
基于分布式存储系统的数据认证和安全保障研究
2015-06-24 13:56:57王丹辉
中国电子科学研究院学报 2015年6期
王丹辉
基于分布式存储系统的数据认证和安全保障研究
王丹辉
(中国电子科学研究院,北京 100041)
在业界通用的分布式存储系统中,对于数据安全性的防护是薄弱和缺失的。在其被用于解决云端的数据存储时,由于数据安全性要求较高,这一问题极为明显。本文以HDFS系统为例,提出了一种有效的基于分布式存储系统的数据安全保障方案。方案为文件存储提供AES加密机制,给出一种能够与分布式计算系统无缝结合的文件加密格式,同时提出了一种基于涉密数据的授权鉴权方式,并持续监控审计。
分布式;存储;数据安全;HDFS
0 引 言
随着大数据时代的到来,业界越来越倾向于使用分布式存储系统去管理、存储数据文件。分布式存储系统诸如Google文件系统(Google File System,GFS)、Apache Hadoop分布式文件系统(Hadoop Distribute File System,HDFS)[1],通过使用大规模的廉价机器硬件,将数据文件拆分存储,以及提升整体读写吞吐等技术手段,在数据存储规模、性能、价格、以及稳定性上获得了极大的成功。鉴于此类分布式存储系统的优异表现,业界的文件存储系统大多遵循这一体系架构实现。
另一方面,开放云的兴起使得多用户共享集群隔离存储的需求快速增长,分布式存储系统的数据安全性也越来越引起人们的关注和重视。但在现有的这种分布式存储体系模式下,数据存储存在很多的风险和问题,一旦系统被攻破,将会造成极大的数据泄露风险和损失。
其中HDFS因为在业界使用最为广泛,其数据安全问题影响范围最广,也最具共性。本文将以HDFS系统为例,分析其存在的数据安全性问题,并针对这些问题,提出了一套基于分布式存储系统的数据认证和安全保障。
1 HDFS分布式存储系统的数据安全性
Hadoop是Apache的一个开源项目[2],用来支持数据密集型的分布式应用,能够支持上千个节点以及PB级数据量的运算[3]。Hadoop主要由HDFS和MapReduce引擎两部分组成,最底层是HDFS,它存储Hadoop集群中所有存储节点上的文件[4]。HDFS是为以流式数据访问模式存储超大文件而设计的文件系统[5],为Hadoop提供了数据的可靠性。第1节以HDFS为例分析现有的分布式存储系统的安全特性。
1.1整体组件架构
HDFS采用的是Master/Slave主从架构模型,如图1所示,一个HDFS集群包含一个单独的Master节点NameNode和一系列Slave节点DataNode。NameNode是中心服务器,充当管理者的角色,主要负责管理HDFS文件系统,接受来自客户端的请求;DataNode是工作节点,主要用于存储数据文件,文件数据的读写是直接在DataNode上进行的。HDFS将一个文件分割成多个独立的Block,这些Block可能存储在一个或多个DataNode上,DataNode同时为用户或NameNode提供定位Block的服务。

图1 HDFS架构图
1.2文件存储形式
如图2所示,对于存储于HDFS上的数据文件,HDFS会将文件分割成数个Block并将其存储到不同的DataNode中。在创建Block的时候,NameNode服务器会存储这些Block和文件的映射关系,Data-Node服务器把Block保存在本地硬盘上,并且根据指定的Block标识和字节范围来读写块数据。同时为了保障数据的安全性和完整性,HDFS提供了多副本主从复制,从而保证了数据的Block的副本存储于多个DataNode机器上。
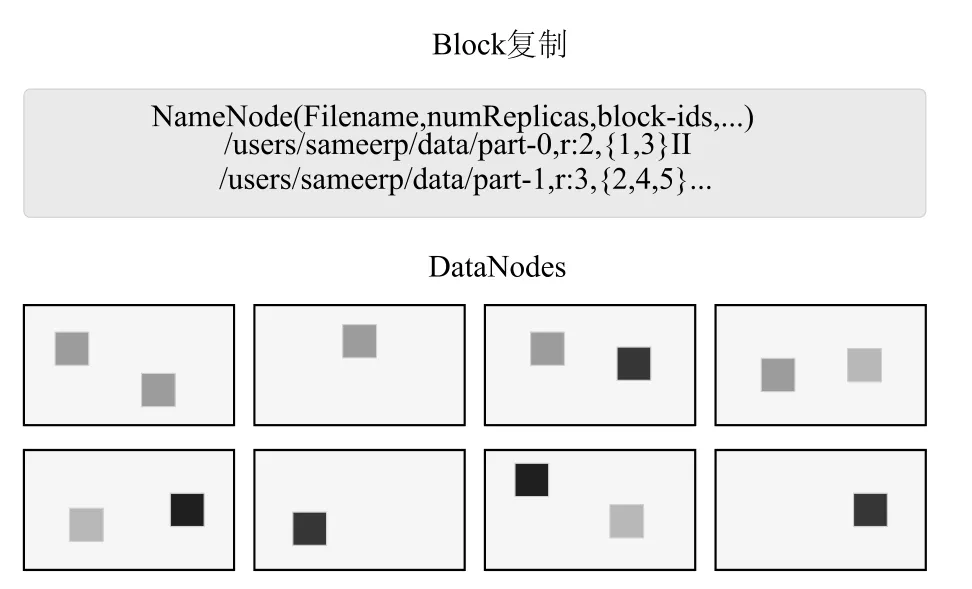
图2 HDFS文件存储形式
1.3身份识别机制
HDFS系统实现了一个和可移植操作系统接口(Portable Operating System Interface,POSIX)系统类似的文件和目录的权限模型。每个文件或目录有一个所有者(Owner)和一个组(Group),文件或目录对其所有者、同组的其他用户以及所有其他用户分别有着不同的权限[6]。由于不涉及可执行文件的概念,HDFS权限模型与POSIX模型不同,其中的文件和目录都不设特殊权限位sticky、setuid和setgid。HDFS文件或目录的权限就是它的模式,当新建一个文件或目录,它的所有者即客户进程的用户,它的所属组是父目录的组[6]。
访问HDFS的用户进程的标识由用户名和组名列表两部分组成,当用户进程每访问一个文件或目录时,HDFS将对用户进行权限检查。权限检查过程如下:
(1)如果用户为此文件或目录的所有者,则检查所有者的访问权限;
(2)如果此文件或目录关联的组在组名列表中出现,则检查组用户的访问权限;
(3)否则检查此文件或目录其他用户的访问权限;
(4)如果访问权限不合法,则权限检查失败,也就是说客户的操作失败。
然而一方面,这种权限检查方式无法抵抗用户假冒其他用户身份的行为,另一方面,这种用户身份识别机制以及权限模型设定,使得一个有组织的用户群体能够共享文件系统中组群用户的资源。
2 业界常见的数据安全改进思路
从第一节可以看出,在设计之初,类似HDFS的分布式存储系统并没有很好的考虑系统的数据安全问题。随着分布式存储系统在大数据潮流之下,应用场景越来越广泛,其本身存在的安全问题也愈发的凸显。大量的安全漏洞及安全风险,也促使业界和厂商更加关注于HDFS的数据安全,并提供了一些解决方案和思路。
2.1业界和厂商提供的HDFS安全解决方案
业界和厂商提供的HDFS安全解决方案,大多以HDFS“安全加强版”的形式提供,通过修改HDFS代码和安全架构解决HDFS的数据安全问题。比较著名的有intel的安全版hadoop,IBMInfoSphere Optim Data Masking,Cloudera Sentry,DataGuise for Hadoop,Revelytix Loom、Zettaset安全数据仓库,Data-Stax企业版等。另外,Apache社区也提供了类似的Apache Accumlo,Knox网关,Rhino项目用于解决HDFS的数据安全问题。
几乎所有参与Hadoop项目的厂商都提供了自己的解决方案和产品,但这些方案并不可以平滑迁移到任意HDFS版本的集群上,更多的是以整体安全方案的形式售卖。
2.2解决方案安全性分析
业界和厂商提供的HDFS安全解决方案,主要是从HDFS文件访问控制、数据块访问控制、网络加密三个方向来增强HDFS的安全性。
(1)HDFS文件访问控制
Hadoop 0.20之后的版本引入了Kerberos RPC(SASL/GSSAPI)的机制,也就是说可以在RPC连接上做相互认证,通过这个机制,就可以实现RPC连接上的用户、进程以及Hadoop服务的相互认证。而基于这个认证,可以通过NameNode根据文件许可(用户及组的访问控制列表(ACLs))强制执行对HDFS中文件的访问控制,从而有效的做到HDFS文件级别的访问控制(ACL)。
(2)数据块的访问控制
一个存储于HDFS上的文件是由落在DataNode上的几个数据块组成的。对于数据块的安全性,业界的解决思路基本是通过令牌的形式,对其访问权限进行控制。当需要访问数据块时,NameNode会根据HDFS的文件许可做出访问控制决策,并发出一个块访问令牌,可以把这个令牌交给DataNode用于块访问请求。这种令牌机制保证对所有对于数据块的访问行为增加了权限控制。
(3)网络加密
网络加密是指在数据的传输过程中,通过SSL在网络传输层进行加密。这种手段主要是用于保证HDFS文件在被浏览器打开浏览、client端下载、API操作、集群间文件数据传输等过程中,数据本身不被窃取。在业界和厂商的解决方案中,更加偏向于通过权限控制和网络加密的方式解决分布式文件系统的安全问题。
通过上述解决方案安全性分析,可以得知业界和厂商提供的解决方案存在以下的几点缺陷:
①无法适用于所有的HDFS版本,只能在特定版本中提供安全保障;
②没有解决数据文件在存储过程中的安全保障;
③无法对文件持续审计。
3 基于分布式存储系统数据安全的解决思路
数据的安全保障,可以抽象为权限控制安全保障,静态数据安全保障,数据审计安全保障。具体来说,权限控制安全保障需要解决数据访问的授权和鉴权;静态数据安全保障需要保证数据文件在存储传输过程中被非法获取后信息不泄露;数据安全审计需要保证能够持续追踪数据的使用情况。
根据上述内容描述,可以得出HDFS系统中的数据存储存在以下三点安全问题:
(1)数据安全过分依赖于Master节点的权限管理
现有的HDFS系统中,所有的数据安全措施只局限于Master节点,也就是说只要通过了权限系统的认证,数据就不存在任何其它安全防护。而由于权限系统是一个简单的user:password系统,容易被攻破,同时本身不具有任何密码的防护,因此单纯依赖权限系统做数据安全防护是存在很多漏洞的。
(2)数据文件本身没有做加密处理
在HDFS系统中,所有的数据文件被切割成多个Block文件,以明文形式存储在各个DataNode机器上,这种存储方式存在极大风险。一旦DataNode所在机器被登录后,攻击者可以绕过中心的权限系统,读取走所有涉密数据文件。
(3)数据文件的访问使用缺乏审计和记录手段
在HDFS系统中,涉密数据文件的访问使用缺乏有效的审计和记录手段,如在某一时段哪个用户读取了这份数据,此类信息不会被记录下来。并且,当数据文件被拷贝到其他集群后,系统更加无法控制数据文件的扩散使用。
基于以上问题,HDFS系统在数据安全的保障上存在设计缺陷,而厂商和业界的提供的解决方案在应用中也存在一些缺陷。本文以AES加密算法为例,使用密码分组链接模式(CBC,Cipher Block Chaining),从基于AES的单文件认证和加密、与分布式计算系统的协同工作、以及涉密文件使用的持续审计三个方面,对HDFS系统的数据安全性进行优化改进。
4 基于AES的文件认证和加密
高级加密标准(Advanced Encryption Standard,AES),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。第4节介绍对单文件级别的文档加密和转换的具体过程和方法。
4.1单文件加密过程
优化的HDFS数据安全架构由HDFS系统、密钥服务器、以及数据转换系统组成。对于存储在HDFS系统中的文件,我们会对数据文件进行加密处理,如图3所示,具体流程如下:
(1)将数据文件写入到HDFS系统;
(2)将数据文件写入消息即时通知数据转换系统;
(3)数据转换系统生成一个和该写入文件相关的令牌Token,并将其发送给密钥服务器。Token本身具有时效性,如24小时或1个月;
(4)密钥服务器使用Token生成一个相对应的密钥,并将密钥返回给数据转换系统。这个密钥就是对数据文件进行加密时使用的密钥;
(5)获取加密密钥后,数据转换系统向HDFS系统发出申请并读取数据文件;
(6)数据转换系统对明文存储的数据文件进行数据格式及加密转换;
(7)文档转换完成后,加密后的数据文件被回填到HDFS系统上;
(8)HDFS系统使用加密后的数据文件替换原有的数据文件,完成数据加密过程。
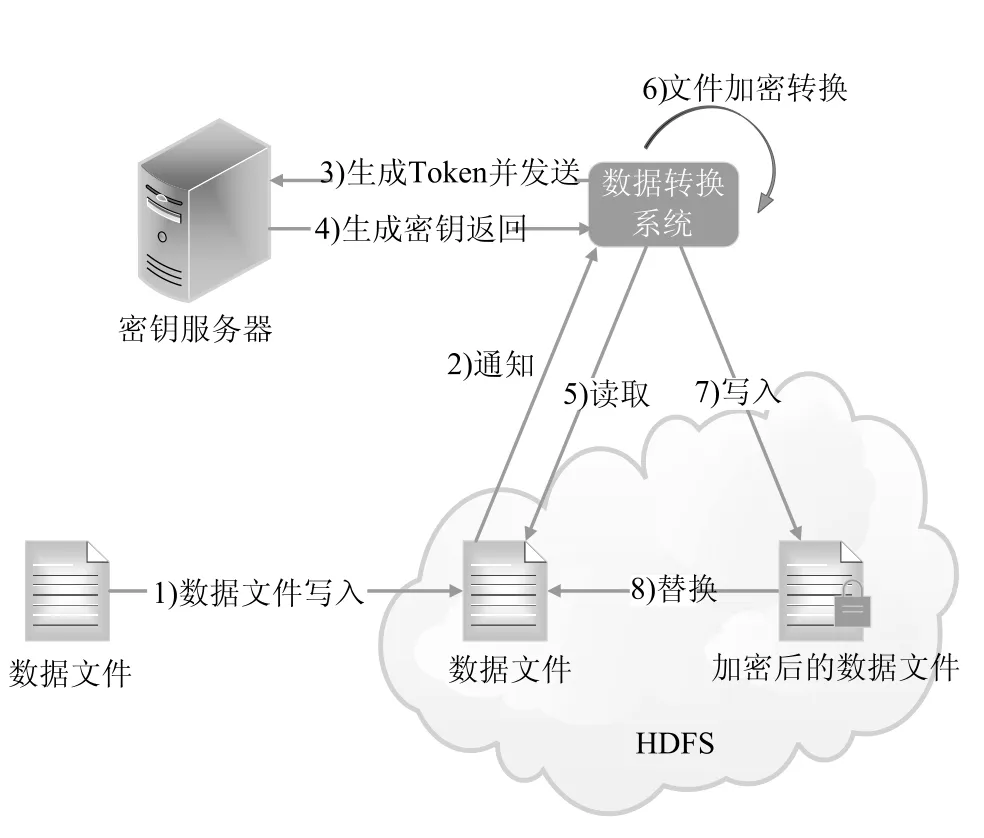
图3 优化的HDFS数据安全架构图
在整体的数据加密过程中,除原有的HDFS系统外,以上方案引入了数据转换系统和密钥服务器两个组件。这两个组件均为轻量级的外挂组件,不会显著增加原有HDFS系统的复杂性,其中:
(1)密钥服务器用于存储文件所涉及到的密钥记录,每个加密文件对应一个密钥记录,包含用户信息,token信息,文件信息,有效期信息,权限信息,AES密钥信息。在实现上该密钥服务器为一台部署了数据库服务(如mysql)的机器。密钥服务器的安全性由机器密码,数据库密码,网络访问限制(白名单)来共同保证。具体的数据格式参见第4.2节。
(2)数据转换系统用于将非加密文件格式转换为加密格式,加密格式和过程参见第4.2和4.3节。
4.2文件加密格式
在密钥服务器上,每一个文件在加密后都会存储以下形式的一条记录。

User Token Dataset(File/path)Deadline Chmod AESKEY
每个字段的具体含义如下:
(1)User:文件所属的用户;
(2)Token:Token会返回给用户,用户使用Token来获取解密后的数据文件;
(3)Dateset:加密文件或路径;
(4)Deadline:Token的生存周期,也就是说超过Deadline后,整个Token就失效,用户必须重新申请Token;
(5)Chmod:对于该文件的操作权限;
(6)AESKEY:AES加密密钥;
在用户对文件的访问过程中,文件的解密权限完全由密钥服务器控制。用户申请获取某一个文件的操作Token,在Token有效期内具有对该文件的解密和读写等操作权限。未获取权限的用户在HDFS系统上直接看到的文件均为无法直接读取的加密格式。
对于一个具有如下格式的原始数据文件,
<记录行1>< 换行符>
<记录行2>< 换行符>
<记录行3>< 换行符>
…
在经过数据转换系统加密转换后会被转化为以下的数据格式:
<文件元信息><加密后记录行1长度><AES加密后的记录行1><加密后记录行2长度><AES加密后的记录行2><加密后记录行3长度><AES加密后的记录行3>…<结束符>
也就是说原始的数据文件会按行进行切割,并使用AES进行加密,而加密后不再区分文件行,加密文件被糅合到一起存储。这样做的优点在于,数据文件最终会被HDFS系统切割成一个个Block存储,这样假如用户获得了一个Block,即使用户同时拥有AES key,也无法解析出文件片段,只有获取所有Block和密钥才能对文件进行解密操作。
4.3加密模式下的数据访取
在这种加密模式下,密钥服务器成为数据安全架构最重要的核心组件。对于用户而言,要想获取到一个加密文件中的内容需要按以下流程操作:
(1)通过HDFS的权限系统,获取需要的被加密数据文件;
(2)通过预先申请的Token,与密钥服务器通话,进行获取密钥的验证;
(3)在Token验证通过后,从密钥服务器获取到密钥;
(4)在取得密钥后进行文件的逆转换过程;
(5)获取到解密后的文件。
4.4可行性实验
针对上述的数据加密方式,从算法可行性上,我们基于以下实验环境进行了测试实验。
4.4.1实验环境信息
(1)CPU信息:
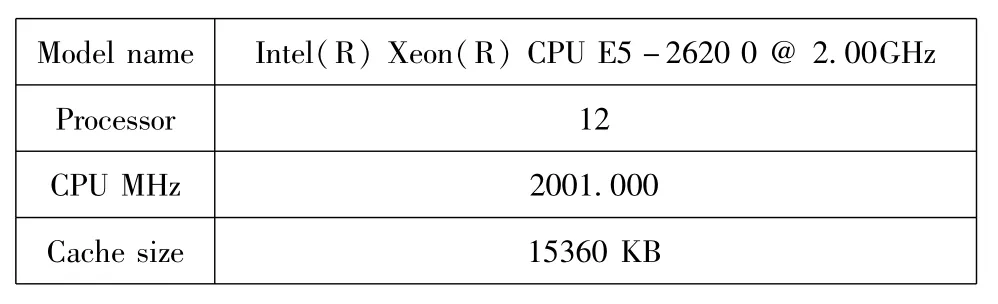
Model name Intel(R)Xeon(R)CPU E5-2620 0@2.00GHz Processor 12 CPU MHz 2001.000 Cache size 15360 KB
(2)操作系统信息:
Red Hat4.4.4-13
(3)内核信息:
2.6.32-1-13-0-0
(4)实验数据:
使用Hadoop自带的randomTextWriter生成,每行数据中均由英文单词拼接构成。
(5)加密算法:AES-128
4.4.2实验过程
(1)单行数据加密效率
假设每个文件中只包含一个数据行,分别设定数据行长度为1 K,10 K,100 K,1 M,10 M,使用第4节中的加密算法对文件进行加密操作,并记录耗时。
实验数据如下:

1 K 10 K 100 K 1 M10 M文件加密耗时(ms)行数据长度98 278 902 3981 38912
从单行数据的加密效率来看,整体上通过这种方式对于数据进行加密,可以满足速度需求的。
(2)多行数据加密效率
假设每个文件中只包含多个数据行,分别设定数据行长度为1 K,10 K,100 K,1 M,10 M,设定文件总大小为64 M,使用第4节中的加密算法对文件进行加密操作,并记录耗时,如图4所示。
实验数据如下:

1 K 10 K 100 K 1 M10 M文件加密耗时(s)行数据长度4 653 1 354 469 199 189
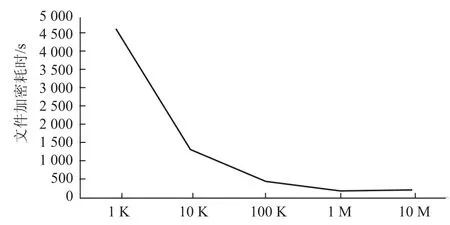
图4 多行数据加密效率图
从实验数据可以看出,在文件级别的加密效率上,对于一个64 M的文件,加密的整体时间会随着文件行记录长度的增大而明显缩小,当文件中行记录大于500 K时,加密耗时会维持在500 s内,当文件中行记录大于1 M时,加密耗时会维持在200 s内。所以从单文件的角度看,加密耗时在可接受范围内。
(3)集群整体加密效率
在大数据处理中,由于存在分布式集群的原因,集群的整体计算能力是充足且廉价的。我们假设有100个节点的Hadoop集群是用于做数据的加密工作。那么按照实验2中的数据进行假设推算,可以得出在集群条件下的整体加密效率,如图5所示。
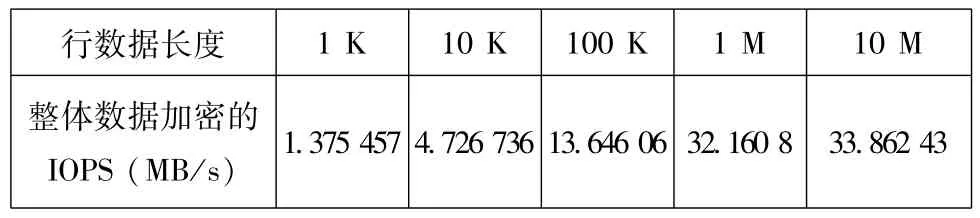
1 K 10 K 100 K 1 M10 M整体数据加密的IOPS(MB/s)行数据长度1.375 457 4.726 736 13.646 06 32.160 8 33.862 43
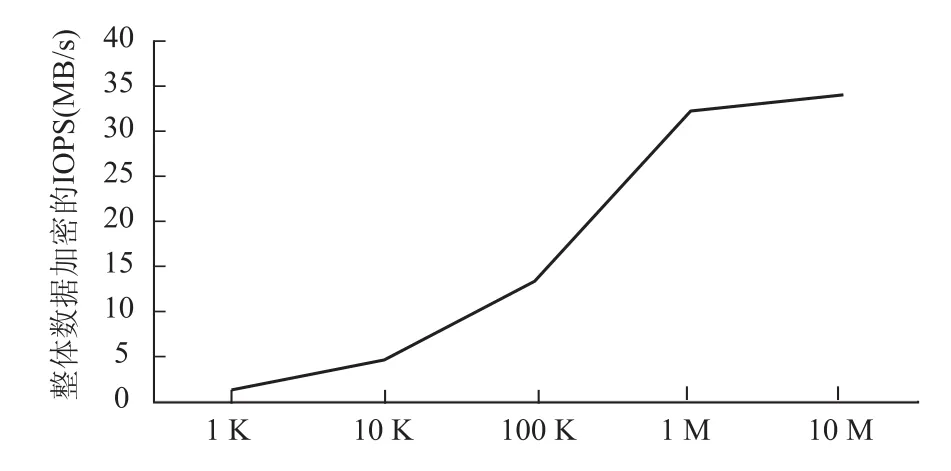
图5 集群整体加密效率图
可以看出在一个100节点的Hadoop集群中,整体的加密效率可以达到30MB/s,整体效率完全可以满足正常的需求。
4.4.3实验结论
从上述的测试实验中可以看出,在分布式计算中,计算能力是充足且廉价的。通过牺牲计算能力,用于数据文件加密,获取更高的数据安全性是可行的。
由于加密过程和数据访取过程是针对单文件级别进行的,因此在HDFS系统中的数据可以选择是否进行加密,也就是说对于部分有加密需求的数据可以通过上述方式加密管理,对于一些非重要数据也可以选择不加密,仍以原文件格式存储。
5 与分布式计算系统的协同工作
通过第3节的描述可知,我们在文件级别进行了数据的加密工作,并通过密钥服务器和数据转换系统提升了HDFS的安全级别,然而这一过程也加大了数据获取的难度和复杂度。HDFS上层更多的支持了分布式计算系统,因此数据加密本身同时需要考虑和分布式计算系统间的协同工作。
在分布式计算系统中,读写HDFS主要是通过ImportFormat和OutputFormat类来操作,所以我们通过实现一个特殊的AesInputFormat和AesOutputFormat类来实现和分布式计算系统的协同工作。具体来说,这部分需要实现两个功能:首先,用户在计算作业中传入合适的Token时,经过加密的数据能够被解密和读出;其次,解密后的数据能够直接提供给计算程序使用。这两个功能可以通过实现AesInputFormat、AesOutputFormat、AesRecordReader、及AesRecordWriter四个类来完成。
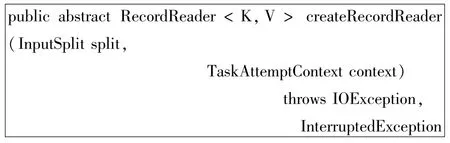
(1)AesInputFormat类
实现createRecordReader方法,根据文件后缀,决定返回LineRecordReader还是AesRecordReader对象。
(2)AesRecordReader类
实现initialize方法,根据aes.token和split.toString(),判断用哪个token去获取密钥,在和密钥服务器交互之后,获取密钥后写入jobconf。

实现nextKeyValue()、getCurrentKey()、getCurrentValue()三个方法,获取用AES流解密后的记录。

(3)AesOutputFormat类
重载构造函数,在密钥服务器上增加output文件的加密记录,用于追踪文件流转情况,records记录为<token:input-output>。

实现getRecordReader方法,返回AesRecord-Writer对象。

(4)AesRecordWriter类
实现write方法,以AES加密的形式写出数据,key和value单独加密。

通过实现AesInputFormat、AesOutputFormat、AesRecordReader、及AesRecordWriter四个类,使得用户在分布式计算作业中可以直接使用加密后的数据文件。
6 涉密文件使用的持续审计
在涉密文件的管理中还有一个比较重要的部分就是审计,具体来说就是能够持续检测到文件在什么时候被谁访问,以及在文件被复制到其他集群后仍然可以被持续监控和记录。这些记录文件需要最终被整理收集,用于涉密文件的持续审计。
如前面两节所述,所有的加密后的数据文件在被读取操作时,均需要通过Token与密钥服务器联系获取到AES密钥,在这种模式下,可以在密钥服务器上记录这些访取日志来做持续的数据使用审计工作。记录信息如下:
(4)Date:操作的时间。
通过这种方式可以比较好的实现数据访取记录的审计工作。
7 结 语
本研究以HDFS系统为例,通过讨论分布式存储系统的整体架构、文件存储形式、身份识别机制等要点,分析得出HDFS系统在数据安全保障上存在的安全性问题。并针对已知安全问题,提出了一种有效的基于分布式存储系统的数据安全保障方案。方案以分组密码AES为例,从基于AES的单文件认证和加密,与分布式计算系统的协同工作,涉密文件使用的持续审计等方面,对HDFS系统的数据安全性做出了优化改进。
[1] 郝树魁.Hadoop HDFS和MapReduce架构浅析[J].邮电设计技术,2012,07:37-42.
[2] MICHAEL Armbrust,ARMANDO Fox.Above the Clouds:A Berkeley View of Cloud Computing[R].California:Electrical Engineering and Computer Sciences,2009.
[3] 仇李寅,邱卫东,苏芊,等.基于Hadoop的分布式哈希算法实现[J].信息安全与通信保密,2011,11:54-56.
[4] WHITE Tom.Hadoop:The Definitive Guide[M].California:O’Reilly,2009.
[5] JIMMY Lin,CHRISDyer.Data-Intensive Text Processing with MapReduce[M].Maryland:Human Language Technologies,2010.
[6] Hadoop.HDFS权限管理用户指南. http://hadoop.apache.org/docs/r1.0.4/cn/hdfs-permissions-guide.htm l,2013.

各个字段对应的含义如下:
(1)Token:操作数据集使用的Token;
(2)SrcDataSet:操作的数据集;
(3)Action:具体的操作;
Data Authentication and Security Assurance Based on Distributed Storage System
WANG Dan-hui
(China Academy of Electronics and Information Technology,Beijing 100041,China)
In the general distributed storage systems,lack of data securitymeasures is a serious problem. Due to the high demand of data security,it′s difficult to dealwith security issues in Cloud storage by the distributed storage systems.An Effective data security scheme based on distributed storage system is proposed,in which the AES encryption mechanism is used in document storage.The File encryption format in this scheme can be combined seam lessly with distributed computing system.This scheme also proposes an Authorization mode based on confidential data,and the data will bemonitored continuously.
distributed;storage;data security;HDFS
TP309
:A
:1673-5692(2015)06-613-07

10.3969/j.issn.1673-5692.2015.06.010
2015-09-07
2015-10-30
王丹辉(1984—),山东济南人,工程师,博士,主要研究方向为信息安全和数据服务;
E-mail:wangdanhui2014@163.com
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:17:56
北京电子科技学院学报(2020年2期)2020-11-20 01:44:06
电子制作(2019年14期)2019-08-20 05:43:42
当代贵州(2018年21期)2018-08-29 00:47:20
网络安全和信息化(2018年9期)2018-03-03 18:11:15
信息安全研究(2018年1期)2018-02-07 01:44:46
信息安全研究(2018年1期)2018-02-07 01:44:43
网络安全和信息化(2017年12期)2017-11-08 10:39:14
电信科学(2017年6期)2017-07-01 15:45:06
电子制作(2017年20期)2017-04-26 06:57:48
