
基于大数据平台hadoop的聚类算法K值优化研究
2015-06-23 16:27武霞董增寿孟晓燕
太原科技大学学报 2015年2期
武霞,董增寿,孟晓燕
(太原科技大学电子信息工程学院,太原市 030024)
基于大数据平台hadoop的聚类算法K值优化研究
武霞,董增寿,孟晓燕
(太原科技大学电子信息工程学院,太原市 030024)
针对最大最小值原则的Kmeans聚类算法运行在Hadoop平台时需要多次遍历所有数据的问题,提出了一种改进的初始聚类中心的选择算法称为M+Kmeans算法。该算法只需要遍历一次全局数据极大的缩减了算法并行运算时消耗的时间。多组实验测试结果显示,设计的M+Kmeans算法适合运行在大规模集群Hadoop平台上,并且加速比和扩展率较原始算法有明显提高。
聚类;大数据;Hadoop;Kmeans
聚类分析是数据挖掘领域的一个热门的研究分支。聚类思想就是数据归类:“相似同类,相异不同”[1]。K-means算法是聚类分析中经典的算法。算法计算收敛速度快,易于实现但是思想却不简单,于是受到广泛的研究和使用。算法本身存在缺陷,因为聚类之前对要求划分的类是未知的,因此需要人为的事先确定聚类数目即K的值,还要事先确定种子中心点,这样使聚类的结果会产生局部最优解,而且不正确的K值设定也会对最终数据产生很大的影响。例如数据本该分为4类,而却被人为的分成了3类,这样本身就是不恰当的。在K值的选取上面,已有不少前人做了研究,如canopykmeans算法、最大最小值算法等都是针对K值的选取提出和优化的。但是canopy的划分是粗略的,容易重复覆盖。最大最小值算法在计算K值时要重复的遍历数据,造成时间浪费。本文针对最大最小值算法的不足,根据“最大值原则”提出了改进的算法在中心点选取和K值的确定方面进行优化,这里称改进后的算法为M+Kmeans算法,并且将M+ Kmeans算法运用到Hadoop大数据平台上。
目前国外大数据的理论已经趋于成熟,企业已经将成熟的框架方案运用在商业上[2]。自从Google提出云计算的概念以来,很多企业都已经陆续拥有了属于自己特色的云产品。例如微软、苹果、Facebook先后建立了自己的云平台;SUN、HP、Intel、yahoo等公司也开启了云计算之旅[3]。在国内,大数据云计算作为新兴的产业,由于发展较晚,目前在理论及应用方面相对不成熟,正处于积极探索和研究阶段,主要集中在试商用阶段和学术层面。当然国内一些大的企业也已经尝试对大数据应用研究探索。中国移动率先搭建了云平台“Blue-Carrier”,并在此基础上完成了PEMiner数据挖掘平台的架构。另外淘宝、中国电信、华为等多家大型企业也在着手开发自己的云产品。
Hadoop大数据平台是Apache开发的开源的计算机集群分布式实现框架。Hadoop的一个关键组成部分是HDFS——分布式文件系统(Hadoop Distributed File System)[4]。HDFS是用于存储输入和输出数据的应用程序,有高容错性和高传输率的特点[5]。
1 改进的M+K-means算法
1.1 “最大最小值原则”的K-means算法介绍
最大最小值原则的基本原理是首先随机选取一个种子点作为中心点A,然后计算集合C中剩余点到A点的距离,选取距离最大的点作为第二个种子点B,再计算C中剩余点到这两个种子点的距离,得出到两个中心距离最小的点min(dA,dB),找到该距离的最大值max(min(dA,dB)),迭代条件若满足:

其中dA、dB表示点到A、B点的距离,若满足则点为第三个种子点,按照此方法一直迭代直到无法满足条件,于是种子点就全部得出,并且得到了K的值。但此法有一个缺陷就是每确定一个种子点就要遍历一遍集合中所有的数据,如果数据量大的话,无疑更是灾难性的时间浪费[6]。
1.2 M+K-means算法的思想介绍
M+K-means算法是基于最大值原则在K参数的选取上进行优化的K-means聚类算法,算法思想为:首先任意选取一个点A作为种子中心点。然后遍历一次数据,计算出集合C中剩余点到种子点的距离值,将得到的点和距离dn,dn-1d1存入数组中,设d1到dn为从小到大的距离。选取距离最大的点即dn处作为第二个种子中心点B,接下来选择距离A为dn-1处的点(可不为1),并计算其与B距离DistB,若DistB大于dn-1则设为种子点C,否则为普通点。迭代条件为:
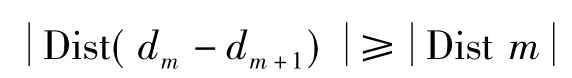
依次选取距离A为distm的点,若这点与dist (m+1)的所有点的距离都不小于distm,则这点设为新种子中心点,否则为普通点。这样可以选择出A点各个方向上的最大值点,防止漏选。这样便可得出初始的种子中心点和K的值。接下来再进行传统的聚类即可,这样可以省掉每次遍历数据浪费的时间。
其基本步骤描述如下:
a)聚类中心A1的选择:从数据集合D中任意选取一个点作为种子中心A1.
b)计算剩余点到A1点的距离,在集合D中选取离A1距离值最大的点标记为第二个中心点A2,设dn为此处最大距离,设点为dn点。
c)并行选取数组中dm-1的所有点,计算与dm所有点的距离,若满足距离不小于dm-1则标记为种子中心点。
d)若点不满足设置的条件则设为普通点。
e)重复步骤c和d,直到无法满足条件就结束,得出符合条件的中心点。
f)邻近类中心合并。
g)将得到的K值和聚类中心点赋予经典的K-means算法,接下来就是传统的算法计算过程。
此时改进的算法在寻找中心点和确定K值是只需要遍历一次集合中的数据,大大节省了数据挖掘的时间。
2 M+K-means算法
2.1 M+K-means算法的并行实现
MapReduce模型是谷歌公司开发的用抽象的Map和Reduce函数的分布式编程框架,执行并行计算[7]。本文在Hadoop平台实现M+K-means算法的MapReduce并行化。将分为两个MapReduce阶段,具体框架图如下:
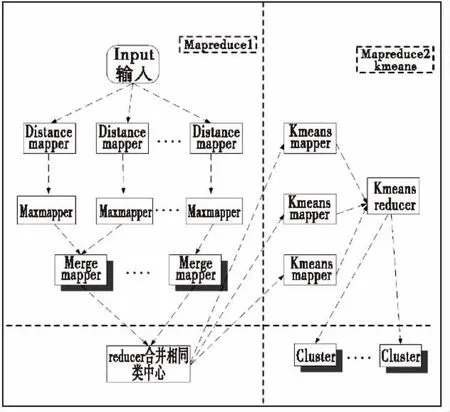
图1 M+K-means算法的mapreduce流程图Fig.1 Mapreduce flow chart of M+Kmeans algorithm
算法的第一个步骤是初始K值的选择,由两个Map和一个Reduce来实现。这里设计两个Mapper过程和一个Reduce过程,可以缩短shuffle阶段的时间和reduce阶段节点间的数据拉取过程所需的时间[8]。其中第一个Map过程主要负责找出随机中心点,遍历数据,计算出剩余点和中心点间距离。接下来第二个Map过程负责计算dn-2的点与所有dn-1的点的距离,执行循环,直到得出M个种子中心,传输给Reduce。Reduce部分得到的结果是来自不同的独立Map的结果,所以有可能种子中心点是相邻的,所以Reduce过程负责将邻近的聚类中心合并[9]。
第二个阶段是由一个MapReduce过程来完成。将第一个阶段产生的初始聚类中心K值赋予传统K-means算法,算法重复计算每个簇的质心直到收敛。聚类过程就完成了。Map过程主要利用欧氏距离对原数据集合中的所有对象进行划分。Reduce过程负责计算并更新各个簇中新的聚类中心,并予以输出,方便其作为下一次迭代的输入,直到聚类中心不再发生变化算法结束。由于初始聚类中心的选择是通过优化算法得到的,不再是人为设置的,这样第二阶段的MapReduce过程能较快的结束迭代,算法能够较快的收敛。
对于改进后的算法整体来说,一方面减少了遍历数据的次数,大大提高了执行速度;另一方面由于聚类中心是由算法执行得到的,而且无需事先人为设定聚类数目,减少了主观因素对聚类结果的影响。
2.2 M+K-means算法的复杂度
传统的K-means聚类的复杂计算程度为O (dkt),其中d为文献数量,k为类的数量,t为迭代次数[10]。这里设原始数据规模为D,计算并行程度为m.所以map过程所用的时间为:
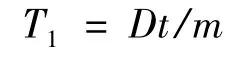
Reduce阶段合并x个聚类种子中心所用时间:
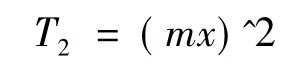
接下来的mapreduce过程为传统K-means计算,所需时间为:
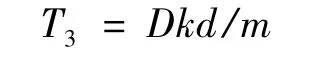
因为x的值非常小,远远小于D,所以算法的复杂计算程度为O(Dkd/m).
3 实验结果及分析
3.1 Hadoop平台搭建
实验环境配置,Hadoop集群一共有5台机器,并将一台设为Jobtracker.每台机器内存4 G,硬盘空间460 G,CPU为2.70 Ghz,双核,操作系统是WindowXP,每台机子安装了Cygwin虚拟机模拟Linux环境,安装eclipse3.3.2运行Hadoop0.20.2,java版本1.6.0_43.配置Hadoop为完全分布模式,根据集群拓扑结构和IP地址对Hadoop的conf下的core-site.xml,hdfs-site.xml,mapred.site.xml和mapred-queues.xml等文件进行配置。在Cygwin中格式化namenode,start-all.sh指令启动Hadoop.在eclipse中创建MapReduce工程,将文件导入HDFS.
3.2 实验结果分析
为了检验算法的可行性和有效性,分别计算优化后的算法和传统最大最小值原则K-means算法的并行时间开销。测试了M+K-means算法的扩展率和加速比。做5次实验取结果的平均值制图。图2为两个算法处理的时间消耗,图3为加速比,图4为扩展率。
在时间消耗的测试上,我们选择了4种类别的数据,分别测试了处理1维、2维和4维数据的时间。从图2可以看出,在数据是1维时,两个算法运行时间相当,是因为1维数据处理比较简单,两种算法对1维数据迭代次数差不多。但运行2维和4维数据时,数据运算量增大,原始的最大最小原则在寻找初始中心点时需要遍历所有数据并且迭代次数也有所增加。而设计的M+kmeans算法在寻找初始中心点时只需要遍历一次所有数据和简单的迭代。所以设计的算法在处理n维数据的运行时间上优于最大最小值Kmeans算法。
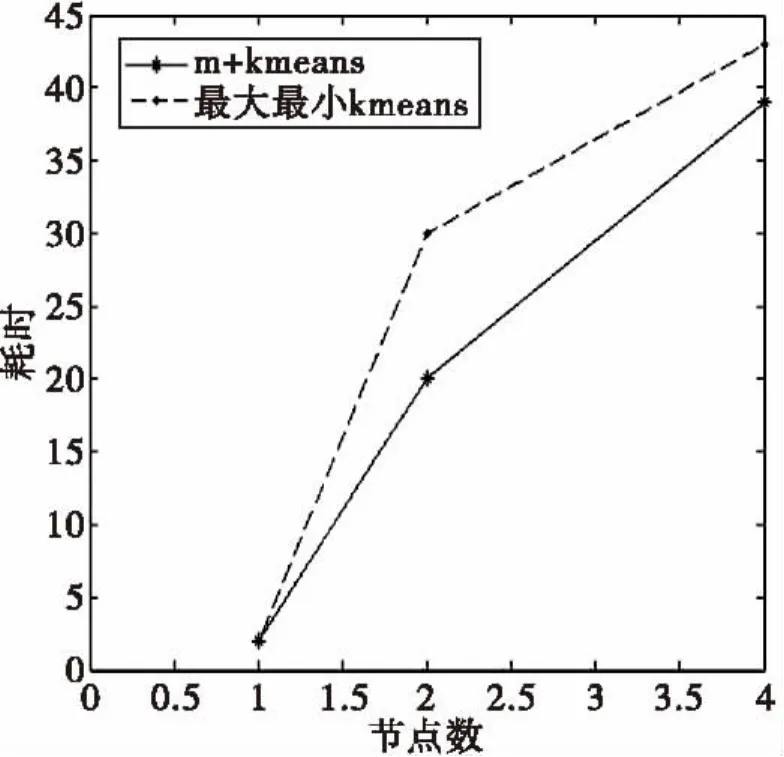
图2 两个算法时间消耗Fig.2 Two algorithms of time consumption
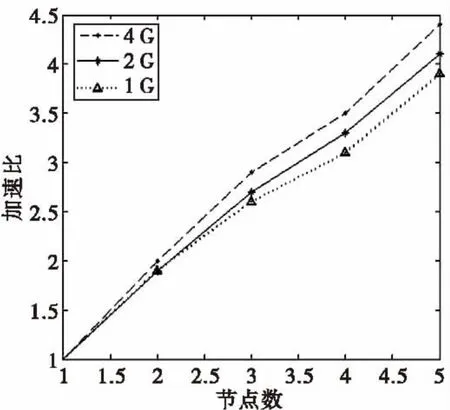
图3 M+Kmeans算法加速比Fig.3 M+Kmeans algorithms speedup
加速比测试选取了三组大小不同的数据,分为1 G,2 G和4 G的数据。从图3的加速比上可以看出,设计的算法的加速比基本上成线性的。而且处理的数据量越大加速比越好。这是因为第一:数据量大时,节点的运行效率增加了,更易发挥每个节点的计算能力了;第二:算法在reduce阶段之前加入了combine,使得节点之间拉取数据的效率提高了,而且数据量越大,这种效率提高的越多[11]。因此mapreduce框架更适合于大量数据的处理,而设计的算法也可以很好的将大数据处理运行在框架上。
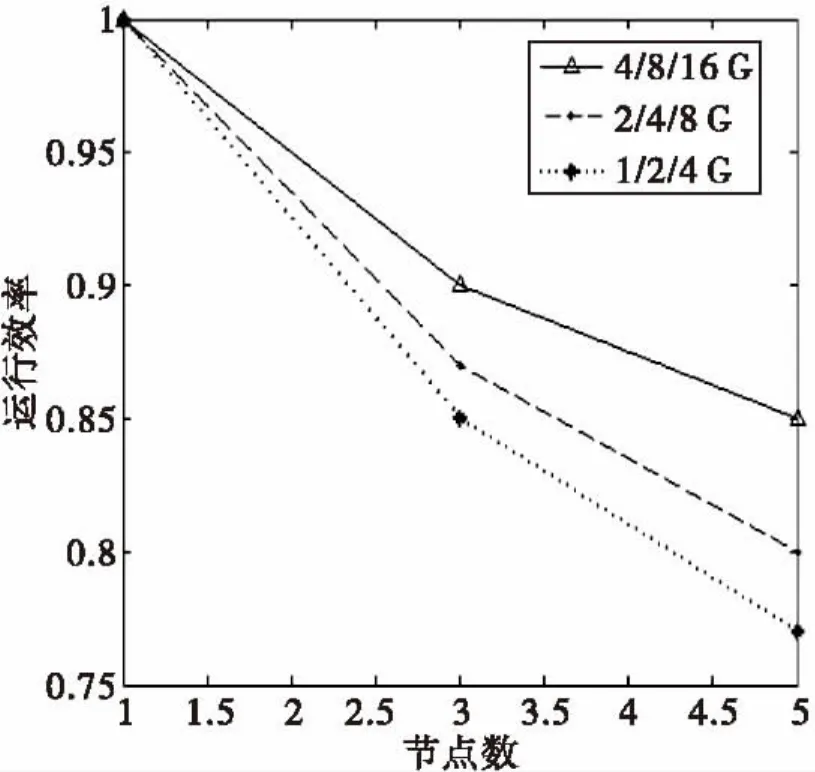
图4 算法扩展率Fig.4 Algorithms expansion ratio
扩展率的测试选取了三组数据,1 G、2 G、4 G为一组,2 G、4 G、8 G为一组,4 G、8 G、16 G为一组,并且每组数据从小到大分别运行在1个节点、3个节点和5个节点上。从图4可以看出随着节点的增加,运行效率也减小了,这是因为多节点运行时,节点之间的数据传送也会耗费资源。但是据图发现,5个节点时运行16 G的数据明显比运行8 G数据运行效率高。这是因为数据量增加,节点更易充分发挥它的计算能力,所以节点利用率高了。
4 结束语
对经典的K-means聚类算法进行了深入研究,针对最大最小值原理的中心值选取方法进行了改进,并移植到Hadoop平台上。改进的算法运用了最大值原则进行计算,将一次遍历数据的距离存入数组中进行map并行计算,减小了遍历数据的次数,然后将并行的map结果进行种子点合并再传送给reduce,节省了Map的资源,得到了优化的K值。
通过多组实验表明,改进的算法可以有效利用Hadoop平台强大的并行计算能力,更适合计算多维的大数据。但是不管是mapreduce框架的设计,还是算法到平台的移植都会有不断的新的问题出现。效率和时间消耗问题仍然是不变的改进重点,还需要不断的努力和探究。
[1]毛典辉.基于MapReduee的Canopy-kmeans改进算法[J].计算机工程与应用,2012,48(27):22-26.
[2]朱为盛,王鹏.基于Hadoop云计算平台的大规模图像检索方案[J].计算机应用,2014,34(3):695-699.
[3]JINSON ZHANG,MAO LINHUANG.5WS Model for BigData Analysis and Visualization[C]∥IEEE 16th International Conference on Computational Science and Engineering,Sydney,NSW,IEEE,2013:1021-1028.
[4]ROSANGELA DE FÁTIMA PEREIRA,MARCELO RISSE DE ANDRADE,ARTUR CARVALHO ZUCCHI,et al.Distributed processing from large scale sensor network using Hadoop[C]∥IEEE International Congress on Big Data,Santa Clara CA,IEEE,2013:417-418.
[5]李伟卫,赵航,张阳,等.基于MapReduce的海量数据挖掘技术研究[J].计算机工程与应用,2013,49(20):112-117.
[6]赵庆.基于Hadoop平台下的Canopy-Kmeans高效算法[J].2014,27(2):29-31.
[7]WEIKUAN YU,YANDONG WANG.Design and Evaluation of Network-Levitated Merge for Hadoop Acceleration[C]∥IEEE Transactions on Parallel and Distributed Systems,Washington DC,2014:602-611.
[8]亓开元,赵卓峰,房俊,等.针对高速数据流的大规模数据实时处理方法[J].计算机学报,2012,35(3):477-490.
[9]汪丽,张露.基于分布式数据挖掘方法的研究与应用[J].武汉理工大学学报:信息与管理工程版,2013,35(1):40-43.
[10]赖桃桃,冯少荣.聚类算法中的相似性度量方法研究[J].心智与计算,2008,18(2):176-181.
[11]曲朝阳,朱莉,张士林.基于Hadoop的广域测量系统数据处理[J].电力系统自动化,2013,37(4):92-97.
Clustering Algorithm K-value Optimization Research Based on Hadoop Platform
WU Xia,DONG Zeng-shou,MENG Xiao-yan
(School of Electronic information engineering,Taiyuan University of Science and Technology,Taiyuan 030024,China)
An initial clustering center selection algorithm called M+Kmeans algorithm was presented because the maximum-minimum principle of Kmeans clustering algorithm running on Hadoop platform needs to traverse all data for many times.This algorithm only needs to traverse a global data,thus greatly reducing the time of the algorithm and parallel computing.Multiple sets of experimental test results show that the design of M+Kmeans algorithm is suitable for operation on large Hadoop cluster platform,and the speed ratio can obviously improve the expansion rate than the original algorithm.
big data,cluster,Hadoop,kmeans
TP301.6
A
10.3969/j.issn.1673-2057.2015.02.003
1673-2057(2015)02-0092-05
2014-09-26
山西省自然科学基金(2012011015-4)
武霞(1988-),女,硕士研究生,主要研究方向为大数据数据挖掘。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
计算机技术与发展(2020年8期)2020-08-12
中国交通信息化(2020年1期)2020-07-27
电脑报(2020年12期)2020-06-30
铁道通信信号(2019年6期)2019-10-08
电脑报(2019年4期)2019-09-10
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
大众摄影(2015年9期)2015-09-06
