J]. 计算机应用研究,2001(9):23-26.
A Correlation Study of Science and Technology Plans and New Strategic Industries
LI Guangwen
(Tianjin Science and Technology Statistic Center,Tianjin 300051,China)
As science and technology plans take the goal of supporting and leading economic and social development and new strategic industries will become the leading industry in the future economic growth this paper studies the relationship between the S&T plan projects and new strategic industries. By dividing categories of new strategic industries into key words it carries out key words searching in the study content of the S&T Plan projects. The search results were modeled with the help of space vector model to calculate the correlation coefficients of the projects and the industries and then analyze them. In addition the data of Tianjin Science and Technology Support Program were used to analyze the model and the method. Test results show that the two have strong relevance.
vector space model;science and technology plan;implementation
G312
:A
:1006-8945(2015)12-0052-03
2015-11-08
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
河北地质(2017年1期)2017-07-18 11:08:09
生活用纸(2016年5期)2017-01-19 07:36:10
信息安全研究(2016年4期)2016-12-01 06:06:54
智库理论与实践(2016年1期)2016-03-20 16:22:27
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
学习月刊(2015年6期)2015-07-09 03:54:06
电子工业专用设备(2015年4期)2015-05-26 09:10:40
江苏年鉴(2014年0期)2014-03-11 17:09:30
中央社会主义学院学报(2013年6期)2013-03-01 04:18:51
