
基于统一表格的软件产品线可变性建模
2015-06-23 16:27胡月莹陈立潮潘理虎
太原科技大学学报 2015年2期
胡月莹,陈立潮,潘理虎,2
(1.太原科技大学计算机科学与技术学院,太原 030024; 2.中国科学院地理科学与资源研究所,北京 100101)
基于统一表格的软件产品线可变性建模
胡月莹1,陈立潮1,潘理虎1,2
(1.太原科技大学计算机科学与技术学院,太原 030024; 2.中国科学院地理科学与资源研究所,北京 100101)
软件产品线是在某一固定领域中用于软件重用的一种方法,其最重要的步骤是可变性建模,但随着变量的不断增多模型中的依赖关系会变的十分复杂,因此针对模型中依赖复杂性问题提出了一个分离模型来处理这些变量的依赖关系,即统一表格方法,建立了采煤工作面的统一表格,同时使用表中的子域列描述特定产品变量的前置条件,可以有效的解决变量之间依赖性复杂的问题,还有利于领域模型中变量的追踪。实验结果表明,与其他模型相比较,统一表格方法可以有效的解决变量依赖的复杂性问题。
软件产品线;统一表格方法;变量;特征模型
软件产品线可以提高软件的开发速度和质量,是一种软件复用的开发方法[1]。软件产品线首先要建立变化模型来记录软件家族成员产品的共性和可变性,然后派生产品,根据产品需求从模型中选择需要的变量和配置来派生产品[2]。
所有家族成员中的公共需求比较容易处理,因为家族成员的一部分,但在处理可变需求时,就会出现许多问题。在产品线模型中,一个相同的变量会出现在不同的领域模型视图中,且不同变量之间会有依赖关系。在不同的模型视图中需要追踪变量并说明这些无法达到定制产品的目的,无法建立清晰的领域模型。因此需要一个分离的模型来处理这些变量之间的依赖关系。
文中基于统一表格方法进行可变性建模[3],该模型包含变量所有的相关信息(如规格、变量依赖性、变量起源等)。统一表格由变量以及它们之间的关系组成,表格的方式可以缓解变量冲突的问题,有利于领域模型中变量的追踪,使变量之间的依赖关系变得清晰。本文以采煤工作面模拟量监控系统为例来分析和建立其相关模型。
1 采煤工作面模拟量监控概况
采煤工作面必须要监控的模拟量包括瓦斯浓度、一氧化碳浓度、风压、风速、温度等,煤矿安全监控系统分为井下设备、传输和井上管理三层[4],系统设备间的连接图如图1所示,其中第一层包括分站、执行器和传感器;第二层即传输网络;第三层包括网络系统和地面中心站。
工作面模拟量监控的基本操作过程为:
(1)采集信号:在采煤工作面中,传感器用于采集模拟量、显示监测值、超限报警并将监测数据传送给分站。
(2)控制过程:监控主机向井下各分站发送控制和分站巡检信号,当各模拟量的浓度超限时,分站会控制井下不同的设备报警、断电和复电。
(3)存储、显示过程:监控主机会不间断的接收来自分站的各模拟量信号,然后存盘,并显示大屏幕、显示器、模拟盘上。该过程中关键实体如表1所示。

图1 设备间的连接图Fig.1 The connection diagram among devices
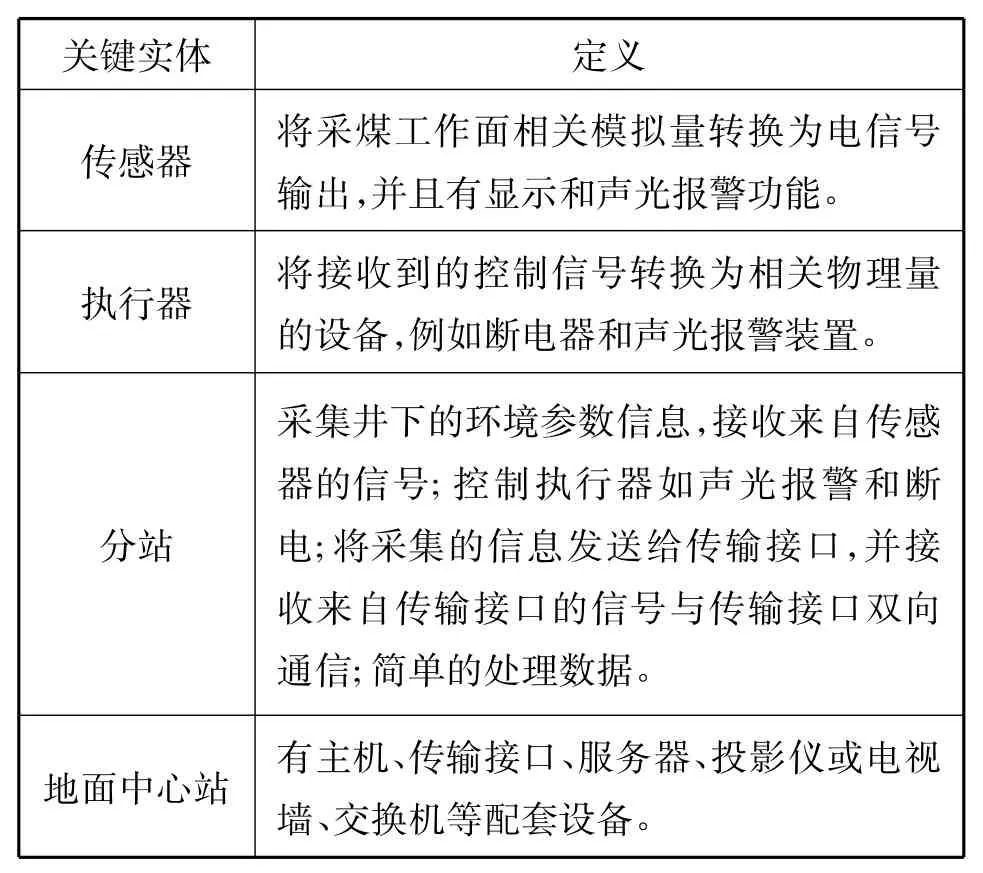
表1 采煤工作面环境参数监控领域的关键实体Tab.1 key entities of environment parameters monitoring in the field of coal mining working place
在基本的操作层面上,所有的采煤工作面环境监控过程是相同的,然而对于不同的采煤工作面,由于环境的不同,所需要采集的数据、数据的属性和处理不同,因此会有许多变量。以下为数据采集过程的变量:
各模拟量设置地点,即各传感器的设置地点。由于不同采煤工作面的地理条件不同,各传感器的类别、设置地点、报警、断电与复电浓度会发生变化。例如,所有的采煤工作面都需要对工作面、工作面回风巷和上隅角设置瓦斯传感器,但在专用排瓦斯巷要多设置高浓度的瓦斯传感器。并非所有的采煤工作面都需要CO的监控,只有在容易自燃的矿井中设置CO传感器[4]。其他的环境参数也有这样的变化特点。
报警方式:当模拟量监测值超限时,蜂鸣器(有的是报警喇叭)会发出警报,有时也会向有关人员手机发送信号。
2 特征模型
软件产品线需求建模最常用的是特征模型,特征模型首先要识别领域特征,因此从两方面进行定义特征是首要问题[5]:
(1)特征的内涵角度。特征是系统需求的概念化,将系统的需求分割为一组需求子集。
(2)特征的外延角度。特征是软件系统具有的一种显著的或具有区分作用的、且用户可见的特点[2]。
特征模型是以树的方式表示。特征树的内部结点表示特征,叶子代表特征值,根结点代表需要建模的领域[6]。特征与其父特征之间存在精化关系,通过精化关系使特征形成树形结构。引用基数的概念表示特征之间存在的约束关系[7-8]:
(1)特征基数是指当父特征被系统绑定后,其某个子特征被绑定的范围。强制特征是系统必须要绑定的特征,可选特征是系统可能被绑定的特征。强制特征和可选特征是特殊的带有基数的特征,其基数分别为[1..1],[0..1].
(2)组基数是指特征和它的一组子特征之间关系,即当父特征被绑定时,它的子特征组被绑定的范围。例如<1..3>.对于一组特征,这里多选多和多选一是组基数的特殊情况:对于多选一约束关系的组基数是<1..1>;对于多选多约束关系的组基数是<1..*>.
特征之间的关联关系常被划分为依赖和互斥。依赖关系是指只有在一个特征最后被确定后,其相关的依赖特征才能被确定;互斥关系是指两个特征中只有一个特征处于被绑定状态[9]。采煤工作面模拟量监控的特征树如图2所示。其中强制特征有数据采集、控制等,调节为可选特征,并非所有的系统都需要该功能。传感器与瓦斯传感器是特征基数的关系,传感器设置地点与各地点是组基数的关系。传感器与报警时依赖关系,断电与复电是互斥关系。

图2 数据采集的特征树Fig.2 The characteristics tree of data acquisition
3 统一表格方法
软件产品线中的变量之间关系紧密。产品线的任意产品都可以从产品线的通用模型中定制。在定制过程中,必须先从变量列表中选择所需的变量。在选择变量时会需要查询,当变量很多时,查询会变得困难。可能出现的查询有:
有些变量会被产品线中所有的产品使用,而有些变量和值只适用于某些特定产品。
变量可能会有先决条件和后置条件,随着变量的增加,变量之间的依赖性会变的太过于复杂,而无法表示。
新信息增加、删除或修改时,会影响其他变量,所以需要一个简单的方法来处理这个问题。
这些情况可以使用特征模型表示,但需要额外的注释,而这些注释会变得复杂、难以处理。使用统一表格方法可以描述特征模型的所有信息,有助于在应用工程阶段筛选变量。采煤工作面模拟量数据采集的表格如表2所示(传感器是指所有的模拟量相关的传感器)。给出了数据采集过程中主要变量(类型)、值(类型)、子域、值关系以及依赖关系。

表2 数据采集的统一表格Tab.2 The unity of data acquisition
3.1 表结构
统一表格包含特征模型中的所有可用信息,主要有:
(1)“变量(类型)”,变量名称。变量编号显示了它所在的层次和位置。例如,本表格描述的案例将数据采集作为根,“模拟量采集”是一个变量,它位于变量列表,用v.2表示,“(类型)”表示变量的类型,一个变量要么是强制的,要么是可选的。v.2是一个强制变量。
(2)“变量值”,变量的值或选择。其编号也是显示了它所在的层次和位置,变量编号与变量值编号保持一致以便跟踪其依赖性。如“传感器”使用v.2.2编号。
(3)“子域”列表示变量特定值适用的产品区域。如果变量存在于所有产品中,那么“所有”将显。
(4)在列表中,否则将显示适用区域的名称。由于某些变量和它们的值只适用于某些产品,所以该列能够更快捷的指导筛选过程。如v.2.1.2只有在工作面里存在瓦斯积聚时选用。
(5)“值间关系”,变量各值间的关系。存在两种关系:
①基于特征基数的关系,用[m..n]表示,如传感器与瓦斯传感器之间是[1*]关系。
②基于组基数的关系,用<ab>表示,如传感器设置点与地点组之间是<4—*>关系,表明至少有四个地点需要设置传感器。其中“多选一”是特殊的“基于组基数的关系”,对应于组基数用<1—1>,例如“报警喇叭”和“蜂鸣器”就是多选一关系。
(6)“依赖关系”列表示变量之间是否有依赖或互斥关系。“依赖”例如v.3只有在v.2.1存在情况下才会被选择。“互斥”表中并没有表示出来,但在特征模型中经常存在这样的依赖关系,用!v.n表示。依赖关系的扩展类型如表3.

表3 变量依赖的扩展类型Tab.3 the extension of the type
3.2 与特征模型相比
统一方法也像其他方法那样可以显示所有变量信息及其性质。它克服了在特征图中变量建模的依赖复杂性问题,本文利用采煤工作面模拟量监控系统的特征图(图2)和其对应的统一表格(表2)的对比来说明这一点。当某些变量依赖于其他变量时,它的信息修改或可视化呈现将影响所有依赖变量和它们的值。由于特征图以图表形式表示变量,有时它便于一目了然地检查总体功能。但在一个领域中,存在许多变量并且每个变量都有值以及依赖关系,把所有的变量及其信息都集中在一个特征图中只能使其变得难以处理。例如两个强制变量“传感器设置地点”和“传感器”之间的依赖关系。
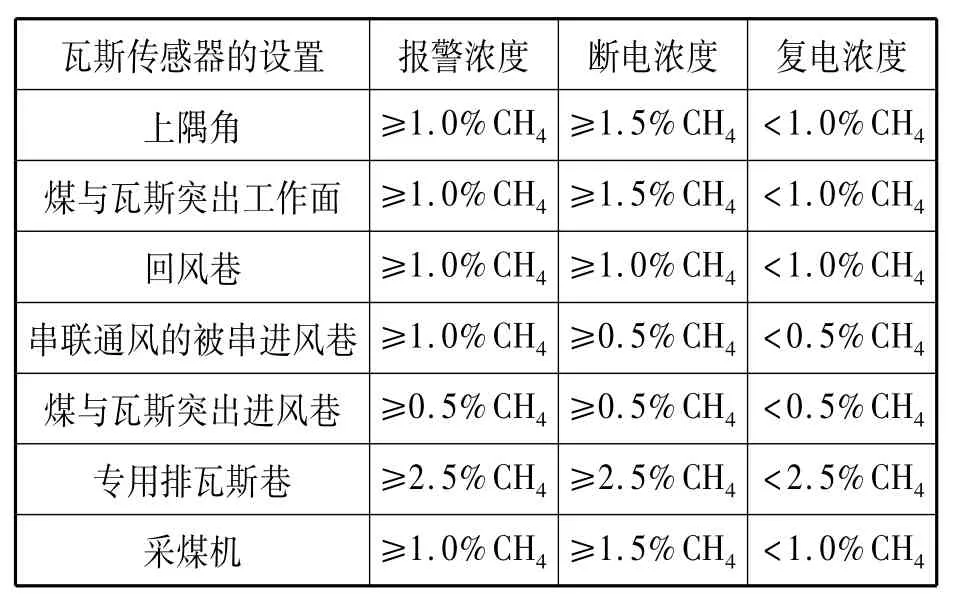
表4 采煤工作面瓦斯传感器报警、断电和复电浓度Tab.4 The concentration of alarm,power outage and reply about gas sensor in coal mining working place
如表4所示,甲烷断电浓度、报警浓度和复电浓度由于其设置的采煤工作面的地理环境的不同而不同,也就是图2中每个瓦斯传感器的报警点、断电点和复电点都依赖于传感器的安装点。像这样所有变量及其依赖关系在一个特征图表示,它将变得非常复杂和难以处理。因为在特征图中修改任意一个变量的值将影响所有依赖变量的值。在表格中只需更新或添加相应变量的特定行,使用表格方式可以便捷的修改或添加任意变量。在表格中,所有的变量相对应的信息都用不同列清楚地分割开来,检索任意特定行都能方便地找到变量的相关属性。
在特征图中,可注释指示变量的适用领域,但对所有变量都作这种注释只会使功能图变得复杂。统一表格的“子域”列详细的对适用领域进行了描述,从而使这一问题得到解决。事实上,特征图由于没有合理的尺寸而逐渐变得更复杂和难以管理。因此使用文本语言定义特征模型和特征图共同显示一组选择特征间的关系比单独使用特征图更有效果。
因此统一表格方法与特征模型相比的优势在于:①易用性。当所有可能的家族变量可用时,变量模型很容易掌握变量相关信息。而当任何新的变量出现时,它不需要干预其他变量就可以出现在模型中。同样的,不需要的变量可用从模型中删除。②可追溯性。开发变量模型后,定位任意变量及其依赖信息就变得简单了,无需搜索模型中每个可能的条目,只需查找相关表条目即可。③可伸缩性。在应用工程中,为了所需产品,很可能从整个变量模型中提取更小的模型。④支持分离问题。本文提出的变量模型支持领域模型在定制过程中实现问题分离。
4 结束语
软件产品线的成功发展需要适当的组织和管理产品需求,管理变量是产品线的关键成功因素。本文提出了建模产品线变量的统一表格方法,为生产任意领域模型的定制产品提供了所有变量的相关信息。本文分析了领域模型中建模变量的现有方法,发现其中一些有用变量相关信息的表示存在不足之处,然后提出在建模变量时使用统一表格方法。它还包括领域模型中产品定制需要的信息,而这些信息很难通过其他方法呈现。表格模型的优点是它的表达能力和易用性,对建模变量工程中提高变量处理效率很有益处,它是定制过程简便,同时也降低了因变量增加而产生的复杂性。但是该方法的相关管理工具还有待进一步的研究。
[1]聂坤明,张莉.基于模型对比和组合的软件产品线领域需求建模[J].计算机学报,2014(3):539-550.
[2]李弈远(朱理).基于特征的软件产品线开发关键技术研究[D].浙江大学,2007.
[3]SHAMIM H Ripon.A unified tabular method for modeling variants of software product line[J].ACM SIGSOFT Software Engineering Notes,2012,37(3):1-7.
[4]张国晨,郭银章,曾建潮.适用于煤炭采掘业ERP系统的业务模型设计与研究[J].太原科技大学学报,2006,27(5): 331-335.
[5]WEI ZHANG,HONG MEI,HAIYAN ZHAO.Feature-driven requirement dependency analysis and high-level software design[J].Requirements Engineer,2006(11):205-220.
[6]DAVID BENAVIDES,SERGIO SEGURA,ANTONIO RUIZ CORTÉS.Automated analysis of feature models 20 years later:A literature review.[J].Information System,2010(35):615-636.
[7]KRZYSZTOF CZARNECKI,SIMON HELSEN,ULRICH EISENECKER.Formalizing cardinality-based feature models and their specialization[J].Software Process Improve Practice,2005(10):7-29.
[8]STEVEN SHE,UWE RYSSEL,NELE ANDERSEN,et al.Efficient synthesis of feature models[J].Information and Software Technology,2014.
[9]张伟,梅宏.面向特征的软件复用技术——发展与现状[J].科学通报,2014(59):21-42.
Variability Modelling Based on Software Product Line of the United Form Method
HU Yue-ying1,CHEN Li-chao1,PAN Li-hu1,2
(1.Taiyuan University of Science and Technology,Taiyuan 030024,China;2.Institute of Geographic Sciences and Natural Resources Research,Chinese Academy of Science,Beijing 100101,China)
It is a systematic way to realize the reuse of software for specific areas to set up software product lines.The variability modeling is the key technology in software product line,but the dependence among variables in the model become complicated with the increase of information.Therefore,a separate model is needed to deal with these variables.In this paper,the unified form is presented to manage variables in the product line,and the child domain column in the table is used to describe the precondition of specific product variables,which not only can effectively solve the problem,but also track variables in the model.
software product line,unified tabular method,modeling variants,feature model
TP311.5
A
10.3969/j.issn.1673-2057.2015.02.004
1673-2057(2015)02-0097-06
2014-11-06
“十二五”山西科技重大专项项目(20121101001)
胡月莹(1987-),女,硕士研究生,主要研究方向为软件体系结构;通讯作者:陈立潮,教授,E-mail:Chen_lc@ 263.net
猜你喜欢
现代临床医学(2022年1期)2022-02-12
四川劳动保障(2021年9期)2022-01-18
文化创新比较研究(2020年13期)2020-01-01
无锡职业技术学院学报(2019年4期)2019-12-27
文萃报·周五版(2019年13期)2019-09-10
铁道通信信号(2018年12期)2019-01-31
小学生必读(中年级版)(2018年6期)2018-09-05
高中时代(2017年7期)2018-02-24
电子制作(2016年21期)2016-05-17
中国医药科学(2013年16期)2013-12-20
